大数据hadoop的伪分布式搭建
1.配置环境变量JDK配置
1.JDK安装
个人喜欢在
vi ~/.bash profile 下配置
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_91
export PATH=$JAVA_HOME/bin:$PATH
当然要让环境变量生效source ~/.bash_profile
echo $JAVA_HOME
在输入 java -verision,生效就装好了jdk

2.安装ssh
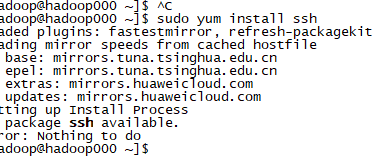
生成秘钥
ssh-keygen -t rsa
在将公钥复制到authorized_keys中

hadoop 安装中需要安装hadoop.env.sh

通过echo $JAVA_HOME 的到环境变量并且配置hadoop.env.sh中

core-site.xml要修改的文件在hadoop中
hadoop 在1.0是端口默认是9000现在2.0默认是8020
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:8020</value>
</property>
</configuration>
//制定一个存放临时文件的文件夹
<configuration>
<property>
<name>dfs.replication</name>
<value>/home/hadoop/app/tmp</value>
</property>
</configuration>
然后可以再core-site.xml中的指定的文件夹中
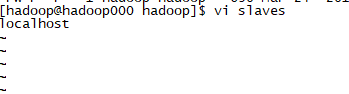
你有多少个datenode就写在slave中
5.启动hdfs
格式化文件系统(仅第一次执行即可,不要重复执行):hdfs/hadoop namenode -format

2.快速启动namenode和datanode

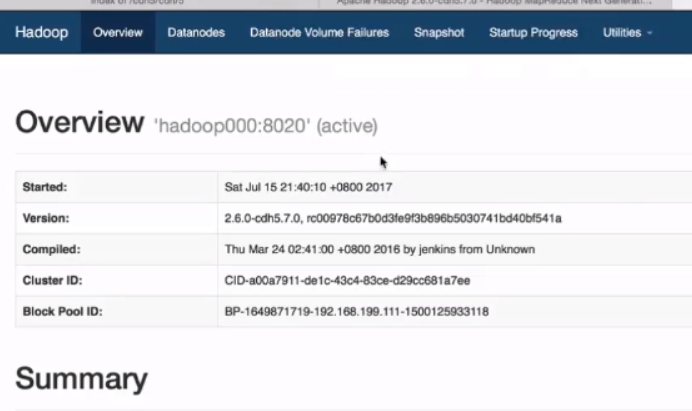
伪分布式启动成功

在网页上输入http://hadoop000:50070可以进行观看hadoop给前端的展示
停止伪分布式
./stop.dfs.sh

大数据hadoop的伪分布式搭建的更多相关文章
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- 【原创干货】大数据Hadoop/Spark开发环境搭建
已经自学了好几个月的大数据了,第一个月里自己通过看书.看视频.网上查资料也把hadoop(1.x.2.x).spark单机.伪分布式.集群都部署了一遍,但经历短暂的兴奋后,还是觉得不得门而入. 只有深 ...
- Hadoop的伪分布式搭建
我们在搭建伪分布式Hadoop环境,需要将一系列的配置文件配置好. 一.配置文件 1. 配置文件hadoop-env.sh export JAVA_HOME=/opt/modules/jdk1.7.0 ...
- 大数据-hadoop HA集群搭建
一.安装hadoop.HA及配置journalnode 实现namenode HA 实现resourcemanager HA namenode节点之间通过journalnode同步元数据 首先下载需要 ...
- 搭建大数据hadoop完全分布式环境遇到的坑
搭建大数据hadoop完全分布式环境,遇到很多问题,这里记录一部分,以备以后查看. 1.在安装配置完hadoop以后,需要格式化namenode,输入指令:hadoop namenode -forma ...
- 我搭建大数据Hadoop完全分布式环境遇到的坑---hadoop: command not found
搭建大数据hadoop环境,遇到很多问题,这里记录一部分,以备以后查看. [遇到问题].在安装配置完hadoop以后,需要格式化namenode,输入指令:hadoop namenode -forma ...
- 大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵. 一.概述 本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建had ...
- Hadoop简介与伪分布式搭建—DAY01
一. Hadoop的一些相关概念及思想 1.hadoop的核心组成: (1)hdfs分布式文件系统 (2)mapreduce 分布式批处理运算框架 (3)yarn 分布式资源调度系统 2.hadoo ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
随机推荐
- centos 7 端口
查看端口是否占用 netstat -tlnp|grep 8080 查看已经开放的端口 firewall-cmd --zone=public --list-ports 增加开放端口 firewall-c ...
- win10 解决 WMI Provider Host 占用CPU过高问题
真心懒得写Blog,但是之前遇到这个问题在网上查了一大圈,几乎一摸一样都是让关防火墙等服务的,然而对于我来说,并没有毛线用. 无奈,直接去微软社区查,还真有一篇问题解决方案.顺手翻译一下放在这里,希望 ...
- PhotoShop阵列功能
阵列有两种,如下.但是PS没有阵列这一工具,一定要用ps的话,可以参照以下两条: 1:方形阵列 先按CTRL+ALT+T 会出现一个自由变换选取 但是这个是多重复制的选取只要一动就能复制了 确定 然后 ...
- 网易云音乐api资料
https://github.com/LanFD/music_163 网易云音乐常用API浅析:http://moonlib.com/606.html
- DOM节点的增删改查以及class属性的操作
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- copyOnWriteArray 并发包下的不安全(数组)集合
copyOnWriteArray 记录一下 package java.util.concurrent;//你没有看错,是这个包 private transient volatile Object[] ...
- Lazarus的DBGrid中回车键的处理
Lazarus的DBGrid中回车键默认行为是向下移动一个记录,如果想对这一事件做处理,请不要在onkeypress里处理,而在onkeydown事件里处理.
- Visual Studio配置C/C++-PostgreSQL(9.6.3)开发环境(ZT)
https://www.2cto.com/database/201707/658910.html 开发环境 Visual Studio 2017[15.2(26430.16)] PostgreSQL ...
- ReactiveX 学习笔记(0)学习资源
ReactiveX 学习笔记 ReactiveX 学习笔记(1) ReactiveX 学习笔记(2)创建数据流 ReactiveX 学习笔记(3)转换数据流 ReactiveX 学习笔记(4)过滤数据 ...
- walle自动部署增量上线
walle的部署大家都会,全量上线也会,今天突然想用下增量上线,试了好多次都不行,咨询了开发的同事终于明白了,特写个笔记省的忘了 如上图我们网站根目录为/data/ifengsite/htdocs/x ...