SQL 入门了解
SQL
随着应用程序的功能越来越复杂,数据量越来越大,如何管理这些数据就成了大问题:
- 读写文件并解析出数据需要大量重复代码;
- 从成千上万的数据中快速查询出指定数据需要复杂的逻辑。
如果每个应用程序都各自写自己的读写数据的代码,一方面效率低,容易出错,另一方面,每个应用程序访问数据的接口都不相同,数据难以复用。
所以,数据库作为一种专门管理数据的软件就出现了。应用程序不需要自己管理数据,而是通过数据库软件提供的接口来读写数据。至于数据本身如何存储到文件,那是数据库软件的事情,应用程序自己并不关心:
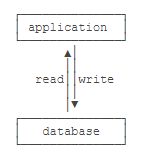
SQL是结构化查询语言的缩写,用来访问和操作数据库系统。SQL语句既可以查询数据库中的数据,也可以添加、更新和删除数据库中的数据,还可以对数据库进行管理和维护操作。不同的数据库,都支持SQL,这样,我们通过学习SQL这一种语言,就可以操作各种不同的数据库。
虽然SQL已经被ANSI组织定义为标准,不幸地是,各个不同的数据库对标准的SQL支持不太一致。并且,大部分数据库都在标准的SQL上做了扩展。也就是说,如果只使用标准SQL,理论上所有数据库都可以支持,但如果使用某个特定数据库的扩展SQL,换一个数据库就不能执行了。例如,Oracle把自己扩展的SQL称为PL/SQL,Microsoft把自己扩展的SQL称为T-SQL。
现实情况是,如果我们只使用标准SQL的核心功能,那么所有数据库通常都可以执行。不常用的SQL功能,不同的数据库支持的程度都不一样。而各个数据库支持的各自扩展的功能,通常我们把它们称之为“方言”。
总的来说,SQL语言定义了这么几种操作数据库的能力:
DDL:Data Definition Language
DDL允许用户定义数据,也就是创建表、删除表、修改表结构这些操作。通常,DDL由数据库管理员执行。
DML:Data Manipulation Language
DML为用户提供添加、删除、更新数据的能力,这些是应用程序对数据库的日常操作。
DQL:Data Query Language
DQL允许用户查询数据,这也是通常最频繁的数据库日常操作。
一、数据模型
数据库按照数据结构来组织、存储和管理数据,实际上,数据库一共有三种模型:
- 层次模型
- 网状模型
- 关系模型
层次模型就是以“上下级”的层次关系来组织数据的一种方式,层次模型的数据结构看起来就像一颗树:

网状模型把每个数据节点和其他很多节点都连接起来,它的数据结构看起来就像很多城市之间的路网:

关系模型把数据看作是一个二维表格,任何数据都可以通过行号+列号来唯一确定,它的数据模型看起来就是一个Excel表:
主流关系数据库
目前,主流的关系数据库主要分为以下几类:
- 商用数据库,例如:Oracle,SQL Server,DB2等;
- 开源数据库,例如:MySQL,PostgreSQL等;
- 桌面数据库,以微软Access为代表,适合桌面应用程序使用;
- 嵌入式数据库,以Sqlite为代表,适合手机应用和桌面程序。
二、数据类型
对于一个关系表,除了定义每一列的名称外,还需要定义每一列的数据类型。关系数据库支持的标准数据类型包括数值、字符串、时间等:
| 名称 | 类型 | 说明 |
|---|---|---|
| INT | 整型 | 4字节整数类型,范围约+/-21亿 |
| BIGINT | 长整型 | 8字节整数类型,范围约+/-922亿亿 |
| REAL | 浮点型 | 4字节浮点数,范围约+/-1038 |
| DOUBLE | 浮点型 | 8字节浮点数,范围约+/-10308 |
| DECIMAL(M,N) | 高精度小数 | 由用户指定精度的小数,例如,DECIMAL(20,10)表示一共20位,其中小数10位,通常用于财务计算 |
| CHAR(N) | 定长字符串 | 存储指定长度的字符串,例如,CHAR(100)总是存储100个字符的字符串 |
| VARCHAR(N) | 变长字符串 | 存储可变长度的字符串,例如,VARCHAR(100)可以存储0~100个字符的字符串 |
| BOOLEAN | 布尔类型 | 存储True或者False |
| DATE | 日期类型 | 存储日期,例如,2018-06-22 |
| TIME | 时间类型 | 存储时间,例如,12:20:59 |
| DATETIME | 日期和时间类型 | 存储日期+时间,例如,2018-06-22 12:20:59 |
上面的表中列举了最常用的数据类型。很多数据类型还有别名,例如,REAL又可以写成FLOAT(24)。还有一些不常用的数据类型,例如,TINYINT(范围在0~255)。各数据库厂商还会支持特定的数据类型,例如JSON。
选择数据类型的时候,要根据业务规则选择合适的类型。通常来说,BIGINT能满足整数存储的需求,VARCHAR(N)能满足字符串存储的需求,这两种类型是使用最广泛的。
三、数据查询
3.1、基本查询
SELECT * FROM <表名>; -->>查询这个表的数据
使用SELECT * FROM <表名>;时,SELECT是关键字,表示将要执行的一个查询,*表示"所有列",FROM表示将要从那个表查询
SELECT不仅可以查询表,还能用作计算,如SELECT 10+20,可以计算出结果为30,但是,不带FROM的SELECT语句还有一个用途,就是用来判断当前到数据库的连接是否有效。许多检测工具会执行一条SELECT 1;来从测试数据库是否连接。
注:查询结果是一个二维表,它包含列名和每一行数据。
3.2、条件查询
使用SELECT * FROM <表名>可以查询到一张表的所有记录。但是,很多时候,我们并不希望获得所有记录,而是根据条件选择性地获取指定条件的记录。
SELECT语句可以通过WHERE条件来设定查询条件,查询结果是满足查询条件的记录。
SELECT * FROM <表名> WHERE <条件表达式> ;
条件表达式可以分为: 1、<条件一> AND <条件二> --> 表达满足条件一并且满足条件二。 如:SELECT * FROM students WHERE score >= 80 AND gender = ' M ';
2、<条件一> OR <条件二> --> 表达满足条件一或者满足条件二。 如:SELECT * FROM students WHERE score >= 80 OR gender=' M ';
3、 NOT <条件> --> 表达"不符合该条件" 。 如:SELECT * FROM students WHERE NOT class_id = 2;
4、可以使用 " ( ) "包含上面多个条件。 如:SELECT * FROM students WHERE ( score < 80 OR score > 90 ) AND gender = ' M ';
5、BETWEEN --> BETWEEN 60 AND 90 表示在60~90之前(包含)的查询。
注:如果不加括号,条件运算按照NOT、AND、OR的优先级进行,即NOT 优先级最高,其次AND,最后OR 。
3.3、投影查询
使用SELECT * FROM <表名> WHERE <条件>可以选出表中的若干条记录。我们注意到返回的二维表结构和原表是相同的,即结果集的所有列与原表的所有列都一一对应。
如果我们只希望返回某些列的数据,而不是所有列的数据,我们可以用SELECT 列1, 列2, 列3 FROM ...,让结果集仅包含指定列。这种操作称为投影查询。
SELECT <列名>, <列名> <更换的列名> FROM <表名>;
使用SELECT 列1, 列2, 列3 FROM ...时,还可以给每一列起个别名,这样,结果集的列名就可以与原表的列名不同。它的语法是SELECT 列1 别名1, 列2 别名2, 列3 别名3 FROM ...。
如:SELECT id, score points, name FROM students; 这里查询了id,score,name并且把score重命名为point,而id,name列名保持不变。
3.4、排序
使用SELECT查询时,你可能注意到,查询结果集通常是按照id排序的,也就是根据主键排序。这也是大部分数据库的做法。如果我们要根据其他条件排序怎么办?可以加上ORDER BY子句。
SELECT <列名>,...,<列名> FROM <表名> ORDER BY <列名>;
如:SELECT id, name, gender, score FROM students ORDER BY score; -> 这里查询了id,name,gender和score,但结果是按照score的低到高排序的。
如果score列有相同的数据,要进一步排序,可以继续添加列名。例如,使用ORDER BY score DESC, gender表示先按score列倒序,如果有相同分数的,再按gender列排序
注:ORDER BY 排序是默认从低到高,若要从高到低则需要在ORDER BY后面添加DESC关键字(ASC升序,DESC降序)。 即 SELECT id, name, gender, score FROM students ORDER BY score DESC;
如果有WHERE子句,那么ORDER BY子句要放到WHERE子句后面。
3.5、分页查询
使用SELECT查询时,如果结果集数据量很大,比如几万行数据,放在一个页面显示的话数据量太大,不好查看,不如分页显示,每次显示100条。
要实现分页功能,实际上就是从结果集中显示第1~100条记录作为第1页,显示第101~200条记录作为第2页,以此类推。
SELECT * FROM <表名> LIMIT <X> OFFSET <Y> ; X ->每页显示最多几条数据,Y -> 显示第几条数据索引值
如:SELECT id, name, gender, score FROM students ORDER BY score DESC LIMIT 3 OFFSET 0; -> 每页显示3行,显示第一页,数据索引从0开始。如果要查询第二页,那么需要跳过前三条数据,即需要OFFSET设为3。如此类推
注:OFFSET超过了查询的最大数量并不会报错,而是得到一个空的结果集。
OFFSET是可选的,如果只写LIMIT 10,那么相当于LIMIT 10 OFFSET 0。(数据总量为10条)分页查询需要先确定每页的数量和当前页数,然后确定LIMIT和OFFSET的值。
3.6、聚合查询
对于统计总数、平均数这类计算,SQL提供了专门的聚合函数,使用聚合函数进行查询,就是聚合查询,它可以快速获得结果。
SELECT <函数>(<列名>) <新列名> FROM <表名>;
所有的UDAF(即聚合函数)都应该支持分组查询,内置的聚合函数有:
| 函数 | 说明 |
| COUNT | 统计记录数 注意和count(*)的区别 |
| SUN | 某一列的总值,该列必须为数值类型 |
| AVG | 某一列的平均值,该列必须为数值类型 |
| MAX | 最大值 |
| MIN | 最小值 |
| FIRST | 第一条记录 |
| LAST | 最后一条记录 |
WHERE条件没有匹配到任何行,COUNT()会返回0,而SUM()、AVG()、MIN()和MAX()会返回NULL。
GROUP BY
SELECT <列名>, COUNT(*) <新列名> FROM <表名> GROUP BY <列名>; (这里两个列名是同一个列名,先由GROUP BY将表根据列名进行分组在逐一进行COUNT统计)
如:SELECT class_id, COUNT(*) num FROM students GROUP BY class_id;
若将那么放入其中,即SELECT name, class_id, COUNT(*) num FROM students GROUP BY class_id;返回的结果集中name的值会为NULL。
因为在任意一个分组中,只有class_id都相同,name是不同的,SQL引擎不能把多个name的值放入一行记录中。因此,聚合查询的列中,只能放入分组的列。
3.6、多表查询
四、增、删、改
4.1、增(INSERT INTO)
INSERT INTO <表名> (字段1,字段2,...)VALUES (值1,值2,...);
| id | class_id | name | gender | score |
|---|---|---|---|---|
| 1 | 1 | 小明 | M | 90 |
| 2 | 1 | 小红 | F | 95 |
| 3 | 1 | 小蓝 | M | 88 |
students表插入一条新记录,先列举出需要插入的字段名称,然后在VALUES子句中依次写出对应字段的值:| id | class_id | name | gender | score |
|---|---|---|---|---|
| 1 | 1 | 小明 | M | 90 |
| 2 | 1 | 小红 | F | 95 |
| 3 | 1 | 小蓝 | M | 88 |
| 4 | 2 | 小绿 | M | 80 |
注:1、我们并没有列出id字段,也没有列出id字段对应的值,这是因为id字段是一个自增主键,它的值可以由数据库自己推算出来。此外,如果一个字段有默认值,那么在INSERT语句中也可以不出现。
2、字段顺序不必和数据库表的字段顺序一致,但值的顺序必须和字段顺序一致。也就是说,可以写INSERT INTO students (score , gender , name , class_id) ...,但是对应的VALUES就得变成(80, 'M', '小绿', 2)。
4.2、删(DELETE)
DELETE FROM <表名> WHERE <条件>;
注意到DELETE语句的WHERE条件也是用来筛选需要删除的行,因此可以通过条件的筛选一次删除多条记录。
若WHERE没有匹配到合适的记录,DELETE不会报错,当然也不会有数据被删除。
最后,要注意不带WHERE筛选条件的DELETE语句会删除整个表的数据。
4.3、改(UPDATE)
UPDATE <表名> SET 字段1=值1, 字段2=值2, ... WHERE ...;
| id | class_id | name | gender | score |
|---|---|---|---|---|
| 1 | 1 | 小明 | M | 66 |
students表id=1的记录的name和score这两个字段,先写出UPDATE students SET name='大明', score=66,然后在WHERE子句中写出需要更新的行的筛选条件id=1| id | class_id | name | gender | score |
|---|---|---|---|---|
| 1 | 1 | 大明 | M | 66 |
SQL 入门了解的更多相关文章
- SQL入门语句之ORDER BY 和GROUP BY
一.SQL入门语句之ORDER BY ORDER BY 是用来基于一个或多个列按升序或降序顺序排列数据 1.从数据库表获取全部数据按字段A的升序排列 select *from table_name o ...
- SQL入门语句之LIKE、GLOB和LIMIT
一.SQL入门语句之LIKE LIKE用来匹配通配符指定模式的文本值.如果搜索表达式与模式表达式匹配,LIKE 运算符将返回真(true),也就是 1.这里有两个通配符与 LIKE 运算符一起使用,百 ...
- SQL入门语句之SELECT和WHERE
一.SQL入门语句之SELECT SELECT语句用于从数据库表中获取数据,结果表的形式返回数据.这些结果表也被称为结果集 1.从数据库表中取部分字段 select 字段A,字段B from tabl ...
- SQL入门语句之INSERT、UPDATE和DELETE
一.SQL入门语句之INSERT insert语句的功能是向数据库的某个表中插入一个新的数据行 1.根据对应的字段插入相对应的值 insert into table_name(字段A, 字段B, 字段 ...
- SQL入门经典(十) 之事务
事务是什么?事务关键在与其原子性.原子性概念是指可以把一些事情当作一个执行单元来看待.从数据库角度看待.他是指应该全部执行或者全部不执行一条或多条语句的最小组合.当处理数据时候经常确保一件事发生另一件 ...
- SQL入门经典(一)之简介
今天是我第一天开通博客,也是我的第一篇博客.以后为大家带来第一篇关于学习技术性文章,这段时间会为大家带来是SQL入门学习.希望大家坚持读下去,因为学历有限.我也是初学者.语言表达能力不好和知识点不足, ...
- SQL入门
# SQL入门 数据库表 一个数据库(database)通常包含一个或多个表(table). 每一个表都有一个名字标识. 表单包含数据的记录(行). 一些重要的SQL命令(常用的吧) 命令 说明 ...
- Linq To sql入门练习 Lambda表达式基础
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; usin ...
- sql数据黑马程序员——SQL入门
最近研究sql数据,稍微总结一下,以后继续补充: ---------------------- ASP.Net+Android+IO开辟S..Net培训.等待与您交流! --------------- ...
- 可能是最好的SQL入门教程
个人博客:这可能是最好的SQL入门教程
随机推荐
- SAP SD-销售模式-寄售(客户寄售)
SAP SD-销售模式-寄售(客户寄售) http://blog.sina.com.cn/s/blog_a440b7ee01014kgq.html http://www.doc88.com/p-23 ...
- 在客户端先通过JS验证后再将表单提交到服务器
问题:想要在客户端先通过JS验证后再将表单提交到服务器 参考资料: jQuery 事件 - submit() 方法 试验过程: 服务器端使用PHP <html> <head> ...
- 调试.vs08
1.vs2008 在调试的时候出现如下状况: 关键字:“不会命中断点.源代码与原始版本不同.”(ZC:我的情况是 main.cpp里面的断点是有效的,但是执行到另一个cpp里面时 这个文件里面的断点都 ...
- Jfinal集成Spring
JFinal框架也整合了spring框架,下面实现JFinal怎么去配置Spring框架.在JFinal中整合Spring使用到的类是SpringPlugin和IocInterceptor类 Spri ...
- postman(三):添加断言
进行接口测试时,添加断言时必不可少的,断言就是判断响应内容与预期返回是否一致 进行接口测试时,添加断言时必不可少的,断言就是判断响应内容与预期返回是否一致 postman可以在请求模块的Tests ...
- Go 安装 sqlite3驱动报错
问题:最近在使用Go做一个博客示例,在使用go get 安装 sqlIite3的驱动遇到下面的问题(cc1.exe: sorry, unimplemented: 64-bit mode not com ...
- fcn+caffe+voc2012实验记录
参考博客: http://blog.csdn.net/haoji007/article/details/77148374 http://blog.csdn.net/jacke121/article/d ...
- 安卓MVP框架
一.理解MVP 原文地址 我的Demo 效果图: 项目结构: 实现 一.Model层 首先定义一个实体类User package app.qcu.pmit.cn.mvpdemo.model; /** ...
- hbase大规模数据写入的优化历程 ,ZZ
http://blog.csdn.net/zbc1090549839/article/details/51582817
- nlp基础(一)基本应用
1.问答系统,它主要是针对那些有明确答案的用户问题,而且通常面向特定的领域,比如金融,医疗,这一类的机器人.它的技术实现方案分为基于检索和基于知识库两大类. 2.第二个任务型对话系统,大家看论文的时候 ...