【CV】CVPR2015_A Discriminative CNN Video Representation for Event Detection
A Discriminative CNN Video Representation for Event Detection
Note here: it's a learning note on the topic of video representation, based on the paper below.
Link: http://arxiv.org/pdf/1411.4006v1.pdf
Motivation:
The use of improved Dense Trajectories (IDT) has led good performance on the task of event detection, while the performance of CNN based video representation is worse than that. The author argues the following three main reasons:
- Lack of labeled video data to train good models.
- Video level event labels are too coarse to finetune a pre-trained model for adapting the event detection task.
- The use of average pooling to generate a discriminative video level representation from CNN frame level descriptors works worse than hand-crafted features like IDT.
Proposed Model:
This paper proposes a model mainly targetting at the third problem, namely how to build a cost-efficient and discrimintive video representation based on CNN.
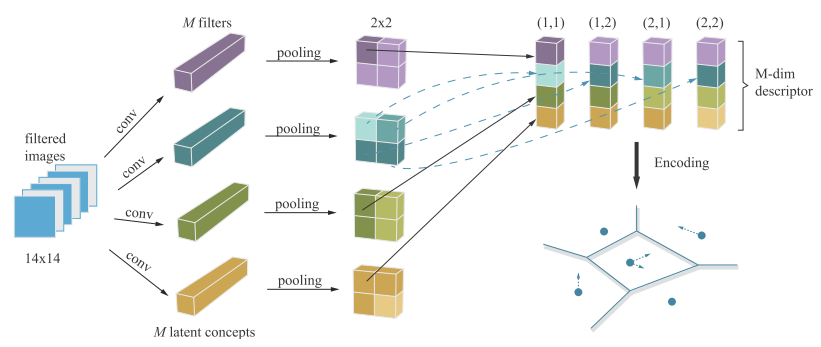
1) Firstly, we should extract frame-level descriptor:
We adopt M filters in the last convolutional layers as M latent concept classifiers. Each convolutional filter is corresponding to one latent concept, and each of it will apply on different location of the frame. So we’ll get responses of discrimintive latent concepts on different locations of the frame.
After that, we apply max-pooling operation on all concepts descriptors and concatenate different responses at the same location to form vectors each of which containing various concepts descriptions at this location.
By now, we’ve extract frame-level features.
(Actually, they didn’t do anything special at this step, they just give a new illustration of responses in CNN and rearrange those responses for further process.)
2) Secondly, we need to encode a discrimintive video-level descriptor from all these frame-level descriptors:
They introduce and compare three different encoding methods in the paper.
However, as I’m not proficient in the mathematical meanings of them, I can just give a briefly look at them instead of going further.
- Fisher Vector Encoding (refer to: http://blog.csdn.net/breeze5428/article/details/32706507 & http://www.cnblogs.com/CBDoctor/archive/2011/11/06/2236286.html)
- VLAD Encoding (simplified version of Fisher Vector Encoding)
- Average Pooling
Through experiment, they find out VLAD is better than other encoding methods. (You can refer to the paper for details about that experiment.)
"This is the first work on the video pooling of CNN descriptors and we broaden the encoding methods from local descriptors to CNN descriptors in video analysis."
(That's the takeaway in their work. They're the first to apply these encoding methods on the CNN descriptors. Previously, most of the works utilize Fisher Vector Encoding to encode a general feature of an image from local descriptors like HOG, SIFT, HOF and so on.)
3) Lastly, we get a video-level descriptor and feed it into a SVM to do detection task.
Two Tricks:
1) Spatial Pyramid Pooling: they apply four different CNN max-pooling operations to give more spatial locations for a single frame, which makes the descriptor more discrimintive. And that’s also more cost-friendly than applying spatial pyramid on raw frame.
2) Representation Compression: they do Product Quntization to compress the final representation while still maintain or even slightly improve the original performance.
【CV】CVPR2015_A Discriminative CNN Video Representation for Event Detection的更多相关文章
- 论文阅读(Weilin Huang——【TIP2016】Text-Attentional Convolutional Neural Network for Scene Text Detection)
Weilin Huang--[TIP2015]Text-Attentional Convolutional Neural Network for Scene Text Detection) 目录 作者 ...
- 【CV】ICCV2015_Unsupervised Learning of Visual Representations using Videos
Unsupervised Learning of Visual Representations using Videos Note here: it's a learning note on Prof ...
- 【PSMA】Progressive Sample Mining and Representation Learning for One-Shot Re-ID
目录 主要挑战 主要的贡献和创新点 提出的方法 总体框架与算法 Vanilla pseudo label sampling (PLS) PLS with adversarial learning Tr ...
- 【CV】ICCV2015_Learning Temporal Embeddings for Complex Video Analysis
Learning Temporal Embeddings for Complex Video Analysis Note here: it's a review note on novel work ...
- 【CV】ICCV2015_Unsupervised Visual Representation Learning by Context Prediction
Unsupervised Visual Representation Learning by Context Prediction Note here: it's a learning note on ...
- 【CV】ICCV2015_Unsupervised Learning of Spatiotemporally Coherent Metrics
Unsupervised Learning of Spatiotemporally Coherent Metrics Note here: it's a learning note on the to ...
- 【CV】ICCV2015_Describing Videos by Exploiting Temporal Structure
Describing Videos by Exploiting Temporal Structure Note here: it's a learning note on the topic of v ...
- 【ML】ICML2015_Unsupervised Learning of Video Representations using LSTMs
Unsupervised Learning of Video Representations using LSTMs Note here: it's a learning notes on new L ...
- 【实战问题】【3】iPhone无法播放video标签中的视频
问题:视频都是MP4格式,视频可以在手机上正常播放.video标签中的视频在安卓点击可以播放,但在iPhone无法播放 解决方案: 1,视频编码格式问题,具体iPhone手机支持的是哪些格式可见官方的 ...
随机推荐
- plsql developer如何查询SQL语句执行历史记录(转)
相信很多在plsql developer调试oracle的朋友,经常会遇到在plsql developer执行的某一条SQL语句没有保存,那么我们在plsql developer下如何找到我们执行过的 ...
- Linux下Sublime Text 3的安装
1.下载 官网下载 或者直接 #wget http://c758482.r82.cf2.rackcdn.com/sublime_text_3_build_3059_x32.tar.bz2 (linux ...
- HDU 2865 Birthday Toy
题目链接 题意:n个小珠子组成的正n边形,中间有一个大珠子.有木棍相连的两个珠子不能有相同的颜色,旋转后相同视为相同的方案,求着色方案数. \(\\\) 先选定一种颜色放在中间,剩下的\(k-1\)种 ...
- Mongodb主从模式SECONDARY提升为PRIMARY
生产环境不建议仅使用PRIMARY-SECONDARY模式 当primary挂掉,并且无法恢复时,可以把secondary提升为主节点. 注意:此时从节点可能有部分数据未同步过来,部分数据可能丢失. ...
- [Sdoi2010]古代猪文 (卢卡斯定理,欧拉函数)
哇,这道题真的好好,让我这个菜鸡充分体会到卢卡斯和欧拉函数的强大! 先把题意抽象出来!就是计算这个东西. p=999911659是素数,p-1=2*3*4679*35617 所以:这样只要求出然后再快 ...
- 在Windows中安装PostgreSQL
在Windows中安装PostgreSQL 虽然PostgreSQL是为类UNIX平台开发的,但它却是可以移植的.从7.1版本开始,PostgreSQL可以编译安装和作为一个PostgreSQL服务器 ...
- linux如何查看端口被哪个进程占用
1.lsof -i:端口号 2.netstat -tunlp|grep 端口号 都可以查看指定端口被哪个进程占用的情况 工具/原料 linux,windows xshell 方法/步骤 [ ...
- [转]Python shutil 模块
转自: https://www.cnblogs.com/wuzhiblog/p/6535527.html https://www.cnblogs.com/caibao666/p/6433864.htm ...
- Python Tornado集成JSON Web Token方式登录
本项目github地址 前端测试模板如下: Tornado restful api 项目 项目结构如下: 项目组织类似于django,由独立的app模块构成. 登录接口设计 模式:post -> ...
- PAT A1074 Reversing Linked List (25 分)——链表,vector,stl里的reverse
Given a constant K and a singly linked list L, you are supposed to reverse the links of every K elem ...