HDFS高级功能
HDFS的六大高级特性:
安全模式
安全模式是HDFS所处的一种特殊状态,在这种状态下,文件系统只接受读数据请求,而不接受删除、修改等变更请求。在NameNode主节点启动时,HDFS首先进入安全模式,DataNode在启动的时候会向namenode汇报可用的block等状态,让NameNode得到块的位置信息,并对每一个文件对应的数据块副本进行统计,当最小副本条件满足时HDFS自动离开安全模式。如果HDFS出于安全模式下,则文件block不能进行任何的副本复制操作,如果HDFS出于安全模式下,则文件block不能进行任何的副本复制操作,因此达到最小的副本数量要求是基于datanode启动时的状态来判定的,启动时不会再做任何复制(从而达到最小副本数量要求)
假设我们设置的副本数即(参数dfs.replication是5),那么在datanode上应该有5个副本存在,假设只存在3个副本那么比例就是3/5=0.6,默认的最小的副本率是0.999.因此系统会自动复制副本到其他的dataNode,使得副本率不小于0.99.
安全模式的相关命令:
hdfs dfsadmin -safemode get
进入安全模式
hdfs dfsadmin -safemode enter
强制离开安全模式
hdfs dfsadmin -safemode leave
一直等待直到安全模式结束
hdfs dfsadmin -safemode wait
Web查看启动过程 端口50070

回收站
HDFS会为每一个用户创建一个回收站目录:/user/用户名/.Trash/,每一个被用户通过Shell删除的文件/目录,在系统回收站中都一个周期,也就是当系统回收站中的文件/目录在一段时间之后没有被用户恢复的话,HDFS就会自动的把这个文件/目录彻底删除,之后,用户就永远也找不回这个文件/目录了。在HDFS内部的具体实现就是在NameNode中开启了一个后台线程Emptier,这个线程专门管理和监控系统回收站下面的所有文件/目录,对于已经超过生命周期的文件/目录,这个线程就会自动的删除它们,不过这个管理的粒度很大。另外,用户也可以手动清空回收站,清空回收站的操作和删除普通的文件目录是一样的,只不过HDFS会自动检测这个文件目录是不是回收站,如果是,HDFS当然不会再把它放入用户的回收站中了。
设置trashtrash选项
hadoop中的trash选项默认关闭,如果生效,需要更改conf中的core-site.xml
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>1440</value>
</property>
执行 Hadoop fs -rm -f /文件路径,将文件删除时,文件并不是直接消失在系统中,而是被从当前目录move到了所属用户的回收站中。保留时间(1440分钟=24小时),24小时内,用户可以去回收站找到这个文件,并且恢复它。24小时过后,系统会自动删除这个文件,于是这个文件彻底被删除了。
fs.trash.checkpoint.interval则是指的是检查垃圾回收的检查间隔,应该是小于或者等于fs.trash.checkpoint.。想要恢复数据只需要把数据移动到要恢复的数据即可。
快照
Hadoop 2.x HDFS新特性
基于某时间点的数据的备份复制.利用快照,可以针对基本的目录或者整个文件系统,让HDFS在数据损坏时恢复到过去一个正确的时间点,快照比较常见的应用场景书数据备份,以防止一些用户错误或者灾难.
快照功能默认禁用,开启或者禁用快照功能需要针对目录进行操作命令如下
hdfs dfsadmin -allowSnapshot<snapshotDir> #开启快照
hdfs dfsadmin -disallowSnapshot<snapshotDir> #取消快照
hdfs dfs -createSnapshot<snapshotDir> [<snapshotName>] # 创建快照
hdfs dfs -deleteSnapshot<snapshotDir> [<snapshotName>] # 删除快照
hdfs dfs -renameSnapshot<snapshotDir> <oldName> <newName> #重命名快照
hdfs snapshotDiff <snapshodir> <snapshoName> <snapshoName> #比较快照不同
hdfs lsSnapshottableDir ##查看快录
开启快照
[hadoop@datanode1 ~]$ hdfs dfsadmin -allowSnapshot /input
Allowing snaphot on /input succeeded
创建快照
hdfs dfs -createSnapshot /input input_2018-12-19
Created snapshot /input/.snapshot/input_2018-12-19
上传文件
[hadoop@datanode1 ~]$ hadoop fs -put bigtable /input
对比快照
[hadoop@datanode1 ~]$ hdfs snapshotDiff /input input_2018-12-19 input_2018-12-19_2
Difference between snapshot input_2018-12-19 and snapshot input_2018-12-19_2 under directory /input:
M .
+ ./bigtable
Web查看
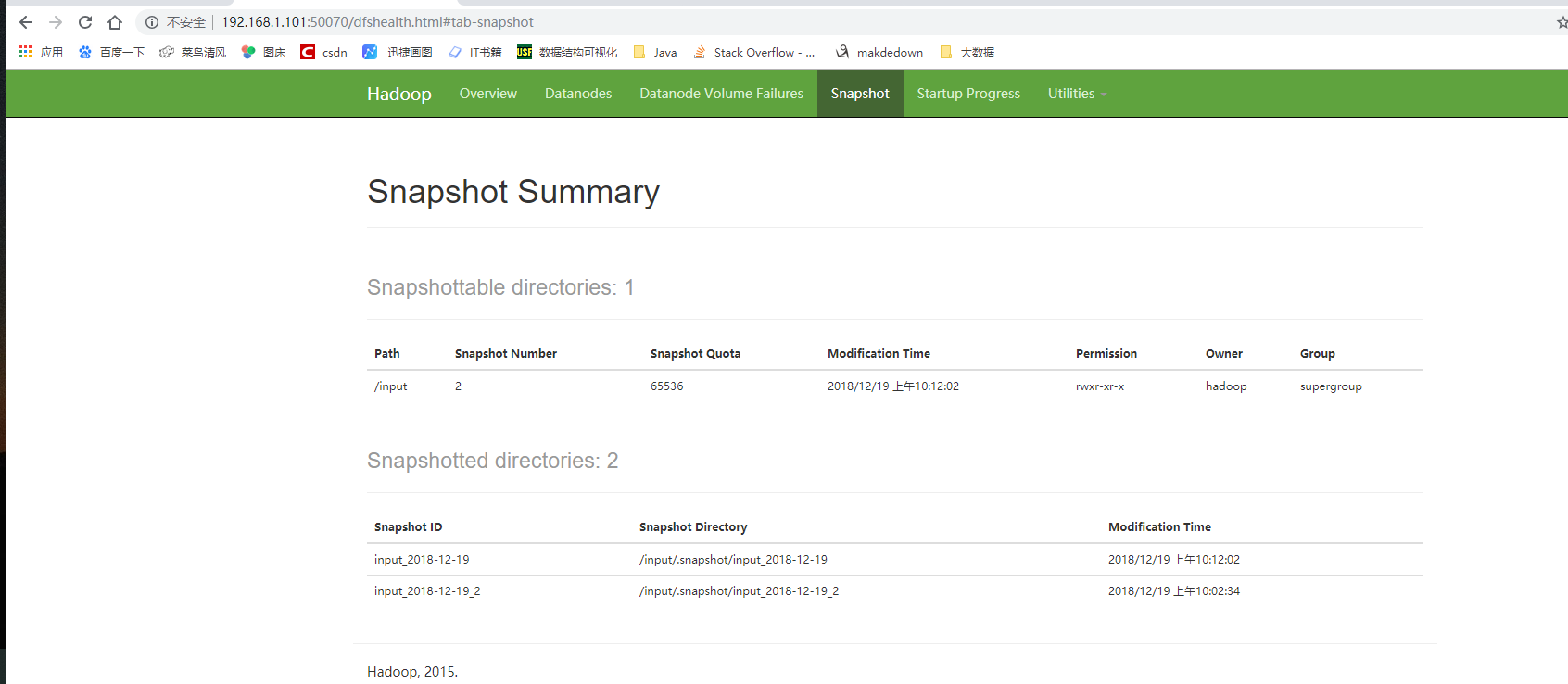
恢复数据
恢复数据的方法就是拷贝
[hadoop@datanode1 ~]$ hdfs dfs -cp /input/.snapshot/input_2018-12-19 /input
[hadoop@datanode1 ~]$ hdfs dfs -ls /input/input_2018-12-19
Found 2 items
-rw-r--r-- 3 hadoop supergroup 51 2018-12-19 10:17 /input/input_2018-12-19/test
-rw-r--r-- 3 hadoop supergroup 12 2018-12-19 10:17 /input/input_2018-12-19/write.txt
配额
- setQuota 针对HDFS中的某个目录设置文件和目录数量之和的最大值
[hadoop@datanode1 ~]$ hdfs dfsadmin -setQuota 5 /input # 该目录下目录数之和不超过5
#超过5个情况下put文件
#put: The NameSpace quota (directories and files) of directory /input is exceeded: quota=5 file count=8
- setSoaceQuota
[hadoop@datanode1 ~]$ hdfs dfsadmin -setSpaceQuota 134217728 /input #设置input的存储空间为128M
清除配额命令
[hadoop@datanode1 ~]$ hdfs dfsadmin -clrQuota /input
[hadoop@datanode1 ~]$ hdfs dfsadmin -clrSpaceQuota /input
联邦
Federation即为“联邦”,该特性允许一个HDFS集群中存在多个NameNode同时对外提供服务,这些NameNode分管一部分目录(水平切分),彼此之间相互隔离,但共享底层的DataNode存储资源。
【单机namenode的瓶颈大约是在4000台集群,而后则需要使用联邦机制】
什么是Federation机制
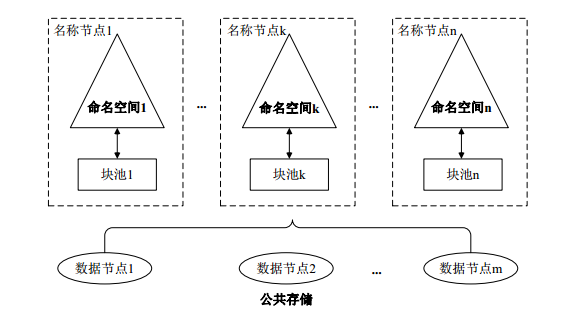
Federation是指HDFS集群可使用多个独立的NameSpace(NameNode节点管理)来满足HDFS命名空间的水平扩展 ,这些NameNode分别管理一部分数据,且共享所有DataNode的存储资源。
NameSpace之间在逻辑上是完全相互独立的(即任意两个NameSpace可以有完全相同的文件名)。在物理上可以完全独立(每个NameNode节点管理不同的DataNode)也可以有联系(共享存储节点DataNode)。一个NameNode节点只能管理一个Namespace
Federation机制解决单NameNode存在的以下几个问题
(1)HDFS集群扩展性。每个NameNode分管一部分namespace,相当于namenode是一个分布式的。
(2)性能更高效。多个NameNode同时对外提供服务,提供更高的读写吞吐率。
(3)良好的隔离性。用户可根据需要将不同业务数据交由不同NameNode管理,这样不同业务之间影响很小。
(4)Federation良好的向后兼容性,已有的单Namenode的部署配置不需要任何改变就可以继续工作。
Federation是简单鲁棒的设计
鲁棒性(健壮和强壮):在输入错误、磁盘故障、网络过载或有意攻击情况下,能否不死机、不崩溃
由于联盟中各个Namenode之间是相互独立的:Federation整个核心设计大部分改变是在Datanode、Config和Tools,而Namenode本身的改动非常少,这样Namenode原先的鲁棒性不会受到影响。比分布式的Namenode简单,虽然扩展性比真正的分布式的Namenode要小些,但是可以迅速满足需求。
另外一个原因是Federation良好的向后兼容性,可以无缝的支持目前单Namenode架构中的配置。已有的单Namenode的部署配置不需要任何改变就可以继续工作。
Federation不足之处
HDFS Federation并没有完全解决单点故障问题。虽然namenode/namespace存在多个,但是从单namenode/namespace看,仍然存在单点故障。因此 Federation中每个namenode配置成HA高可用集群,以便主namenode挂掉一下,用于快速恢复服务。
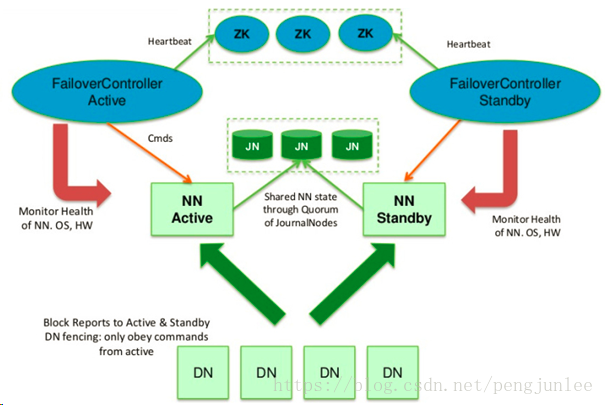
HA
通常一个集群只有一个NameNode,所有的元数据由唯一的NameNode负责管理,如果机器或者进程变得不可用,整个集群都会无法工作。知道NameNode恢复工作为止。影响集群的可用性,HDFS高可用通过提供同一集群中运行两个NameNode的方法来解决问题,一台保持活跃(Active)状态对外提供服务,一台处于备用(Standby)状态,两个节点保持数据同步。为了实时同步两个NameNode上的元数据需要一个共享存储系统,可以是NFS QJM 或者Zookeeper,Active的NameNode将共享数据写入到共享系统中去,而Standby监听该系统与ActiveNameNode基本保持一致因此在一个NameNode不能对外提供服务的情况下,可以快速故障转移到另外一个NameNode。
HDFS高级功能的更多相关文章
- Xen之初体验:XenMotion、 StorageMotion、Site Recovery、Power Management 各种新、高级功能免费
Xenserver 的新版本6.2现在已经全面开源,省掉了原有的序列号,也能免费体验曾经标题中的付费高级功能. 安装镜像:http://downloadns.citrix.com.edgesuite. ...
- MVC5 Entity Framework学习之Entity Framework高级功能(转)
在之前的文章中,你已经学习了如何实现每个层次结构一个表继承.本节中你将学习使用Entity Framework Code First来开发ASP.NET web应用程序时可以利用的高级功能. 在本节中 ...
- C#高级功能(四)扩展方法和索引
扩展方法使你能够向现有类型“添加”方法,而无需创建新的派生类型.重新编译或以其他方式修改原始类型. 扩展方法是一种特殊的静态方法,但可以像扩展类型上的实例方法一样进行调用.扩展方法被定义为静态方法,但 ...
- C#高级功能(三)Action、Func,Tuple
Action和Func泛型委托实际上就是一个.NET Framework预定义的委托,3.5引入的特性.基本涵盖了所有常用的委托,所以一般不用用户重新声明. Action系列泛型委托,是没有返回参数的 ...
- C#高级功能(二)LINQ 和Enumerable类
介绍LINQ之前先介绍一下枚举器 Iterator:枚举器如果你正在创建一个表现和行为都类似于集合的类,允许类的用户使用foreach语句对集合中的成员进行枚举将会是很方便的.我们将以创建一个简单化的 ...
- C#高级功能(一)Lambda 表达式
Lambda 表达式是一种可用于创建委托或表达式目录树类型的匿名函数. 通过使用 lambda 表达式,可以写入可作为参数传递或作为函数调用值返回的本地函数. Lambda 表达式对于编写 LINQ ...
- iOS开发——UI篇Swift篇&玩转UItableView(二)高级功能
UItableView高级功能 class UITableViewControllerAF: UIViewController, UITableViewDataSource, UITableViewD ...
- delphi实现ado的高级功能
ADO是Microsoft存取通用数据源的标准引擎.ADO通过封装OLE DB而能够存取不同类型的数据,让应用程序能很方便地通过统一的接口处理各种数据库.ADO由一组COM对象组成,每一个不同的原生A ...
- Unity3D之Mecanim动画系统学习笔记(十一):高级功能应用
动作游戏 还记得读书的时候熬夜打<波斯王子>的时光,我们的王子通过跳跃穿过墙壁的小洞.在高层建筑上进行攀爬和跳跃,还有在操作失误掉下高楼和触发必死机关后使用时之沙的时光倒流功能回归死亡之前 ...
随机推荐
- Jenkins发布后自动通知【钉钉】
阅读目录 一.前言 二.使用钉钉推送的优势 三.配置 一.前言 最近使用Jenkins进行自动化部署,但是发布署后,并没有相应的通知,虽然有邮件发送通知,但是发现邮件会受限于大家接受的设置,导致不能及 ...
- mongo之 前后台创建索引 --noIndexBuildRetry
在数据量超大的情形下,任何数据库系统在创建索引时都是一个耗时的大工程.MongoDB也不例外.因此,MongoDB索引的创建有两个选择,一个是前台方式,一个是后台方式.那这两种方式有什么差异呢,在创建 ...
- KNN算法原理(python代码实现)
kNN(k-nearest neighbor algorithm)算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性 ...
- 四、springboot(一)入门
1.创建maven工程 2.修改jdk版本为1.8以上 3.项目结构如下 4.添加依赖jar包 <parent> <groupId>org.springframework.bo ...
- WEB开发库收集
1. EASYUI http://www.jeasyui.com/ [INTRODUCTION] jQuery EasyUI framework helps you build yo ...
- 深入理解ASP.NET MVC(5)
系列目录 回顾 系列的前4节深入剖析了ASP.NET URL路由机制,以及MVC在此基础上是如何实现Areas机制的,同时涉及到inbound和outbound很多细节部分.第2节中提到MvcRout ...
- Linux mktemp命令
mktemp命令 Linux mktemp命令用于建立暂存文件.mktemp建立的一个暂存文件,供shell script使用.主要特点就是可以做到每次执行mktemp时产生文件和目录都不重名:这个特 ...
- 用Shell判断字符串包含关系的方法小结
这篇文章主要给大家介绍了关于用Shell判断字符串包含关系的几种方法,其中包括利用grep查找.利用字符串运算符.利用通配符.利用case in 语句以及利用替换等方法,每个方法都给出了详细的示例代 ...
- 关于IP核中中断信号的使用---以zynq系统为例
关于IP核中中断信号的使用---以zynq系统为例 1.使能设备的中断输出信号 2.使能处理器的中断接收信号 3.连接IP核到处理器之间的中断 此处只是硬件的搭建,软件系统的编写需要进一步研究. 搭建 ...
- 几种always块的形态
几种always块的形态 1.时钟沿触发与复位触发 2.使能触发 3.预设触发 4.时序寄存器与锁存触发 5.组合逻辑