吴裕雄 python 熵权法确定特征权重
一、熵权法介绍
熵最先由申农引入信息论,目前已经在工程技术、社会经济等领域得到了非常广泛的应用。
熵权法的基本思路是根据各个特征和它对应的值的变异性的大小来确定客观权重。
一般来说,若某个特征的信息熵越小,表明该特征的值得变异(对整体的影响)程度越大,提供的信息量越多,在综合评价中所能起到
的作用也越大,其权重也就越大。相反,某个特征的信息熵越大,表明指标值得变异(对整体的影响)程度越小,提供的信息量也越少,
在综合评价中所起到的作用也越小,其权重也就越小。
二、熵权法赋权步骤
1. 数据标准化(数据归一化)
将各个指标的数据进行标准化(归一化)处理。
假设给定了k个特征,其中
(每个特征的值表示)。假设对各特征数据(值)标准化后的值为
,那么
。
i 表示特征序列,j 表示 i 特征序列对应的各个具体的值的序列,所谓的序列就是起到标号的作用,方便人们理解公式的运行过程。
2. 求各指标的信息熵
根据信息论中信息熵的定义,一组数据的信息熵。其中
,如果
,则定义
。
3. 确定各指标权重
根据信息熵的计算公式,计算出各个特征的信息熵为 。通过信息熵计算各指标的权重:
。
4. 对各个特征进行评分
根据计算出的指标权重,设Zl为第l个特征的最终得分,则 ,
import xlrd
import numpy as np #读数据并求熵
path=u"D:\\LearningResource\\myLearningData\\hostital.xls"
hn,nc=1,1
#hn为表头行数,nc为表头列数
sheetname=u'Sheet1' def readexcel(hn,nc):
data = xlrd.open_workbook(path)
table = data.sheet_by_name(sheetname)
nrows = table.nrows
data=[]
for i in range(hn,nrows):
data.append(table.row_values(i)[nc:])
return np.array(data) def entropy(data0):
#返回每个样本的指数
#样本数,指标个数
n,m=np.shape(data0)
#一行一个样本,一列一个指标
#下面是归一化
maxium=np.max(data0,axis=0)
minium=np.min(data0,axis=0)
data= (data0-minium)*1.0/(maxium-minium)
##计算第j项指标,第i个样本占该指标的比重
sumzb=np.sum(data,axis=0)
data=data/sumzb
#对ln0处理
a=data*1.0
a[np.where(data==0)]=0.0001
# #计算每个指标的熵
e=(-1.0/np.log(n))*np.sum(data*np.log(a),axis=0)
print(e)
# #计算权重
w=(1-e)/np.sum(1-e)
recodes=np.sum(data0*w,axis=1)
return recodes data=readexcel(hn,nc)
grades=entropy(data)
print(grades)

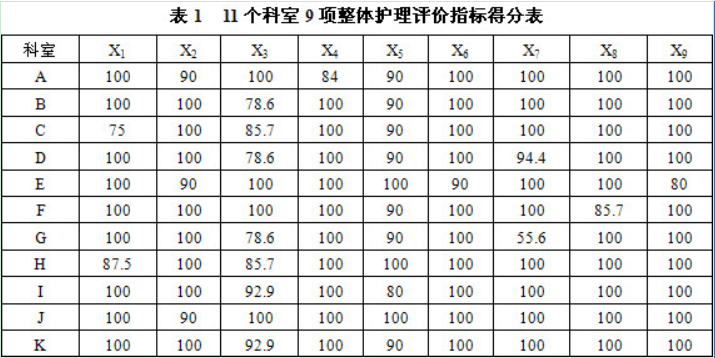
原数据集
吴裕雄 python 熵权法确定特征权重的更多相关文章
- 吴裕雄 python 机器学习——数据预处理过滤式特征选取SelectPercentile模型
from sklearn.feature_selection import SelectPercentile,f_classif #数据预处理过滤式特征选取SelectPercentile模型 def ...
- 吴裕雄 python 机器学习——数据预处理过滤式特征选取VarianceThreshold模型
from sklearn.feature_selection import VarianceThreshold #数据预处理过滤式特征选取VarianceThreshold模型 def test_Va ...
- 吴裕雄 python 机器学习——数据预处理包裹式特征选取模型
from sklearn.svm import LinearSVC from sklearn.datasets import load_iris from sklearn.feature_select ...
- 基于topsis和熵权法
% % X 数据矩阵 % % n 数据矩阵行数即评价对象数目 % % m 数据矩阵列数即经济指标数目 % % B 乘以熵权的数据矩阵 % % Dist_max D+ 与最大值的距离向量 % % Dis ...
- 熵权法(the Entropy Weight Method)以及MATLAB实现
按照信息论基本原理的解释,信息是系统有序程度的一个度量,熵是系统无序程度的一个度量:如果指标的信息熵越小,该指标提供的信息量越小,在综合评价中所起作用理当越小,权重就应该越低.因此,可利用信息熵这个工 ...
- 熵权法原理及matlab代码实现
参考原理博客地址https://blog.csdn.net/u013713294/article/details/53407087 一.基本原理 在信息论中,熵是对不确定性的一种度量.信息量越大,不确 ...
- 吴裕雄 python深度学习与实践(17)
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data import time # 声明输 ...
- 吴裕雄 python神经网络 水果图片识别(4)
# coding: utf-8 # In[1]:import osimport numpy as npfrom skimage import color, data, transform, io # ...
- 吴裕雄 python神经网络 水果图片识别(2)
import osimport numpy as npimport matplotlib.pyplot as pltfrom skimage import color,data,transform,i ...
随机推荐
- Hive快捷查询:不启用Mapreduce job启用Fetch task
启用MapReduce Job是会消耗系统开销的.对于这个问题,从Hive0.10.0版本开始,对于简单的不需要聚合的类似SELECT <col> from <table> L ...
- MySQL/InnoDB中,对于锁的认识
MySQL/InnoDB的加锁,一直是一个面试中常问的话题.例如,数据库如果有高并发请求,如何保证数据完整性?产生死锁问题如何排查并解决?我在工作过程中,也会经常用到,乐观锁,排它锁,等.于是今天就对 ...
- django之前-----web应用与框架
一web应用 web应用程序是一种可以通过Web访问的应用程序,程序的最大好处是用户很容易访问应用程序,用户只需要有浏览器即可,不需要再安装其他软件.应用程序有两种模式C/S.B/S. 下面来看一个简 ...
- 非阻塞套接字编程, IO多路复用(epoll)
非阻塞套接字编程: server端 import socket server = socket.socket() server.setblocking(False) server.bind(('', ...
- 【Python爬虫实战】pywin32 安装后出现 import win32api ImportError DLL load failed
windows下执行 scrapy 的指定的时候出现错误, 最初出现错误 提示没有pywin32 那么就去安装了一个pywin32 然后pip安装 https://www.lfd.uci.edu ...
- 【Python爬虫实战】Scrapy框架的安装 搬运工亲测有效
windows下亲测有效 http://blog.csdn.net/liuweiyuxiang/article/details/68929999这个我们只是正确操作步骤详解的搬运工
- php-- orther
0.PHP实现物流查询(通过快递网API实现) 1.php7 新特性 2.php的精确计算 3.PHP大小写是否敏感问题的汇总 4.取得类的 对象属性名 和类的属性 和类的方法名 5.php判断 != ...
- Angular.js入门
一.引入angular.js <script type="text/javascript" src="../plugins/angularjs/angular.m ...
- mysql高级聚合
GROUP_CONCAT() 函数的值等于属于一个组的指定列的所有值,以逗号隔开,并且以字符串表示 mysql> select sex,group_concat(level) from role ...
- javascript创建节点的事件绑定
javascript创建节点的事件绑定 timeupdate事件是<video>中用来返回视频播放进度的事件,绑定在<video>标签返回视频播放位置(每秒计). 现video ...