json&pickle&shelve模块
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
json
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
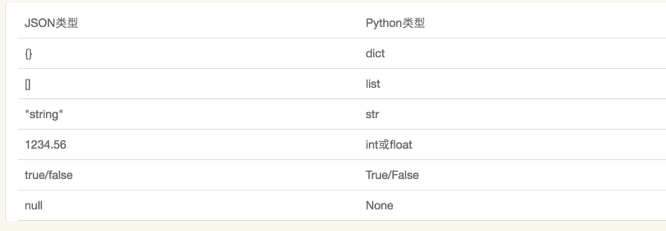
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
#----------------------------序列化
import json dic={'name':'alvin','age':23,'sex':'male'}
print(type(dic))#<class 'dict'> j=json.dumps(dic)
print(type(j))#<class 'str'> f=open('序列化对象','w')
f.write(j) #-------------------等价于json.dump(dic,f)
f.close()
#-----------------------------反序列化<br>
import json
f=open('序列化对象')
data=json.loads(f.read())# 等价于data=json.load(f)
import json
#dct="{'1':111}"#json 不认单引号
#dct=str({"1":111})#报错,因为生成的数据还是单引号:{'one': 1} dct='{"1":"111"}'
print(json.loads(dct)) #conclusion:
# 无论数据是怎样创建的,只要满足json格式,就可以json.loads出来,不一定非要dumps的数据才能loads
pickle模块
##----------------------------序列化
import pickle dic={'name':'alvin','age':23,'sex':'male'} print(type(dic))#<class 'dict'> j=pickle.dumps(dic)
print(type(j))#<class 'bytes'> f=open('序列化对象_pickle','wb')#注意是w是写入str,wb是写入bytes,j是'bytes'
f.write(j) #-------------------等价于pickle.dump(dic,f) f.close()
#-------------------------反序列化
import pickle
f=open('序列化对象_pickle','rb') data=pickle.loads(f.read())# 等价于data=pickle.load(f) print(data['age'])
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
shevel模块:
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型
import shelve
f = shelve.open(r'shelve.txt')
# f['stu1_info']={'name':'alex','age':'18'}
# f['stu2_info']={'name':'alvin','age':'20'}
# f['school_info']={'website':'oldboyedu.com','city':'beijing'}
#
#
# f.close()
print(f.get('stu_info')['age'])
json&pickle&shelve模块的更多相关文章
- python序列化: json & pickle & shelve 模块
一.json & pickle & shelve 模块 json,用于字符串 和 python数据类型间进行转换pickle,用于python特有的类型 和 python的数据类型间进 ...
- python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess logging re正则
python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess ...
- day6_python序列化之 json & pickle & shelve 模块
一.json & pickle & shelve 模块 json,用于字符串 和 python数据类型间进行转换pickle,用于python特有的类型 和 python的数据类型间进 ...
- Python全栈之路----常用模块----序列化(json&pickle&shelve)模块详解
把内存数据转成字符,叫序列化:把字符转成内存数据类型,叫反序列化. Json模块 Json模块提供了四个功能:序列化:dumps.dump:反序列化:loads.load. import json d ...
- json,pickle,shelve模块,xml处理模块
常用模块学习—序列化模块详解 什么叫序列化? 序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes. 为什么要序列化? 你打游戏过程 ...
- json & pickle & shelve 模块
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下: # json序列化 import json,time user={'name':'egon' ...
- Python json & pickle & shelve模块
json & pickle 之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇 ...
- Python序列化,json&pickle&shelve模块
1. 序列化说明 序列化可将非字符串的数据类型的数据进行存档,如字典.列表甚至是函数等等 反序列化,将通过序列化保存的文件内容反序列化即可得到数据原本的样子,可直接使用 2. Python中常用的序列 ...
- Python json & pickle, shelve 模块
json 用于字符串和python的数据类型间的转换 四个功能 dumps dump loads load pickle 用于python特有的类型和python的数据类型进行转换 四个功能 dump ...
随机推荐
- 解决启动vs2010 未能找到自动配置的设置文件
今天室友把固态拆掉,重新安上.打开vs2010出现 打开项目,出现 找了许多方法都无效. 发现c:user\Administer\documents\下,vs2010 .vs webset 那些文件点 ...
- 非常好的开源C项目tinyhttpd(500行代码)
编译命令 gcc -W -Wall -lpthread -o httpd httpd.c 源码 #include <stdio.h> #include <sys/socket.h&g ...
- 【leetcode】414. Third Maximum Number
problem 414. Third Maximum Number solution 思路:用三个变量first, second, third来分别保存第一大.第二大和第三大的数,然后遍历数组. cl ...
- mod_conference ESL控制三(程序)
第一篇描述了mod_conference控制原理,第二篇描述了conference相关事件,接下来对esl内联程序做简要说明. 由于event-socket采用TCP协议,因此需要一个线程与frees ...
- s21day11 python笔记
s21day11 python笔记 一.函数小高级 函数名可以当作变量来使用 #示例一: def func(): print(123) func_list = [func, func, func] # ...
- 在vue中使用Echarts画曲线图(异步加载数据)
现实的工作中, 数据不可能写死的,所有的数据都应该通过发送请求进行获取. 所以本项目的需求是请求服务器获得二维数组,并生成曲线图.曲线图的横纵坐标均从获得的数据中取得. Echarts官方文档: ht ...
- js barcode 打印
新建 html <!DOCTYPE HTML> <html lang="en-US"> <head> <meta charset=&quo ...
- [cf1038E][欧拉路]
http://codeforces.com/contest/1038/problem/E E. Maximum Matching time limit per test 2 seconds memor ...
- python: ImportError:DLL load failed 解决方法。
在学习使用wordcloud 库创建词云过程中,mooc里提到可以使用另一个库函数,来创建不同形状的词云. 就是这句: ... from scipy.misc import imread mk = i ...
- 第三章泛型集合ArrayList 和Hashtable
第三章泛型集集合 ArrayList 变量名 = new ArrayList(); //相当与一个容器 他的执行using 是 using System.Collections; 变量名.ADD( ...