【Java集合框架002】原理层面:HashMap全解析
一、前言
二、HashMap
2.1 HashMap数据结构 + HashMap线程不安全 + 哈希冲突
2.1.1 HashMap数据结构
学习的时候,先整体后细节,HashMap整体结构是 底层数组+链表 ,先记住,再开始看下面的
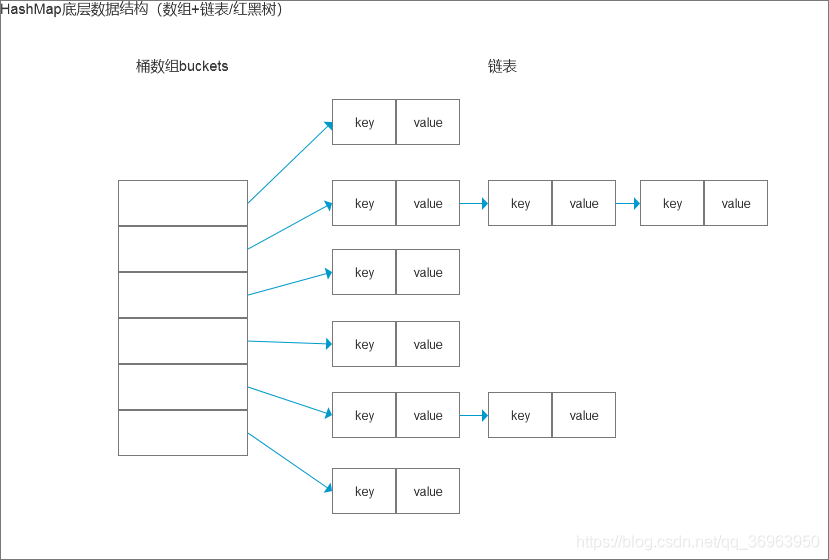
HashMap相关知识点:
- 底层数据结构:HashMap基于哈希散列表实现 ,可以实现对数据的读写。
- 插入逻辑put()方法:将键值对传递给put方法时,它调用键对象的hashCode()方法来计算hashCode,然后找到相应的bucket位置(即数组)来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。
- 哈希冲突:插入逻辑中,如果发生哈希冲突,使用链表来解决hash冲突问题,即当发生冲突了,对象将会储存在链表的头节点中。HashMap在每个链表节点中储存键值对对象,当两个不同的键对象的hashCode相同时(HashMap在两个key-value,hashcode相同导致index相同,就认为发生哈希冲突,equals相同任务同一个,不重复插入,HashSet在hashcode和equals相同,认为同一个,不重复插入),它们会储存在同一个bucket位置的链表中,如果链表大小超过阈值(TREEIFY_THRESHOLD,8),链表就会被改造为树形结构。
- HashMap和HashSet:HashMap在两个key-value,hashcode相同导致index相同,哈希冲突,equals相同任务同一个,不重复插入,HashSet在hashcode和equals相同,认为同一个,不重复插入。
2.1.2 HashMap线程不安全
HashMap是应用更广泛的哈希表实现,而且大部分情况下,都能在常数时间性能的情况下进行put和get操作。但是,HashMap在多线程并发的情况下是不安全的,通过两个问题的回答来解释原因。
问题1:为什么说HashMap是线程不安全的?
回答1:在接近临界点时,若此时两个或者多个线程进行put操作,都会进行resize(扩容)和reHash(为key重新计算所在位置),而reHash在并发的情况下可能会形成链表环。即在多线程环境下,使用HashMap进行put操作会引起死循环,导致CPU利用率接近100%,所以在并发情况下不能使用HashMap。
问题2:为什么在并发执行put操作会引起死循环?
回答2:因为多线程会导致HashMap的Entry链表形成环形数据结构,一旦形成环形数据结构,Entry的next节点永远不为空,就会产生死循环获取Entry。值得注意的是,JDK1.7的情况下,并发扩容时容易形成链表环,此情况在1.8时就好太多太多了,因为在1.8中当链表长度大于阈值(默认长度为8)时,链表会被改成树形(红黑树)结构。
2.1.3 哈希冲突
哈希冲突定义:若干Key的哈希值按数组大小取模后,如果落在同一个数组下标上,将组成一条Entry链,对Key的查找需要遍历Entry链上的每个元素执行equals()比较(tip:知道了HashMap的“数组+链表”结构,就很好懂哈希冲突了)。
加载因子:为了降低哈希冲突的概率,默认当HashMap中的键值对达到数组大小的75%时,即会触发扩容。因此,如果预估容量是100,即需要设定100/0.75=134的数组大小,又因为HashMap大小必须是2的整数次幂,所以是大于134的最小的2的整数次幂,即256。
减少哈希冲突两方法:降低加载因子,加大初始大小。
HashMap中数组扩容相关概念(size capacity size/capacity):
size是当前现实的记录数;capacity是理论上的容量,第一次由初始化决定,之后由扩容决定;initial capacity是初始的capacity,第一次的capacity。
负载因子等于“size/capacity”,全称为当前负载因子,其作用是当负载因子达到负载极限的时候扩容。当负载因子为0,表示空的hash表;负载因子为0.5,表示半满的散列表,依此类推。轻负载的散列表具有冲突少、适宜插入与查询的特点(但是使用Iterator迭代元素时比较慢)。
负载极限:“负载极限”是一个0~1的数值,“负载极限”决定了hash表的最大填满程度。当hash表中的负载因子达到指定的“负载极限”时,hash表会自动成倍地增加容量(桶的数量),并将原有的对象重新分配,放入新的桶内,这称为rehashing。HashMap和HashTable的构造器允许指定一个负载极限,HashMap和HashTable默认的“负载极限”为0.75,这表明当该hash表的3/4已经被填满时,hash表会发生rehashing。
“负载极限”的默认值(0.75)是时间和空间成本上的一种折中:
- 较高的“负载极限”可以降低hash表所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的操作(HashMap的get()与put()方法都要用到查询),所以会影响时间性能;
- 较低的“负载极限”会提高查询数据的性能,但会增加hash表所占用的内存开销,影响空间性能;
程序员可以根据实际情况来调整“负载极限”值。
以上专有名词连接起来是:size是记录数,capacity是桶数量,两者size/capacity得到负载因子,当负载因子达到理论设定的负载极限的时候扩容。专有名词(size、capacity、负载因子、负载极限、扩容(具体扩容逻辑)),所有的这些都可以在源码中找到逻辑。
2.2 JDK1.7中HashMap的实现
2.2.1 基本元素Entry
数组中的每一个元素其实就是Entry<K,V>[] table,Map中的key和value就是以Entry的形式存储的。Entry包含四个属性:key、value、hash值和用于单向链表的next。关于Entry<K,V>的具体定义参看如下源码:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
public final String toString() {
return getKey() + "=" + getValue();
}
/**
* This method is invoked whenever the value in an entry is
* overwritten by an invocation of put(k,v) for a key k that's already
* in the HashMap.
*/
void recordAccess(HashMap<K,V> m) {
}
/**
* This method is invoked whenever the entry is
* removed from the table.
*/
void recordRemoval(HashMap<K,V> m) {
}
}
JDK7中的HashMap,小结为以下几点:
- 基本元素为Entry,Entry包含四个属性:key、value、int类型的hash值和用于单向链表的Node类型的next;
- hash不是用于新插入的Entry和原有的链表节点的hashcode比较的,只是用于计算一下数组index的;
- key,value 是用于新插入的Entry和原有的链表的节点的 key,value 比较的,只有到equals和hashcode(index)比较都先相同,就认为是相同元素,被认为是相同就不会插入HashMap;
- next用于下一个链表中下一个节点。
2.2.2 插入逻辑
2.2.2.1 put()方法 = hash()方法 + indexFor()方法 + equals()方法
当向 HashMap 中 put一对键值时,它会根据 key的 hashCode 值计算出一个位置, 该位置就是此对象准备往数组中存放的位置。 该计算过程参看如下代码:
transient int hashSeed = 0;
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
return h & (length-1);
}hash(Object)方法是用来计算哈希值的,indexFor(hash,length)方法是用来计算数组下标的。
两者关系:indexFor方法根据hash(Object)方法的返回值作为实参来计算数组下标。
金手指:(put操作中的)hashcode方法和equals方法
- 第一步,确定数组下标,indexFor使用hash方法计算出来的值得到数组下标;
- 第二步,插入,如果指定的数组下标无对象存在,不发生哈希冲突,直接插入;
- 第三步,如果指定的数组下标有对象存在,发生哈希冲突,使用equals对链条上对象比较,全部为false插入,其中一个为true,表示已经存在(hash和equals都相同就是存在)
小结:仅以put操作为例,插入操作中hash方法用来作为计算数组下标的输入,equals用于比较对象是否存在。
问题1:指定数组下标有值,哈希冲突后如何处理?
回答1:put操作的时候,当两个key通过hashCode计算相同时,则发生了hash冲突(碰撞),HashMap解决hash冲突的方式是用链表(拉链法),当发生hash冲突时,则将存放在数组中的Entry设置为新值的next(比如A和B都hash后都映射到下标i中,之前已经有A了,当map.put(B)时,将B放到下标i中,A则为B的next,所以新值存放在链表最头部的数组中,旧值在新值的链表上)。
问题2:哈希冲突发生后,为什么后插入的值要放在链表头部?
回答2:因为后插入的Entry是“热乎的”,被查找的可能性更大(因为get查询的时候会遍历整个链表),既然后插入的Entry是“热乎的”,那么这个后插入的Entry应该放在哪里呢?当然是放在链表头部,因为链表查找复杂度为O(n),插入和删除复杂度为O(1),如果将新值插在末尾,就需要先经过一轮遍历,这个开销大,如果是插在头结点,省去了遍历的开销,还发挥了链表插入性能高的优势。
2.2.2.2 addEntry() + createEntry()
添加节点到链表中:找到数组下标后,会先进行key判重,如果没有重复,就准备将新值放入到链表的表头。
void addEntry(int hash, K key, V value, int bucketIndex) {
// addEntry方法中,如果当前 HashMap 大小已经达到了阈值,并且新值要插入的数组位置已经有元素了,那么要扩容
if ((size >= threshold) && (null != table[bucketIndex])) {
// 扩容
resize(2 * table.length);
// 扩容以后,重新计算 hash 值
hash = (null != key) ? hash(key) : 0;
// 重新计算扩容后的新的下标
bucketIndex = indexFor(hash, table.length);
}
// createEntry就是插入新值
createEntry(hash, key, value, bucketIndex); // key value由方法参数提供,未扩容,hash bucketIndex使用方法参数传递的,扩容,hash bucketIndex使用新计算的
}
// 这个很简单,其实就是将新值放到链表的表头,然后 size++
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}上述代码解释了:JDK7情况下的扩容
- addEntry方法中,如果当前 HashMap 大小已经达到了阈值,并且新值要插入的数组位置已经有元素了,那么要扩容
- HashMap扩容方式:两倍扩容
- 扩容后重新计算要已经插入了的key的数组下标:先hash,然后indexFor
- 新元素插入指定数组下标的链头,table[bucketIndex] = new Entry<>(hash, key, value, e); 新建一个Entry就是一个元素
这个方法的主要逻辑就是先判断是否需要扩容,需要带的话先扩容,然后再将这个新的数据插入到扩容后的数组的相应位置处的链表的表头。
2.2.3 扩容逻辑:resize()
定义:扩容就是用一个新的大数组替换原来的小数组,并将原来数组中的值迁移到新的数组中。
由于是双倍扩容,迁移过程中,会将原来table[i]中的链表的所有节点,分拆到新的数组的newTable[i]和newTable[i+oldLength]位置上。比如:原来数组长度是16,那么扩容后,原来table[0]处的链表中的所有元素会被分配到新数组中newTable[0]和newTable[16]这两个位置。扩容期间,由于会新建一个新的空数组,并且用旧的项填充到这个新的数组中去。所以,在这个填充的过程中,如果有线程获取值,很可能会取到 null 值,而不是我们所希望的、原来添加的值。
我们对照HashMap的结构来说,如下:
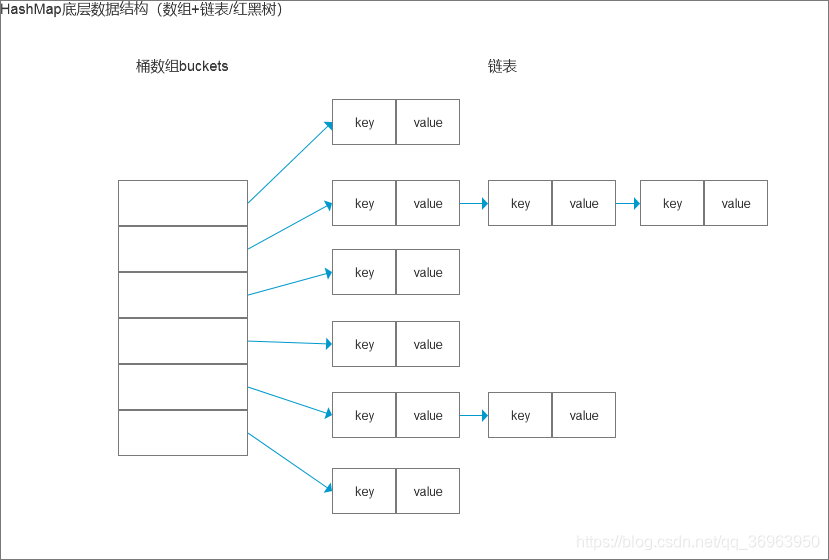
上图中,左边部分即代表哈希表,也称为哈希数组(默认数组大小是16,每对key-value键值对其实是存在map的内部类entry里的),数组的每个元素都是一个单链表的头节点,跟着的蓝色链表是用来解决冲突的,如果不同的key映射到了数组的同一位置处,就将其放入单链表中。
当size>=threshold( threshold等于“容量*负载因子”)时,会发生扩容。
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length); // 扩容
hash = (null != key) ? hash(key) : 0; // 扩容后要用新的hash,不能用参数的
bucketIndex = indexFor(hash, table.length); // 扩容后要用新的bucketIndex,不用用参数的
}
createEntry(hash, key, value, bucketIndex); // key value由方法参数提供,未扩容,hash bucketIndex使用方法参数传递的,扩容,hash bucketIndex使用新计算的
}特别提示:JDK1.7中resize,只有当 size>=threshold 并且 table中的那个槽中已经有Entry时,才会发生resize。即有可能虽然size>=threshold,但是必须等到相应的槽至少有一个Entry时,才会触发扩容,可以通过上面的代码看到每次resize都会扩大一倍容量(2 * table.length)。
2.2.4 null处理
前面说过HashMap的key是允许为null的,当出现这种情况时,会放到table[0]中。
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}put()逻辑:hash()方法、indexFor()方法、equals()方法
金手指:(put操作中的)hashcode方法和equals方法
JDK7 put 子步骤:扩容 + createEntry插入 + 哈希冲突 ( JDK8 put 子步骤:扩容 + createEntry插入 + 哈希冲突链表/树化 )
- 第一步,使用hash和tab.lenght计算数组下标index,准备插入,index=hash&(tab.length-1);
- 第二步,执行插入,如果指定的数组下标无对象存在,不发生哈希冲突,直接插入;
- 第三步,如果指定的数组下标有对象存在,表示发生哈希冲突,使用equals对链条上对象比较,全部为false插入,其中一个为true,表示已经存在(hash和equals都相同就是存在)
小结:插入操作中hash方法用来作为计算数组下标的输入参数,equals用于比较链表上对象是否存在
小结:JDK7情况插入情况下的扩容 addEntry
- 扩容方式:HashMap扩容方式:两倍扩容 newsize=oldsize *2
- 数组扩容的触发-两个条件:addEntry方法中,如果当前 HashMap 大小已经达到了阈值75%,并且新值要插入的数组位置已经有元素了,才执行扩容(两个条件,即有可能虽然size>=threshold,但是必须等到相应的槽至少有一个Entry时,才会扩容)
- 扩容后重新计算要已经插入了的key的数组下标:使用hash和tab.lenght计算数组下标index,准备插入,index=hash&(tab.length-1);
- 扩容后的插入,对于原来数组的位置:扩容就是用一个新的大数组替换原来的小数组,并将原来数组中的值迁移到新的数组中。由于是双倍扩容,迁移过程中,会将原来table[i]中的链表的所有节点,分拆到新的数组的newTable[i]和newTable[i+oldLength]位置上。如原来数组长度是16,那么扩容后,原来table[0]处的链表中的所有元素会被分配到新数组中newTable[0]和newTable[16]这两个位置,从而减小链表长度。
- 扩容后的新插入:equals比较全部为false,然后将新元素插入指定数组下标的链头,table[bucketIndex] = new Entry<>(hash, key, value, e); 新建一个Entry就是一个元素
- 扩容过程中的隐患:扩容期间,由于会新建一个新的空数组,并且用旧的项填充到这个新的数组中去。所以,在这个填充的过程中,如果有线程获取值,很可能会取到 null 值,而不是我们所希望的、原来添加的值。
tip:ArrayList 1.5倍扩容,Vector两倍扩容,HashTable newsize=2oldsize +1 ,HashMap newsize=2oldsize
辨析:扩容、树化、哈希冲突
- 扩容:扩容的对象是数组,扩容两个条件:addEntry方法中,如果当前 HashMap 大小已经达到了阈值75%,并且新值要插入的数组位置已经有元素了,才触发扩容(扩容的第二个条件一定要put操作才能满足)
- 树化:树化的对象是链表,链表节点数达到8,且要求数组长度大于64
树化的时机:链表树化一定要在put操作才会出现,树链表化一定要在remove操作才会出现。
注意:树化第二个要求:数组长度必须大于等于MIN_TREEIFY_CAPACITY(64),否则继续采用扩容策略; - 哈希冲突:哈希冲突的定义是要插入的数组index位置有元素了。
JDK7:
(1)如果未发生哈希冲突,直接放到数组中;
(2)如果哈希冲突,没有达到阈值的75%,插入到链表后面;
(3)如果哈希冲突,达到阈值75%,数组扩容操作,扩容后原数组元素和新插入的数组元素都要变动的;
JDK8:
(1)如果未发生哈希冲突,直接放到数组中;插入完成后判断阈值是否扩容
(2)如果哈希冲突,链表节点数未达到8,但是数组长度小于64,尾插法放在链表后面,插入完成后判断阈值是否扩容
(3)如果哈希冲突,链表节点数未达到8,但是数组长度大于等于64,尾插法放在链表后面,插入完成后判断阈值是否扩容
(4)如果哈希冲突,链表节点数达到8,但是数组长度小于64,尾插法放在链表后面,插入完成后判断阈值是否扩容
(5)如果哈希冲突,链表节点数达到8,且要求数组长度大于等于64,尾插法插入到链表后面,链表树化,插入完成后判断阈值是否扩容
小结:扩容是数组扩容,哈希冲突是数组哈希冲突,但是对于JDK8的HashMap,扩容和是否产生哈希冲突无关,扩容是判断 size/capacity - 小结:扩容、树化、哈希冲突都是在put操作出现,但是三种不同。扩容和树化都是put操作发生哈希冲突导致的,put操作如果不哈希冲突啥是没有,所以只最重要的是设计分布均衡的哈希算法,头插和尾插,扩容和树化都是缓解措施。JDK7是put涉及哈希冲突、数组扩容,JDK8是put涉及哈希冲突、数组扩容、链表树化,JDK8中remove可以涉及树链表化。
2.3 JDK1.8中HashMap的实现(所有内容围绕JDK7与JDK8最大不同——链表/红黑树而展开)
2.3.1 属性支持
HashMap底层维护的是数组+链表,我们可以通过一小段源码来看看:
/**
* The default initial capacity - MUST be a power of two.
* 即 默认初始大小,值为16
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
* 即 最大容量,必须为2^30
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
* 负载因子为0.75
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
* 大致意思就是说hash冲突默认采用单链表存储,当单链表节点个数大于8时,会转化为红黑树存储
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
* hash冲突默认采用单链表存储,当单链表节点个数大于8时,会转化
为红黑树存储。
* 当红黑树中节点少于6时,则转化为单链表存储
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* The smallest table capacity for which bins may be treeified.
* (Otherwise the table is resized if too many nodes in a bin.)
* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
* between resizing and treeification thresholds.
* hash冲突默认采用单链表存储,当单链表节点个数大于8时,会转化为红黑树存储。
* 但是有一个前提:要求数组长度大于64,否则不会进行转化
*/
static final int MIN_TREEIFY_CAPACITY = 64;通过以上代码可以看出初始容量(16)、负载因子以及对数组的说明。
小结:HashMap相关的变量:
- 初始化默认大小是16 initial capacity 16 JDK7+JDK8都一样
- 最大容量,必须为2^30 JDK7+JDK8都一样
- 默认负载因子为0.75 达到0.75就扩容,JDK7+JDK8都一样
- 树化阈值为8,链表化阈值为6 JDK8新增
树化的两个条件: 链表节点数达到8,且要求数组长度大于64
HashMap中最重要的两个操作是扩容和哈希冲突,但是要注意以下几点:
- 扩容是数组扩容,哈希冲突是链表/红黑树的哈希冲突,两者是的对象是不同的,关系是扩容是为了减低负载因子,减少哈希冲突;
- 减少哈希冲突两个设计:设计一个好的哈希算法 + 数组扩容;
- 对于真正发生了哈希冲突:JDK7是使用头插法插入链表,JDK8额外添加了树化逻辑;
- 无论是数组扩容还是哈希冲突后的链表/红黑树,都是发生在put操作中的,无论JDK7还是JDK8。put操作中的数组扩容和链表/红黑树哈希冲突:
JDK7的put方法:扩容 + hashcode生成index插入 + 哈希冲突;
JDK8的put方法:扩容 + hashcode生成index插入 + 哈希冲突。
2.3.2 基本元素Node
- 在JDK1.8中HashMap的内部结构可以看作是数组(Node<K,V>[] table)和链表的复合结构。
- 数组被分为一个个桶(bucket),通过哈希值决定了键值对在这个数组中的寻址(哈希值相同的键值对,就是哈希冲突,则以链表形式存储。
- 如果链表大小超过阈值(TREEIFY_THRESHOLD,8),图中的链表就会被改造为树形(红黑树)结构。
transient Node<K,V>[] table;Entry的名字变成了Node,原因是和红黑树的实现TreeNode相关联。1.8与1.7最大的不同就是利用了红黑树,即由数组+链表(或红黑树)组成。JDK1.8中,当同一个hash值的节点数不小于8时,将不再以单链表的形式存储了,会被调整成一颗红黑树(上图中null节点没画)。这就是JDK1.7与JDK1.8中HashMap实现的最大区别。
在分析JDK1.7中HashMap的哈希冲突时,不知大家是否有个疑问就是万一发生碰撞的节点非常多怎么办?如果说成百上千个节点在hash时发生碰撞,存储一个链表中,那么如果要查找其中一个节点,那就不可避免的花费O(N)的查找时间,这将是多么大的性能损失。这个问题终于在JDK1.8中得到了解决,在最坏的情况下,链表查找的时间复杂度为O(n),而红黑树一直是O(logn),这样会提高HashMap的效率。
JDK1.7中HashMap采用的是位桶+链表的方式,即我们常说的散列链表的方式;
JDK1.8中采用的是位桶+链表/红黑树的方式,虽然加快链表查找效率,但是也是非线程安全的,因为只有当某个位桶的链表的长度达到某个阀值的时候,这个链表才会转换成红黑树。
小结:从JDK7的Entry变为JDK8的Node
- 基本元素使用Node,意为红黑树的节点,Node包含四个属性:key、value、hash值和用于单向链表的next,和JDK7的Entry节点一样;
- hash不是用于新插入的Entry和原有的链表节点的hashcode比较的,只是用于计算一下数组index的;
- key,value 是用于新插入的Entry和原有的链表的节点的 key,value 比较的,只有到equals和hashcode(index)比较都先相同,就认为是相同元素,被认为是相同元素的不插入HashMap;
- next用于下一个链表中下一个节点。
2.3.3 插入逻辑:put()方法
通过分析put方法的源码,可以让这种区别更直观:
static final int TREEIFY_THRESHOLD = 8; // 树化
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true); // 调用putVal
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab;
Node<K,V> p;
int n, i;
//如果当前map中无数据,执行resize方法。并且返回n JDK7先扩容再插入,可能无效扩容,JDK8先插入再扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//如果要插入的键值对要存放的这个位置刚好没有元素,那么把他封装成Node对象,放在这个位置上即可,插入的时候没有哈希冲突
if ((p = tab[i = (n - 1) & hash]) == null) // 这里对p赋值,就是新的要插入的节点
tab[i] = newNode(hash, key, value, null); // 插入
//否则的话,说明这数组上面有元素,插入的时候发生哈希冲突
else {
Node<K,V> e; K k;
//如果这个元素的key与要插入的一样,那么就替换一下。
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p; // 直接将p赋值给局部变量e
// 1.如果这个元素的key与要插入的不一样,如果当前节点是TreeNode类型的数据,执行putTreeVal方法
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else { // else表示如果这个元素的key与要插入的不一样,如果还是遍历这条链子上的数据,跟JDK7没什么区别
for (int binCount = 0; ; ++binCount) { // 循环
if ((e = p.next) == null) { // 循环找到一个空位置的就插入链表
p.next = newNode(hash, key, value, null);
//2.完成了操作后多做了一件事情,判断,并且可能执行treeifyBin方法
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break; // 插入并判断是否树化,break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break; // 如果链表上已经存在了,直接break;这里不用树化了,应该根本没插入
p = e; // 不断将e赋值给p,更新p,就是p在链条上不断往后移动
}
}
// e 不为null 要么第一个if替换,要么else if树插入,要么链表插入,总之插入成功了,返回oldValue
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null) //true || --
e.value = value;
//3.
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//判断阈值,决定是否数组扩容 插入后决定是否扩容
if (++size > threshold)
resize();
//4. 插入之后的操作
afterNodeInsertion(evict);
return null;
}以上代码中的特别之处如下:
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);treeifyBin()就是将链表转换成红黑树。
源码解析putVal()操作(语言组织),如下:
扩容:如果当前map中无数据,执行resize方法。并且返回n JDK8先扩容再插入,JDK7先插入再扩容,可能无效扩容
没有哈希冲突:如果要插入的键值对要存放的这个位置刚好没有元素,那么把他封装成Node对象,放在这个位置上即可,插入的时候没有哈希冲突
这里对p赋值,就是新的要插入的节点
else 表示 否则的话,说明这数组上面有元素,插入的时候发生哈希冲突
if表示 //如果这个元素的key与要插入的一样,那么就替换一下。
else if 表示 1.如果这个元素的key与要插入的不一样,如果当前节点是TreeNode类型的数据,执行putTreeVal方法
else表示如果这个元素的key与要插入的不一样,如果还是遍历这条链子上的数据,跟JDK7没什么区别
// 循环
// 循环找到一个空位置的就插入链表
//2.完成了操作后多做了一件事情,判断,并且可能执行treeifyBin方法
// 插入并判断是否树化,break;
// 如果链表上已经存在了,直接break;这里不用树化了,应该根本没插入
// 不断将e赋值给p,更新p,就是p在链条上不断往后移动
返回oldValue: e 不为null 要么第一个if替换,要么else if树插入,要么链表插入,总之插入成功了,返回oldValue
插入后判断是否扩容:判断阈值,决定是否数组扩容 插入后决定是否扩容
最后 插入之后的操作
完成了。关于putVal(),注意以下三点:
- 树化有个要求就是数组长度必须大于等于MIN_TREEIFY_CAPACITY(64),否则继续采用扩容策略;
- resize方法兼顾两个职责,创建初始存储表格,或者在容量不满足需求的时候;
- 在JDK1.8中取消了indefFor()方法,直接用(tab.length-1)&hash,所以看到这个,代表的就是数组的下角标。
2.3.4 treeifyBin()树化为红黑树(难点:要看懂这个,一定要懂数据结构红黑树)
树化操作的过程有点复杂,可以结合源码来看看。将原本的单链表转化为双向链表,再遍历这个双向链表转化为红黑树。
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
//树形化还有一个要求就是数组长度必须大于等于64,否则继续采用扩容策略
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;//hd指向首节点,tl指向尾节点
do {
TreeNode<K,V> p = replacementTreeNode(e, null);//将链表节点转化为红黑树节点
if (tl == null) // 如果尾节点为空,说明还没有首节点
hd = p; // 当前节点作为首节点
else { // 尾节点不为空,构造一个双向链表结构,将当前节点追加到双向链表的末尾
p.prev = tl; // 当前树节点的前一个节点指向尾节点
tl.next = p; // 尾节点的后一个节点指向当前节点
}
tl = p; // 把当前节点设为尾节点
} while ((e = e.next) != null); // 继续遍历单链表
//将原本的单链表转化为一个节点类型为TreeNode的双向链表
if ((tab[index] = hd) != null) // 把转换后的双向链表,替换数组原来位置上的单向链表
hd.treeify(tab); // 将当前双向链表树形化
}
}特别注意:树化有个要求就是数组长度必须大于等于MIN_TREEIFY_CAPACITY(64),否则继续采用扩容策略。
总的来说,HashMap默认采用数组+单链表方式存储元素,当元素出现哈希冲突时,会存储到该位置的单链表中。但是单链表不会一直增加元素,当元素个数超过8个时,会尝试将单链表转化为红黑树存储。但是在转化前,会再判断一次当前数组的长度,只有数组长度大于64才处理。否则,进行扩容操作。
将双向链表转化为红黑树的实现:
final void treeify(Node<K,V>[] tab) {
TreeNode<K,V> root = null; // 定义红黑树的根节点
for (TreeNode<K,V> x = this, next; x != null; x = next) { // 从TreeNode双向链表的头节点开始逐个遍历
next = (TreeNode<K,V>)x.next; // 头节点的后继节点
x.left = x.right = null;
if (root == null) {
x.parent = null;
x.red = false;
root = x; // 头节点作为红黑树的根,设置为黑色
}
else { // 红黑树存在根节点
K k = x.key;
int h = x.hash;
Class<?> kc = null;
for (TreeNode<K,V> p = root;;) { // 从根开始遍历整个红黑树
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h) // 当前红黑树节点p的hash值大于双向链表节点x的哈希值
dir = -1;
else if (ph < h) // 当前红黑树节点的hash值小于双向链表节点x的哈希值
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) // 当前红黑树节点的hash值等于双向链表节点x的哈希值,则如果key值采用比较器一致则比较key值
dir = tieBreakOrder(k, pk); //如果key值也一致则比较className和identityHashCode
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) { // 如果当前红黑树节点p是叶子节点,那么双向链表节点x就找到了插入的位置
x.parent = xp;
if (dir <= 0) //根据dir的值,插入到p的左孩子或者右孩子
xp.left = x;
else
xp.right = x;
root = balanceInsertion(root, x); //红黑树中插入元素,需要进行平衡调整(过程和TreeMap调整逻辑一模一样)
break;
}
}
}
}
//将TreeNode双向链表转化为红黑树结构之后,由于红黑树是基于根节点进行查找,所以必须将红黑树的根节点作为数组当前位置的元素
moveRootToFront(tab, root);
}然后将红黑树的根节点移动端数组的索引所在位置上:
static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) {
int n;
if (root != null && tab != null && (n = tab.length) > 0) {
int index = (n - 1) & root.hash; //找到红黑树根节点在数组中的位置
TreeNode<K,V> first = (TreeNode<K,V>)tab[index]; //获取当前数组中该位置的元素
if (root != first) { //红黑树根节点不是数组当前位置的元素
Node<K,V> rn;
tab[index] = root;
TreeNode<K,V> rp = root.prev;
if ((rn = root.next) != null) //将红黑树根节点前后节点相连
((TreeNode<K,V>)rn).prev = rp;
if (rp != null)
rp.next = rn;
if (first != null) //将数组当前位置的元素,作为红黑树根节点的后继节点
first.prev = root;
root.next = first;
root.prev = null;
}
assert checkInvariants(root);
}
}putVal方法处理的逻辑比较多,包括初始化、扩容、树化,近乎在这个方法中都能体现,针对源码简单讲解下几个关键点:
如果Node<K,V>[] table是null,resize方法会负责初始化,即如下代码:
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;resize方法兼顾两个职责:创建初始存储表格 + 在容量不满足需求的时候进行扩容(resize)。
在放置新的键值对的过程中,如果发生下面条件,就会发生扩容。
if (++size > threshold)
resize();具体键值对在哈希表中的位置(数组index)取决于下面的位运算:
i = (n - 1) & hash仔细观察哈希值的源头,会发现它并不是key本身的hashCode,而是来自于HashMap内部的另一个hash方法。为什么这里需要将高位数据移位到低位进行异或运算呢?这是因为有些数据计算出的哈希值差异主要在高位,而HashMap里的哈希寻址是忽略容量以上的高位的,那么这种处理就可以有效避免类似情况下的哈希碰撞。
在JDK1.8中取消了indefFor()方法,直接用(tab.length-1)&hash,所以看到这个,代表的就是数组的下角标。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}2.3.5 JDK8中的HashMap的王牌功能:问题1:HashMap为什么要树化?
问题:JDK8中的HashMap的王牌功能:为什么HashMap为什么要树化?
回答: 一句话概括:制造哈希碰撞从而造成DOS攻击,树化后优化哈希碰撞产生后的存取。
解释:其实这本质上一个安全问题。因为在元素放置过程中,如果一个对象哈希冲突,都被放置到同一个桶里,则会形成一个链表,我们知道链表查询是线性的,会严重影响存取的性能。而在现实世界,构造哈希冲突的数据并不是非常复杂的事情,恶意代码就可以利用这些数据大量与服务器端交互,导致服务器端CPU大量占用,这就构成了哈希碰撞拒绝服务攻击,国内一线互联网公司就发生过类似攻击事件。
哈希碰撞攻击: 用哈希碰撞发起拒绝服务攻击(DOS,Denial-Of-Service attack),常见的场景是攻击者可以事先构造大量相同哈希值的数据(制造哈希碰撞从而造成DOS攻击,树化后优化哈希碰撞产生后的存取),然后以JSON数据的形式发送给服务器,服务器端在将其构建成为Java对象过程中,通常以HashTable或HashMap等形式存储,哈希碰撞将导致哈希表发生严重退化,算法复杂度可能上升一个数据级,进而耗费大量CPU资源。
2.3.6 JDK8中的HashMap的王牌功能:问题2:链表树化的两个条件?/为什么要将链表中转红黑树的阈值设为8?
我们可以这么来看,当链表长度大于或等于阈值(默认为 8)的时候,如果同时还满足容量大于或等于 MIN_TREEIFY_CAPACITY(默认为 64)的要求,就会把链表转换为红黑树。同样,后续如果由于删除或者其他原因调整了大小,当红黑树的节点小于或等于 6 个以后,又会恢复为链表形态。
每次遍历一个链表,平均查找的时间复杂度是 O(n),n 是链表的长度。红黑树有和链表不一样的查找性能,由于红黑树有自平衡的特点,可以防止不平衡情况的发生,所以可以始终将查找的时间复杂度控制在 O(log(n))。最初链表还不是很长,所以可能 O(n) 和 O(log(n)) 的区别不大,但是如果链表越来越长,那么这种区别便会有所体现。所以为了提升查找性能,需要把链表转化为红黑树的形式。
还要注意很重要的一点,单个 TreeNode 需要占用的空间大约是普通 Node 的两倍,所以只有当包含足够多的 Nodes 时才会转成 TreeNodes,而是否足够多就是由 TREEIFY_THRESHOLD 的值决定的。而当桶中节点数由于移除或者 resize 变少后,又会变回普通的链表的形式,以便节省空间。
默认是链表长度达到 8 就转成红黑树,而当长度降到 6 就转换回去,这体现了时间和空间平衡的思想,最开始使用链表的时候,空间占用是比较少的,而且由于链表短,所以查询时间也没有太大的问题。可是当链表越来越长,需要用红黑树的形式来保证查询的效率。
在理想情况下,链表长度符合泊松分布,各个长度的命中概率依次递减,当长度为 8 的时候,是最理想的值。
事实上,链表长度超过 8 就转为红黑树的设计,更多的是为了防止用户自己实现了不好的哈希算法时导致链表过长,从而导致查询效率低,而此时转为红黑树更多的是一种保底策略,用来保证极端情况下查询的效率。
通常如果 hash 算法正常的话,那么链表的长度也不会很长,那么红黑树也不会带来明显的查询时间上的优势,反而会增加空间负担。所以通常情况下,并没有必要转为红黑树,所以就选择了概率非常小,小于千万分之一概率,也就是长度为 8 的概率,把长度 8 作为转化的默认阈值。
链表树化的两个条件:当链表长度大于或等于阈值(默认为 8)的时候,并且同时还满足容量大于或等于 MIN_TREEIFY_CAPACITY(默认为 64)的要求
处理哈希冲突两个方法:一个好的哈希算法、链表树化(前者才是根本,后者只是网络安全制造哈希
问题:JDK8中的HashMap的王牌功能:链表树化的两个条件?/为什么要将链表中转红黑树的阈值设为8?
回答:碰撞从而造成DOS攻击和不合理哈希算法的处理),所以设计为8。通常如果 hash 算法正常的话,那么链表的长度也不会很长,那么红黑树也不会带来明显的查询时间上的优势,反而会增加空间负担。所以通常情况下,并没有必要转为红黑树,所以就选择了概率非常小,小于千万分之一概率,也就是长度为 8 的概率,把长度 8 作为转化的默认阈值。
值得注意的是,实际开发中,发现 HashMap 内部出现了红黑树的结构,那可能是我们的哈希算法出了问题,所以需要选用合适的hashCode方法,以便减少冲突。
问题:为什么在JDK1.8中进行对HashMap优化的时候,把链表转化为红黑树的阈值是8,而不是7或者不是20呢?
标准回答:
- 第一,避免频繁转换,树化链表化转换成本与二叉树优化查询性能之间的平衡:如果选择6和8(如果链表小于等于6树还原转为链表,大于等于8转为树),中间有个差值7可以有效防止链表和树频繁转换。假设一下,如果设计成链表个数超过8则链表转换成树结构,链表个数小于8则树结构转换成链表,如果一个HashMap不停的插入、删除元素,链表个数在8左右徘徊,就会频繁的发生树转链表、链表转树,效率会很低。
- 第二,数学证明,泊松分布:还有一点重要的就是由于treenodes的大小大约是常规节点的两倍,因此我们仅在容器包含足够的节点以保证使用时才使用它们,当它们变得太小(由于移除或调整大小)时,它们会被转换回普通的node节点,容器中节点分布在hash桶中的频率遵循泊松分布,桶的长度超过8的概率非常非常小。所以作者应该是根据概率统计而选择了8作为阀值
- 第三,统计学问题:一个统计的问题,java设计一定使用数学方法和统计方法,知道得到这个8,就像丰巢快递为什么是12小时而不是24小时一样。
2.4 HashMap在1.7和1.8之间四个不同(对比方式,重要)
我们可以简单列下HashMap在1.7和1.8之间的变化,四点变化(除了底层结构,都要从源码层面解释):
第一,底层数据结构不同
1.7中采用数组+链表,1.8采用的是数组+链表/红黑树,即在1.7中链表长度超过一定长度后就改成红黑树存储。
第二,index:扩容后index的计算
1.7扩容时需要重新计算哈希值hash,根据hash计算索引位置index,equals比较链表上的元素。
1.8并不重新计算哈希值hash,巧妙地采用和扩容后容量进行&操作来计算新的索引位置index,即index = hash & (tab.length - 1) 。
第三,插入:哈希冲突的时候插入的值*
1.7是采用表头插入法插入链表,1.8采用的是尾部插入法。
在1.7中采用表头插入法,
缺点:因为头插法,在扩容时会改变链表中元素原本的顺序,以至于在并发场景下导致链表成环的问题;
优点:JDK7考虑刚刚插入的值是热乎的,所以放在表头;
在1.8中采用尾部插入法,
优点:因为尾插法,所以在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了;
缺点:因为尾插法,所有刚刚插入的节点放在最后面了,要找很麻烦,所以引入链表树化,超过8个节点就可以树化,找新插入的节点只要O(lgN)。
第四,扩容的时机:扩容与插入的先后顺序
1.7中是先扩容后插入新值的,1.8中是先插值再扩容
问题:为什么在JDK1.7的时候是先进行扩容后进行插入,而在JDK1.8的时候则是先插入后进行扩容的呢?
答案:代码就是这样写的,JDK8插入的时候使用了树化,所以将数组扩容放到了后面。
- 对于JDK1.8
在JDK1.7中的话,是先进行插入新值然后进行扩容操作的,主要是因为对链表转为红黑树进行的优化,因为你插入这个节点的时候有可能是普通链表节点,也有可能是红黑树节点,所以导致先插入后扩容,扩容判断与resize()函数调用如下:
//其实就是当这个Map中实际插入的键值对的值的大小如果大于这个默认的阈值的时候(初始是16*0.75=12)的时候才会触发扩容,
//这个是在JDK1.8中的先插入后扩容
if (++size > threshold)
resize();- 对于JDK1.7
在JDK1.7中的话,是先进行扩容操作然后进行插入新值的,就是当你发现你插入的桶是不是为空:
(1)如果不为空说明存在值,当前插入会发生哈希冲突,那么就必须得扩容;
(2)如果为空说明不存在值,当前插入不会发生哈希冲突,那么本次插入不需要扩容,那就等到下一次发生Hash冲突的时候在进行扩容,但是当如果以后都没有发生hash冲突产生,那么就不会进行扩容了,减少了一次无用扩容,也减少了内存的使用。
先扩容后插入代码逻辑如下:
void addEntry(int hash, K key, V value, int bucketIndex) {
//这里当钱数组如果大于等于12(假如)阈值的话,并且当前的数组的Entry数组还不能为空的时候就扩容
if ((size >= threshold) && (null != table[bucketIndex])) {
//扩容数组,比较耗时
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
> void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
//把新加的放在原先在的前面,原先的是e,现在的是new,next指向e
table[bucketIndex] = new Entry<>(hash, key, value, e);//假设现在是new
size++;
}三、其他:HashTable、TreeMap、ConcurrentHashMap
3.1 HashTable
| HashTable | HashMap 1.8 | |
|---|---|---|
| 底层数据结构 + key-value是否为null + 线程安全 | 底层数组+链表实现,无论key还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时锁住整个HashTable,效率低,ConcurrentHashMap做了相关优化 | 底层数组+链表实现,无论key还是value都可以为null,key为null,但是只有一个,value为null可以多个,使用containsKey()判断是否存在某个key,线程不安全 (可以在源码中找到逻辑) |
| 扩容方式 + 扩容触发 + 扩容对象 + 插入后扩容 | 扩容方式:初始size为11,扩容:newsize = olesize*2+1 | (1)扩容方式:初始size为16,扩容:newsize = oldsize*2,size一定为2的n次幂;(2)数组扩容触发:扩容触发是负载极限,当Map中元素总数超过Entry数组的75%,触发扩容操作,为了减少链表长度,元素分配更均匀;(3)扩容对象:扩容对象是整个Map数组,每次扩容时,原来数组中的元素依次重新计算存放位置,并重新插入(4)插入后扩容:插入元素后才判断该不该扩容,有可能无效扩容(插入后如果扩容,如果没有再次插入,就会产生无效扩容) |
| 计算下标index(源码中可以看到) | index = (hash & 0x7FFFFFFF) % tab.length | index = hash & (tab.length – 1) |
| 迭代器Iterator、迭代器Enumerator,fast-fail,与线程安全一起记 | HashTable的enumerator迭代器不是fail-fast的。 | HashMap的迭代器(Iterator)是fail-fast迭代器,这里的fail-fast迭代器的意义是:所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。 |
| 相同点1:类结构 | HashMap是继承自AbstractMap类,而HashTable是继承自Dictionary类。不过它们都同时实现了Map(key-value键值对)、Cloneable(可复制)、Serializable(可序列化)这三个接口。 | |
| 相同点2:put/get操作:存储结构 | HashMap和HashTable存储的内容是基于key-value的键值对映射,不能有重复的key,而且一个key只能映射一个value。HashSet底层就是基于HashMap实现的。 | |
| 相同点2:put/get操作:HashMap put()与hashcode+equals() + get()与equals() | put()方法: 接收键值对参数,然后调用键对象的hashCode()方法来计算hashCode,然后找到相应的bucket位置(即数组)来储存值对象;get()方法:通过键对象的equals()方法找到正确的键值对,然后返回值对象 | |
| 相同点3:put/get操作:在HashMap和HashSet中,hashcode确定index,链表上equals相同认为相同 | HashMap在两个key-value,hashcode相同导致index相同,哈希冲突,equals相同认为同一个,不重复插入,HashSet在hashcode和equals相同,认为同一个,不重复插入 | |
3.2 TreeMap
TreeMap需要注意的三点:
key-value是否为null,和HashTable一样:
与HashMap不同的是,TreeMap键、值都不能为null;红黑树是排序二叉树:
TreeMap自定义排序器,底层如何实现排序:树中的每个节点的值都会大于或等于它的左子树中的所有节点的值,并且小于或等于它的右子树中的所有节点的值;红黑树是平衡二叉树-时间复杂度:
与HashMap不同的是它的get、put、remove之类操作都是O(log(n))的时间复杂度。
对TreeMap做成如下小结:
TreeMap是基于红黑树的一种提供顺序访问的Map,与HashMap不同的是它的get、put、remove之类操作都是o(log(n))的时间复杂度,具体顺序可以由指定的Comparator来决定,或者根据键的自然顺序来判断。
3.3 ConcurrentHashMap(核心:锁机制)
Java5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好,ConcurrentHashMap底层采用分段的数组+链表实现,是线程安全。
先看一下ConcurrentHashMap的类图:
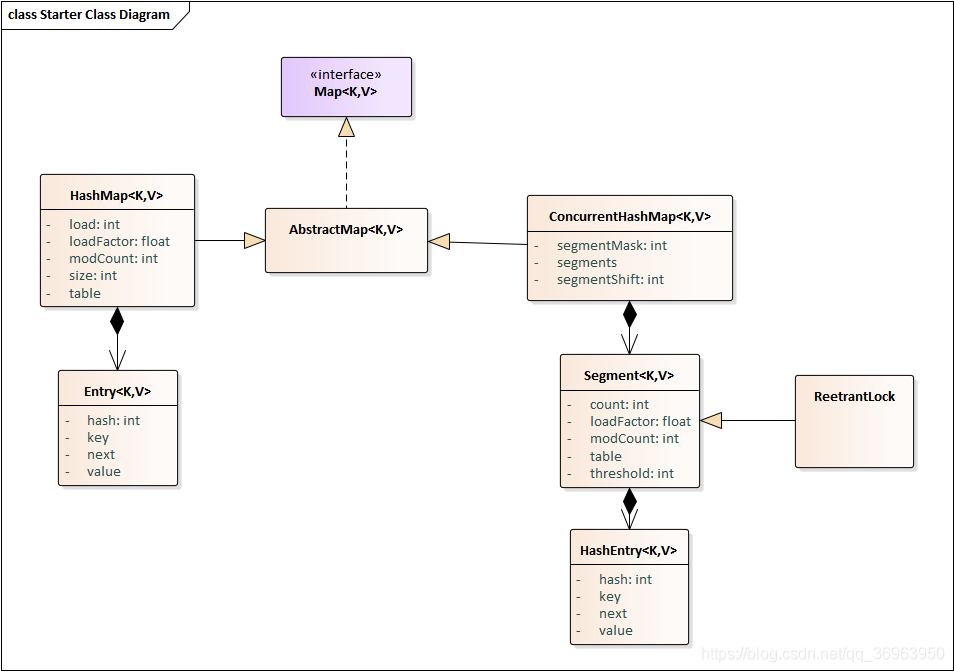
由上面类图,左边是HashMap,右边是ConcurrentHashMap,它都是继承自AbstractMap抽象类,但是,在存储结构中,ConcurrentHashMap比HashMap多出了一个类Segment,而Segment就是一个可重入锁,这个Segment就是ConcurrentHashMap实现分段锁的关键,ConcurrentHashMap也正是使用这种锁分段技术来保证线程安全的。
锁分段技术定义:首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
ConcurrentHashMap与HashTable的不同:
- HashTable中采用的锁机制是一次锁住整个hash表,从而在同一时刻只能由一个线程对其进行操作;而ConcurrentHashMap中则是一次锁住一个桶。
- ConcurrentHashMap默认将hash表分为16个桶,诸如get、put、remove等常用操作只锁住当前需要用到的桶。这样,原来只能一个线程进入,现在却能同时有16个写线程执行,并发性能的提升是显而易见的。
问题:ConcurrentHashMap是如何实现锁机制的?
回答:
- 实现上,Segment内部类实现分段:
ConcurrentHashMap具有一个内部类Segment,正是因为内部类Segment,将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问; - 实现上,ConcurrentHashMap分段锁就是Lock锁:
Segement extends ReentrantLock implements Serializable,所以说ConcurrentHashMap中的分段锁就是一种普通的Lock锁; - 方法上,段内方法,分段操作,性能提高16倍,get() put() remove():
ConcurrentHashMap默认将hash表分为16个桶,诸如get、put、remove等常用操作只锁住当前需要用到的桶。ConcurrentHashMap是HashTable的替代,HashTable中采用的锁机制是一次锁住整个hash表,从而在同一时刻只能由一个线程对其进行操作,而ConcurrentHashMap中则是一次锁住一个桶; - 方法上,扩容方法,分段锁实现段内扩容resize():
段内数组扩容(段内元素超过该段对应Entry数组长度的75%触发扩容,不会对整个Map进行扩容),插入前检测需不需要扩容,有效避免无效扩容; - 方法上,跨段方法,跨段方法size()和containsValue():
有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁; - 读不加锁、写加锁:
读操作不加锁,由于HashEntry的value变量是 volatile的,也能保证读取到最新的值。
3.4 HashTable/ConcurrentHashMap、HashMap、TreeMap
存储内容为key-value键值对:
存储的内容是基于key-value的键值对映射,不能有重复的key,而且一个key只能映射一个value。HashSet底层就是基于HashMap实现的。key、value是否为null:
HashTable的key、value都不能为null;TreeMap键、值都不能为null;HashMap的key、value可以为null,不过只能有一个key为null,但可以有多个null的value;HashTable、HashMap具有无序特性,TreeMap默认升序,可以自定义排序方式:
HashTable、HashMap具有无序特性,TreeMap是利用红黑树实现的(金手指:TreeMap自定义排序器,底层如何实现排序:树中的每个节点的值都会大于或等于它的左子树中的所有节点的值,并且小于或等于它的右子树中的所有节点的值),实现了SortMap接口,能够对保存的记录根据键进行排序。所以一般需求排序的情况下首选TreeMap,默认按键的升序排序(深度优先搜索),也可以自定义实现Comparator接口实现排序方式。选用原则:一般用HashMap,需要排序使用TreeMap,需要保证线程安全使用ConcurrentHashMap
一般情况下选用HashMap,因为HashMap的键值对在取出时是随机的,其依据键的hashCode和键的equals方法存取数据,具有很快的访问速度,所以在Map中插入、删除及索引元素时其是效率最高的实现。其他的,TreeMap的键值对在取出时是排过序的,效率会低一点,而HashTable/ConcurrentHashMap是线程安全的,效率也低一点。
四、小结
HashMap全解析,完成了。
天天打码,天天进步!!!
【Java集合框架002】原理层面:HashMap全解析的更多相关文章
- Java——集合框架之Set&HashSet,HashMap,泛型,compareTo
Set Set接口--数据存放无序,非常简单,主要呈现信息列表 Set接口存储一组唯一.无序的对象 HashSet是Set接口常用的实现类 Set接口不存在get方法 Iterator接口:表示对集合 ...
- java集合框架(1) hashMap 简单使用以及深度分析(转)
java.util 类 HashMap<K,V>java.lang.Object java.util.AbstractMap<K,V> java.util.Hash ...
- java集合框架使用原理分析
集合是我们日常编程中可能用的很多的技术之一 使用频率极高 可能平时就会知道怎么去用 但是集合之间的关系与不同之处都不是很清楚 对它们的底层原理更甚 所以写词文章 让自己有一个更深的认识 集合是一个庞大 ...
- java集合框架之java HashMap代码解析
java集合框架之java HashMap代码解析 文章Java集合框架综述后,具体集合类的代码,首先以既熟悉又陌生的HashMap开始. 源自http://www.codeceo.com/arti ...
- (转)Java集合框架:HashMap
来源:朱小厮 链接:http://blog.csdn.net/u013256816/article/details/50912762 Java集合框架概述 Java集合框架无论是在工作.学习.面试中都 ...
- Java集合框架:HashMap
转载: Java集合框架:HashMap Java集合框架概述 Java集合框架无论是在工作.学习.面试中都会经常涉及到,相信各位也并不陌生,其强大也不用多说,博主最近翻阅java集合框架的源码以 ...
- 【java集合框架源码剖析系列】java源码剖析之HashMap
前言:之所以打算写java集合框架源码剖析系列博客是因为自己反思了一下阿里内推一面的失败(估计没过,因为写此博客已距阿里巴巴一面一个星期),当时面试完之后感觉自己回答的挺好的,而且据面试官最后说的这几 ...
- Java集合框架详解(全)
一.Java集合框架概述 集合可以看作是一种容器,用来存储对象信息.所有集合类都位于java.util包下,但支持多线程的集合类位于java.util.concurrent包下. 数组与集合的区别如下 ...
- java集合框架(一):HashMap
有大半年没有写博客了,虽然一直有在看书学习,但现在回过来看读书基本都是一种知识“输入”,很多时候是水过无痕.而知识的“输出”会逼着自己去找出没有掌握或者了解不深刻的东西,你要把一个知识点表达出来,自己 ...
- Java集合框架之HashMap浅析
Java集合框架之HashMap浅析 一.HashMap综述: 1.1.HashMap概述 位于java.util包下的HashMap是Java集合框架的重要成员,它在jdk1.8中定义如下: pub ...
随机推荐
- 踩坑之旅:配置 ROS 环境
以下内容为本人的著作,如需要转载,请声明原文链接微信公众号「englyf」https://www.cnblogs.com/englyf/p/16660252.html 最近在学习机器人相关的导航算法, ...
- 《Java编程思想》读书笔记(五)
前言:本文是<Java编程思想>读书笔记系列的最后一章,本章的内容很多,需要细读慢慢去理解,文中的示例最好在自己电脑上多运行几次,相关示例完整代码放在码云上了,码云地址:https://g ...
- 使用脚本在FTP上传、下载文件
由于最近勒索病毒变种又一次爆发,公司内部封锁了TCP 445端口.导致原来通过文件共享的方式上传下载的计划任务无法执行.所以,我开设了FTP服务器来完成这个工作. 关于如何建立FTP服务器,请看这里 ...
- 输入法词库解析(六)QQ 拼音分类词库.qpyd
详细代码:https://github.com/cxcn/dtool 前言 .qpyd 是 QQ 拼音输入法 6.0 以下版本所用的词库格式,可以在 http://cdict.qq.pinyin.cn ...
- Scrum五大会议要怎么开?
在Scrum框架中,我们对Scrum的五个会议一定都不陌生,但如何组织这五个会议,才能让Scrum团队真正积极.主动地参与进项目管理中呢?接下来我们会以一个Sprint为周期,详细介绍一下Sprint ...
- Django 聚合查询 分组查询 F与Q查询
一.聚合查询 需要导入模块:from django.db.models import Max, Min, Sum, Count, Avg 关键语法:aggregate(聚合结果别名 = 聚合函数(参数 ...
- 【BotR】CLR类型系统
.NET运行时之书(Book of the Runtime,简称BotR)是一系列描述.NET运行时的文档,2007年左右在微软内部创建,最初目的是为了帮助其新员工快速上手.NET运行时:随着.NET ...
- [CG从零开始] 3. 安装 pyassimp 库加载模型文件
assimp 是一个开源的模型加载库,支持非常多的格式,还有许多语言的 binding,这里我们选用 assimp 的 python 的 binding 来加载模型文件.不过社区主要是在维护 assi ...
- POJ3342 Party at Hali-Bula(树形DP)
dp[u][0]表示不选u时在以u为根的子树中最大人数,dp[u][1]则是选了u后的最大人数: f[u][0]表示不选u时的唯一性,f[u][1]是选了u后的唯一性,值为1代表唯一,0代表不唯一. ...
- 220501 T1 困难的图论 (tarjan 点双)
求满足题目要求的简单环,做出图中所有的点双,用vector存储点双中的边,如果该点双满足点数=边数,就是我们想要的,求边的异或和即可:如果该点双点数小于边数,说明有不只一个环覆盖,不满足题意. 1 # ...