源码(chan,map,GMP,mutex,context)
1、chan原理
1.1 chan底层数据结构
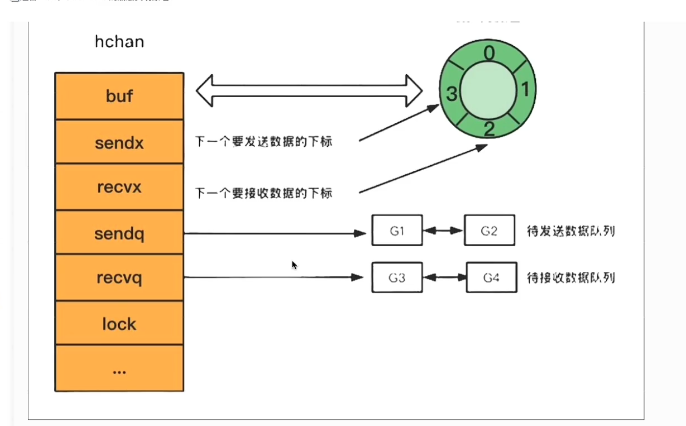
概念:go中的channel是一个队列,遵循先进先出的原则,负责协程之间的通信(go语言提倡不要通过共享内存来通信,而提倡通过通信实现内存共享,CSP模型)
使用场景:
停止信号监听
定时任务
生产和消费解藕
控制并发数
底层数据结构:
通过var或者make创建的channel变量是一个存储在函数栈帧上的指针,占用8个字节,指向堆上的chan结构体
源码:src/runtime/chan.map定义了hchan的结构体
环形数组好处:
环形数组消费元素只需要移动下标,普通数组消费元素,需要对剩余的数据前移
底层hchan结构:
type hchan struct {
qcount uint // 循环数组中元素的数量
dataqsiz uint // 循环数组的长度
buf unsafe.Pointer // 底层缓冲环形数组,有缓冲的channel使用
elemsize uint16 // channel中元素的大小
closed uint32 // channel是否关闭标志
elemtype *_type // channel中元素的类型
sendx uint // 下一次写下标的位置
recvx uint // 下一次读下标的位置
//读取channel或者写入channel而被阻塞的goroutine,
//包含头节点尾节点,记录哪个协程在等待,等待的是哪个channel,等待接收/发送的数据在哪里
recvq waitq // 读等待队列,
sendq waitq // 写等待队列
lock mutex //互斥锁,保证读写channel时不存在并发竞争资源问题
}
//recvq的队列
type waitq struct {
first *sudog
last *sudog
}
//双向链表
type sudog struct {
g *g
next *sudog
prev *sudog
elem unsafe.Pointer //
acquiretime int64
releasetime int64
ticket uint32
isSelect bool
success bool
parent *sudog // semaRoot binary tree
waitlink *sudog // g.waiting list or semaRoot
waittail *sudog // semaRoot
c *hchan // channel
}
1.2 创建channel原理
创建channel有两种:1.带缓冲的channel,2.不带缓冲的channel
带缓冲:异步,缓冲区没有满之前,不会阻塞
不带缓冲:同步,写和读同步。否则阻塞
ch:=make(chan int,1) //带缓冲
ch:=make(chan int) //不带缓冲
创建时的策略:
如果是无缓冲的channel,会直接给hchan分配内存
如果是有缓冲的channel,并且元素不包含指针,那么会为hchan和底层数组分配一段连续的地址
如果是有缓冲的channel,并且元素包含指针,那么会为hchan和底层数组分别分配地址
1.3 写入channel原理
写入操作,编译时会调用runtime.chansend函数
ch<-10
1.如果channel的读等待队列存在读的goroutine,将数据直接发送给第一个等待的G,唤醒接收的G。
2.如果channel的写等待队列不存在读的goroutine,
如果循环数组buf未满,那么将数据写入到循环队列队尾,sendx++
如果循环数组已满,这时会阻塞写入到流程,将当前的G加入写入等待队列,并挂起等待唤醒
1.4 读channel原理
读操作,编译时会调用runtime.chanrecv函数
<-ch
v:=<-ch
v,ok:=<-ch
for v:=rang ch{
fmt.println(v)
}
读出到环形队列buf成功:recvx++,释放buf锁
写入到环形队列buf成功:sendx++,释放buf锁
原理与写入相似
1.如果channel的写等待队列存在G,
如果是无缓冲的channel,直接从第一个写的G把数据拷贝给接收的G,唤醒写入的G,recvx++。
如果是有缓冲的G(循环数组有值),将循环数组的首位元素拷贝给接收的G,recvx++,将第一个写入的G的数据拷贝到循环数组的队尾,唤醒写入的G,sendx++。
如果循环数组为空,这时阻塞读的G,将当前读的G加入到读等待队列,并挂起等待唤醒
1.5 关闭channel原理
关闭channel,编译时会调用runtime.closechan函数
close(ch)
1.6 总结
hchan结构体主要组成部分有4个:
1.用来保存读写G之间传递到数据的环形数组:buf
2.用来记录此循环数组当前发送或者接收数据的下标值:sendx和recvx
3.用于保存该chan读和写阻塞被阻塞的goroutine队列,sendq和recvq
4.保证channel写入和读取数据时线性安全的锁:lock
2、map原理
2.1存储结构
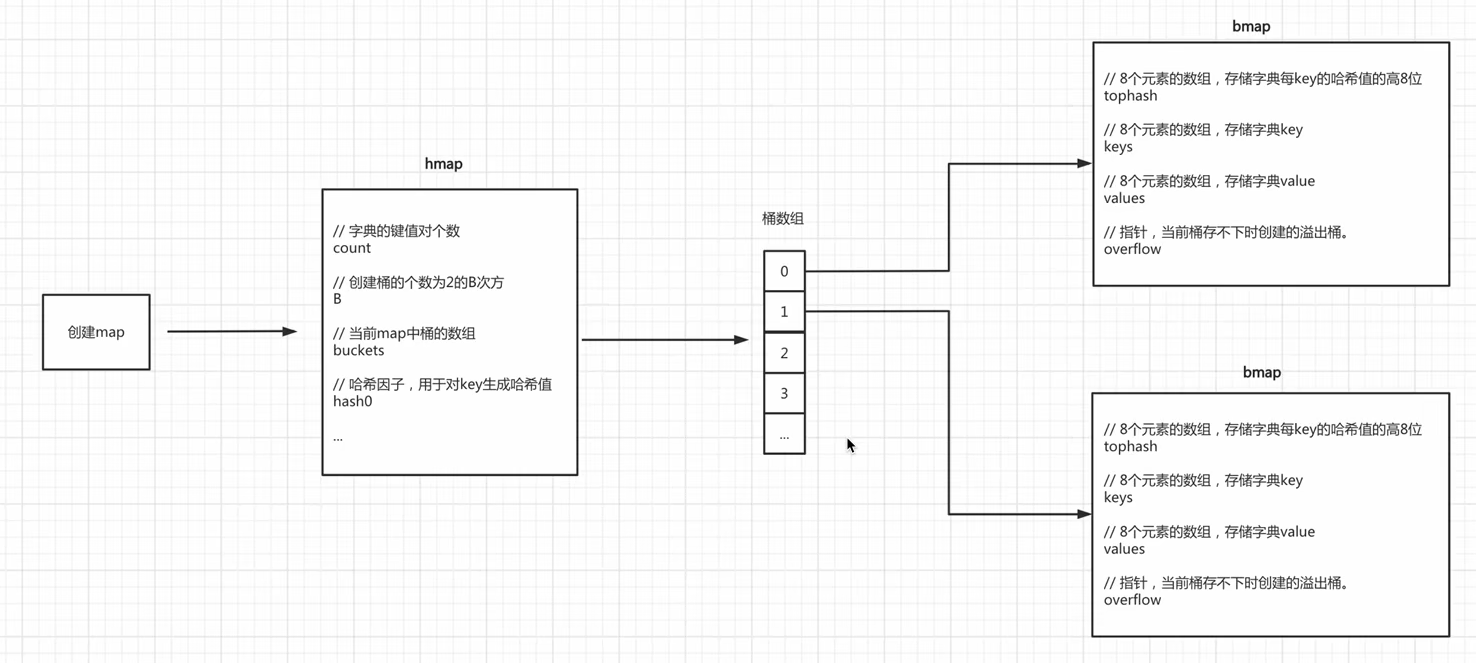
hmap:
count:字典健值对个数,len时直接返回count的值
B:创建桶(bmap)的个数,2^B
buckets:当前map中桶(bmap)的数组,2^B
hash0:哈希因子,用于对key生成哈希值。这里hash值为64位二进制(0101001)
bmap:最多8个元素的健值对
tophash:8个元素数组,存储key的hash值高8位
keys:8个元素数组,存储key
values:8个元素数组,存储value
overflow:指针,当前桶存不下时的溢出桶
2.2初始化原理
info:=make(map[string]string,10) //初始化容量为10的map
第一步:创建hmap结构体对象
第二步:生成一个哈希因子hash0并复制到hmap对象中(用于后续为key创建hash值)
第三步:根据容量=10,根据算法规则创建B,当前B为1
第四步:根据B创建桶(bmap)并存放进buckets数组中,当前bmap数量为2
count/B(桶个数)>6.5,翻倍扩容
B的计算:
hint B bmap(桶)数量
0~8 0 1
9~13 1 2
13~26 2 4
2.3写入数据原理
info["name"]="Jeff"
在map中写入数据时,内部执行的流程为:
第一步:结合hash因子和健name生成哈希值,01010101011100011001,64位
第二步:获取哈希值的后B位,(上面的B在初始化已完成B的运算),并根据后B位的值来决定此健值对存放在哪个桶(bmap)中。
第三步:在上一步确定桶(bmap)之后,接下来就在桶中写入数据。获取哈希值的高8位写入tophash,将tophash,key,value分别写到桶中的三个数组中。如果桶已满,则通过overflow找到溢出桶,并在溢出桶中继续写入。
第四步:hmap的个数count++(map中的元素个数+1)
2.4读取数据原理
name:=info["name"]
在map中读取数据时,内部的执行流程为:
第一步:结合哈希因子和健name生成哈希值。
第二步:获取哈希值的后B位,并根据后B位的值来确定将此简直对存放在哪个桶中(bmap)
第三步:确定桶的位置之后,再根据哈希的高8位(tophash值),根据tophash和key去桶中查找数据。当前桶如果没有找到,则根据overflow再去溢出桶中找,均未找到则表示key不存在。
根据tophash定位到在数组中的下标索引位置,比如tophash的位置在数组第4位,那么key和value也都在各自数组的第4位。
2.5map扩容原理
在向map中添加数据时,当达到某个条件,则会引发map扩容。
扩容条件:
1.map中健值对个数(count)/B(bmap桶)个数>6.5,引发翻倍扩容。桶的个数=2^B,所以B+1了
2.使用了太多的溢出桶(溢出桶太多会导致map处理速度降低)
B<=15,已使用的溢出桶个数>=2^B时,引发等量扩容
B>15,已使用的溢出桶个数>=2^15时,引发等量扩容。
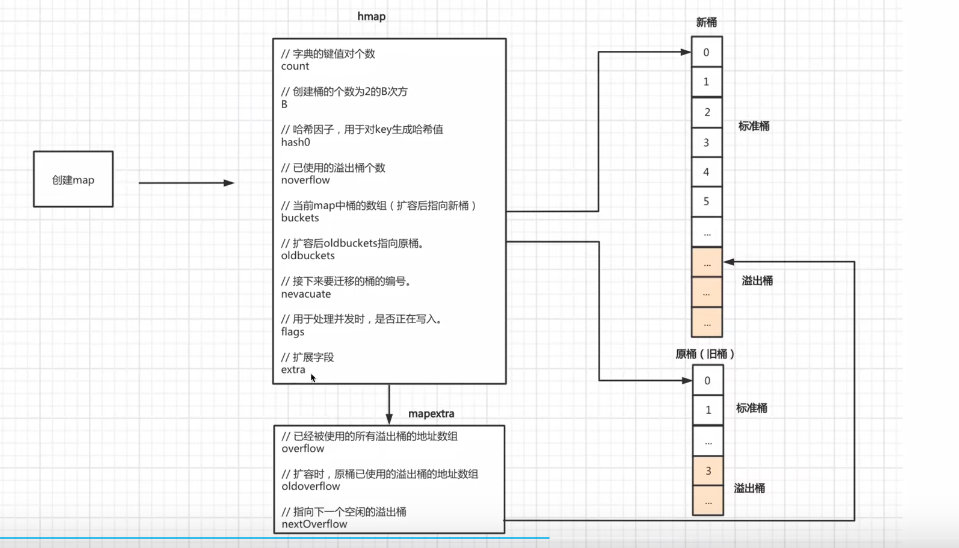
2.6map迁移原理
扩容之后,必然要伴随着数据迁移,即:将旧桶中的数据迁移到新桶中。
2.6.1翻倍扩容迁移原理
如果是翻倍扩容,那么迁移就是将桶中的数据分流至两个桶中(比列不定)
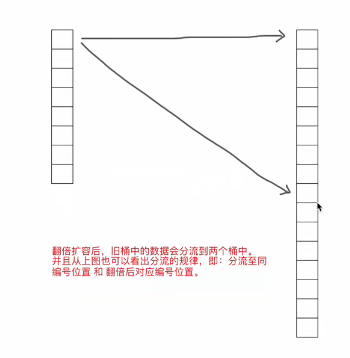
如何实现这种迁移呢?其实也很简单:
首先,我们要知道如果翻倍扩容条件(健值对个数(count)/桶(bmap)个数>6.5),则新桶个数是旧桶的2倍,即:map中的B值要+1(因为桶的个数等于2^B,而翻倍之后桶的个数就是(2^B)*2,也就是2^(B+1),所以新桶的B值=原桶B+1)
迁移时会遍历某个旧桶中的所有key(包括溢出桶),并根据key的hash值的低B位来决定将此健值对分流到哪个新桶中。ps:key的前后hash值都一样,低B位不一样。因为B已经+1了
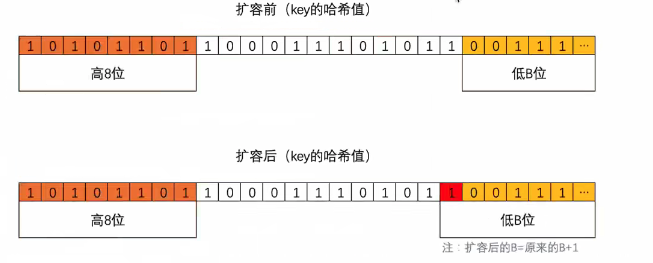
扩容后,B的值在原来的基础上,也就意味着通过多一位来计算此健值对要分流到新桶的位置,如上图。
当新增位(红色)的值为0时,二进制表示的数和原来相同,则数据会迁移到与旧桶的编号一致的位置。
当新增位(红色)的值为1时,二进制表示的数大一倍,则数据会迁移到翻倍后对应的编号位置。
ps:同一个桶中key的哈希值的低B位一定相同,不然不会放在同一个桶中,所有同一个桶中黄色标记的位置都是相同的。
eg:
旧桶个数为32,翻倍后新桶个数为64。
再重新计算旧桶中的所有key哈希值时,红色为要能是0或1,所以桶中的所有数据的后B位只能是以下两种情况:
- 000111 [7],意味着要迁移到与旧桶编号一致的位置
- 100111 [39],意味着会迁移到翻倍后对应编号位置
2.6.2等量扩容迁移原理
如果是等量扩容(溢出桶太多引发的扩容),那么数据迁移机制就会比较简单,就是将旧桶(含溢出桶)中的健值对迁移到新桶中。
这种扩容和迁移到意义在于:当溢出桶比较多时,而每个桶中的数据又不多时,可以通过等量扩容和迁移让数据更紧凑,从而减少溢出桶。
eg:
一个桶中有两个溢出桶,第一个最开始肯定是满的,第二个也是满的,这样才会创建第三个溢出桶,第三个健值对个数为1。之后删除操作把第一个桶数据删了7个,第二个删了七个。那么总共健值对只有3个,这时候占用了3个桶。这时来个等量扩容,让数据更精凑,把两个溢出桶的数据放在第一个桶中,这样就减少了2个溢出桶,从而提升效率
ps:等量扩容B不变哦,这里的桶数量没有变化哦。桶的数量=2^B次方
3、GMP原理
3.1调度器的设计策略
调度器的设计策略:
复用线程:避免频繁的创建,销毁线程,而是对线程的复用,1.当本地G队列没有G时,优先从全局队列获取G(从全局获取G时需要加锁解锁),如果全局队列也没有,就从其他线程绑定的G队列偷取G,其他线程的G队列也没有获取到G,就睡眠或者销毁M 2.当M上正在执行的G阻塞了,此时M释放绑定的P(P和G队列还是绑定的),把绑定的P转移给其他空闲的线程执行。原本的M与G睡眠或者阻塞,当G需要执行时再放进G队列等待执行。
利用并行:GOMAXPROCS设置P的数量,最多有GOMAXPROCS个线程分布在多个CPU上同时运行。
抢占:一个goroutine最多占用CPU 10ms,防止其他goroutine饿死。
全局G队列:当创建协程时,优先放入P的本地G队列,当所有的本地G队列满了时,256,放入全局G队列(需要加锁解锁),然后从全局队列获取G,当全局队列没有G时,从其他P的G队列偷取G。
ps:P本地G队列大小为256,本地G满了才放入全局G队列
从全局队列获取的个数:
GQ:全局队列G的总长度 n=min(len(GQ)/GOMAXPROCS+1,len(GQ/2))
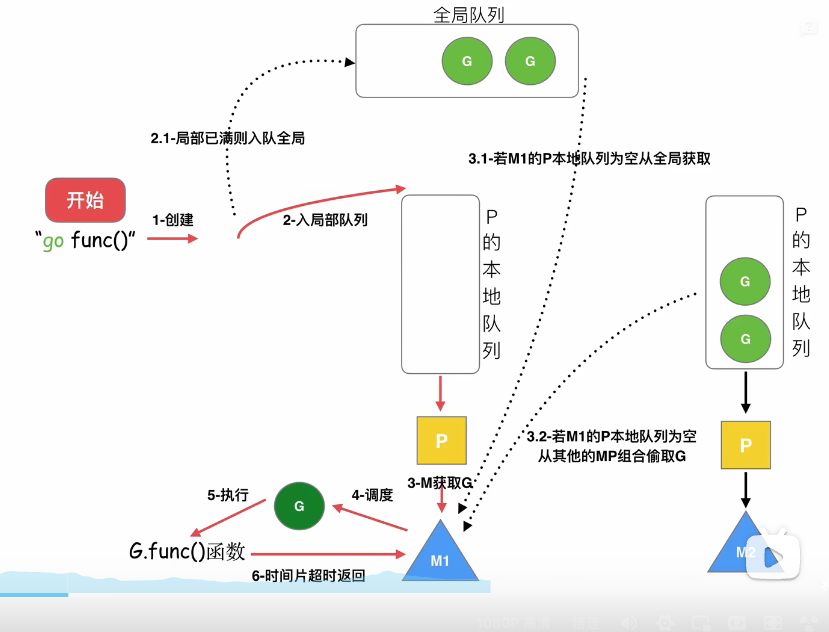
3.2执行go func()调度流程原理
第一步:执行go func()
第二步:创建一个G,优先加入到当前协程的G队列(如果是这个协程执行的),如果本地队列满了,则把G加入到全局队列。
第三步:P需要调度一个G给M执行,P优先从本地G队列获取一个G,如果本地队列没有G,则从其他P绑定的G偷取一个G来执行,如果其他队列也没有G,则从全局队列获取一个G执行。
第四步:M调度执行G,如果执行到G.func发送阻塞,那么M和P解绑,把P转移给其他的M执行。当G阻塞完了,M放入休眠M队列或者销毁,G寻找其他G队列,或者放入全局G队列,等待下次调度
ps:休眠队列中长期没有被唤醒,则被GC回收了
3.3一个G创建很多G的过程原理
首先:假设G的队列大小为4(实际为256),一个goroutine创建了8个goroutine
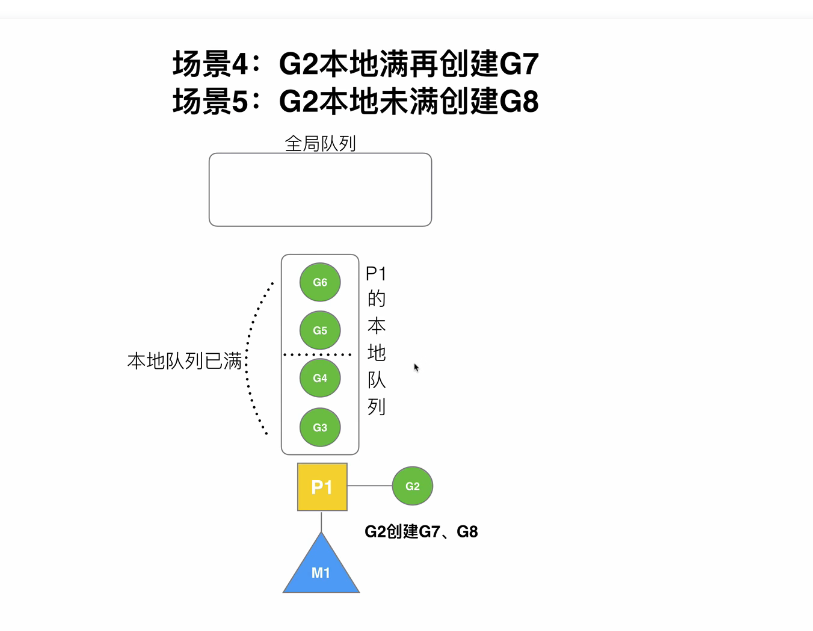
此时G队列已经放满了,再创建G7时,会把G的前半部分连同G7打乱一起放入全局队列
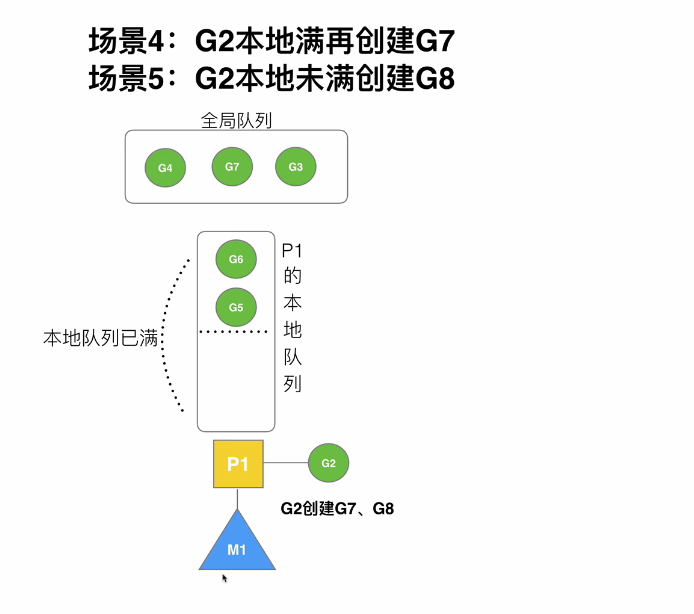
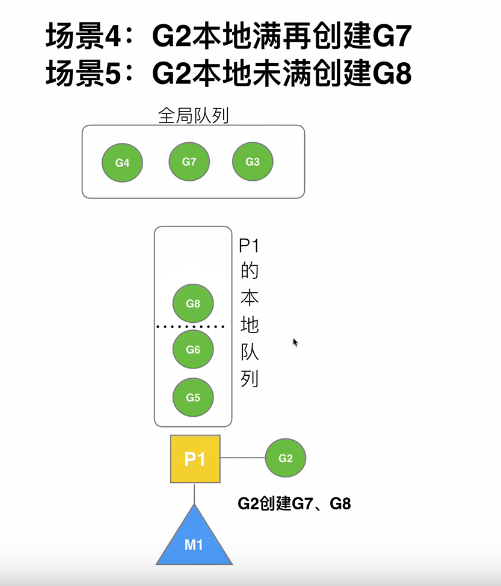
此时G队列G5,G6往前移,已经空了一半。再创建G8,会把G8直接加入G队列
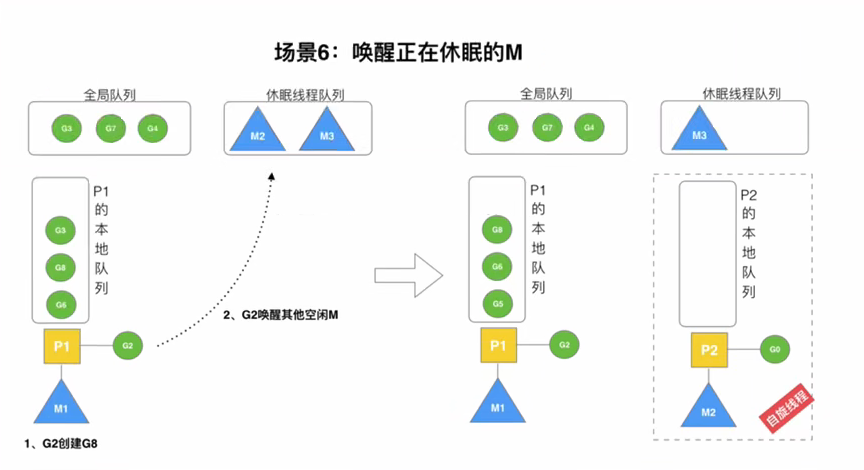
3.4唤醒正在休眠的M原理
规定:在创建G时,运行的G会尝试唤醒其他空闲的P和M组合去执行,从休眠的M队列唤醒M
假定G2唤醒了M2,M2绑定了P2,并运行Go,单P2本地队列没有G,M2此时称为:自旋线程,会优先去全局队列获取G,全局队列没有,才会去其他P的G队列偷取G来执行
从全局队列获取的个数:
GQ:全局队列G的总长度 n=min(len(GQ)/GOMAXPROCS+1,len(GQ/2))
3.5被唤醒的M从全局G队列取G原理
规定:在创建G时,运行的G会尝试唤醒其他空闲的P和M组合去执行,从休眠的M队列唤醒M
假定G2唤醒了M2,M2绑定了P2,并运行G,单P2本地队列没有G,M2此时称为:自旋线程,会优先去全局队列获取G,全局队列没有,才会去其他P的G队列偷取G来执行
从全局队列获取的个数:
GQ:全局队列G的总长度 n=min(len(GQ)/GOMAXPROCS+1,len(GQ/2))
ps:偷到G了,就不是自旋线程了
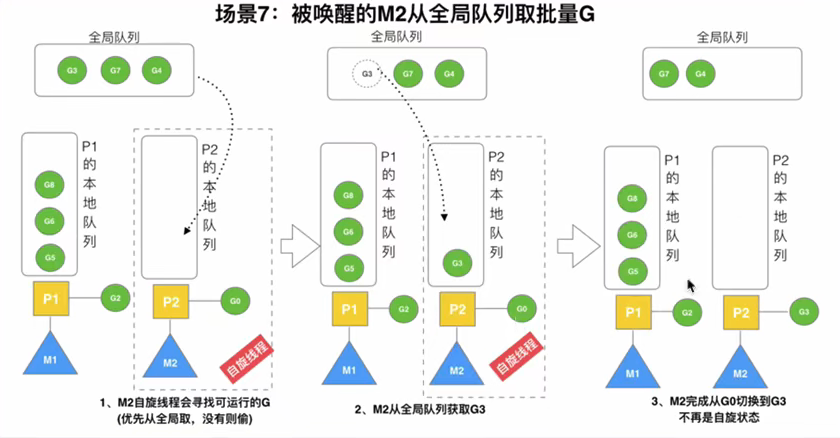
3.6M2从M1中偷取G原理
偷取条件:全局队列没有G了,就会从其他P的G队列偷取G.
偷取G的数量:其他P的G队列数量/2,取队列的后半部分全偷过来。
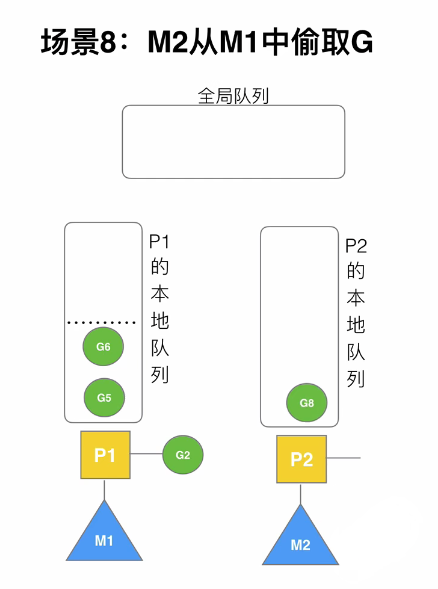
3.7自旋线程的最大限制
M的数量=GOMAXPROCS
自旋线程M+执行线程M<=GOMAXPROCS
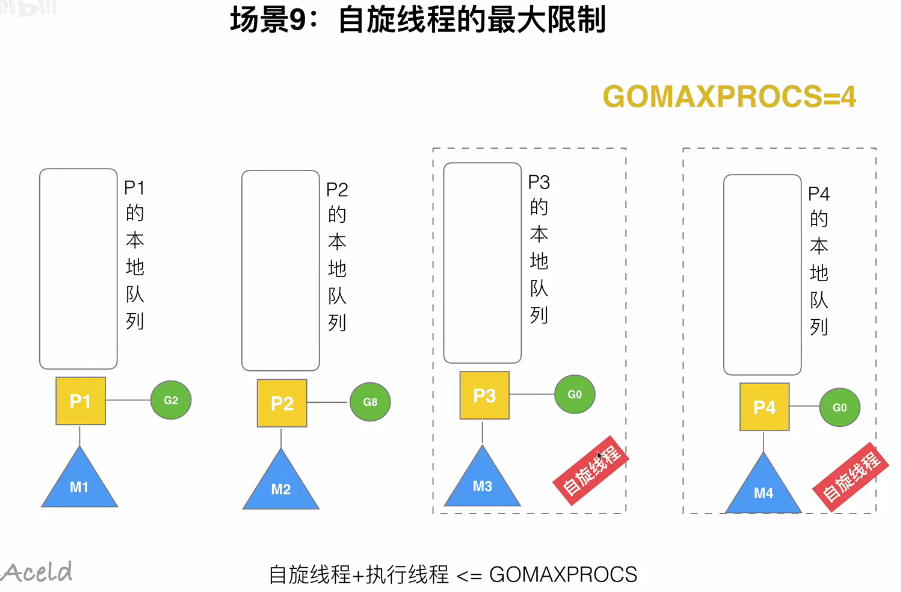
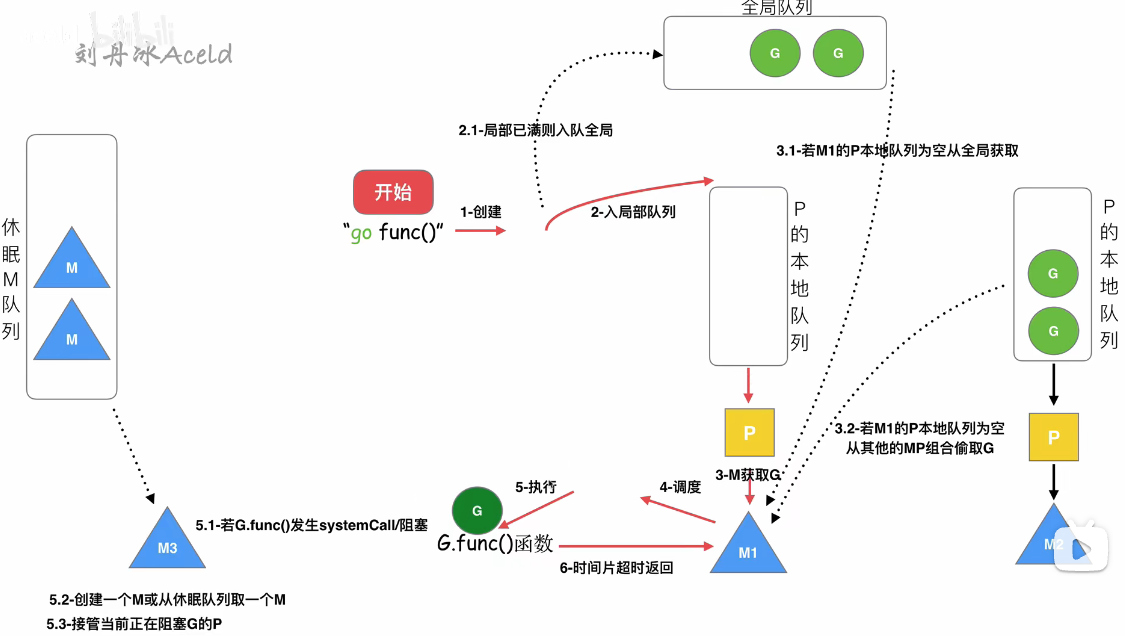
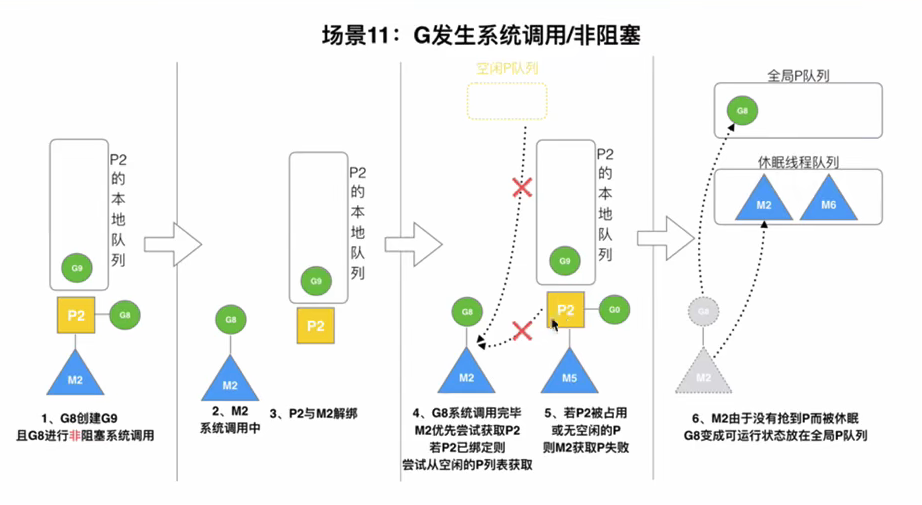
3.8G发送阻塞时,调度原理
M调度执行G,如果执行到G.func发送阻塞,那么M和P解绑,把P转移给其他的M执行。当G阻塞完了,M放入休眠M队列或者销毁,G寻找其他G队列,或者放入全局G队列,等待下次调度
假设G8阻塞,则G8停留在M2当前系统空间中,因为此时M2全部的堆栈信息都在为G8服务,所以M2不能再为P2服务,所以M2与P2解绑,P2自行去寻找一个M来绑定。先寻找休眠M队列,如果没有则把P放进空闲P队列,等待其他M来调度。
ps:P2为什么不绑定M3,M4?因为M3,M4是自旋线程,此时已经拥有P了。自旋线程是寻找G的
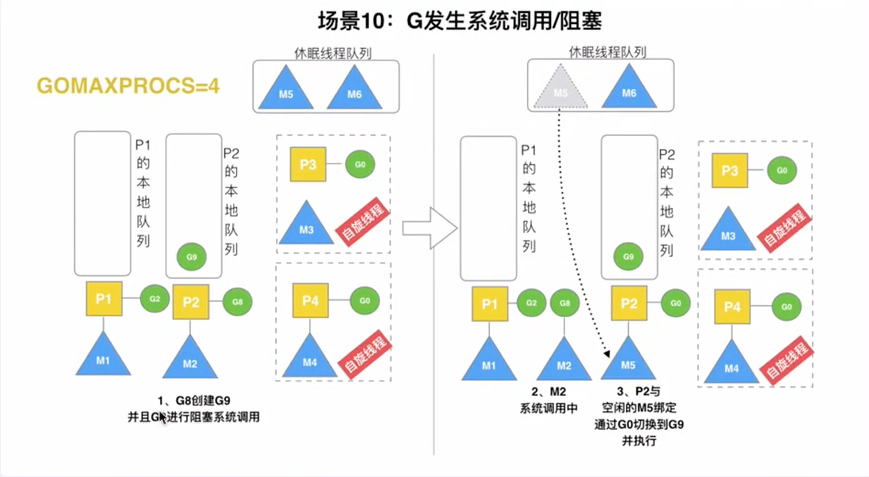
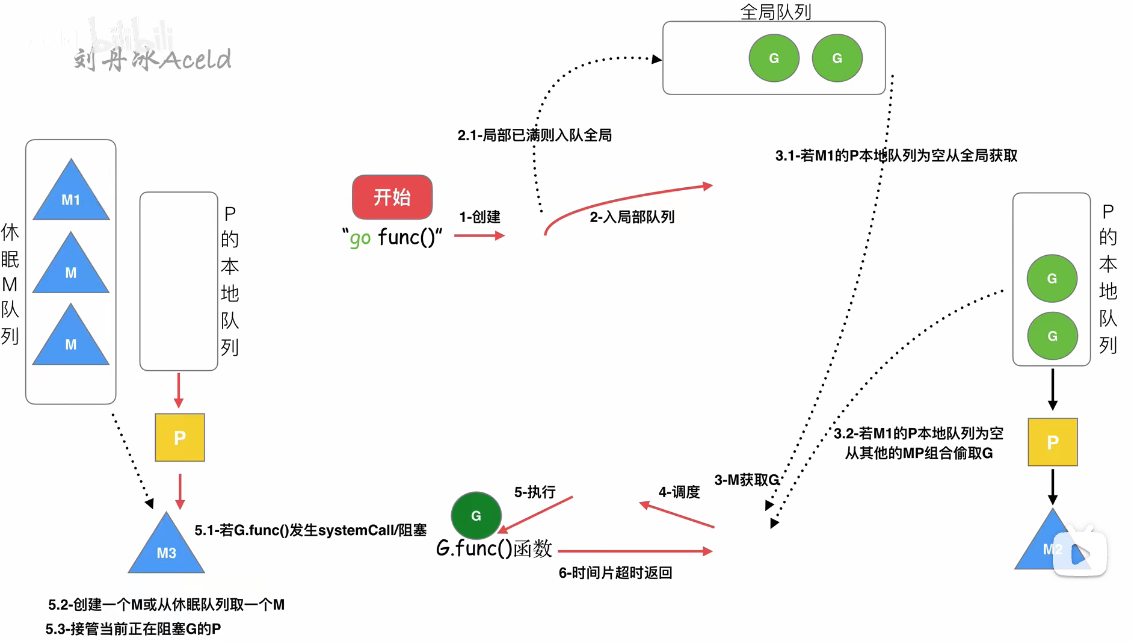
3.9G阻塞完之后,调度原理
G阻塞完之后:
第一步:M2会找P2(原配),发现P2已经被其他M绑定了
第二步:去找空闲P队列,没找到
第三步:M2和G2解绑,G2放入全局G队列,等待其他P调用
第四步:M2放入休眠队列
ps:休眠队列中长期没有被唤醒,则被GC回收了
4、mutex原理
4.1mutex结构体解析
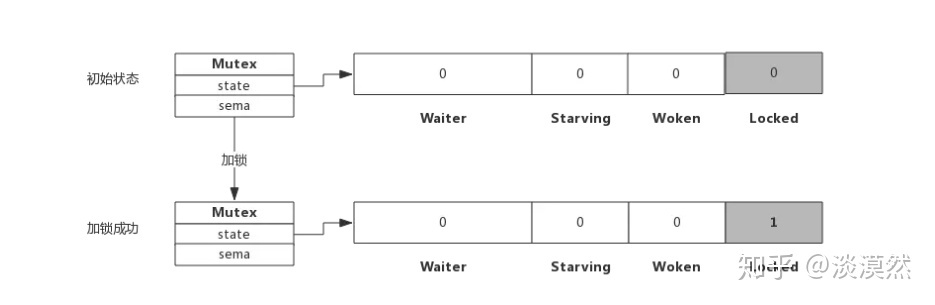
type Mutex Struct{
state int32 // 互斥锁的状态,原子操作actomic包操作该字段
sema uint32 // 信号量,等待队列
}
state:表示互斥锁的状态,后三位表示锁的状态,其他表示等待的goroutine数量。
sema表示信号量,协程阻塞等待该信号量来唤醒协程,解锁的协程释放该信号量来唤醒阻塞的协程
Locked:表示mutex是否已经锁定。1:锁定。 0:没有锁定
Woken:表示是否有协程已被唤醒,0:没有协程唤醒。1:有协程唤醒,正在加锁过程中
Starving:表示该mutex是否处于饥饿状态。0:正常模式。1:饥饿模式,表示有协程已经阻塞超过1ms
Waiter:等待等待加锁的G的队列个数(自旋之后未抢到锁会加入到此队列),协程解锁时根据此值来判断是否需要释放信号量
4.2正常模式工作原理
首先mutex有两种状态:正常模式,饥饿模式
一个加锁的goroutine抢锁过程
第一步:首先G进入自旋状态(最多4次自旋),尝试通过mutex的原子操作获得锁
第二步:若几次自旋之后仍没有获得锁,则通过信号量排队等待。所有的等待的G都会按照先入先出的顺序排队
第三步:当锁被释放,通过信号量唤醒第一个排队等待的G,但是第一个等待的G不会直接拥有锁。而是需要和所有(很多个G)处于自旋状态的G竞争,这种情况后来的进入自旋状态的G更容易获得锁,因为正在CPU上执行,比刚被唤醒的G(自旋没有获得锁,排队等待的G)更有优势,所以被唤醒的G大概率不会抢到锁,此时把这个G再次放入等待队列的头部。
第四步:当等待队列的G获取锁的时间大于1ms时,锁会进入饥饿模式
ps:正常模式自旋和排队并行更够有更高的吞吐量,因为频繁的挂起和唤醒G会带来较多的开销,但是又不能无限制的自旋,要把开销控制在较小的范围内。所以在正常模式下mutex有更好的性能,但是队列尾端的G迟迟抢不到锁。饥饿模式所有的G都需要排队。
4.3饥饿模式工作原理
首先mutex有两种状态:正常模式,饥饿模式
ps:抢锁先自旋,自旋没抢到进入队列,队列头部G唤醒再次抢锁,抢锁时间大于1ms锁进入饥饿模式
饥饿模式抢锁过程:
第一步:一个协程解锁,释放信号量
第二步:通过信号量唤醒等待队列头部第一个G直接获得锁,后来的G不会自旋,也不会尝试获得锁,而是直接加入到队列尾部等待。(先把锁给等待时间大于1ms的G)
饥饿模式切换到正常模式:
1.头部的G等待的时间小于1ms,锁进入正常模式
2.等待队列已经空了(队列空了,自然没有饥饿的G了),锁进入正常模式
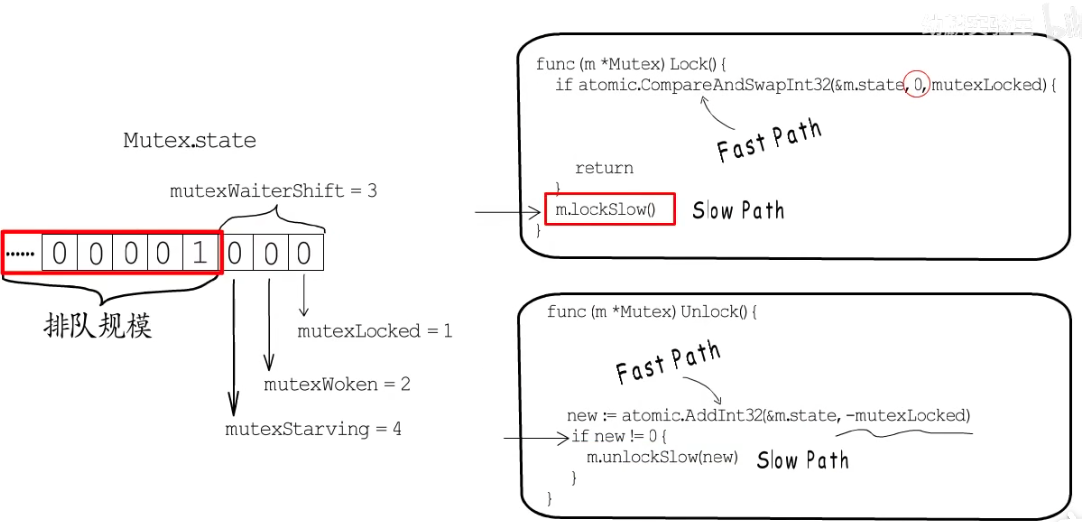
4.4抢锁/解锁的代码原理
抢锁:
第一步:通过原子操作CASInt32对锁的最后一位状态赋值,赋值成功代表抢到锁。
第二步:没有抢到锁(赋值失败),进入m.lockSlow(),让此协程进入等待队列,并休眠
ps: 原子操作CASInt32:类似乐观锁,先判断这个锁的状态是否为0,是0就改变为1,否则不变。
解锁:
第一步:通过原子操作atomic.AddInt32把锁的状态值设置为0。
第二步:判断new!=0,证明有协程在队列等待,需要释放信号唤醒一个协程
func demo() {
var state int32 = 2001
ne := atomic.AddInt32(&state, -1)
fmt.Println(ne) //2000,2表示有两个G在队列等待,0表示正常模式,0没有协程唤醒,0当前锁没有被占用
}
5、context原理
5.1context结构体
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key interface{}) interface{}
}
Deadline:返回绑定当前context的任务被取消的截止时间;如果没有设定期限,将返回ok == false。
Done:信号,当绑定当前context的任务被取消时,将返回一个关闭的channel信号;如果当前context不会被取消,将返回nil。
Err:
1.如果Done返回的channel没有关闭,将返回nil;
2.如果Done返回的channel已经关闭,将返回非空的值表示任务结束的原因。
3.如果是context被取消,Err将返回Canceled;
4.如果是context超时,Err将返回DeadlineExceeded。
Value:返回context存储的键值对中当前key对应的值,如果没有对应的key,则返回nil。
5.2context核心原理
context包的核心原理:链式传递context,基于context构造新的context
核心接口:
ctx,err:=context.Background() //通常用于主函数,初始化以及测试,作为顶层的context
ctx:=context.TODO() //不确定使用什么用context的时候才会使用
ctx:=context.WithValue(context.Background(),"name","jeff")//向context添加键值
name := ctx.Value("name") //向context取值
ctx, cancel := context.WithCancel(context.Background()) //可取消的contex,调用cancel()取消,取消之后 <-ctx.Done()可以被触发,用于监听
监听ctx有没有被关闭
func waitCancel(ctx context.Context, i int) {
for {
time.Sleep(time.Second)
select {
case <-ctx.Done():
fmt.Printf("%d end\n", i)
return
default:
fmt.Printf("%d do\n", i)
}
}
}
OSI7层协议
websocket
http
udp
tcp
内存逃逸
栈:由系统申请和释放,不会有额外的性能开销。比如局部变量
堆:在堆上的内存需要GC管理回收,GC将带来额外的性能开销。
内存逃逸:由栈逃逸到堆
逃逸条件:变量在函数结束时,仍然想要使用这个变量。比如全局变量
逃逸机制:
编辑器会根据变量是否被外部引用来决定是否逃逸:
1.如果函数外部没有引用,则优先放到栈中
2.如果函数外部存在引用,则必定放在堆中
3.如果栈放不下,则必定放在堆上
总结:
1.栈上分配内存比堆中分配内存效率更高
2.栈上分配的内存不需要GC处理,因为函数结束就自动释放了。而堆需要GC处理
3.逃逸分析的目的是决定内存分配地址是堆还是栈
4.逃逸分析是在编译阶段完成
因为无论变量的大小,只要是指针变量都会在堆上分配,所以对于小变量我们还是使用值传递效率更高,因为指针传递会分配到堆,会增加GC的压力
源码(chan,map,GMP,mutex,context)的更多相关文章
- jdk1.8.0_45源码解读——Map接口和AbstractMap抽象类的实现
jdk1.8.0_45源码解读——Map接口和AbstractMap抽象类的实现 一. Map架构 如上图:(01) Map 是映射接口,Map中存储的内容是键值对(key-value).(02) A ...
- requirejs源码分析: requirejs 方法–2. context.require(deps, callback, errback);
上一篇 requirejs源码分析: requirejs 方法–1. 主入口 中的return context.require(deps, callback, errback); 调用的是make ...
- 【大数据】深入源码解析Map Reduce的架构
这几天学习了MapReduce,我参照资料,自己又画了两张MapReduce的架构图. 这里我根据架构图以及对应的源码,来解释一次分布式MapReduce的计算到底是怎么工作的. 话不多说,开始! ...
- STL源码中map和set中key值不能修改的实现
前言 最近正好刚刚看完,<stl源码剖析>这本书的map和set的源码部分.但是看完之后又突然发现,之前怎么没有注意到map和set容器中key不能修改是怎么实现的.故,特此整理如下. s ...
- 给jdk写注释系列之jdk1.6容器(6)-HashSet源码解析&Map迭代器
今天的主角是HashSet,Set是什么东东,当然也是一种java容器了. 现在再看到Hash心底里有没有会心一笑呢,这里不再赘述hash的概念原理等一大堆东西了(不懂得需要先回去看下Has ...
- java读源码 之 map源码分析(HashMap)二
在上篇文章中,我已经向大家介绍了HashMap的一些基础结构,相信看过文章的同学们,应该对其有一个大致了了解了,这篇文章我们继续探究它的一些内部机制,包括构造函数,字段等等~ 字段分析: // 默 ...
- java读源码 之 map源码分析(HashMap,图解)一
开篇之前,先说几句题外话,写博客也一年多了,一直没找到一种好的输出方式,博客质量其实也不高,很多时候都是赶着写出来的,最近也思考了很多,以后的博客也会更注重质量,同时也尽量写的不那么生硬,能让大家 ...
- Java容器 | 基于源码分析Map集合体系
一.容器之Map集合 集合体系的源码中,Map中的HashMap的设计堪称最经典,涉及数据结构.编程思想.哈希计算等等,在日常开发中对于一些源码的思想进行参考借鉴还是很有必要的. 基础:元素增查删.容 ...
- 【JDK】JDK源码分析-Map
Map 接口 Map 是一个接口,它表示一种“键-值(key-value)”映射的对象(Entry),其中键是不重复的(值可以重复),且最多映射到一个值(可以理解为“映射”或者“字典”). Map 常 ...
随机推荐
- $.fn解析
$.fn是指jquery的命名空间,加上fn上的方法及属性,会对jquery实例每一个有效. 如扩展$.fn.abc(),即$.fn.abc()是对jquery扩展了一个abc方法,那么后面你的每一个 ...
- Android (微信扫码登录) 获取微信二维码+扫码登录
话不多说 直接上菜! 一.因为是微信扫码登录,所有要在微信开放平台 微信开放平台 (qq.com) 进行注册----- 如下 1.资源中心 里面也有详细的官方讲解,里面也有demo 可以下载 2 ...
- 用console画条龙?
相识 console一定是各位前端er最熟悉的小伙伴了,无论是console控制台,还是console对象,做前端做久了,打开一个网页总是莫名自然的顺手打开控制台,有些调皮的网站还会故意在控制台输出一 ...
- URL网络编程
package com.atguigu.java1; import java.io.FileOutputStream; import java.io.IOException; import java. ...
- JDBC(Java Database Connectivity)编写步骤
JDBC是代表一组公共的接口,是Java连接数据库技术: JDBC中的这些公共接口和DBMS数据库厂商提供的实现类(驱动jar),是为了实现Java代码可以连接DBMS,并且操作它里面的数据而声名的. ...
- 使用Docker搭建自己的Bitwarden密码管理服务
相信身为开发者,总会在各种网站中注册账号,为了方面记忆可以使用同一套账号密码进行注册,自从前段时间学习通时间撞库后有些人已经开始疯狂改密码了,可是密码一多就很难记忆,最好找个地方存储账户信息 我曾经使 ...
- 7.5 The Morning after Halloween
本题主要是存储的问题,在存储上笔者原先的代码占用了大量的内存空间 这边笔者采用暴力的思想直接硬开所有情况的16^6的数组来存储该问题,当然这在时间上是十分浪费的,因为初始化实在太慢了,剩下的就是状态转 ...
- 如何在Rust中打印变量的类型?
#![feature(core_intrinsics)] fn print_type_of<T>(_: T) { println!("{}", unsafe { std ...
- 关于 CMS 垃圾回收器,你真的懂了吗?
大家好,我是树哥. 前段时间有个小伙伴去面试,被问到了 CMS 垃圾回收器的详细内容,没答出来.实际上,CMS 垃圾回收器是回收器历史上很重要的一个节点,其开启了 GC 回收器关注 GC 停顿时间的历 ...
- 一篇文章带你搞定BFC~
一.什么是BFC 是 Block Formatting Contexts 的缩写,名为"块级格式化上下文". 是指浏览器中创建了一个独立的渲染区域,并且拥有一套渲染规则,他决定了其 ...