Python—集合的操作、文件的操作
1.集合的操作
1.集合的操作
定义:
1.不同元素组成,自动去重
2.无序
3.集合中的元素必须是不可变类型
1.集合的定义:
>>> s1 = set('abcd') #同s1 = set{'a','b','c','d'}
>>> s1
{'a', 'c', 'b', 'd'}
>>> t1 = set('cdef')
>>> t1
{'c', 'f', 'e', 'd'}
>>> un_set = set('hello')
>>> un_set
{'h', 'e', 'o', 'l'}
>>> #set是去重的
>>> un_set = frozenset(un_set) #定义只读集合
>>> un_set
frozenset({'h', 'e', 'o', 'l'})
>>> #定义只读集合
2.集合的运算:
集合之间也可进行数学集合运算(例如:并集、交集等),可用相应的操作符或方法来实现。
#子集
>>> s1 = set('abcd')
>>> t1 = set('cdef')
>>> C = set('ab')
>>> C>s1 #判断C是否为S1子集,用符号表示
False
>>> C < s1
True
>>> C.issubset(s1) #用方法.issubset()表示
True
#交集:所有的相同元素的集合
>>> t1 = set('cdef')
>>> s1 = set('abcd')
3 >>> i = s1 & t1
>>> i
{'c', 'd'}
6 >>> s1.intersection(t1)
{'c', 'd'}
#并集:集合中所有元素的集合,重复元素只出现一次
1 >>> s1 | t1 #符号表示
{'f', 'e', 'a', 'c', 'b', 'd'}
3 >>> s1.union(t1) #方法表示
{'f', 'e', 'a', 'c', 'b', 'd'}
#差集:s1和t1的差集,所有属于s1且不属于t1的元素集合
>>> s1 - t1
{'a', 'b'}
>>> s1.difference(t1)
{'a', 'b'}
#对称差集,s1和t1去掉公共元素后,其余元素的集合
1 >>> s1 ^ t1
{'f', 'e', 'a', 'b'}
3 >>> s1.symmetric_difference(t1)
{'f', 'e', 'a', 'b'}
3.集合的方法
参考博客,非常详细:https://www.cnblogs.com/suendanny/p/8597596.html
#方法
>>> s = {1,2,3,4,5}
>>> s.add('s') #增加元素
>>> s
{'s', 1, 2, 3, 4, 5}
>>>
>>> s.clear() #清空集合
>>> s
set()
>>>
>>> s = {1,2,3,4,5}
>>> s
{1, 2, 3, 4, 5}
>>> new_s = s.copy() #浅copy
>>> new_s
{1, 2, 3, 4, 5}
>>>
>>>
>>> #pop()
>>> s.pop() #随机删除,若无,会报错 KeyError
1
>>> s
{2, 3, 4, 5}
>>>
>>>
>>> s.remove(2) #删除指定元素,若指定元素不存在,会报错 KeyError
>>> s
{3, 4, 5}
>>>
>>> s.discard("3") #删除集合中的一个元素,如果元素不存在,则不执行任何操作
>>> s
{3, 4, 5}
>>>
>>> s.discard(3)
>>> s
{4, 5}
>>> >>> # 并集.union() 符号:| 所有元素的集合,重复元素只出现一次
>>> # 交集 .intersection() 符号:& 所有相同元素的集合
>>> # 子集.issubset() 符号:< 判断是否是子集
>>> # 父集.isuperset() 符号:> 判断是否是父集
>>> # 差集.difference() 符号:- 所有属于s1且不属于t1的元素构成新的set >>> # 对称差集 .symmetric_difference() 符号:^
#对称差集,去掉公共元素后,其余元素的集合 >>> s1
{'a', 'c', 'b', 'd'}
>>> t1
{'c', 'f', 'e', 'd'}
>>> s1.intersection_update(t1) #用s1与t1的交集,来替换为s1
>>> s1
{'c', 'd'} >>> s1 = {1,2}
>>> t1 = {2,3,4}
>>> s1.update(t1) #update
>>> s1
{1, 2, 3, 4}
>>>
>>> s1.update(['h','i'],{4,5,6}) #方法中直接添加元素,可list和set
>>> s1
{1, 2, 3, 4, 'h', 5, 6, 'i'}
>>> >>> s1
{1, 2, 3, 4, 'h', 5, 6, 'i'}
>>> t1
{2, 3, 4}
>>> s = {555,666}
>>>
>>> s1.isdisjoint(t1) #若s1和t1不存在交集,返回true,否则返回false
False
>>> s1.isdisjoint(s)
True
>>> >>> s1 = {1,2,3,4}
>>> t1 = {2,3,5}
>>> s1.difference_update(t1) #用s1与t1的差集更新替换为s1
>>> s1
{1, 4} >>> s1 = {1,2,3,4}
>>> t1 = {2,3,5}
>>> s1.symmetric_difference_update(t1) #用s1与t1的对称差集更新替换为s1
>>> s1
{1, 4, 5}
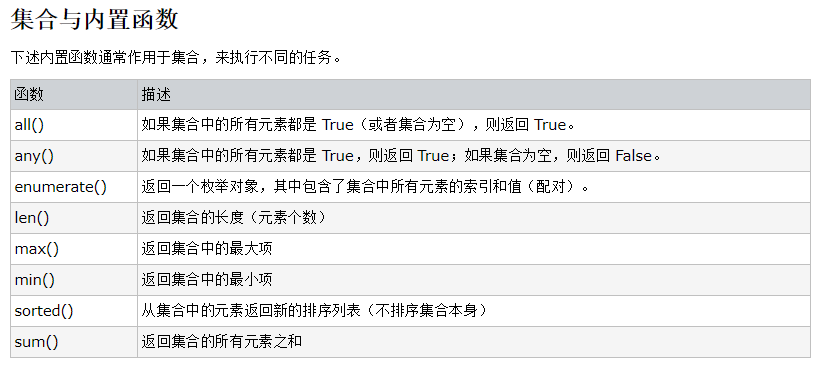
2.文件的操作
1.文件的打开模式

2.文件的读取:注意每次打开文件最后都需要 file.close() 进行关闭,也可直接使用【with】语句打开,其可以自动关闭,具体如下所示:
f = open("yesterday.txt",'r',encoding="utf-8") #文件的句柄,”r“是以只读模式打开
print(f.read) #读取yesterday.txt文件内容
print(f.readline) #读取一行,yesterday.txt文件内容
print(f.readlines) #将文件输出为一个列表,每一行为列表的一个元素
f.close()
8 #建议的写法,逐行读写,在第十行打印分割线
9 count = 0
10 for i in f:
11 count +=1
12 if count == 10:
13 print("我是分割线".center(40,'-'))
14 print(i)
for i in range(5): #行数少的时候打印前五行
print(f.readline())
#逐行读取文件,在第十行的时候输出分割线,占内存较多的写法,不建议
for index,i in enumerate(f.readlines()):
if index == 9:
print("我是分割线".center(40,"-")+"\n")
print(i)
25
#读取指定路径的文件
file_path = r'C:\Users\15302\PycharmProjects\GKXXX\day2\yesterday.txt' #注意由于路径中出现 ‘\U’在python中此转义符其后为Unicode编码,故此处路径要前要加 【r】
f = open(file_path,'r',encoding='utf-8')
print(f.read()) #with语句
为避免打开文件后忘记关闭,当with代码块执行完毕时,内部会自动关闭并释放文件资源。with使用方法如下:
with open('file or file_path','r',encoding='utf-8') as file_object:
print(f.read())
with open('file or file_path','r',encoding='utf-8') as file_object1 , open('file or file_path','r',encoding='utf-8') as file_object2 #可打开多个
with open('111111.txt','rb') as f2:
for i in f2:
off = -3
while True:
f2.seek(off,2)
data = f2.readlines()
if len(data)>1: #当.readlines() len为2时候,证明读了两行
print("last hang ",data[-1].decode("utf-8")) #取最后一个值,即最后一行
break
off *=3 #加大偏移量
读取文件最后一行
2.文件的写入:file.writelines(sequence)的参数是序列,比如列表,它会迭代帮你写入文件。
#w模式,是在文件操作一开始的时候进行判断是否新建和覆盖写入。如果是在文件操作过程中,一直写入也不会覆盖
f = open("yesterday.txt",'w',encoding="utf-8") #文件的打开模式为 ‘w’,此时文件可以写入,文件不存在则新建,若存在则清空再写入,切记注意。
f.write("莺歌燕舞太守醉,\n")
f.write("明朝酒醒春已归。\n")
f.write('枕上诗书闲处好,\n')
f.write('门前风景雨来佳。')
f.close()
关于文件光标,默认在0,.read()后在最后
with open('111111.txt','r+') as f2: #txt 文件里为gkxxx,写完后为 2kxxx
print(f2.tell()) #
f2.write('')
print(f2.tell()) #
f2.read()
print(f2.tell()) #
3.文件的方法:
f = open("yesterday.txt",'r',encoding="utf-8")
print(f.readline()) #打印第一行
print(f.tell()) #打印指针位置
print(f.seek(10)) #将指针位置放到第十个字符处,注意虽然可以把指针放到指定处,但是在‘a’,‘r+’模式下,f.write()还是会默认追加到文件末尾,不会在指针处追加
print(f.tell()) #打印指针位置
>>>>>>>>结果如下所示:
Somehow, it seems the love I knew was always the most destructive kind
72
10
10
with open('111111.txt','rb') as f2: #seek补充用法
print(f2.readlines())
print(f2.seek(-2,2))
>>>
[b'2kxxx\r\n', b'dfdf'] #二进制中的换行 \r\n
9 #对于111111.txt中的内容,倒数2个字符,相当于正数9个字符
#seek有三种模式 0,1,2
0:默认用法
1:相对位置seek
2:倒数seek,当用1,2时候,模式要换成rb,
seek用 seek(int,2) 这种模式读取文件最后一行
with open('111111.txt','rb') as f2: #读取最后一行的思路
for i in f2:
off = -3
while True:
f2.seek(off,2)
data = f2.readlines()
if len(data)>1:
print("last hang ",data[-1].decode("utf-8"))
break
off *=3
#truncate方法
1 f = open("yesterday.txt",'a',encoding="utf-8")
f.truncate(10) #截取文件前十个字符,其余内容删除
>>> somehow,i
#flush方法
1 import time,sys
for i in range(10):
sys.stdout.write("#")
sys.stdout.flush()
time.sleep(0.5) #每隔0.5秒打印一个“#”,一共打印十个
4.文件的修改
f = open('yesterday.txt','r',encoding='utf-8')
f2 = open('yesterday3.txt','w',encoding='utf-8')
for line in f:
if "肆意的快乐" in line:
line = line.replace("有那么多肆意的快乐等我享受","有那么多肆意的快乐等Gkx享受")
f2.write(line)
>>>>>
将yesterday.txt文件逐行读取,修改其中一行,并write到新文件中
with open('upload_file','r') as f:
line = f.readline()
while line != '':
print(line)
line = f.readline()
判断文件读取结束
Python—集合的操作、文件的操作的更多相关文章
- python glob fnmatch 用于文件查找操作
參考: http://python.jobbole.com/81552/:Python模块学习:glob文件路径查找 http://blog.csdn.net/suiyunonghen/article ...
- 《转》Python学习(15)-对文件的操作(二)
转自 http://www.cnblogs.com/BeginMan/p/3169020.html 一.文件系统 从系统角度来看,文件系统是对文件存储器空间进行组织和分配,负责文件存储并对存入的文件进 ...
- Python学习日记之文件读取操作
Python内置了文件读写的函数open,read 用法示例: open('/home/root/files.txt ') 在打开文件后,操作完成后可以使用close()关闭文件,但比较好的文件读写方 ...
- 记录我的 python 学习历程-Day08 文件的操作
文件操作的初识 用 python 代码对文件进行各种操作. 基本构成: 文件路径:path 打开方式:读.写.追加.读写.写读-- 编码方式:utf-8 / gbk / gb2312-- f = op ...
- 《转》Python学习(14)-对文件的操作(一)
转自 http://www.cnblogs.com/BeginMan/p/3166644.html 一.文件对象 我理解的文件对象就是一个接口,通过这个接口对文件进行相关操作. <Python ...
- Python之路 day2 文件基础操作
#!/usr/bin/env python # -*- coding:utf-8 -*- #Author:ersa ''' #f,文件句柄;模式 a : append 追加文件内容 f = open( ...
- python下对目录&文件的操作
Windows桌面上: 总文件夹 子文件夹01 文档01.txt-------------------------------------------------------------------- ...
- Day 8 集合与文件的操作
一.创建集合两种方式. 二.添加元素的方式(add.update"属于迭代添加") 一.集合# 1. 集合是无序的,不能重复的.# 2.集合内元素必须是可哈希的.# 3.集合不能更 ...
- 『无为则无心』Python序列 — 22、Python集合及其常用操作
目录 1.Python集合特点 2.Python集合的创建 3.操作集合常用API (1)增加数据 @1.add()方法 @2.update()方法 (2)删除数据 @1.remove()方法 @2. ...
- Django数据库性能优化之 - 使用Python集合操作
前言 最近有个新需求: 人员基础信息(记作人员A),10w 某种类型的人员信息(记作人员B),1000 要求在后台上(Django Admin)分别展示:已录入A的人员B列表.未录入的人员B列表 团队 ...
随机推荐
- 要学的javaee技术
mybatis.hibernate.spirng MVC.freemarker.zookeeper.dubbo.quartz的技术框架:NoSQL技术ehcache.memcached.redis等: ...
- caffe-ssd安装GPU版本和CPU的区别
在CPU中1.CPU_ONLY :=1的注释取消掉 2.BLAS := atlas 在GPU中 1.USE_CUDNN := 1的注释取消 2.BLAS := open
- 【转】Jira插件安装
一.Jira插件列表(可以将下面免费插件直接下载,然后登陆jira,在"插件管理"->"上传插件",将下载后的免费插件直接进行上传安装即可) 序号 插件名 ...
- 一定要知道的,那些Linux操作命令
一定要知道的,那些Linux基本操作命令(一) 目录 1.文件和目录操作命令 2.用户和用户组操作命令 3.vim编辑器操作命令 4.打包和解压操作命令 5.系统操作命令 为什么要学习linux? 1 ...
- undefined的几种情况
1.变量声明了,但是没有赋值: 2.一个变量声明了,并且赋值了undefined: var a = undefined; 3.一个对象中,获取某个不存在的属性,值也是undefined
- Zeu.js
一个生成各种 GIF 动画的 JavaScript 类库,非常适合用于让你的数据展示变得更加地生动.使用起来也非常简单,有数据展示需求的同学可以尝试一下.https://shzlw.github.io ...
- Generative Adversarial Nets
1. 基本思想 两个模型: 判别器:预测从生成器生成的样本的概率 生成器:生成样本时,最大化使得判别器发生错误的概率 最后得到唯一解:使得生成器生成的样本输入到判别器中,得到的概率全是1/2. ...
- Docker+Jenkins+Maven+SVN搭建持续集成环境
Docker+Jenkins+Maven+SVN搭建持续集成环境 环境拓扑图(实验项目使用PHP环境) 发布流程图 环境说明 系统:Centos 7.4 x64 Docker版本:18.09.0 Ma ...
- Link-Cut-Tree详解
图片参考YangZhe的论文,FlashHu大佬的博客 Link-Cut-Tree实际靠的是实链剖分,重链剖分和长链剖分珂以参考树链剖分详解 Link-Cut-Tree将某一个儿子的连边划分为实边,而 ...
- Docker安装准备
第一次写作下笔记: 以centos6.5安装yum优先级插件 yum install yum-priorities 1.epel简介: https://fedoraproject.org/wiki/E ...