KNN算法之集美大学
在本篇文章中,我即将以在集美大学收集到的一些数据集为基础,使用KNN算法进行一系列的操作
一、KNN算法
首先,什么是KNN算法呢,这得用到老祖宗说的一句话“近朱者赤近墨者黑”,简单来讲就是,一个物体它靠近什么,我们也可以认为它就是什么。此算法运用广泛,生活中就有体现。比如,你是否发现,你好朋友刷到的抖音视频,你也可能提前刷到过,这就是KNN。
KNN也叫K近邻(K-Nearest Neighbor, KNN)是一种最经典和最简单的有监督学习方法之一。K-近邻算法是最简单的分类器,没有显式的学习过程或训练过程,是懒惰学习(Lazy Learning)。当对数据的分布只有很少或者没有任何先验知识时,K 近邻算法是一个不错的选择。
二、K自制数据集(基于集美大学)
集美大学于1918年始建,这所大学的名字很有意思,单纯从字面上看,这是一所集美丽于一身的大学。集美大学也正如名字所说,不仅学校美,周围的环境也跟着美。因为这所大学所在的地区被当地叫做集美学村,这个集美学村是一个旅游区,其中还包含了许多学府,从小学到大学一应俱全,集美大学就在其中,这里给人的感觉很大很美,既适合出行旅游观光,又是学术氛围浓厚之地。在集美大学读书感觉犹如在旅游一般,对于学生来说是一种美好的享受。
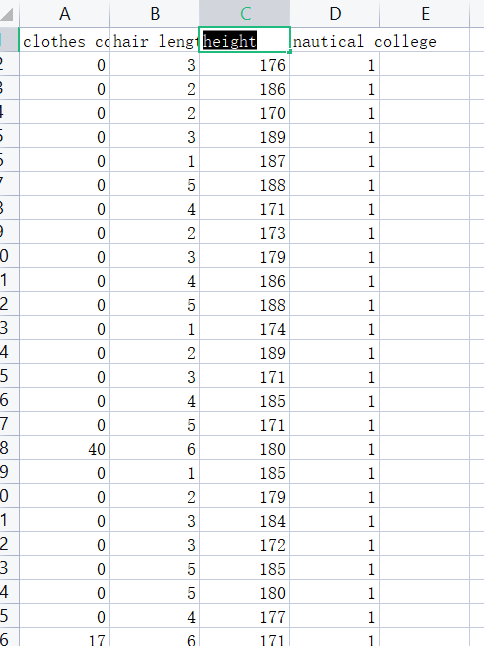
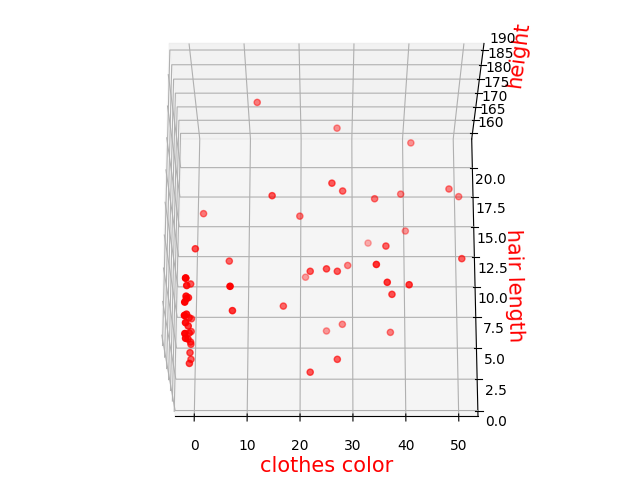
众所周知,航海是集美大学的特色专业,我运用Excel手动制作了一些数据,内容为航海学院和其他学院的学生数据差异。航海学院纪律严格,判断一个学生是不是航海学院的学子可以从以下角度分析:clothes color(航海学院身穿制度,颜色较为统一),hair length,height。如果是航海学院则nautical college置为1。还有数据三维散点图如下。

三、代码部分(主要运用了sklearn,pandas工具包)
1.预测
file = "sklearn/file/JMU.csv"
data = pd.read_csv(file)
lable = data.iloc[:, -1]
feature = data.iloc[:, :3]
# 2.划分数据集
x_train, x_test, y_train, y_test = train_test_split(feature, lable, test_size=0.2)
#网格搜索和交叉验证
para_dic={"n_neighbors":[i for i in range(1,20)]}
estimator=KNeighborsClassifier()
estimator=GridSearchCV(estimator,param_grid=para_dic)
estimator.fit(x_train,y_train)
# 模型评估
#1.比对真实值与预测值
# y_pre=estimator.predict(x_test)
# print("y_pre:\n",y_pre)
# print(y_pre==y_test)
#2.计算准确率
score=estimator.score(x_test,y_test)
print("准确率:\n",score) # 最佳参数
print("最佳参数:\n",estimator.best_params_)
# 最佳结果
print("最佳结果:\n",estimator.best_score_)
# 最佳估计器
print("最佳估计器:\n",estimator.best_estimator_)
准确率:
0.9166666666666666
最佳参数:
{'n_neighbors': 1}
最佳结果:
0.8936170212765957
最佳估计器:
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')
Process finished with exit code 0
2.作图
x = data.iloc[:, 0]
y = data.iloc[:, 1]
z = data.iloc[:, 2]
# 绘制散点图
fig = plt.figure()
ax = Axes3D(fig)
ax.scatter(x, y, z, color='r') # 添加坐标轴(顺序是Z, Y, X)
ax.set_zlabel('height', fontdict={'size': 15, 'color': 'red'})
ax.set_ylabel('hair length', fontdict={'size': 15, 'color': 'red'})
ax.set_xlabel('clothes color', fontdict={'size': 15, 'color': 'red'})
plt.show()
3.结果分析
通过网格搜索1到20的K值结果可知,最优K取值为1。也就是说找最近的一位同学是否属于航海学院,就能大概率判断这位未知同学是否也为海院学子。
思考,为什么会是K=1呢,通过散点图可以清楚看出,海院学子特征比较集中,所以只要距离海院学子特征最近,就大概率为海院学子。
KNN算法之集美大学的更多相关文章
- 【Machine Learning】KNN算法虹膜图片识别
K-近邻算法虹膜图片识别实战 作者:白宁超 2017年1月3日18:26:33 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
- KNN算法
1.算法讲解 KNN算法是一个最基本.最简单的有监督算法,基本思路就是给定一个样本,先通过距离计算,得到这个样本最近的topK个样本,然后根据这topK个样本的标签,投票决定给定样本的标签: 训练过程 ...
- kNN算法python实现和简单数字识别
kNN算法 算法优缺点: 优点:精度高.对异常值不敏感.无输入数据假定 缺点:时间复杂度和空间复杂度都很高 适用数据范围:数值型和标称型 算法的思路: KNN算法(全称K最近邻算法),算法的思想很简单 ...
- 什么是 kNN 算法?
学习 machine learning 的最低要求是什么? 我发觉要求可以很低,甚至初中程度已经可以. 首先要学习一点 Python 编程,譬如这两本小孩子用的书:[1][2]便可. 数学方面 ...
- 数据挖掘之KNN算法(C#实现)
在十大经典数据挖掘算法中,KNN算法算得上是最为简单的一种.该算法是一种惰性学习法(lazy learner),与决策树.朴素贝叶斯这些急切学习法(eager learner)有所区别.惰性学习法仅仅 ...
- 机器学习笔记--KNN算法2-实战部分
本文申明:本系列的所有实验数据都是来自[美]Peter Harrington 写的<Machine Learning in Action>这本书,侵删. 一案例导入:玛利亚小姐最近寂寞了, ...
- 机器学习笔记--KNN算法1
前言 Hello ,everyone. 我是小花.大四毕业,留在学校有点事情,就在这里和大家吹吹我们的狐朋狗友算法---KNN算法,为什么叫狐朋狗友算法呢,在这里我先卖个关子,且听我慢慢道来. 一 K ...
- 学习OpenCV——KNN算法
转自:http://blog.csdn.net/lyflower/article/details/1728642 文本分类中KNN算法,该方法的思路非常简单直观:如果一个样本在特征空间中的k个最相似( ...
- KNN算法与Kd树
最近邻法和k-近邻法 下面图片中只有三种豆,有三个豆是未知的种类,如何判定他们的种类? 提供一种思路,即:未知的豆离哪种豆最近就认为未知豆和该豆是同一种类.由此,我们引出最近邻算法的定义:为了判定未知 ...
随机推荐
- UI自动化框架搭建之Python3
UI自动化框架搭建--unittest 使用的代码是Python3版本,与时俱进哈哈 解释一下我的框架目录接口(每个人框架的目录接口不一样,根据实际要求) common目录:公共模块,这个地方可以存放 ...
- k8s中ingress,service,depoyment,pod如何关联
k8s中pod通过label标签名称来识别关联,它们的label name一定是一样的.ingress,service,depoyment通过selector 中app:name来关联 1.查询发布 ...
- SpringMVC 01: SpringMVC + 第一个SpringMVC项目
SpringMVC SpringMVC概述: 是基于MVC开发模式的框架,用来优化控制器 是Spring家族的一员,也具备IOC和AOP 什么是MVC: 它是一种开发模式,是模型视图控制器的简称,所有 ...
- 服务端挂了,客户端的 TCP 连接还在吗?
作者:小林coding 计算机八股文网站:https://xiaolincoding.com 大家好,我是小林. 如果「服务端挂掉」指的是「服务端进程崩溃」,服务端的进程在发生崩溃的时候,内核会发送 ...
- 全网最全Redis学习
一.Redis简介 Redis是以Key-Value形式进行存储的NoSQL数据库,C语言进行编写的.平时操作的数据都在内存中,效率特高,读的效率110000/s,写81000/s,所以多把Redis ...
- 若依(RuoYi )权限管理设计
前言 若依权限管理包含两个部分:菜单权限 和 数据权限.菜单权限控制着我们可以执行哪些操作.数据权限控制着我们可以看到哪些数据. 菜单是一个概括性名称,可以细分为目录.菜单和按钮,以若依自身为例: 目 ...
- typora收费了,最后一个免费版提供下载
typora收费了,在这里,博主提供最后一个免费版下载,地址如下,顺便把typora导入和导出word时需要的工具也一同提供.最看不惯免费用着别人的软件,还搞引流的垃圾网站和公众号.地址如下 http ...
- 【项目实战】CNN手写识别复杂模型的构造
感谢视频教程:https://www.bilibili.com/video/BV1Y7411d7Ys?p=11 这里开一篇新博客不仅仅是因为教程视频单独出了1p,也是因为这是一种代码编写的套路,特在此 ...
- kibana访问多个 Elasticsearch 节点间的负载均衡
如果 Elasticsearch 集群有多个节点,分发 Kibana 节点之间请求的最简单的方法就是在 Kibana 机器上运行一个 Elasticsearch 协调(Coordinating onl ...
- 第四章:Django表单 - 2:Django表单API详解
声明:以下的Form.表单等术语都指的的广义的Django表单. Form要么是绑定了数据的,要么是未绑定数据的. 如果是绑定的,那么它能够验证数据,并渲染表单及其数据,然后生成HTML表单.如果未绑 ...