Hash-题解-方法
有效的字母异位词
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
示例 1: 输入: s = "anagram", t = "nagaram" 输出: true
示例 2: 输入: s = "rat", t = "car" 输出: false
说明: 你可以假设字符串只包含小写字母。
数组其实就是一个简单哈希表,而且这道题目中字符串只有小写字符,那么就可以定义一个数组,来记录字符串s里字符出现的次数。
需要定义一个多大的数组呢,定一个数组叫做record,大小为26 就可以了,初始化为0,因为字符a到字符z的ASCII也是26个连续的数值。
需要把字符映射到数组也就是哈希表的索引下表上,因为字符a到字符z的ASCII是26个连续的数值,所以字符a映射为下表0,相应的字符z映射为下表25。
再遍历 字符串s的时候,只需要将 s[i] - ‘a’ 所在的元素做+1 操作即可,并不需要记住字符a的ASCII,只要求出一个相对数值就可以了。 这样就将字符串s中字符出现的次数,统计出来了。
那看一下如何检查字符串t中是否出现了这些字符,同样在遍历字符串t的时候,对t中出现的字符映射哈希表索引上的数值再做-1的操作。
那么最后检查一下,record数组如果有的元素不为零0,说明字符串s和t一定是谁多了字符或者谁少了字符,return false。
最后如果record数组所有元素都为零0,说明字符串s和t是字母异位词,return true。
时间复杂度为O(n),空间上因为定义是的一个常量大小的辅助数组,所以空间复杂度为O(1)。
class Solution {
public boolean isAnagram(String s, String t) {
int[] record = new int[26];
for (char c : s.toCharArray()) {
record[c - 'a'] += 1;
}
for (char c : t.toCharArray()) {
record[c - 'a'] -= 1;
}
for (int i : record) {
if (i != 0) {
return false;
}
}
return true;
}
}
两个数组的交集
import java.util.HashSet;
import java.util.Set;
class Solution {
public int[] intersection(int[] nums1, int[] nums2) {
if (nums1 == null || nums1.length == 0 || nums2 == null || nums2.length == 0) {
return new int[0];
}
Set<Integer> set1 = new HashSet<>();
Set<Integer> resSet = new HashSet<>();
//遍历数组1
for (int i : nums1) {
set1.add(i);
}
//遍历数组2的过程中判断哈希表中是否存在该元素
for (int i : nums2) {
if (set1.contains(i)) {
resSet.add(i);
}
}
int[] resArr = new int[resSet.size()];
int index = 0;
//将结果几何转为数组
for (int i : resSet) {
resArr[index++] = i;
}
return resArr;
}
}
利用 set 达到一个去重的效果,但是,数据量太大的话 ,效率不好。
快乐数
「快乐数」定义为:对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和,然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。如果 可以变为 1,那么这个数就是快乐数。
示例:
输入:19
输出:true
解释:
1^2 + 9^2 = 82
8^2 + 2^2 = 68
6^2 + 8^2 = 100
1^2 + 0^2 + 0^2 = 1
当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法了。
class Solution {
public boolean isHappy(int n) {
Set<Integer> record = new HashSet<>();
while (n != 1 && !record.contains(n)) {
record.add(n);
n = getNextNumber(n);
}
return n == 1;
}
private int getNextNumber(int n) {
int res = 0;
while (n > 0) {
int temp = n % 10;
res += temp * temp;
n = n / 10;
}
return res;
}
}
两数之和
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
用数组和set来做哈希法的局限。
- 数组的大小是受限制的,而且如果元素很少,而哈希值太大会造成内存空间的浪费。
- set是一个集合,里面放的元素只能是一个key,而两数之和这道题目,不仅要判断y是否存在而且还要记录y的下表位置,因为要返回x 和 y的下表。所以set 也不能用。
此时就要选择另一种数据结构:map ,map是一种key value的存储结构,可以用key保存数值,用value在保存数值所在。

四数相加II
给定四个包含整数的数组列表 A , B , C , D ,计算有多少个元组 (i, j, k, l) ,使得 A[i] + B[j] + C[k] + D[l] = 0。
为了使问题简单化,所有的 A, B, C, D 具有相同的长度 N,且 0 ≤ N ≤ 500 。所有整数的范围在 -2^28 到 2^28 - 1 之间,最终结果不会超过 2^31 - 1 。
例如:
输入: A = [ 1, 2] B = [-2,-1] C = [-1, 2] D = [ 0, 2] 输出: 2
解释: 两个元组如下:
- (0, 0, 0, 1) -> A[0] + B[0] + C[0] + D[1] = 1 + (-2) + (-1) + 2 = 0
- (1, 1, 0, 0) -> A[1] + B[1] + C[0] + D[0] = 2 + (-1) + (-1) + 0 = 0
本题解题步骤:
- 首先定义 一个map,key放a和b两数之和,value 放a和b两数之和出现的次数。
- 遍历大A和大B数组,统计两个数组元素之和,和出现的次数,放到map中。
- 定义int变量count,用来统计a+b+c+d = 0 出现的次数。
- 在遍历大C和大D数组,找到如果 0-(c+d) 在map中出现过的话,就用count把map中key对应的value也就是出现次数统计出来。
- 最后返回统计值 count 就可以了
class Solution {
public int fourSumCount(int[] nums1, int[] nums2, int[] nums3, int[] nums4) {
Map<Integer, Integer> map = new HashMap<>();
int temp;
int res = 0;
//统计两个数组中的元素之和,同时统计出现的次数,放入map
for (int i : nums1) {
for (int j : nums2) {
temp = i + j;
if (map.containsKey(temp)) {
map.put(temp, map.get(temp) + 1);
} else {
map.put(temp, 1);
}
}
}
//统计剩余的两个元素的和,在map中找是否存在相加为0的情况,同时记录次数
for (int i : nums3) {
for (int j : nums4) {
temp = i + j;
if (map.containsKey(0 - temp)) {
res += map.get(0 - temp);
}
}
}
return res;
}
}
赎金信
给定一个赎金信 (ransom) 字符串和一个杂志(magazine)字符串,判断第一个字符串 ransom 能不能由第二个字符串 magazines 里面的字符构成。
如果可以构成,返回 true ;否则返回 false。
(题目说明:为了不暴露赎金信字迹,要从杂志上搜索各个需要的字母,组成单词来表达意思。杂志字符串中的每个字符只能在赎金信字符串中使用一次。)
注意:
你可以假设两个字符串均只含有小写字母。
canConstruct("a", "b") -> false
canConstruct("aa", "ab") -> false
canConstruct("aa", "aab") -> true
因为题目所只有小写字母,那可以采用空间换取时间的哈希策略, 用一个长度为26的数组还记录magazine里字母出现的次数。
然后再用ransomNote去验证这个数组是否包含了ransomNote所需要的所有字母。
依然是数组在哈希法中的应用。
一些同学可能想,用数组干啥,都用map完事了,其实在本题的情况下,使用map的空间消耗要比数组大一些的,因为map要维护红黑树或者哈希表,而且还要做哈希函数,是费时的!数据量大的话就能体现出来差别了。 所以数组更加简单直接有效!
class Solution {
public boolean canConstruct(String ransomNote, String magazine) {
//记录杂志字符串出现的次数
int[] arr = new int[26];
int temp;
for (int i = 0; i < magazine.length(); i++) {
temp = magazine.charAt(i) - 'a';
arr[temp]++;
}
for (int i = 0; i < ransomNote.length(); i++) {
temp = ransomNote.charAt(i) - 'a';
//对于金信中的每一个字符都在数组中查找
//找到相应位减一,否则找不到返回false
if (arr[temp] > 0) {
arr[temp]--;
} else {
return false;
}
}
return true;
}
}
三数之和
给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有满足条件且不重复的三元组。
注意: 答案中不可以包含重复的三元组。
示例:
给定数组 nums = [-1, 0, 1, 2, -1, -4],
满足要求的三元组集合为: [ [-1, 0, 1], [-1, -1, 2] ]
其实这道题目使用哈希法并不十分合适,因为在去重的操作中有很多细节需要注意,在面试中很难直接写出没有bug的代码。
而且使用哈希法 在使用两层for循环的时候,能做的剪枝操作很有限,虽然时间复杂度是O(n^2),也是可以在leetcode上通过,但是程序的执行时间依然比较长 。
接下来我来介绍另一个解法:双指针法,这道题目使用双指针法 要比哈希法高效一些。
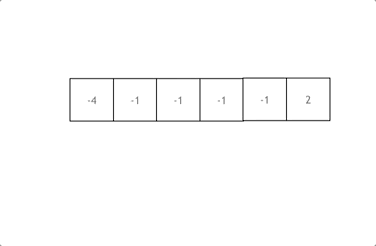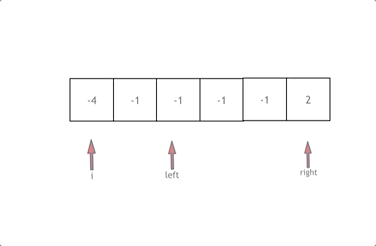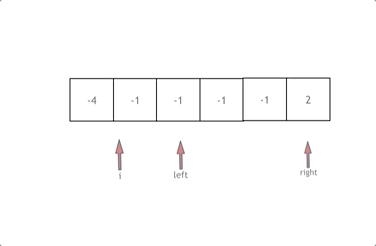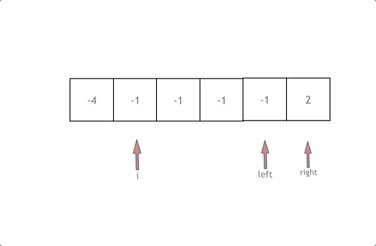
解释:
拿这个nums数组来举例,首先将数组排序,然后有一层for循环,i从下标0的地方开始,同时定一个下标left 定义在i+1的位置上,定义下标right 在数组结尾的位置上。
依然还是在数组中找到 abc 使得a + b +c =0,我们这里相当于 a = nums[i] b = nums[left] c = nums[right]。
接下来如何移动left 和right呢, 如果nums[i] + nums[left] + nums[right] > 0 就说明 此时三数之和大了,因为数组是排序后了,所以right下标就应该向左移动,这样才能让三数之和小一些。
如果 nums[i] + nums[left] + nums[right] < 0 说明 此时 三数之和小了,left 就向右移动,才能让三数之和大一些,直到left与right相遇为止。
时间复杂度:O(n^2)。
class Solution {
public List<List<Integer>> threeSum(int[] nums) {
List<List<Integer>> result = new ArrayList<>();
Arrays.sort(nums);
for (int i = 0; i < nums.length; i++) {
if (nums[i] > 0) {
return result;
}
if (i > 0 && nums[i] == nums[i - 1]) {
continue;
}
int left = i + 1;
int right = nums.length - 1;
while (right > left) {
int sum = nums[i] + nums[left] + nums[right];
if (sum > 0) {
right--;
} else if (sum < 0) {
left++;
} else {
result.add(Arrays.asList(nums[i], nums[left], nums[right]));
while (right > left && nums[right] == nums[right - 1]) right--;
while (right > left && nums[left] == nums[left + 1]) left++;
right--;
left++;
}
}
}
return result;
}
}
Hash-题解-方法的更多相关文章
- 海量数据挖掘MMDS week2: 频繁项集挖掘 Apriori算法的改进:基于hash的方法
http://blog.csdn.net/pipisorry/article/details/48901217 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- 内网技巧-通过SAM数据库获得本地用户hash的方法
内网技巧-通过SAM数据库获得本地用户hash的方法 在windows上的C:\Windows\System32\config目录保存着当前用户的密码hash.我们可以使用相关手段获取该hash. 提 ...
- MySQL提权之user.MYD中hash破解方法
经常在服务器提权的时候,尤其是windows环境下,我们发现权限不高,却可以读取mysql的datadir目录,并且能够成功下载user.MYD这个文件.但是在读取内容的时候,经常会遇到root密码h ...
- 解决hash冲突方法
转自:https://www.cnblogs.com/wuchaodzxx/p/7396599.html 目录 开放定址法 线性探测再散列 二次探测再散列 伪随机探测再散列 再哈希法 链地址法 建立公 ...
- windows 2003 域控服务器导出全部hash的方法
天下文章一大抄,我也是醉了... 一份“错误”的文章一遍又一遍的被转载,盲目转载,根本不细看.只会误导新手. 谈下windows2003域控下如何导出全部的hash信息. 1. 使用备份还原向导 2. ...
- webqq 获得好友列表hash算法 获得最新hash的方法
webqq获得好友列表的hash算法,大约每一个月中旬会变动一次.知道怎么获得他就能够了. js文件路径 http://web.qstatic.com/webqqpic/pubapps/0/50/eq ...
- 离线提取域控HASH的方法
1.注册表提取 提取文件,Windows Server 2003或者Win XP 及以前需要提升到system权限,以后只要Administrator权限即可. reg save hklm\sam s ...
- 简单使用location.hash的方法 ,怎么做,有什么用? 简单的js路由页面方法。
hash 属性是一个可读可写的字符串,该字符串是URL的锚部分(从#号开始的部分).语法location.hash刚开始我真不知道hash有什么用,直到我在项目中遇上一个最大的问题.而且很恶心的体验 ...
- windows 2003 windows 2008 windows 2012 导出域控hash的方法
quarkspwdump作者介绍的用法: 1. Windows 2008 Microsoft recently implements VSS (Volume Shadow Copy Ser ...
- $.ajax()方法详解 ajax之async属性 【原创】详细案例解剖——浅谈Redis缓存的常用5种方式(String,Hash,List,set,SetSorted )
$.ajax()方法详解 jquery中的ajax方法参数总是记不住,这里记录一下. 1.url: 要求为String类型的参数,(默认为当前页地址)发送请求的地址. 2.type: 要求为Str ...
随机推荐
- kkFileView部署到windows服务出现问题解决
1.部署之后执行出现api-ms-win-crt-runtime-l1-1-0.dll丢失的办法 微软官网下载vc_redist.x64.exe vc_redist.x86.exe 64位的操作系统需 ...
- LGP4463题解
这玩意儿怎么看上去就很经典啊( 哦互不相同啊,那没事了( 考虑一个 \(\rm DP\).由于限制了互不相同,那么我们考虑从值域开始想. 设 \(dp_{n,k}\) 为在 \([1,n]\) 中选了 ...
- 使用WebService的优点
1.支持跨平台,跨语言,远程调用 WSDL:web service definition language 直译 webservice定义语言 对应一种类型的文件.wsdl2.定义了web servi ...
- 放在initramfs的ko会先加载,还是/lib/modules/下面的ko会先加载?
如果是在switchroot时加载,用的是initramfs,在switchroot后,用的是硬盘上的,有些ko放到initramfs中,但是switchroot前不加载的话,用的还是硬盘上的,关键看 ...
- 三层PetShop架构设计
<解剖 PetShop >系列之一 前言: PetShop 是一个范例,微软用它来展示 .Net 企业系统开发的能力.业界有许多 .Net 与 J2EE 之争,许多数据是从微软的 Pe ...
- CodeForces Round #760 (Div. 3)
A. Polycarp and Sums of Subsequences 题目大意: 给七个不降序的数字,为三个数组合后得到的七种答案,求原来的三个数是哪些 思路: 由样例不难发现,第一个一定是三个数 ...
- 题解P0006:生日蛋糕(P1731)
这道题居然是1999年省选题!这可能是洛谷蓝题里最水的了... 题目链接:https://www.luogu.com.cn/problem/P1731 大家有兴趣可以去看看 题目描述:就是类似这样一个 ...
- (数据科学学习手札135)tenacity:Python中最强大的错误重试库
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 我们在编写程序尤其是与网络请求相关的程序, ...
- Mysql之B+树索引实战
索引代价 空间上的代价 一个索引都对应一棵B+树,树中每一个节点都是一个数据页,一个页默认会占用16KB的存储空间,所以一个索引也是会占用磁盘空间的. 时间上的代价 索引是对数据的排序,那么当对表中的 ...
- vue自定义指令?
除核心指令之外的指令, 使用directive进行注册. 指令自定义钩子函数: bind, inserted, update, componentUpdated, unbind