Codeforces Round #844 (Div.1 + Div.2) CF 1782 A~F 题解
A. Parallel Projection
我们其实是要在这个矩形的边界上找一个点(x,y),使得(a,b)到(x,y)的曼哈顿距离和(f,g)到(x,y)的曼哈顿距离之和最小,求出最小值之后加h就是答案了,因为我们不可能在竖着的墙面上来回走,只可能走一次。进一步发现我们在上底面和下底面中,总有一个会走直线,也就是从起点沿直线直接走到边界,然后沿着墙面往下或往上走。把这8种情况都枚举一遍即可(也可能4种就够了,但是Div2A可没有那么多时间去想)。
时间复杂度\(O(1)\)。
点击查看代码
#include <bits/stdc++.h>
#define rep(i,n) for(int i=0;i<n;++i)
#define repn(i,n) for(int i=1;i<=n;++i)
#define LL long long
#define pii pair <int,int>
#define fi first
#define se second
#define mpr make_pair
#define pb push_back
void fileio()
{
#ifdef LGS
freopen("in.txt","r",stdin);
freopen("out.txt","w",stdout);
#endif
}
void termin()
{
#ifdef LGS
std::cout<<"\n\nEXECUTION TERMINATED";
#endif
exit(0);
}
using namespace std;
LL t,w,d,h,ans;
void upd(LL x,LL y,LL xx,LL yy,LL add)
{
ans=min(ans,llabs(x-xx)+llabs(y-yy)+add);
}
void upd(LL x,LL y,LL xx,LL yy)
{
upd(0,y,xx,yy,x);
upd(w,y,xx,yy,w-x);
upd(x,0,xx,yy,y);
upd(x,d,xx,yy,d-y);
}
int main()
{
fileio();
cin>>t;
rep(tn,t)
{
cin>>w>>d>>h;
LL x,y,xx,yy;
cin>>x>>y>>xx>>yy;
ans=1e18;
upd(x,y,xx,yy);upd(xx,yy,x,y);
printf("%lld\n",ans+h);
}
termin();
}
B. Going to the Cinema
先搞清楚题意,看看样例解释发现去0个人也是可以的。
假设现在强制恰好有x个人去。显然\(a_i>x\)的人只能不去,\(a_i<x\)的人必须去。\(a_i=x\)的人,如果他去了,那除了他以外的去的人就是x-1,他就会不开心;如果不去,除了他以外的去的人就是x,他也会不开心;所以不允许这样的人存在。因此枚举x,如果\(a_i<x\)的人数=x,且不存在\(a_i=x\)的人,就有1种方案,否则没有方案。
时间复杂度\(O(n)\)。
点击查看代码
#include <bits/stdc++.h>
#define rep(i,n) for(int i=0;i<n;++i)
#define repn(i,n) for(int i=1;i<=n;++i)
#define LL long long
#define pii pair <int,int>
#define fi first
#define se second
#define mpr make_pair
#define pb push_back
void fileio()
{
#ifdef LGS
freopen("in.txt","r",stdin);
freopen("out.txt","w",stdout);
#endif
}
void termin()
{
#ifdef LGS
std::cout<<"\n\nEXECUTION TERMINATED";
#endif
exit(0);
}
using namespace std;
int t,n,a[200010],b[200010],c[200010];
int main()
{
fileio();
cin>>t;
rep(tn,t)
{
cin>>n;
rep(i,n+3) b[i]=c[i]=0;
rep(i,n)
{
cin>>a[i];
++b[a[i]];c[a[i]]=1;
}
rep(i,n+3) b[i+1]+=b[i];
int ans=0;
rep(go,n+1) if(b[go]==go&&c[go]==0) ++ans;
cout<<ans<<endl;
}
termin();
}
C. Equal Frequencies
先枚举t中字母的种类数cnt,那么每种字母有\(len=\frac n{cnt}\)个。接下来我们要选出这cnt种字母,显然选s中出现次数越多的越好。令\(c_i\)表示字母i在s中的出现次数。对于字母i,如果它是选出的cnt个之一,且\(cnt\le c_i\),就把这cnt个i都放到s中字母i出现的对应位置。剩下没放的字母,发现不管怎么放都至少会产生这么多代价,所以随便放即可。最后用构造出的字符串更新一下答案就行了。
时间复杂度\(O(26n)\)。
点击查看代码
#include <bits/stdc++.h>
#define rep(i,n) for(int i=0;i<n;++i)
#define repn(i,n) for(int i=1;i<=n;++i)
#define LL long long
#define pii pair <int,int>
#define fi first
#define se second
#define mpr make_pair
#define pb push_back
void fileio()
{
#ifdef LGS
freopen("in.txt","r",stdin);
freopen("out.txt","w",stdout);
#endif
}
void termin()
{
#ifdef LGS
std::cout<<"\n\nEXECUTION TERMINATED";
#endif
exit(0);
}
using namespace std;
int t,n;
string s;
vector <int> v[30];
pair <int,string> ans;
int main()
{
fileio();
cin>>t;
rep(tn,t)
{
cin>>n>>s;
rep(i,28) v[i].clear();
rep(i,n) v[s[i]-'a'].pb(i);
vector <int> ord;rep(i,26) ord.pb(i);
sort(ord.begin(),ord.end(),[](int x,int y){return v[x].size()>v[y].size();});
ans=mpr((int)1e9,"");
repn(cnum,26) if(n%cnum==0)
{
int ecnt=n/cnum,dif=0;
string res="",lft="";rep(i,n) res.pb('-');
rep(j,cnum)
{
int use=min(ecnt,(int)v[ord[j]].size());
rep(k,use) res[v[ord[j]][k]]=ord[j]+'a';
rep(k,ecnt-use) lft.pb(ord[j]+'a');
}
dif=lft.size();
rep(j,res.size()) if(res[j]=='-')
{
res[j]=lft.back();
lft.pop_back();
}
ans=min(ans,mpr(dif,res));
}
cout<<ans.fi<<endl<<ans.se<<endl;
}
termin();
}
D. Many Perfect Squares
发现答案至少为1,我们只需要看答案>1的情况。如果答案>1,那肯定存在\(i,j(i<j)\),满足存在x使得\(a_i+x,a_j+x\)都是完全平方数(注意a数组递增)。所以这就要求存在两个数\(b,c\),使得\((b+c)^2-b^2=a_j-a_i\),也就是\(c^2-2bc=a_j-a_i\)。由于\(a_j-a_i\le 1e9\),所以对于任意合法的(b,c),\(c\le \sqrt{1e9}\)。因此我们可以枚举i和j,然后再枚举c,就可以求出所有满足"a数组中有至少两个数+x之后为完全平方数"的x了。理论上界是1e8左右,实际上远远达不到。对每个求出的x,直接暴力求出它的squareness,判断\(a_i+x\)的充要条件是\(((int)floor(sqrt(a_i+x)+0.5))^2=a_i+x\)。
时间复杂度\(O(能过)\)。
点击查看代码
#include <bits/stdc++.h>
#define rep(i,n) for(int i=0;i<n;++i)
#define repn(i,n) for(int i=1;i<=n;++i)
#define LL long long
#define pii pair <int,int>
#define fi first
#define se second
#define mpr make_pair
#define pb push_back
void fileio()
{
#ifdef LGS
freopen("in.txt","r",stdin);
freopen("out.txt","w",stdout);
#endif
}
void termin()
{
#ifdef LGS
std::cout<<"\n\nEXECUTION TERMINATED";
#endif
exit(0);
}
using namespace std;
LL t,n,a[60],ans;
void checkX(LL x)
{
LL res=0;
rep(i,n)
{
LL val=floor(sqrt(a[i]+x)+0.5);
if(val*val==a[i]+x) ++res;
}
ans=max(ans,res);
}
void check(LL i,LL sub)
{
for(LL N=1;N*N<sub;++N)
{
LL XN2=sub-N*N;
if(XN2%(N+N)==0)
{
LL sml=XN2/(N+N);sml*=sml;
if(sml>=a[i]) checkX(sml-a[i]);
}
}
}
int main()
{
fileio();
cin>>t;
rep(tn,t)
{
cin>>n;
rep(i,n) cin>>a[i];
ans=1;
rep(i,n) for(int j=i+1;j<=n;++j) check(i,a[j]-a[i]);
cout<<ans<<endl;
}
termin();
}
E. Rectangle Shrinking
思路不难,写起来比较烦。这题的本质是大模拟。
直觉告诉我们:初始被任意一个矩形覆盖的格子,在最后应该也一定能被覆盖。问题就是怎么构造出方案。
先把矩形分成三类:只在第一行的,只在第二行的,横跨两行的。然后对每一类的所有矩形的左端点和右端点都做一些调整(直接删除也行),使得同一类中没有任意两个矩形有重合,且每一类中所有矩形的并保持原样。这个直接排一下序就可以做到。
然后把只在第一行的,只在第二行的这两类中调整完的矩形加入答案。接下来,向答案中逐个插入调整完的横跨两行的矩形。假设当前插入的横跨两行的矩形的左右端点分别为\(L,R\)。令条件1="当前答案中是否存在只在第一行的矩形i满足\(l_i\le L且R\le r_i\)",条件2="当前答案中是否存在只在第二行的矩形i满足\(l_i\le L且R\le r_i\)"。如果两个条件都成立,那么这个矩形已经没有用了,可以删除。如果只有条件1成立,那就强制把当前矩形变成只在第二行的矩形并加入答案;如果当前答案中已经有只在第二行的矩形与这个矩形有重合,那就对这些矩形的左右边界进行调整(或者直接删除),使得所有原来被覆盖的格子现在仍被覆盖。只有条件2成立的情况同理。如果两个条件都不成立,那就直接把这个矩形加入答案,然后调整答案中已有的与当前矩形有重合的矩形的左右边界。以上操作都可以用set完成。容易发现在这种构造方式下,初始被任意一个矩形覆盖的格子,在最后也一定能被覆盖。
时间复杂度\(O(nlogn)\)。
点击查看代码
#include <bits/stdc++.h>
#define rep(i,n) for(int i=0;i<n;++i)
#define repn(i,n) for(int i=1;i<=n;++i)
#define LL long long
#define pii pair <LL,LL>
#define fi first
#define se second
#define mpr make_pair
#define pb push_back
void fileio()
{
#ifdef LGS
freopen("in.txt","r",stdin);
freopen("out.txt","w",stdout);
#endif
}
void termin()
{
#ifdef LGS
std::cout<<"\n\nEXECUTION TERMINATED";
#endif
exit(0);
}
using namespace std;
LL t,n,u[200010],d[200010],l[200010],r[200010];
set <pair <pii,LL> > st[3];//{双,上,下}
void del(LL w,LL ll,LL rr)
{
if(st[w].empty()) return;
auto tmp=st[w].lower_bound(mpr(mpr(ll,0LL),0LL));
if(tmp!=st[w].begin())
{
--tmp;
if(tmp->fi.se>=ll)
{
auto val=*tmp;val.fi.se=ll-1;
st[w].erase(tmp);
st[w].insert(val);
}
}
while(true)
{
auto it=st[w].lower_bound(mpr(mpr(ll,0LL),0LL));
if(it==st[w].end()||it->fi.fi>rr) break;
if(it->fi.se<=rr) st[w].erase(it);
else
{
auto val=*it;val.fi.fi=rr+1;
st[w].erase(it);
st[w].insert(val);
}
}
}
bool isCovered(LL w,LL ll,LL rr)
{
if(st[w].empty()) return false;
auto tmp=st[w].lower_bound(mpr(mpr(ll,0LL),0LL));
if(tmp!=st[w].begin())
{
--tmp;
if(tmp->fi.se>=rr) return true;
}
auto it=st[w].lower_bound(mpr(mpr(ll,0LL),0LL));
if(it!=st[w].end()&&it->fi.fi==ll&&it->fi.se>=rr) return true;
return false;
}
int main()
{
fileio();
cin>>t;
rep(tn,t)
{
scanf("%lld",&n);
rep(i,n) scanf("%lld%lld%lld%lld",&u[i],&l[i],&d[i],&r[i]);
rep(i,3) st[i].clear();
vector <pair <pii,LL> > tmp;
rep(i,n) if(d[i]==1) tmp.pb(mpr(mpr(l[i],r[i]),i));
sort(tmp.begin(),tmp.end());
int mx=0;
rep(i,tmp.size())
{
if(mx>=tmp[i].fi.se) continue;
if(tmp[i].fi.fi>mx)
{
mx=tmp[i].fi.se;
st[1].insert(tmp[i]);
}
else
{
st[1].insert(mpr(mpr(mx+1,tmp[i].fi.se),tmp[i].se));
mx=tmp[i].fi.se;
}
}
tmp.clear();
rep(i,n) if(u[i]==2) tmp.pb(mpr(mpr(l[i],r[i]),i));
sort(tmp.begin(),tmp.end());
mx=0;
rep(i,tmp.size())
{
if(mx>=tmp[i].fi.se) continue;
if(tmp[i].fi.fi>mx)
{
mx=tmp[i].fi.se;
st[2].insert(tmp[i]);
}
else
{
st[2].insert(mpr(mpr(mx+1,tmp[i].fi.se),tmp[i].se));
mx=tmp[i].fi.se;
}
}
vector <pair <pii,LL> > addord;
tmp.clear();
rep(i,n) if(u[i]==1&&d[i]==2) tmp.pb(mpr(mpr(l[i],r[i]),i));
sort(tmp.begin(),tmp.end());
mx=0;
rep(i,tmp.size())
{
if(mx>=tmp[i].fi.se) continue;
if(tmp[i].fi.fi>mx)
{
mx=tmp[i].fi.se;
st[0].insert(tmp[i]);addord.pb(tmp[i]);
}
else
{
st[0].insert(mpr(mpr(mx+1,tmp[i].fi.se),tmp[i].se));addord.pb(mpr(mpr(mx+1,tmp[i].fi.se),tmp[i].se));
mx=tmp[i].fi.se;
}
}
st[0].clear();
rep(ii,addord.size())
{
int i=addord[ii].se;l[i]=addord[ii].fi.fi;r[i]=addord[ii].fi.se;
bool c1=isCovered(1,l[i],r[i]),c2=isCovered(2,l[i],r[i]);
if(c1&&c2) continue;
if(c2)
{
del(1,l[i],r[i]);
st[1].insert(mpr(mpr(l[i],r[i]),i));
}
else if(c1)
{
del(2,l[i],r[i]);
st[2].insert(mpr(mpr(l[i],r[i]),i));
}
else
{
del(1,l[i],r[i]);del(2,l[i],r[i]);
st[0].insert(mpr(mpr(l[i],r[i]),i));
}
}
rep(i,n) l[i]=r[i]=u[i]=d[i]=0;
for(auto it:st[0])
{
int id=it.se;
u[id]=1;d[id]=2;l[id]=it.fi.fi;r[id]=it.fi.se;
}
for(auto it:st[1])
{
int id=it.se;
u[id]=1;d[id]=1;l[id]=it.fi.fi;r[id]=it.fi.se;
}
for(auto it:st[2])
{
int id=it.se;
u[id]=2;d[id]=2;l[id]=it.fi.fi;r[id]=it.fi.se;
}
LL ans=0;
rep(i,n) if(u[i]!=0) ans+=(d[i]-u[i]+1)*(r[i]-l[i]+1);
cout<<ans<<endl;
rep(i,n) printf("%lld %lld %lld %lld\n",u[i],l[i],d[i],r[i]);
}
termin();
}
F. Bracket Insertion
发现一旦在中途的某步操作时使得这个括号序列不合法了,那之后就再也救不回来了,因为如果把(看成1,)看成-1,不管插入()还是)(都不能再改变某个字符处的前缀和,而括号序列合法的充要条件就是每个字符处的前缀和\(\ge 0\)。
我们的每次插入操作都是均等概率地选择一个间隔,并插入一些东西。每次操作都会增加恰好2个间隔。定义一个间隔的权值为它前面所有括号的权值和("("为1,")"为-1)。令p=插入()的概率,q=1-p。则操作的过程可以转化成这样:有一个多重集,初始为\(\{0\}\),一共进行n次操作,每次均等概率地从中选择一个数x,并以p的概率插入\(\{x,x+1\}\),以q的概率插入\(\{x,x-1\}\),求最后多重集中不存在负数的概率。
我们可以把多重集中的每个数看成有根树上的一个节点。这棵树点和边都有权值,第i次操作时我们在树上随机选择一个节点,并给它增加两个儿子,其点权都为i。两个儿子其中一个到父亲的边权为0,另一个边权以p的概率为1,q的概率为-1。求树上没有任意一个节点到根的权值和为负数的概率。
为了便于理解,我们把"求概率"改为"对合法的树形态计数"(每条非零边值为1的"方案数"为p,为-1的"方案数"为q,因为概率和方案数本来就是差不多的东西)。最后我们只要把这个方案数除以\(1\cdot3\cdot5\cdots (2n-1)\)就是答案。注意这个树上每个节点的儿子之间是没有顺序的。
为了方便计数,我们修改一下树的结构。初始树上有一个关键点。第i次操作时,选一个关键点,在它的下面连上这样一个东西:
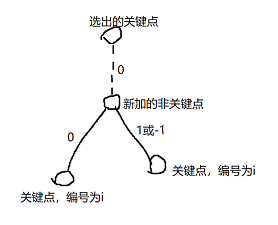
接下来就可以dp了。
- \(dp_{i,j}\)表示一个关键点个数为2i-1(包括根)的子树,根为关键点,子树中关键点权值在[1,i-1]中,最终整棵树的根到这个子树的根的边权和为j,子树内没有到整棵树的根的边权和为负的节点的方案数。最终答案为\(dp_{n+1,0}\)。
- \(g_{i,j}\)表示一个关键点个数为2i的子树,根为非关键点,子树中关键点权值在[1,i]中,最终整棵树的根到这个子树的根的边权和为j,子树内没有到整棵树的根的边权和为负的节点的方案数。
来看看怎么对\(dp_{i,j}\)转移,我们需要枚举它的每个子树的大小,并给每个子树中的关键点分配权值(是一个多重组合数),还要去重(因为子树之间没有顺序)。看起来非常麻烦,所以我们定义一个辅助数组\(f_{i,j}\),使得\(dp_{i,j}=f_{i-1,j}\cdot (i-1)!\)。
我们从小到大地枚举i,在求出\(dp_{i,*}\)的同时维护f。枚举三个数j,k和cnt,从\(f_{j,k}\)转移到\(f_{j+cnt\cdot i,k}\)。cnt这一维的复杂度是个调和级数,所以总的枚举量是\(O(n^3logn)\)。转移系数是\(\frac 1{(cnt\cdot i)!}g_{i,k}^{cnt}\cdot \binom{i\cdot cnt-1}{i-1}\cdot \binom{(i-1)cnt-1}{i-1}\cdots \binom{i-1}{i-1}\)。其中最前面的\(\frac 1{(cnt\cdot i)!}\)与上面的\(dp_{i,j}=f_{i-1,j}\cdot (i-1)!\)中的\((i-1)!\)构成一个多重组合数,用来把i-1种点权分散到每种\(g_{i,k}\);后面的一连串组合数是用来把\(i\cdot cnt\)种点权分散到\(cnt\)个\(g_{i,k}\),由于儿子之间无序,所以用每次选出当前没选的最小权值所在的子树中的所有权值的方式来计数。
\(g\)的转移很简单,在枚举到i时,枚举三个数j,k和r使得j、k中有至少一个=i,并把\(dp_{j,r}\cdot(dp_{k,r+1}\cdot p+dp_{k,r-1}\cdot q)\)转移到\(g_{j+k-1,r}\)即可。还需要乘上一个分配点权的组合数。
总时间复杂度\(O(n^3logn)\)。有点卡常,要尽量减少最内层循环的计算量。
点击查看代码
#include <bits/stdc++.h>
#define rep(i,n) for(int i=0;i<n;++i)
#define repn(i,n) for(int i=1;i<=n;++i)
#define LL long long
#define pii pair <int,int>
#define fi first
#define se second
#define mpr make_pair
#define pb push_back
#pragma GCC optimize("Ofast")
#pragma GCC target("sse,sse2,sse3,ssse3,sse4,popcnt,abm,mmx,avx,avx2,tune=native")
#pragma GCC optimize("inline","fast-math","unroll-loops","no-stack-protector")
void fileio()
{
#ifdef LGS
freopen("in.txt","r",stdin);
freopen("out.txt","w",stdout);
#endif
}
void termin()
{
#ifdef LGS
std::cout<<"\n\nEXECUTION TERMINATED";
#endif
exit(0);
}
using namespace std;
const LL MOD=998244353;
LL qpow(LL x,LL a)
{
LL res=x,ret=1;
while(a>0)
{
if(a&1) (ret*=res)%=MOD;
a>>=1;
(res*=res)%=MOD;
}
return ret;
}
LL n,p,q,dp[510][510],fac[1010],inv[1010],rinv[1010],f[510][510],g[510][510],c[1010][1010];
LL C(LL nn,LL mm){return fac[nn]*inv[mm]%MOD*inv[nn-mm]%MOD;}
void calcG(int i,int j)
{
LL toi=i+j-1,mul=C(i-1+j-1,i-1);
if(toi>=n+3) return;
rep(k,n+2)
{
LL val=dp[i][k]*((dp[j][k+1]*p+(k==0 ? 0LL:dp[j][k-1]*q))%MOD)%MOD;
(g[toi][k]+=val*mul)%=MOD;
}
}
int main()
{
fileio();
fac[0]=1;repn(i,1005) fac[i]=fac[i-1]*i%MOD;
rep(i,1003) inv[i]=qpow(fac[i],MOD-2),rinv[i]=qpow(i,MOD-2);
cin>>n>>p;
(p*=qpow(10000,MOD-2))%=MOD;q=(1-p+MOD)%MOD;
rep(i,n+3) rep(j,i+1) c[i][j]=C(i,j);
rep(i,n+3) f[0][i]=1;
repn(i,n+1)
{
if(i==1) rep(j,n+3) dp[i][j]=1;
else
{
rep(j,n+2)
dp[i][j]=f[i-1][j]*fac[i-1]%MOD;
}
repn(j,i)
{
int k=i;
calcG(j,k);
}
repn(k,i-1)
{
int j=i;
calcG(j,k);
}
for(int pre=n;pre>=0;--pre) rep(j,n+2) if(f[pre][j])
{
LL mul=1;
for(int cnt=1;pre+cnt*i<=n;++cnt)
{
(mul*=g[i][j]*c[i*cnt-1][i-1]%MOD)%=MOD;
LL rv=mul*inv[cnt*i]%MOD;
(f[pre+cnt*i][j]+=f[pre][j]*rv)%=MOD;
}
}
}
LL ans=dp[n+1][0];
repn(i,n) (ans*=qpow(i*2-1,MOD-2))%=MOD;
cout<<ans<<endl;
termin();
}
Codeforces Round #844 (Div.1 + Div.2) CF 1782 A~F 题解的更多相关文章
- Educational Codeforces Round 65 (Rated for Div. 2)题解
Educational Codeforces Round 65 (Rated for Div. 2)题解 题目链接 A. Telephone Number 水题,代码如下: Code #include ...
- Educational Codeforces Round 60 (Rated for Div. 2) - C. Magic Ship
Problem Educational Codeforces Round 60 (Rated for Div. 2) - C. Magic Ship Time Limit: 2000 mSec P ...
- Educational Codeforces Round 60 (Rated for Div. 2) - D. Magic Gems(动态规划+矩阵快速幂)
Problem Educational Codeforces Round 60 (Rated for Div. 2) - D. Magic Gems Time Limit: 3000 mSec P ...
- Educational Codeforces Round 43 (Rated for Div. 2)
Educational Codeforces Round 43 (Rated for Div. 2) https://codeforces.com/contest/976 A #include< ...
- Educational Codeforces Round 35 (Rated for Div. 2)
Educational Codeforces Round 35 (Rated for Div. 2) https://codeforces.com/contest/911 A 模拟 #include& ...
- Codeforces Educational Codeforces Round 44 (Rated for Div. 2) F. Isomorphic Strings
Codeforces Educational Codeforces Round 44 (Rated for Div. 2) F. Isomorphic Strings 题目连接: http://cod ...
- Codeforces Educational Codeforces Round 44 (Rated for Div. 2) E. Pencils and Boxes
Codeforces Educational Codeforces Round 44 (Rated for Div. 2) E. Pencils and Boxes 题目连接: http://code ...
- Educational Codeforces Round 63 (Rated for Div. 2) 题解
Educational Codeforces Round 63 (Rated for Div. 2)题解 题目链接 A. Reverse a Substring 给出一个字符串,现在可以对这个字符串进 ...
- Educational Codeforces Round 39 (Rated for Div. 2) G
Educational Codeforces Round 39 (Rated for Div. 2) G 题意: 给一个序列\(a_i(1 <= a_i <= 10^{9}),2 < ...
- Educational Codeforces Round 48 (Rated for Div. 2) CD题解
Educational Codeforces Round 48 (Rated for Div. 2) C. Vasya And The Mushrooms 题目链接:https://codeforce ...
随机推荐
- 知识图谱-生物信息学-医学论文(Chip-2022)-BCKG-基于临床指南的中国乳腺癌知识图谱的构建与应用
16.(2022)Chip-BCKG-基于临床指南的中国乳腺癌知识图谱的构建与应用 论文标题: Construction and Application of Chinese Breast Cance ...
- Redis Cluster 原理说的头头是道,这些配置不懂就是纸上谈兵
Redis Cluster 原理说的头头是道,这些配置不懂就是纸上谈兵 Redis Cluster 集群相关配置,使用集群方式的你必须重视和知晓.别嘴上原理说的头头是道,而集群有哪些配置?如何配置让集 ...
- Vue3实现动态导入Excel表格数据
1. 前言 在开发工作过程中,我们会遇到各种各样的表格数据导入,大部分我们的解决方案:提供一个模板前端进行下载,然后按照这个模板要求进行数据填充,最后上传导入,这是其中一种解决方案.个人认为还有另外 ...
- 【lwip】12-一文解决TCP原理
目录 前言 12.1 TCP协议简介 12.2 TCP相关的一些概念词 12.2.1 MSL 12.2.2 MSS 12.3 TCP工作特性 12.3.1 面向连接 12.3.2 全双工通信 12.3 ...
- 造个Python轮子,实现根据Excel生成Model和数据导入脚本
前言 最近遇到一个需求,有几十个Excel,每个的字段都不一样,然后都差不多是第一行是表头,后面几千上万的数据,需要把这些Excel中的数据全都加入某个已经上线的Django项目 这就需要每个Exce ...
- 深度学习之Tensorflow入门
声明 本文参考[中文][吴恩达课后编程作业]Course 2 - 改善深层神经网络 - 第三周作业_何宽的博客-CSDN博客我对这篇博客加上自己的理解,力求看懂 本文所使用的资料已上传到百度网盘[点击 ...
- 基于python的数学建模---logicstic回归
樱花数据集的Logistic回归 绘制散点图 import matplotlib.pyplot as plt import numpy as np from sklearn.datasets impo ...
- Xamarin.Android带参数返回上一级界面
在ActivityA跳转到ActivityB后.activityB返回到ActivityA并带参数返回 首先再activitya中跳转到b var intent = new Intent(this, ...
- 解决Qt5 mouseMoveEvent事件不能直接触发
问题描述 mouseMoveEvent 需要鼠标点击(左右中),然后在按下的同时移动鼠标才会触发 mouseMoveEvent事件函数. 解决 setMouseTracking(true);
- HCIE Routing&Switching之MPLS基础理论
技术背景 90年代初期,互联网流量快速增长,而由于当时硬件技术的限制,路由器采用最长匹配算法逐跳转发数据包,成为网络数据转发的瓶颈:于是快速路由技术成为当时研究的一个热点:在各种方案中,IETF确定了 ...