基于python的数学建模---灰色与模糊问题
instance:

我们先对此数据集进行轮廓系数的计算
from sklearn import metrics
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn import preprocessing
import pandas as pd def import_data_format_iris(file):
"""
file这里是输入文件的路径,如iris.txt.
格式化数据,前四列为data,最后一列为类标号(有0,1,2三类)
如果是你自己的data,就不需要执行此段函数了。
"""
data = []
cluster_location = []
with open(str(file), 'r') as f:
for line in f:
current = line.strip().split(",") # 对每一行以逗号为分割,返回一个list
current_dummy = []
for j in range(0, len(current) - 1):
current_dummy.append(float(current[j])) # current_dummy存放data
j += 1
# 下面注这段话提供了一个范例:若类标号不是0,1,2之类数字时该怎么给数据集
# 归类
if current[j] == "Iris-setosa\n":
cluster_location.append(0)
elif current[j] == "Iris-versicolor\n":
cluster_location.append(1)
else:
cluster_location.append(2)
data.append(current_dummy)
print("加载数据完毕")
return data # data = pd.read_csv('C:\\Users\\Style\\Desktop\\Iris.csv')
data = import_data_format_iris('C:\\Users\\Style\\Desktop\\Iris.csv')
info_scaled = preprocessing.scale(data)
X = info_scaled
score = []
for i in range(2, 18):
km = KMeans(n_clusters=i, init='k-means++', n_init=10, max_iter=300, random_state=0)
km.fit(X)
score.append(metrics.silhouette_score(X, km.labels_, metric='euclidean'))
plt.figure(dpi=150)
plt.plot(range(2, 18), score, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('silhouette_score')
plt.show()
得到图像
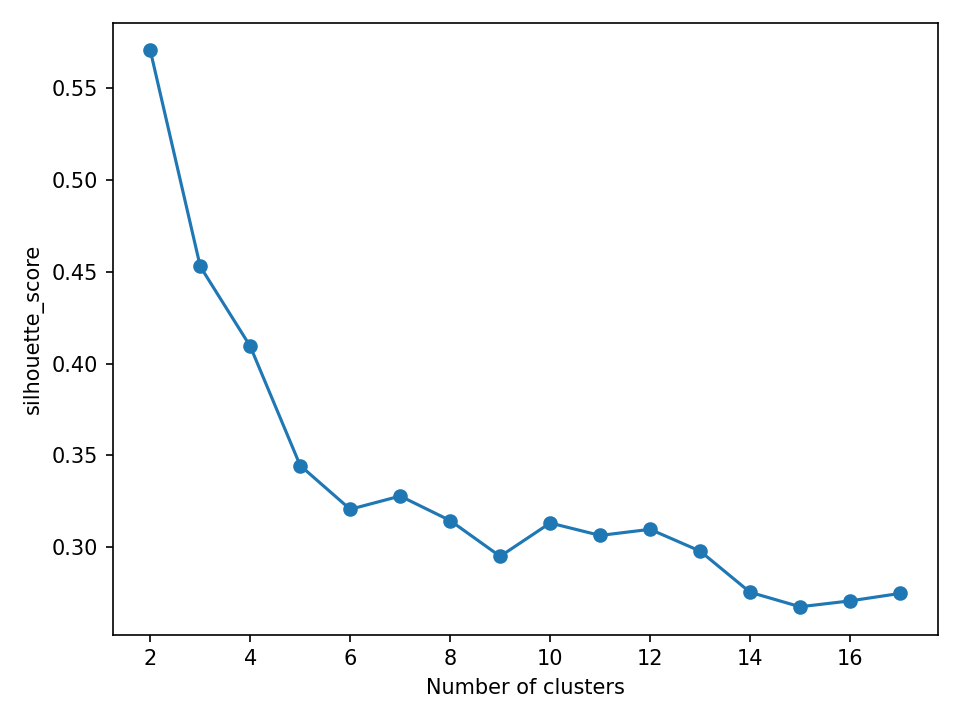
看得出来 当簇数为2的时候点最高
接下来 用模糊C均值聚类
import copy
import math
import random
import time global MAX # 用于初始化隶属度矩阵U
MAX = 10000.0 global Epsilon # 结束条件
Epsilon = 0.0000001 def import_data_format_iris(file):
"""
file这里是输入文件的路径,如iris.txt.
格式化数据,前四列为data,最后一列为类标号(有0,1,2三类)
如果是你自己的data,就不需要执行此段函数了。
"""
data = []
cluster_location = []
with open(str(file), 'r') as f:
for line in f:
current = line.strip().split(",") # 对每一行以逗号为分割,返回一个list
current_dummy = []
for j in range(0, len(current) - 1):
current_dummy.append(float(current[j])) # current_dummy存放data
j += 1
# 下面注这段话提供了一个范例:若类标号不是0,1,2之类数字时该怎么给数据集
# 归类
if current[j] == "Iris-setosa\n":
cluster_location.append(0)
elif current[j] == "Iris-versicolor\n":
cluster_location.append(1)
else:
cluster_location.append(2)
data.append(current_dummy)
print("加载数据完毕")
return data # return data , cluster_location def randomize_data(data):
"""
该功能将数据随机化,并保持随机化顺序的记录
"""
order = list(range(0, len(data)))
random.shuffle(order)
new_data = [[] for i in range(0, len(data))]
for index in range(0, len(order)):
new_data[index] = data[order[index]]
return new_data, order def de_randomise_data(data, order):
"""
此函数将返回数据的原始顺序,将randomise_data()返回的order列表作为参数
"""
new_data = [[] for i in range(0, len(data))]
for index in range(len(order)):
new_data[order[index]] = data[index]
return new_data def print_matrix(list):
"""
以可重复的方式打印矩阵
"""
for i in range(0, len(list)):
print(list[i]) def initialize_U(data, cluster_number):
"""
这个函数是隶属度矩阵U的每行加起来都为1. 此处需要一个全局变量MAX.
"""
global MAX
U = []
for i in range(0, len(data)):
current = []
rand_sum = 0.0
for j in range(0, cluster_number):
dummy = random.randint(1, int(MAX))
current.append(dummy)
rand_sum += dummy
for j in range(0, cluster_number):
current[j] = current[j] / rand_sum
U.append(current)
return U def distance(point, center):
"""
该函数计算2点之间的距离(作为列表)。我们指欧几里德距离。闵可夫斯基距离
"""
if len(point) != len(center):
return -1
dummy = 0.0
for i in range(0, len(point)):
dummy += abs(point[i] - center[i]) ** 2
return math.sqrt(dummy) def end_conditon(U, U_old):
"""
结束条件。当U矩阵随着连续迭代停止变化时,触发结束
"""
global Epsilon
for i in range(0, len(U)):
for j in range(0, len(U[0])):
if abs(U[i][j] - U_old[i][j]) < Epsilon:
return False
return True def normalise_U(U):
"""
在聚类结束时使U模糊化。每个样本的隶属度最大的为1,其余为0
"""
for i in range(0, len(U)):
maximum = max(U[i])
for j in range(0, len(U[0])):
if U[i][j] != maximum:
U[i][j] = 0
else:
U[i][j] = 1
return U # m的最佳取值范围为[1.5,2.5]
def fuzzy(data, cluster_number, m):
"""
这是主函数,它将计算所需的聚类中心,并返回最终的归一化隶属矩阵U.
参数是:簇数(cluster_number)和隶属度的因子(m)
"""
# 初始化隶属度矩阵U
U = initialize_U(data, cluster_number)
# print_matrix(U)
# 循环更新U
while (True):
# 创建它的副本,以检查结束条件
U_old = copy.deepcopy(U)
# 计算聚类中心
C = []
for j in range(0, cluster_number):
current_cluster_center = []
for i in range(0, len(data[0])):
dummy_sum_num = 0.0
dummy_sum_dum = 0.0
for k in range(0, len(data)):
# 分子
dummy_sum_num += (U[k][j] ** m) * data[k][i]
# 分母
dummy_sum_dum += (U[k][j] ** m)
# 第i列的聚类中心
current_cluster_center.append(dummy_sum_num / dummy_sum_dum)
# 第j簇的所有聚类中心
C.append(current_cluster_center) # 创建一个距离向量, 用于计算U矩阵。
distance_matrix = []
for i in range(0, len(data)):
current = []
for j in range(0, cluster_number):
current.append(distance(data[i], C[j]))
distance_matrix.append(current) # 更新U
for j in range(0, cluster_number):
for i in range(0, len(data)):
dummy = 0.0
for k in range(0, cluster_number):
# 分母
dummy += (distance_matrix[i][j] / distance_matrix[i][k]) ** (2 / (m - 1))
U[i][j] = 1 / dummy if end_conditon(U, U_old):
print("结束聚类")
break
print("标准化 U")
U = normalise_U(U)
return U def checker_iris(final_location):
"""
和真实的聚类结果进行校验比对
"""
right = 0.0
for k in range(0, 3):
checker = [0, 0, 0]
for i in range(0, 50):
for j in range(0, len(final_location[0])):
if final_location[i + (50 * k)][j] == 1: # i+(50*k)表示 j表示第j类
checker[j] += 1 # checker分别统计每一类分类正确的个数
right += max(checker) # 累加分类正确的个数
print('分类正确的个数是:', right)
answer = right / 150 * 100
return "准确率:" + str(answer) + "%" if __name__ == '__main__':
# 加载数据
data = import_data_format_iris("C:\\Users\\Style\\Desktop\\Iris.csv")
# print_matrix(data) # 随机化数据
data, order = randomize_data(data)
# print_matrix(data) start = time.time()
# 现在我们有一个名为data的列表,它只是数字
# 我们还有另一个名为cluster_location的列表,它给出了正确的聚类结果位置
# 调用模糊C均值函数
final_location = fuzzy(data, 2, 2) # 还原数据
final_location = de_randomise_data(final_location, order)
# print_matrix(final_location) # 准确度分析
print(checker_iris(final_location))
print("用时:{0}".format(time.time() - start))
得到
加载数据完毕
结束聚类
标准化 U
分类正确的个数是: 126.0
准确率:84.0%
用时:0.0029931068420410156
基于python的数学建模---灰色与模糊问题的更多相关文章
- 使用Python scipy linprog 线性规划求最大值或最小值(使用Python学习数学建模笔记)
函数格式 scipy.optimize.linprog(c, A_ub=None, b_ub=None, A_eq=None, b_eq=None, bounds=None, method='simp ...
- 数学建模-灰色预测模型GM(1,1)_MATLAB
GM(1,1).m %建立符号变量a(发展系数)和b(灰作用量) syms a b; c = [a b]'; %原始数列 A A = [174, 179, 183, 189, 207, 234, 22 ...
- Python数学建模-01.新手必读
Python 完全可以满足数学建模的需要. Python 是数学建模的最佳选择之一,而且在其它工作中也无所不能. 『Python 数学建模 @ Youcans』带你从数模小白成为国赛达人. 1. 数学 ...
- Python数学建模-02.数据导入
数据导入是所有数模编程的第一步,比你想象的更重要. 先要学会一种未必最佳,但是通用.安全.简单.好学的方法. 『Python 数学建模 @ Youcans』带你从数模小白成为国赛达人. 1. 数据导入 ...
- Python小白的数学建模课-A1.国赛赛题类型分析
分析赛题类型,才能有的放矢. 评论区留下邮箱地址,送你国奖论文分析 『Python小白的数学建模课 @ Youcans』 带你从数模小白成为国赛达人. 1. 数模竞赛国赛 A题类型分析 年份 题目 要 ...
- Python小白的数学建模课-A3.12 个新冠疫情数模竞赛赛题与点评
新冠疫情深刻和全面地影响着社会和生活,已经成为数学建模竞赛的背景帝. 本文收集了与新冠疫情相关的的数学建模竞赛赛题,供大家参考,欢迎收藏关注. 『Python小白的数学建模课 @ Youcans』带你 ...
- Python小白的数学建模课-07 选址问题
选址问题是要选择设施位置使目标达到最优,是数模竞赛中的常见题型. 小白不一定要掌握所有的选址问题,但要能判断是哪一类问题,用哪个模型. 进一步学习 PuLP工具包中处理复杂问题的字典格式快捷建模方法. ...
- Python小白的数学建模课-09 微分方程模型
小白往往听到微分方程就觉得害怕,其实数学建模中的微分方程模型不仅没那么复杂,而且很容易写出高水平的数模论文. 本文介绍微分方程模型的建模与求解,通过常微分方程.常微分方程组.高阶常微分方程 3个案例手 ...
- Python小白的数学建模课-B5. 新冠疫情 SEIR模型
传染病的数学模型是数学建模中的典型问题,常见的传染病模型有 SI.SIR.SIRS.SEIR 模型. 考虑存在易感者.暴露者.患病者和康复者四类人群,适用于具有潜伏期.治愈后获得终身免疫的传染病. 本 ...
- Python小白的数学建模课-B6. 新冠疫情 SEIR 改进模型
传染病的数学模型是数学建模中的典型问题,常见的传染病模型有 SI.SIR.SIRS.SEIR 模型. SEIR 模型考虑存在易感者.暴露者.患病者和康复者四类人群,适用于具有潜伏期.治愈后获得终身免疫 ...
随机推荐
- 华南理工大学 Python第6章课后测验-2
1.(单选)以下关于语句 a = [1,2,3,(4,5)]的说法中,正确的个数有( )个.(1)a是元组类型 (2)a是列表类型 (3)a有5个元素 (4)a有4个元素(5)a[1] ...
- 第一个HTML
第一个HTML <!DOCTYPE html><!--html 文件开始--><html lang="en"><!--head 文件头-- ...
- 阿里云SLB的http强制转https
公司的要求:要求强制http转https 我的环境是: 域名<--->slb的ip<-->源服务器nginx 具体做法是: 第一步:证书放到slb的https上,通过443端口 ...
- Centos7主机安装Cockpit管理其他主机
前提条件:需要管理的每台服务器上都需要安装cockpit 假设Centos7主机安装Cockpit的为A,其他主机为B 如果B上有A的公钥,那么直接连接至B,否则,输入B的用户名密码连接. 问题:在A ...
- 延申三大问题中的第三个问题处理---发布更新时先把服务从注册中心给down下来,等待一段时间后再能更新模块
一开始采取的思路大致如下: 在preStop中使用/bin/sh命令,先down 然后sleep一段时间, 这种思路的执行情况如下: 假若升级容器使用的镜像版本的话,先执行preStop中的命令,sl ...
- NSIS安装界面无虚线框移动
最近很多应用程序都在安装界面的美化上面下足了功夫,一个漂亮流畅的安装界面无疑会给其带来用户体验上的加分,其中一个无虚线框跟随鼠标移动比较有趣,狂翻msdn后终于找到了控制函数SystemParamet ...
- 关于aws cli命令的exit/return code分析
最近总是收到一个备份脚本的失败邮件,脚本是之前同事写的,没有加入任何有调试信息,及有用的日志 于是去分析 ,脚本中有一条 aws s3 sync $srclocal $dsts3 命令,然后根据这条 ...
- Nginx代理和动静分离
Nginx代理 微服务项目可能需要 Nginx来实现反向代理,用户请求 Nginx,随后 Nginx将请求转发至 Gateway网关,再由网关转至具体的微服务 一.动态代理 1.1 网关配置 针对使用 ...
- 从零开始学Graph Database:什么是图
摘要:本文从零开始引导与大家一起学习图知识.希望大家可以通过本教程学习如何使用图数据库与图计算引擎.本篇将以华为云图引擎服务来辅助大家学习如何使用图数据库与图计算引擎. 本文分享自华为云社区<从 ...
- C#中ref和out关键字的应用以及区别
首先:两者都是按地址传递的,使用后都将改变原来参数的数值. 其次:ref可以把参数的数值传递进函数,但是out是要把参数清空,就是说你无法把一个数值从out传递进去的,out进去后,参数的数值为空,所 ...