模型介绍之FastText
模型介绍一:
1. FastText原理及实践
前言----来源&特点
fastText是Facebook于2016年开源的一个词向量计算和文本分类工具,在学术上并没有太大创新。但是它的优点也非常明显,在文本分类任务中,fastText(浅层网络)往往能取得和深度网络相媲美的精度,却在训练时间上比深度网络快许多数量级。在标准的多核CPU上, 能够在10分钟之内训练10亿词级别语料库的词向量,能够在一分钟之内分类有着30万多类别的50多万句子。
关键词:
多标签分类,很快,浅层网络,Facebook
1.1 模型架构
下面是fastText模型架构图:
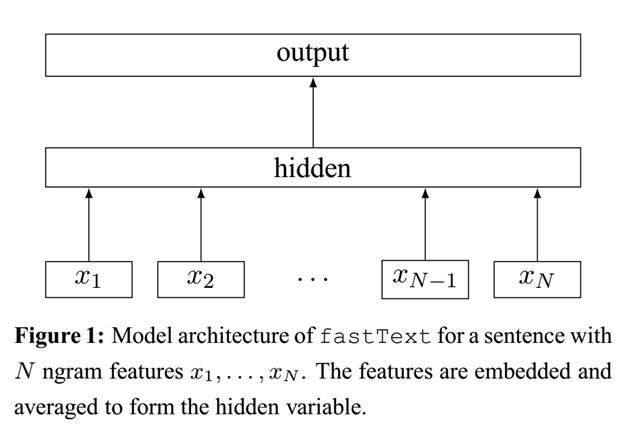
注意:此架构图没有展示词向量的训练过程。
fastText模型也只有三层:输入层、隐含层、输出层(Hierarchical Softmax),输入都是多个经向量表示的单词,输出都是一个特定的target类别,隐含层都是对多个词向量的叠加平均。
细节:
采用softmax去计算概率分布(但是当类别特别多时,论文中采用分层softmax加速训练【为了加速计算,还可以采用NEC loss来计算softmax,表现和采用hierarchy-softmax相近】word2vector中也采用分层softmax和负采样来降低梯度计算复杂度);
交叉熵cross-Entropy来计算损失loss;
这里词袋模型表示不考虑单词的顺序。为了弥补顺序缺失,此处增加了每个单词的n-gram(bi-gram/tri-gram)特征,例如:单词apple的n-gram特征(n=3):“<ap”, “app”, “ppl”, “ple”, “le>”。
1.2 核心思想
fastText文本分类的核心思想:
将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做softmax多分类
(1)观察模型的后半部分,即从隐含层输出到输出层输出,会发现它就是一个softmax线性多类别分类器 ,分类器的输入是一个用来表征当前文档的向量;
(2)模型的前半部分,即从输入层输入到隐含层输出部分,主要在做一件事情:生成用来表征文档的向量 。那么它是如何做的呢?叠加构成这篇文档的所有词及n-gram的词向量,然后取平均。叠加词向量背后的思想就是传统的词袋法,即将文档看成一个由词构成的集合。
这中间涉及到两个技巧:字符级n-gram特征的引入(模型前半部分)以及分层Softmax分类(模型后半部分)。
1.3 知识介绍
1.3.1 Softmax回归和分层softmax
(1)Softmax回归
Softmax回归(softmax regression)又被称作多项式逻辑回归(multinomial logistic regression),它是逻辑回归在处理所分类问题上的推广。
在普通LR中
类别目标是二元的: ,
m个被标注的样本: ,其中
。
预测函数:
代价函数(cost function):

Softmax回归
类别目标是多元>2: 。
假设 形式如下,给定一个测试输入x,我们的假设应该输出一个K维的向量,向量内每个元素的值表示x属于当前类别的概率。
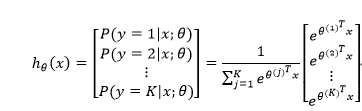
代价函数如下:
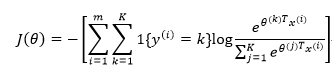
其中1{·}是指示函数,即1{true}=1,1{false}=0
两者一致性
既然我们说Softmax回归是逻辑回归的推广,那我们是否能够在代价函数上推导出它们的一致性呢?当然可以,于是:
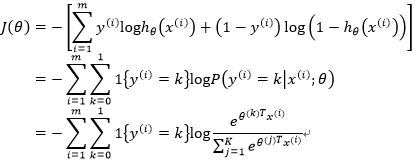
可以看到,逻辑回归是softmax回归在K=2时的特例。
(2)分层Softmax--------复杂度从|K|降低到log|K|
问题
你可能也发现了,标准的Softmax回归中,要计算y=j时的Softmax概率: ,我们需要对所有的K个概率做归一化,这在|y|很大时非常耗时,即在类别很多时,计算开销很大。于是,分层Softmax诞生了。
基本思想
它的基本思想是使用树的层级结构替代扁平化的标准Softmax,使得在计算 时,只需计算一条路径上的所有节点的概率值,无需在意其它的节点。
细节
下图是一个分层Softmax示例:
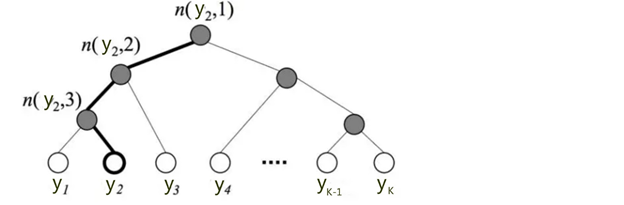
树的结构是根据类标的频数构造的霍夫曼树。
K个不同的类标组成所有的叶子节点,K-1个内部节点作为内部参数,从根节点到某个叶子节点经过的节点和边形成一条路径,路径长度被表示为 。于是,
就可以被写成:
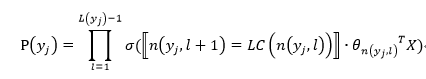
其中:
表示sigmoid函数,里面是判断该节点是否是左孩子,若是,则1,否则-1;
表示n节点的左孩子;
是一个特殊的函数,被定义为:
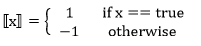
是中间节点
的参数;
X是Softmax层的输入
实例
上图中,高亮的节点和边是从根节点到 的路径,路径长度
可以被表示为:
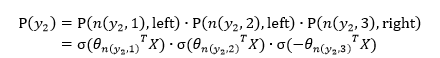
于是,从根节点走到叶子节点 ,实际上是在做了3次二分类的逻辑回归。
通过分层的Softmax,计算复杂度一下从|K|降低到log|K|。
《运用到huffman树,降低复杂度到log》
1.3.2 n-gram特征
在文本特征提取中,常常能看到n-gram的身影。它是一种基于语言模型的算法,基本思想是将文本内容按照字节顺序进行大小为N的滑动窗口操作,最终形成长度为N的字节片段序列。
n-gram中的gram根据粒度不同,有不同的含义。它可以是字粒度,也可以是词粒度的。
字粒度的n-gram
我来到达观数据参观
相应的bigram特征为:我来 来到 到达 达观 观数 数据 据参 参观
相应的trigram特征为:我来到 来到达 到达观 达观数 观数据 数据参 据参观
词粒度
我 来到 达观数据 参观
相应的bigram特征为:我/来到 来到/达观数据 达观数据/参观
相应的trigram特征为:我/来到/达观数据 来到/达观数据/参观
接下来介绍
FastText -------字符级别的n-gram
word2vec把语料库中的每个单词当成原子的,它会为每个单词生成一个向量。这忽略了单词内部的形态特征,比如:“apple” 和“apples”,“达观数据”和“达观”,这两个例子中,两个单词都有较多公共字符,即它们的内部形态类似,但是在传统的word2vec中,这种单词内部形态信息因为它们被转换成不同的id丢失了。
为了克服这个问题,fastText使用了字符级别的n-grams来表示一个单词。对于单词“apple”,假设n的取值为3,则它的trigram有“<ap”, “app”, “ppl”, “ple”, “le>”其中,<表示前缀,>表示后缀。于是,我们可以用这些trigram来表示“apple”这个单词,进一步,我们可以用这5个trigram的向量叠加来表示“apple”的词向量。
这带来两点好处:
1.对于低频词生成的词向量效果会更好。因为它们的n-gram可以和其它词共享。
2.对于训练词库之外的单词,仍然可以构建它们的词向量。我们可以叠加它们的字符级n-gram向量。
n-gram产生的特征只是作为文本特征的候选集,后面可能会采用信息熵、卡方统计、IDF等(后续整理)文本特征选择方式筛选出比较重要特征。
1.4关于分类效果
假设我们有两段文本:
(1)我 来到 达观数据
(2)俺 去了 达而观信息科技
这两段文本意思几乎一模一样,如果要分类,肯定要分到同一个类中去。
但在传统的分类器中,用来表征这两段文本的向量可能差距非常大。传统的文本分类中,你需要计算出每个词的权重,比如tfidf值, “我”和“俺” 算出的tfidf值相差可能会比较大,其它词类似,于是,VSM(向量空间模型)中用来表征这两段文本的文本向量差别可能比较大。
但是fastText:
它是用单词的embedding叠加获得的文档向量,词向量的重要特点就是向量的距离可以用来衡量单词间的语义相似程度,于是,在fastText模型中,这两段文本的向量应该是非常相似的,于是,它们很大概率会被分到同一个类中。
使用词embedding而非词本身作为特征,这是fastText效果好的一个原因;另一个原因就是字符级n-gram特征的引入对分类效果会有一些提升 。
1.5 实现
//待补充
前言 ---word2vec的CBOW模型架构和fastText模型非常相似。facebook开源的fastText工具不仅实现了fastText文本分类工具,还实现了快速词向量训练工具。
1.6 word2vec
word2vec主要有两种模型:skip-gram 模型和CBOW模型,这里只介绍CBOW模型,有关skip-gram模型的内容请参考达观另一篇技术文章:
1.6.1 CBOW模型架构
CBOW模型的基本思路是:用上下文预测目标词汇。架构图如下所示:

输入层由目标词汇y的上下文单词 组成,
是被onehot编码过的V维向量,其中V是词汇量;隐含层是N维向量h;输出层是被onehot编码过的目标词y。输入向量通过
维的权重矩阵W连接到隐含层;隐含层通过
维的权重矩阵
连接到输出层。因为词库V往往非常大,使用标准的softmax计算相当耗时,于是CBOW的输出层采用的正是上文提到过的分层Softmax,另一种方法是采用负采样。
1.6.2 前向传播
输入是如何计算而获得输出呢?先假设我们已经获得了权重矩阵 和
,隐含层h的输出的计算公式:
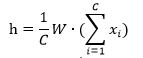
即:隐含层的输出是C个上下文单词向量的加权平均,权重为W。
接着我们计算输出层的每个节点:
这里 是矩阵
的第j列,最后,将
作为softmax函数的输入,得到
:
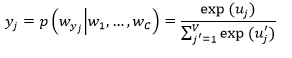
1.6.3 反向传播学习权重矩阵
在学习权重矩阵和过程中,我们首先随机产生初始值,然后feed训练样本到我们的模型,并观测我们期望输出和真实输出的误差。接着,我们计算误差关于权重矩阵的梯度,并在梯度的方向纠正它们。
首先定义损失函数,objective是最大化给定输入上下文,target单词的条件概率。因此,损失函数为:
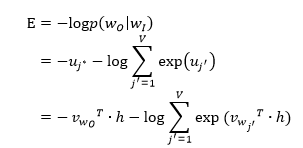
这里, 表示目标单词在词库V中的索引。
如何更新权重 ?
我们先对E关于 求导:
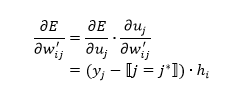
函数表示:
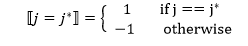
于是, 的更新公式:
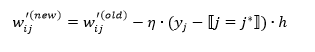
如何更新权重*W*?
我们首先计算E关于隐含层节点的导数:
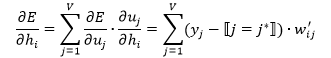
然后,E关于权重的导数为:
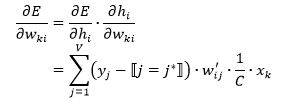
于是, 的更新公式:
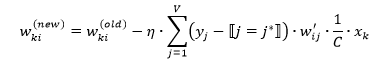
1.6.4 对比CBOW和FastText
相同
和CBOW一样,fastText模型也只有三层:输入层、隐含层、输出层(Hierarchical Softmax),输入都是多个经向量表示的单词,输出都是一个特定的target,隐含层都是对多个词向量的叠加平均。fastText相关公式的推导和CBOW非常类似,这里也不展开了。
不同
不同的是,CBOW的输入是目标单词的上下文,fastText的输入是多个单词及其n-gram特征,这些特征用来表示单个文档;CBOW的输入单词被onehot编码过,fastText的输入特征是被embedding过;CBOW的输出是目标词汇,fastText的输出是文档对应的类标。
1.6.5 fastText和word2vec的区别
相似处:
((1)图模型结构很像,都是采用embedding向量的形式,得到word的隐向量表达。
(2)都采用很多相似的优化方法,比如使用Hierarchical softmax优化训练和预测中的打分速度。
- 不同处:
(1)模型的输出层:word2vec的输出层,对应的是每一个term,计算某term的概率最大;而fasttext的输出层对应的是 分类的label。不过不管输出层对应的是什么内容,起对应的vector都不会被保留和使用;
(2)模型的输入层:word2vec的输出层,是 context window 内的term;而fasttext 对应的整个sentence的内容,包括term,也包括 n-gram的内容;
两者本质的不同,
(3)体现在 h-softmax的使用:
Wordvec的目的是得到词向量,该词向量 最终是在输入层得到,输出层对应的 h-softmax 也会生成一系列的向量,但最终都被抛弃,不会使用。
fasttext则充分利用了h-softmax的分类功能,遍历分类树的所有叶节点,找到概率最大的label(一个或者N个)
1.7 总结
总的来说,fastText的学习速度比较快,效果还不错。fastText适用与分类类别非常大而且数据集足够多的情况,当分类类别比较小或者数据集比较少的话,很容易过拟合。
可以完成无监督的词向量的学习,可以学习出来词向量,来保持住词和词之间,相关词之间是一个距离比较近的情况;
也可以用于有监督学习的文本分类任务,(新闻文本分类,垃圾邮件分类、情感分析中文本情感分析,电商中用户评论的褒贬分析)
参考:
[1] https://zhuanlan.zhihu.com/p/32965521 from: 陈运文-复旦大学-计算机应用技术博士
[2] https://github.com/brightmart/text_classification
[3] https://www.zhihu.com/question/32275069
[4] https://blog.csdn.net/john_bh/article/details/79268850
模型介绍之FastText的更多相关文章
- IO模型介绍
先理解几个问题: (1)为什么读取文件的时候,需要用户进程通过系统调用内核完成(系统不能自己调用内核)什么是用户态和内核态?为什么要区分内核态和用户态呢? 在 CPU 的所有指令中,有些指令是非常危险 ...
- python 全栈开发,Day44(IO模型介绍,阻塞IO,非阻塞IO,多路复用IO,异步IO,IO模型比较分析,selectors模块,垃圾回收机制)
昨日内容回顾 协程实际上是一个线程,执行了多个任务,遇到IO就切换 切换,可以使用yield,greenlet 遇到IO gevent: 检测到IO,能够使用greenlet实现自动切换,规避了IO阻 ...
- {python之IO多路复用} IO模型介绍 阻塞IO(blocking IO) 非阻塞IO(non-blocking IO) 多路复用IO(IO multiplexing) 异步IO(Asynchronous I/O) IO模型比较分析 selectors模块
python之IO多路复用 阅读目录 一 IO模型介绍 二 阻塞IO(blocking IO) 三 非阻塞IO(non-blocking IO) 四 多路复用IO(IO multiplexing) 五 ...
- (zhuan) 深度学习全网最全学习资料汇总之模型介绍篇
This blog from : http://weibo.com/ttarticle/p/show?id=2309351000224077630868614681&u=5070353058& ...
- 深入理解 Java 内存模型(一)- 内存模型介绍
深入理解 Java 内存模型(一)- 内存模型介绍 深入理解 Java 内存模型(二)- happens-before 规则 深入理解 Java 内存模型(三)- volatile 语义 深入理解 J ...
- OSI七层网络模型与TCP/IP四层模型介绍
目录 OSI七层网络模型与TCP/IP四层模型介绍 1.OSI七层网络模型介绍 2.TCP/IP四层网络模型介绍 3.各层对应的协议 4.OSI七层和TCP/IP四层的区别 5.交换机工作在OSI的哪 ...
- IO模型《一》IO模型介绍
IO模型介绍 为了更好地了解IO模型,我们需要事先回顾下:同步.异步.阻塞.非阻塞 同步(synchronous) IO和异步(asynchronous) IO,阻塞(blocking) IO和非阻塞 ...
- Python socket编程之IO模型介绍(多路复用*)
1.I/O基础知识 1.1 什么是文件描述符? 在网络中,一个socket对象就是1个文件描述符,在文件中,1个文件句柄(即file对象)就是1个文件描述符.其实可以理解为就是一个“指针”或“句柄”, ...
- Qt样式表之一:Qt样式表和盒子模型介绍
一.Qt样式表介绍 Qt样式表是一个可以自定义部件外观的十分强大的机制,可以用来美化部件.Qt样式表的概念.术语和语法都受到了HTML的层叠样式表(Cascading Style Sheets, CS ...
随机推荐
- Git图形化界面客户端
Git图形化界面客户端大汇总 文,还在不断更新,网上搜到的同名文章都是未经同意就从这里复制过去的) 一.TortoiseGit - The coolest Interface to Git Versi ...
- EasyUI datagrid 序列 化后时间 处理 九
@{ ViewBag.Title = "Home Page"; Layout = null; } <!DOCTYPE html> <html> <he ...
- Google - Reconstruct To Chain
/* 4. 给你一串input,比如: A -> B B -> C X -> Y Z -> X . . . 然后让你设计一个data structure来存这些关系,最后读完了 ...
- oracle-taf
http://blog.sina.com.cn/s/blog_48567d850102wck0.html配置目标:把RAC系统配置为“主-备”模式,即平时所有连接都在rac01这个节点上,当rac01 ...
- 20175202 《Java程序设计》第四周学习总结
20175202 <Java程序设计>第四周学习总结 第五章学习内容 1.子类的继承性: (1)子类与父类在同一包中的继承性:子类自然地继承了其父类中不是private的成员变量作为自己的 ...
- jenkins中如何实现执行脚本时的变量共享
1.主要是利用EnvInject Plugin插件,所以要首先安装插件,安装好后如下图: 2.然后在“增加构建步骤”中,插入一个“Execute Python script” 代码我用的python3 ...
- 启动kafka时报scala相关错误:java.lang.NoSuchMethodError: scala.Predef$.ArrowAssoc()
1.报错现象: 启动kafka的时候启动失败,并且会报告下面的错误: java.lang.NoSuchMethodError: scala.Predef$.ArrowAssoc(Ljava/lang/ ...
- linux服务nfs与dhcp篇
nfs复习: 1.简介:用于liunx与linux之间的文件传输系统 2.下载nfs-utils和rpcbind 3.打开配置文件/etc/exports——文件名(目录名)共享给予的ip地址(rw) ...
- 利用SharpZipLib进行字符串的压缩和解压缩
http://www.izhangheng.com/sharpziplib-string-compression-decompression/ 今天搞了一晚上压缩和解压缩问题,java压缩的字符串,用 ...
- python基础之数字、字符串、列表、元组、字典
Python基础二: 1.运算符: 判断某个东西是否在某个东西里面包含: in 为真 not in 为假 (1).算术运算符: 运算符 描述 实例 + 加 表示两个对象相加 a + b输出结果3 ...