论文解读(USIB)《Towards Explanation for Unsupervised Graph-Level Representation Learning》
论文信息
论文标题:Towards Explanation for Unsupervised Graph-Level Representation Learning
论文作者:Qinghua Zheng, Jihong Wang, Minnan Luo, Yaoliang Yu, Jundong Li, Lina Yao, Xiaojun Chang
论文来源:2022, arXiv
论文地址:download
论文代码:download
1 Introduction
使用信息瓶颈的图级表示可解释性。
2 Notations and preliminaries
2.1 Information Bottleneck
给定输入数据 $X$ 及其标签 $Y$,Information Bottleneck 的目的是发现一个压缩的潜在表示 $Z$,它以 $Y$ 提供最大的信息。在形式上,我们可以通过优化以下优化问题来学习潜在的表示 $Z$:
$\underset{Z}{max } \;\mathcal{L}_{I B}=I(Z ; Y)-\beta I(X ; Z)\quad\quad\quad(1)$
其中,$\beta$ 表示对信息量和压缩量的超参数权衡。
互信息(MI)I(X;Z)度量两个随机变量的相关性,表述为
$I(X ; Z)= \int_{x} \int_{z} p(x, z) \log \frac{p(x, z)}{p(x) p(z)} d x d z $
2.2 GNN explanation
GNN的解释旨在理解对GNN的计算过程至关重要的图的内在信息,从而提供人类可理解的解释。具体来说,给定一个图 $G$ 和一个学习条件分布 $P_{\psi}(\hat{Z} \mid G), \mathrm{GNN}$ 的GNN模型 $\psi$),GNN解释的目的是学习与GNN的计算结果最相关的解释子图 $S$,即:
$\underset{S \in \mathcal{S}}{\text{arg max }} \operatorname{Score}(S, \hat{Z})\quad\quad\quad(2)$
其中,$\mathcal{S}$ 表示由图 $G$ 的所有可能的子图组成的集合;$\operatorname{Score}(S, \hat{Z})$ 测量了子图 $\mathcal{S}$ 和 GNN 的计算结果 $\hat{Z}$ 之间的相关性。
例如,GNNExcraner[9]关注于对监督 GNN 的解释,并将相关评分 $\operatorname{Score}(S, \hat{Z})$ 形式化为互信息,即
$S=\arg \max _{S \in \mathcal{S}} I(S ; \hat{Y})$
其中,随机变量 $\hat{Y}=\hat{Z}$ 表示分类概率。
3 Method
3.1 Unsupervised Subgraph Information Bottleneck
在本文中,我们研究了无监督图级表示学习的未探索的解释问题。给定一个由无监督 GNN 提取的图 $G$ 及其对应的表示 $Z$,我们的目标是识别与这些表示最相关的解释子图 $S$。
根据前面的解释工作原理[9,10],我们利用互信息来度量相关性,因此将解释问题表述为 $\underset{S}{\text{arg max }} I(S ; Z)$。不幸的是,由于 $I(Z ; S) \leq I(Z ; G)$(证明见附录B),因此已经证明了存在一个平凡的解 $S=G$。琐碎的解决方案表明,解释子图年代可能包含多余的信息,例如,噪声和无关的信息表示 $Z$ 受 $IB$ 原则的成功解释监督网络[19],我们推广 $IB$ 原则无监督设置,以避免琐碎的解决方案和利用一个新的原则。
Definition. (Unsupervised Subgraph Information Bottleneck: USIB). Given a graph $G$ and its representation $Z$ , the USIB seeks for the most informative yet compressed explanation $S$ through optimization problem
$ \underset{S}{\text{max } }\mathcal{L}_{U S I B}=I(Z ; S)-\beta I(G ; S)\quad\quad\quad(3)$
通过优化USIB目标,我们可以在解释性子图的信息性和压缩性之间进行权衡。然而,由于USIB目标的优化,互信息涉及到高维数据的积分,这是非常困难的。因此,需要利用互信息估计方法。
3.2 Optimization for USIB
我们分别在USIB的目标中处理两项 $I(Z ; S)$ 和 $I(G ; S)$。
Maximizing $I(Z ; S)$
我们采用 Jensen-Shannon MI estimator [32,33]来为 $I(Z;S)$ 分配一个近似的下界,即,
$\hat{I}^{J S D}(Z ; S):=\sup _{f_{\phi}} \mathbb{E}_{p(S, Z)}\left[-s p\left(-f_{\phi}(S, Z)\right)\right]-\mathbb{E}_{p(S), p(Z)}\left[s p\left(f_{\phi}(S, Z)\right)\right]\quad\quad\quad(4)$
其中 $ s p(x)=\log \left(1+e^{x}\right)$ 为 softplus function;函数 $ f_{\phi}: \mathcal{S} \times \mathcal{Z} \rightarrow \mathbb{R}$ 是带可学习参数 $\phi $,以区分 $S$ 和 $Z$ 的实例是否从联合分布中采样。它是由 $\mathrm{MLP}_{\phi_{1}}$ 和 $\mathrm{GNN}_{\phi_{2}}$ 的函数复合来实现的,即:
$f_{\phi}\left(S^{(k)}, Z^{(k)}\right)=\operatorname{MLP}_{\phi_{1}}\left(\operatorname{GNN}_{\phi_{2}}\left(S^{(k)}\right) \| Z^{(k)}\right)\quad\quad\quad(5)$
其中,$\phi=\left\{\phi_{1}, \phi_{2}\right\}$;$\|$ 是指连接操作符。请注意,先验分布 $p(S, Z)$ 和 $p(Z)$ 在实践中通常是不可到达的。结合蒙特卡罗抽样来近似先验分布,我们得到了一个近似下界 $Eq.4$ 由:
$\underset{\phi}{max} \mathcal{L}_{1}(\phi, S)=\frac{1}{K} \sum\limits_{k=1}^{K}-s p\left(-f_{\phi}\left(S^{(k)}, Z^{(k)}\right)\right)-\frac{1}{K} \sum\limits_{k=1, m \neq k}^{K} s p\left(f_{\phi}\left(S^{(k)}, Z^{(m)}\right)\right)\quad\quad\quad(6)$
其中,$K$ 为样本的数量。$\left(S^{(k)}, Z^{(k)}\right)$ 从联合分布 $p(S, Z)$ 中采样,$\left(S^{(k)}, Z^{(m)}\right)$ 分别从边缘分布 $p(S)$ 和 $p(Z)$ 中独立采样。在实践中,我们通过随机排列从联合分布中抽样 $\left(S^{(k)}, Z^{(k)}\right)$ 对来采样 $\left(S^{(k)}, Z^{(m)}\right)$。
Minimizing $\boldsymbol{I}(\boldsymbol{G} ; \boldsymbol{S}) $
请注意,解释子图的熵 $H(S)=\mathbb{E}_{p(S)}[-\log p(S)]$ 为 $I(G ; S)$ 提供了一个上界,因为不等式 $I(G ; S)=H(S)-H(S \mid G) \leq H(S)$ 成立。然而,由于在实践中 $S$ 的先验分布未知的,因此很难计算熵。为了解决这个问题,我们考虑一个松弛,并假设解释图是一个吉尔伯特随机图(Gilbert random graph)[34],其中边有条件地相互独立。具体地说,让 $(i, j) \in \mathcal{E}$ 表示图 $G$ 的边,$e_{i, j} \sim \operatorname{Bernoulli}\left(\mu_{i, j}\right)$ 是一个二元变量指示是否为子图 $S$ 选择边 $(i, j)$ 。因此,子图的概率分解为 $p(S)=\prod\limits _{(i, j) \in \mathcal{E}} p\left(e_{i, j}\right)$,其中 $p\left(e_{i, j}\right)=\mu_{i, j}^{e_{i, j}}\left(1-\mu_{i, j}\right)^{1-e_{i, j}}$。这样,我们就可以用蒙特卡罗抽样得到 $I(G ; S)$ 的一个近似上界,它记为
$\mathcal{L}_{2}(S)=-\frac{1}{K} \sum\limits_{k=1}^{K} \sum\limits_{(i, j) \in \mathcal{E}} e_{i, j}^{(k)} \log \mu_{i, j}^{(k)}+\left(1-e_{i, j}^{(k)}\right) \log \left(1-\mu_{i, j}^{(k)}\right)\quad\quad\quad(7)$
基于梯度的优化方法可能无法优化 $\text{Eq.6}$ 和 $\text{Eq.7}$ ,由于不可微采样过程和子图结构的离散性质。因此,我们遵循 Gumbel-Softmax reparametrization trick [35, 36] 并将二元变量 $e_{i, j}$ 放宽为一个连续的边权值变量 $\hat{e}_{i, j}=\sigma((\log \epsilon-\log (1-\epsilon)+ \left.\left.w_{i, j}\right) / \tau\right) \in[0,1]$,其中 $\sigma(\cdot)$ 是 sigmoid function ;$\epsilon \sim \operatorname{Uniform}(0,1)$;$\tau$ 是温度超参数,并有 $\lim _{\tau \rightarrow 0} p\left(\hat{e}_{i, j}=1\right)=\sigma\left(w_{i, j}\right)$;$w_{i, j}$ 是由神经网络根据之前的工作计算的潜在变量:
$w_{i, j}^{(k)}=\operatorname{MLP}_{\theta_{1}}\left(\mathbf{z}_{i}^{(k)} \| \mathbf{z}_{j}^{(k)}\right) \text { with } \mathbf{z}_{i}^{(k)}=\operatorname{GNN}_{\theta_{2}}\left(G^{(k)}, i\right), i=1,2, \cdots\quad\quad\quad(8)$
其中,$\mathbf{z}_{i}^{(k)}$ 表示节点 $i$ 的节点表示。为了更好地表示,我们表示 $\theta= \left\{\theta_{1}, \theta_{2}\right\}$,并通过 $\hat{S}^{(k)}=g_{\theta}\left(G^{(k)}\right)^{3}$ 生成松弛子图 $\hat{S}$。设 $\mu_{i, j}^{(k)}=\sigma\left(w_{i, j}^{(k)}\right)$,等式中的 $\text{Eq.7}$ 可以被重写为
$\mathcal{L}_{2}\left(g_{\theta}\left(G^{(k)}\right)\right)=-\frac{1}{K} \sum\limits_{k=1}^{K} \sum\limits_{(i, j) \in \mathcal{E}} \hat{e}_{i, j}^{(k)} \log \sigma\left(w_{i, j}^{(k)}\right)+\left(1-\hat{e}_{i, j}^{(k)}\right) \log \left(1-\sigma\left(w_{i, j}^{(k)}\right)\right)\quad\quad\quad(9)$
总之,我们重写了USIB优化问题 $\text{Eq.3}$ 作为:
$\underset{\phi, \theta}{\text{max }} \mathcal{L}_{U S I B}(\phi, \theta, G)=\mathcal{L}_{1}\left(\phi, g_{\theta}\left(G^{(k)}\right)\right)-\beta * \mathcal{L}_{2}\left(g_{\theta}\left(G^{(k)}\right)\right)\quad\quad\quad(10)$
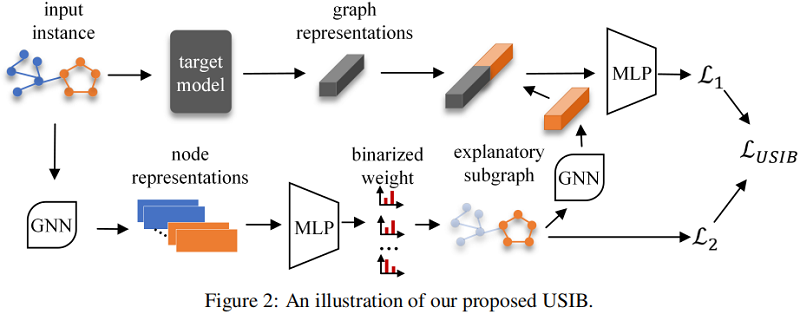
我们的方法的概述如 Fig. 2 所示。首先通过神经网络生成解释子图,然后利用另一个网络来估计解释子图和图表示之间的互信息。最后,对子图生成器和互信息估计器进行了协同优化。最终的解释性子图可以通过选择具有 top-n 个边权值 $\left(\hat{e}_{i, j}^{(k)}\right)$ 的边来实现。详细的算法可以在附录中找到。
3 Experiments
在本节中,我们通过回答以下问题来实证评估我们所提出的方法的有效性和优越性。
- RQ1 How does our proposed method perform compared to other baseline explainers?
- RQ2 Does expressiveness and robustness of representations affect the fifidelity of explanatory subgraphs in agreement with the theoretical analysis?
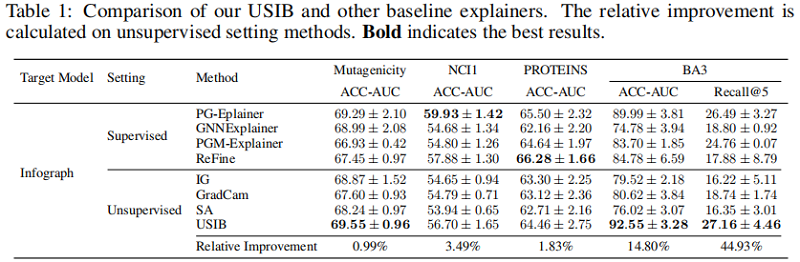
3.1 Effectiveness of USIB
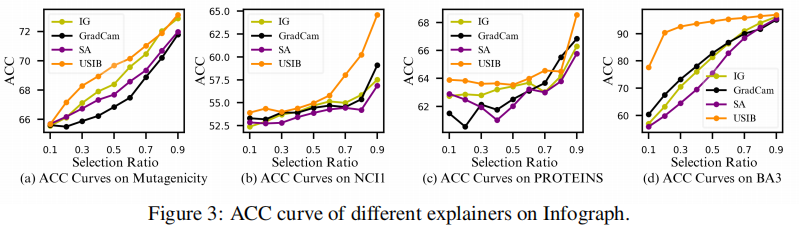
3.2 Inflfluence of representations’ expressiveness and robustness
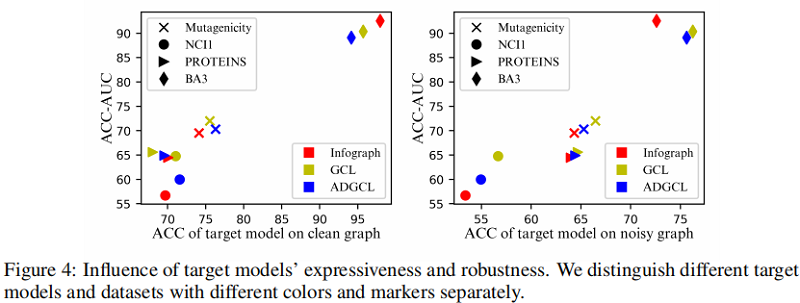
3.3 Qualitative analysis

4 Conclusion
我们研究了一个未被探索的解释问题:对无监督图表示学习的解释。我们提出了IB原理来解决解释问题,从而产生了一种新的解释方法USIB。此外,我们还从理论上分析了标签空间上的表示和解释子图之间的联系,结果表明,表达性和鲁棒性有利于解释子图的保真度。在四个数据集和三个目标模型上的广泛结果证明了我们的方法的优越性和理论分析的有效性。作为未来的研究方向,我们考虑了无监督表示学习的反事实解释[42],并探讨了解释和对抗性例子[43,44,45]之间是否存在联系。
修改历史
2022-06-21 创建文章
参考文献
论文解读(USIB)《Towards Explanation for Unsupervised Graph-Level Representation Learning》的更多相关文章
- 论文解读(GRACE)《Deep Graph Contrastive Representation Learning》
Paper Information 论文标题:Deep Graph Contrastive Representation Learning论文作者:Yanqiao Zhu, Yichen Xu, Fe ...
- 论文解读(GCC)《Efficient Graph Convolution for Joint Node RepresentationLearning and Clustering》
论文信息 论文标题:Efficient Graph Convolution for Joint Node RepresentationLearning and Clustering论文作者:Chaki ...
- 论文解读(AGC)《Attributed Graph Clustering via Adaptive Graph Convolution》
论文信息 论文标题:Attributed Graph Clustering via Adaptive Graph Convolution论文作者:Xiaotong Zhang, Han Liu, Qi ...
- 论文解读《Momentum Contrast for Unsupervised Visual Representation Learning》俗称 MoCo
论文题目:<Momentum Contrast for Unsupervised Visual Representation Learning> 论文作者: Kaiming He.Haoq ...
- 论文解读(MLGCL)《Multi-Level Graph Contrastive Learning》
论文信息 论文标题:Structural and Semantic Contrastive Learning for Self-supervised Node Representation Learn ...
- 论文解读(SelfGNN)《Self-supervised Graph Neural Networks without explicit negative sampling》
论文信息 论文标题:Self-supervised Graph Neural Networks without explicit negative sampling论文作者:Zekarias T. K ...
- 论文解读(DGI)《DEEP GRAPH INFOMAX》
论文标题:DEEP GRAPH INFOMAX 论文方向:图像领域 论文来源:2019 ICLR 论文链接:https://arxiv.org/abs/1809.10341 论文代码:https:// ...
- 论文解读(DCRN)《Deep Graph Clustering via Dual Correlation Reduction》
论文信息 论文标题:Deep Graph Clustering via Dual Correlation Reduction论文作者:Yue Liu, Wenxuan Tu, Sihang Zhou, ...
- 论文解读(IGSD)《Iterative Graph Self-Distillation》
论文信息 论文标题:Iterative Graph Self-Distillation论文作者:Hanlin Zhang, Shuai Lin, Weiyang Liu, Pan Zhou, Jian ...
- 论文解读(SAGPool)《Self-Attention Graph Pooling》
论文信息 论文标题:Self-Attention Graph Pooling论文作者:Junhyun Lee, Inyeop Lee, Jaewoo Kang论文来源:2019, ICML论文地址:d ...
随机推荐
- spring-基于xml的aop开发-快速入门
1.导入aop的相关坐标 <dependency> <groupId>org.springframework</groupId> <artifactId> ...
- Redis 未授权访问漏洞【原理扫描】修复方法
漏洞类型 主机漏洞 漏洞名称/检查项 Redis 配置不当可直接导致服务器被控制[原理扫描] 漏洞名称/检查项 Redis 未授权访问漏洞[原理扫描] 加固建议 防止这个漏洞需要修复以下三处问题 第一 ...
- 时间篇之centos7修复ntpq: read: Connection refused
关于ntp同步时间, 由于是解决问题,所以理论性内容不多. 关于UTC NTP要提供准确的时间,就必须有准确的时间来源,那可以用格林尼治时间吗?答案是否定的. 因为格林尼治时间是以地球自转为基础的时间 ...
- php怎么向上取整以5为界
public function test(){ $number = 52093; var_dump( $this->roundNumberVariant( ( int ) $number ) ) ...
- java高级用法之:JNA类型映射应该注意的问题
目录 简介 String Buffers,Memory,数组和Pointer 可变参数 总结 简介 JNA提供JAVA类型和native类型的映射关系,但是这一种映射关系只是一个大概的映射,我们在实际 ...
- 解决Mapper.xml文件中sql标签第一个字段报错
在文件标头的http后边补上www 下边代码仅第4行有变动 原文件: <?xml version="1.0" encoding="UTF-8"?> ...
- Vagrant详细教程
一.安装virtualBox 进入 VirtualBox 的主页,即可进入下载页面. VirtualBox 是一个跨平台的虚拟化工具,支持多个操作系统,根据自己的情况选择对应的版本下载即可. 在安装完 ...
- 漏洞复现:使用Kali制作木马程序
漏洞复现:使用Kali制作木马程序 攻击机:Kali2019 靶机:Win7 64位 攻击步骤: 1.打开Kali2019和Win7 64位虚拟机,确定IP地址在一个网段 2.确定好IP地址,进入Ka ...
- Linux 运维请务必收藏~ Nginx 五大常见应用场景
关注「开源Linux」,选择"设为星标" 回复「学习」,有我为您特别筛选的学习资料~ Nginx 是一个很强大的高性能 Web 和反向代理服务,它具有很多非常优越的特性,在连接高并 ...
- height不确定时,如何使用动画效果展开高度
要点: 当元素 height 不确定时,可以使用 max-height 设置动画效果 a[href="foldBox"] 用于打开 #foldBox(利用伪元素 :target) ...