5-11 Redis缓存 | 持久化 | 集群_哨兵_主从复制_读写分离
Redis 强化
缓存淘汰策略
Redis服务器繁忙时,有大量信息要保存
如果Redis服务器内存全满,再要往Redis中保存新的数据,就需要淘汰老数据,才能保存新数据
noeviction:返回错误**(默认)**allkeys-random:所有数据中随机删除数据volatile-random:有过期时间的数据库中随机删除数据volatile-ttl:删除剩余有效时间最少的数据allkeys-lru:所有数据中删除上次使用时间最久的数据volatile-lru:有过期时间的数据中删除上次使用时间最久的数据allkeys-lfu:所有数据中删除使用频率最少的volatile-lfu:有过期时间的数据中删除使用频率最少的
缓存穿透
正常业务下,从数据库查询出的数据可以保存在Redis中
下次查询时直接从Redis中获得,大幅提高响应速度,提高系统性能
所谓缓存穿透,就是查询了一个数据库中都不存在的数据
我们Redis中没有这个数据,它到数据库查,也没有
如果这样的请求多了,那么数据库压力就会很大
前面阶段我们使用向Redis中保存null值,来防止一个查询反复穿透
但是这样的策略有问题
如果用户不断更换查询关键字,反复穿透,也是对数据库性能极大的威胁
使用布隆过滤器来解决这个问题
事先创建好布隆过滤器,它可以在进入业务逻辑层时判断用户查询的信息数据库中是否存在,如果不存在于数据库中,直接终止查询返回
缓存击穿
正常运行的情况,我们设计的应该在Redis中保存的数据,如果有请求访问到Redis而Redis没有这个数据
导致请求从数据库中查询这种现象就是缓存击穿
但是这个情况也不是异常情况,因为我们大多数数据都需要设置过期时间,而过期时间到时这些数据一定会从数据库中同步
击穿只是这个现象的名称,并不是不允许的
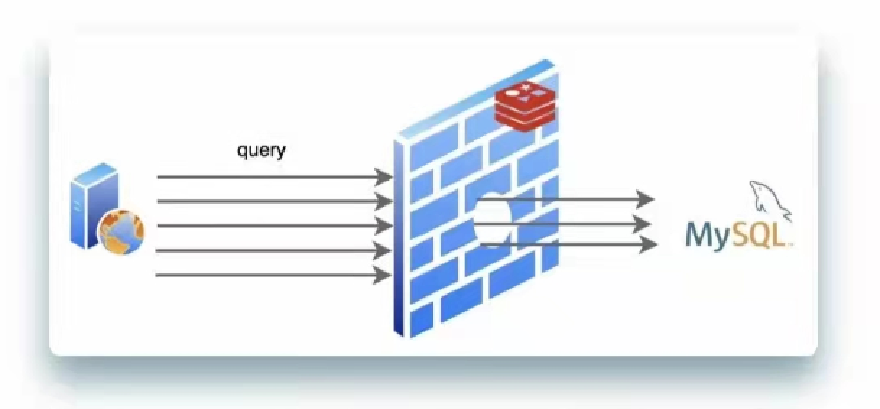
缓存雪崩
上面讲到击穿现象
同一时间发生少量击穿是正常的
但是如果出现同一时间大量击穿现象就会如下图
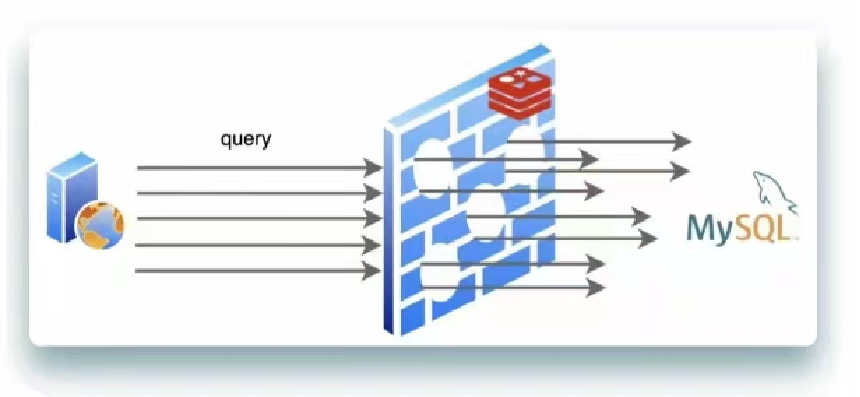
这种情况下,Mysql会短时间出现很多新的查询请求,这样就会发生性能问题
如何避免这样的问题?
因为出现这个问题的原因通常是同时加载的数据设置了相同的有效期
我们需要在设置有效期时添加一个随机数,大量数据就不会同时失效了,
Redis持久化
Redis将信息保存在内存
内存的特征就是一旦断电,所有信息都丢失,Redis来讲,所有数据丢失,就需要从数据库从新查询所有数据,这个是慢的
更有可能,Redis本身是有新数据的,还没有和数据库同步就断电了
所以Redis支持了持久化方案,在当前服务器将Redis中的数据保存在当地硬盘上
Redis恢复策略有两种
RDB:(Redis Database Backup)
数据库快照,(将当前数据库转换为二进制的数据保存在硬盘上),Redis生成一个dump.rdb的文件
我们可以在Redis安装程序的配置文件中进行配置
空白位置编写如下内容
save 60 5
60表示秒数,既1分钟
5表示key被修改的次数
配置效果:1分钟内如果有5个key以上被修改,就启动rdb数据库快照程序
优点:
因为是整体Redis数据的二进制格式,数据恢复是整体恢复的
缺点:
生成的rdb文件是一个硬盘上的文件,读写效率是较低的
如果突然断电,只能恢复最后一次生成的rdb中的数据
AOF(Append Only File):
AOF策略是将Redis运行过的所有命令(日志)备份下来
这样即使信息丢失,我们也可能根据运行过的日志,恢复为断电前的样子
它的配置如下
appendonly yes
特点:只保存命令不保存数据
理论上Redis运行过的命令都可以保存下来
但是实际情况下,Redis非常繁忙时,我们会将日志命令缓存之后,整体发送给备份,减少io次数以提高备份的性能和对Redis性能的影响
实际开发中,配置一般会采用每秒将日志文件发送一次的策略,断电最多丢失1秒数据
为了减少日志的大小
Redis支持AOF rewrite
将一些已经进行删除的数据的新增命令也从日志中移除,达到减少日志容量的目的
Redis存储原理
Redis将内存划分为16384个槽(类似hash槽)
将数据(key)使用CRC16算法计算出一个在0~16383之间的值
将数据存到这个槽中
当再次使用这个key计算时,直接从这个槽获取,大幅提高查询效率
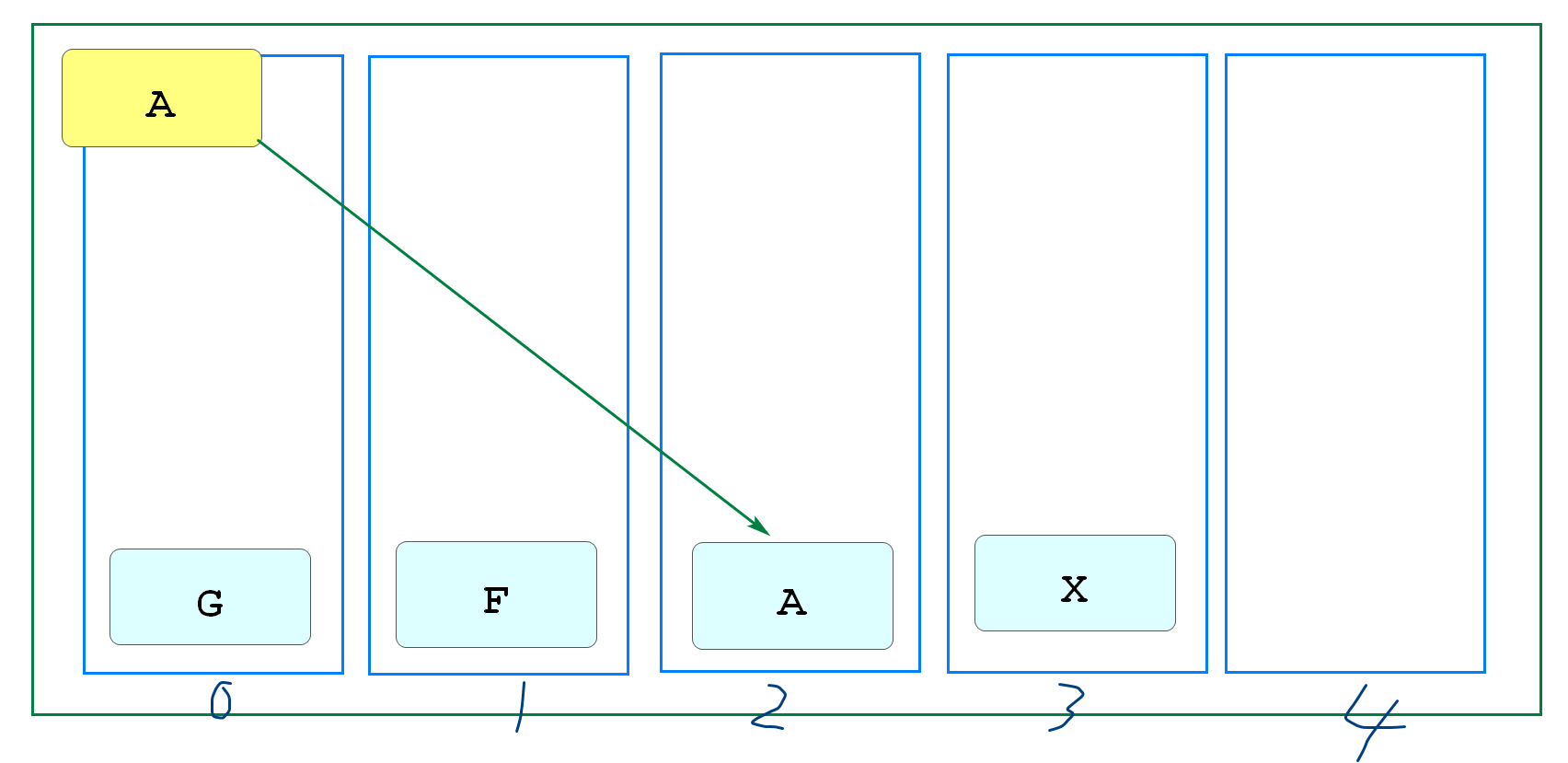
实际上这就是最基本"散列算法"
Redis集群
最小状态Redis是一台服务器
这台服务器的状态直接决定的Redis的运行状态
如果它宕机了,那么Redis服务就没了
系统面临崩溃风险
我们可以在主机运行时使用一台备机
主从复制
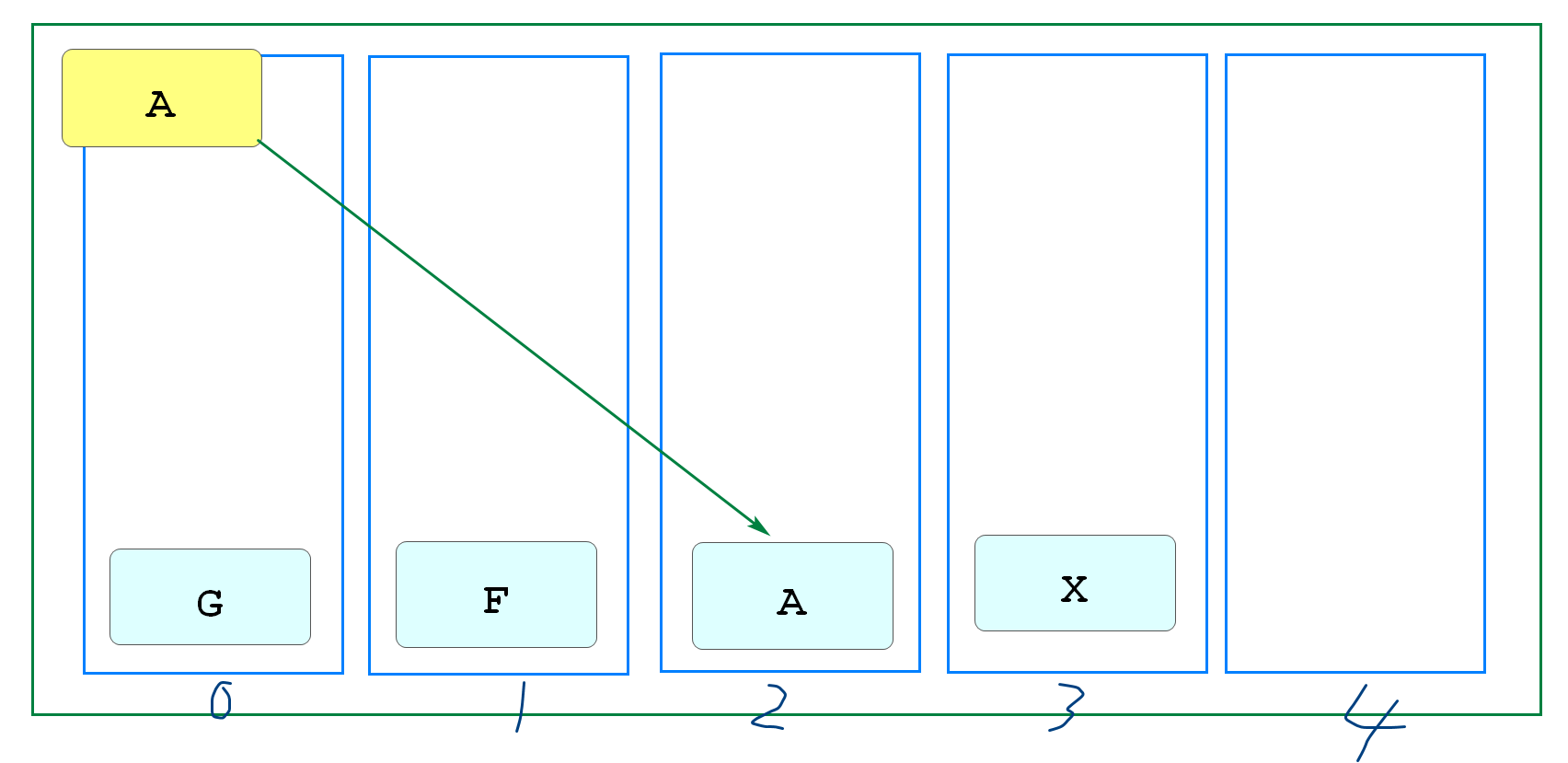
也就是主机(master)工作时,安排一台备用机(slave)实时同步数据,万一主机宕机,我们可以切换到备机运行
缺点,这样的方案,slave节点没有任何实质作用,只要master不宕机它就和没有一样,没有体现价值
读写分离
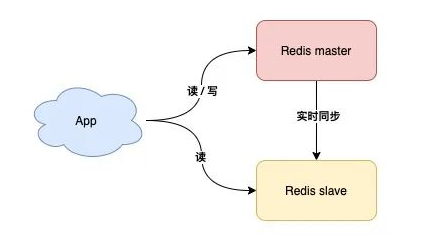
这样slave在master正常工作时也能分担Master的工作了
但是如果master宕机,实际上主备机的切换,实际上还是需要人工介入的,这还是需要时间的
那么如果想实现故障是自动切换,一定是有配置好的固定策略的
哨兵模式
:故障自动切换
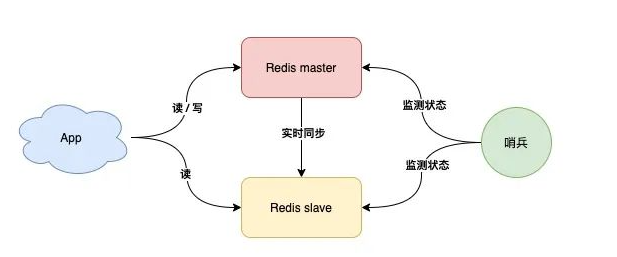
哨兵节点每隔固定时间向所有节点发送请求
如果正常响应认为该节点正常
如果没有响应,认为该节点出现问题,哨兵能自动切换主备机
如果主机master下线,自动切换到备机运行
但是这样的模式存在问题
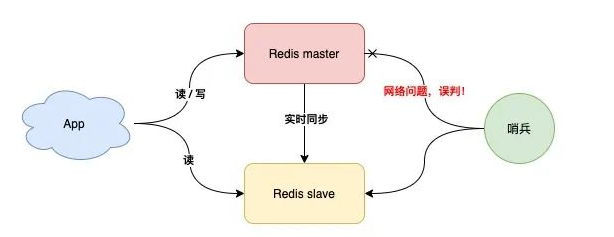
但是如果哨兵判断节点状态时发生了误判,那么就会错误将master下线,降低整体运行性能
哨兵集群
上次课我们说了哨兵
如果哨兵服务器是一个节点,它误判master节点出现了故障,将master节点下线
但是master其实是正常工作的,整体系统效率就会大打折扣
我们可以将哨兵节点做成集群,由多个哨兵投票决定是否下线某一个节点
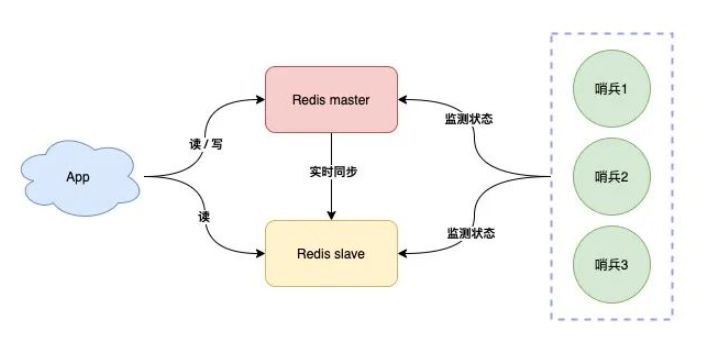
哨兵集群中,每个节点都会定时向master和slave发送ping请求
如果ping请求有2个(集群的半数节点)以上的哨兵节点没有收到正常响应,会认为该节点下线
分片集群
当业务不断扩展,并发不断增高时
有可能一个Master节点做写操作性能不足,称为了系统性能的瓶颈
这时,就可以部署多个Master节点,每个节点也支持主从复制
只是每个节点负责不同的分片
Redis0~16383号槽,
例如MasterA复制0~5000
MasterB复制5001~10000
MasterC复制10001~16383
一个key根据CRC16算法只能得到固定的结果,一定在指定的服务器上找到数据
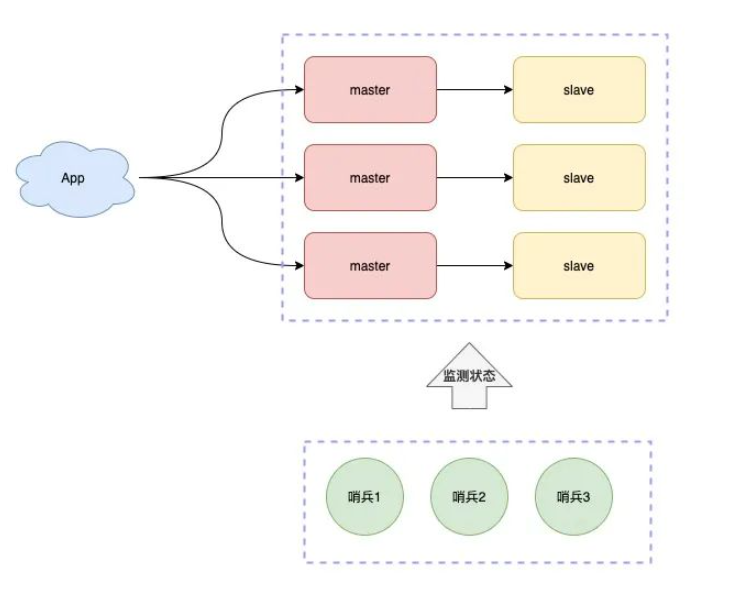
有了这个集群结构,我们就能更加稳定和更加高效的处理业务请求了
为了节省哨兵服务器的成本,有些工作在Redis集群中直接添加哨兵功能,既master/slave节点完成数据读写任务的同时也都互相检测它们的健康状态
5-11 Redis缓存 | 持久化 | 集群_哨兵_主从复制_读写分离的更多相关文章
- (六) Docker 部署 Redis 高可用集群 (sentinel 哨兵模式)
参考并感谢 官方文档 https://hub.docker.com/_/redis GitHub https://github.com/antirez/redis happyJared https:/ ...
- redis主从、集群、哨兵
redis的主从.集群.哨兵 参考: https://blog.csdn.net/robertohuang/article/details/70741575 https://blog.csdn.net ...
- Redis高可用集群方案——哨兵
本篇文章版权归博客园和作者吴双本人共同所有,转载和爬虫请注明原文系列地址http://www.cnblogs.com/tdws/tag/NoSql/ 本人之前有篇文章,讲到了redis主从复制,读写分 ...
- redis缓存服务器集群搭建
一.安装redis 1.下载redis [root@redis ~]# wget http://download.redis.io/releases/redis-4.0.11.tar.gz 2.安装编 ...
- Redis的复制(Master/Slave)、主从复制、读写分离
1.什么是Redis的复制 行话:也就是我们所说的主从复制,主数据更新后根据配置和策略自动同步到备用机的master/slave机制,Mater以写为主,slave以读为主. 2.能干什么 2.1.读 ...
- Redis的复制(Master/Slave)、主从复制、读写分离 (下)
哨兵模式(就是反客为主的自动版) 能够自动监控主机是否故障,如果故障了根据投票数自动将从机变成主机 1创建哨兵文件 touch sentinel.conf [root@localhost myredi ...
- Redis+Twemproxy+HAProxy集群(转) 干货
原文地址:Redis+Twemproxy+HAProxy集群 干货 Redis主从模式 Redis数据库与传统数据库属于并行关系,也就是说传统的关系型数据库保存的是结构化数据,而Redis保存的是一 ...
- 通过 Docker 部署 Redis 6.x 集群
要点步骤总结: # 这里演示使用同一台主机上 # 创建各节点存储路径 mkdir -p /opt/redis/{7000,7001,7002,7003,7004,7005} # 创建各节点配置文件 c ...
- Redis 高可用集群
Redis 高可用集群 Redis 的集群主从模型是一种高可用的集群架构.本章主要内容有:高可用集群的搭建,Jedis连接集群,新增集群节点,删除集群节点,其他配置补充说明. 高可用集群搭建 集群(c ...
随机推荐
- Kafka Kerberos 安全认证
本主要介绍在 Kafka 中如何配置 Kerberos 认证,文中所使用到的软件版本:Java 1.8.0_261.Kafka_2.12-2.6.0.Kerberos 1.15.1. 1. Kerbe ...
- 四月总结&五月计划
四月总结 1. 主要任务 <Effective C++>书 ① 进展: 看完了30讲(共55讲),从4月20号开始居家办公,书落在公司了,一直到昨天29号才去园区上班,耽搁了.30讲之前的 ...
- 真香!Windows 可直接运行 Linux 了
点击关注上方"开源Linux", 后台回复"读书",有我为您特别筛选书籍资料~ 之前了解过一些适用于Linux的Windows子系统,最近又听人提起,于是在自己 ...
- python入门基础知识二(字符串的常用操作方法)
下标/索引: a = "I'm interested in Python." print(a[4]) i # 英文的字符串每一个下标/索引对应一个字母(含标点) a = '我喜欢p ...
- .Net 在容器中操作宿主机
方案描述 在 docker 容器中想操作宿主机,一般会使用 ssh 的方式,然后 .Net 通过执行远程 ssh 指令来操作宿主机.本文将使用 交互式 .Net 容器版 中提供的镜像演示 .Net 在 ...
- yarn/npm 设置镜像地址
注意 如果开发 electron 桌面软件,需要设置以下两个镜像地址 disturl.electron_mirror 如果用到了 node-sass 需要设置以下一个镜像地址 sass_binary_ ...
- 基础篇:java GC 总结,建议收藏
垃圾标记算法 垃圾回收算法 major gc.mini gc.full gc.mixed gc 又是什么,怎么触发的 垃圾回收器的介绍 Safe Point 和 Safe Region 什么是 TLA ...
- App上看到就忍不住点的小红点是如何实现的?
你有没有发现,我们解锁手机后桌面上App右上角总能看到一个小红点,这就是推送角标.推送角标指的是移动设备上App图标右上角的红色圆圈,圆圈内的白色数字表示未读消息数量.角标是一种比较轻的提醒方式,通过 ...
- JavaScript之parseInt()方法
parseInt(string, radix):用于解析一个字符串并返回指定基数的十进制整数或者NaN string参数为被解析的值,如果该值不是一个字符串,则会隐式的使用toString()方法转化 ...
- Eureka属性配置
一:Eureka Instance实例信息配置 里面的配置以"-"隔开 其实也支持驼峰命名代替"-" 首先是入门时的配置: server: port: 80 ...