Flume数据采集准备
,
flume的官网:http://flume.apache.org/
flume的下载地址:http://flume.apache.org/download.html

这里我们用的是apache版本的flume

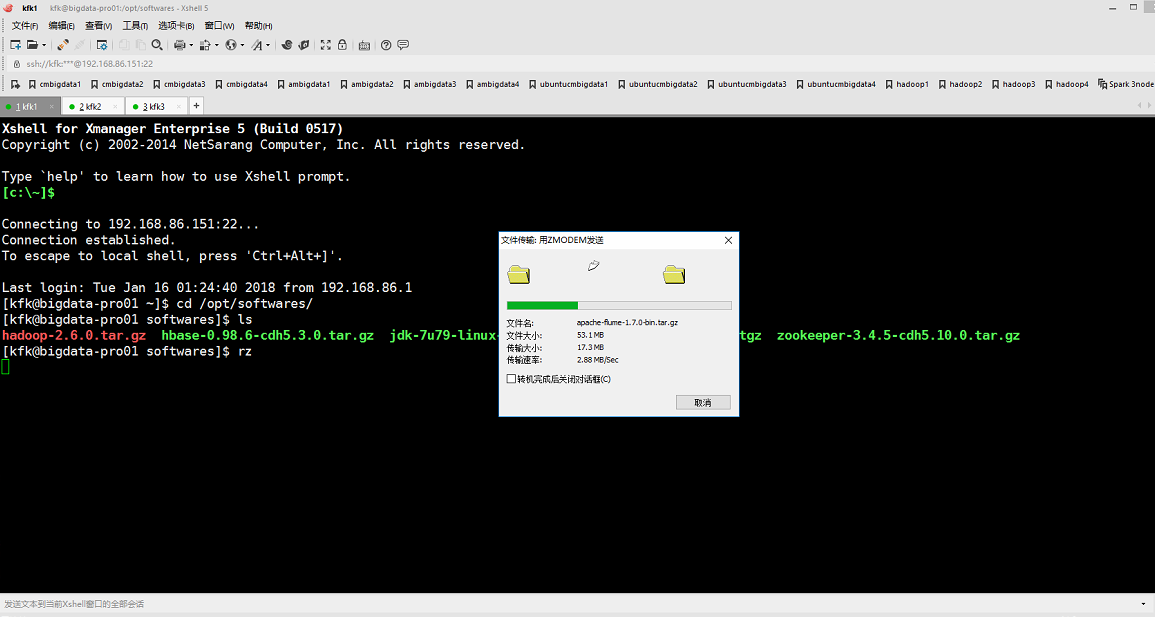
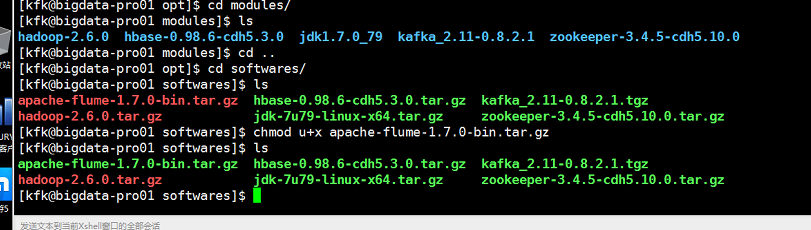
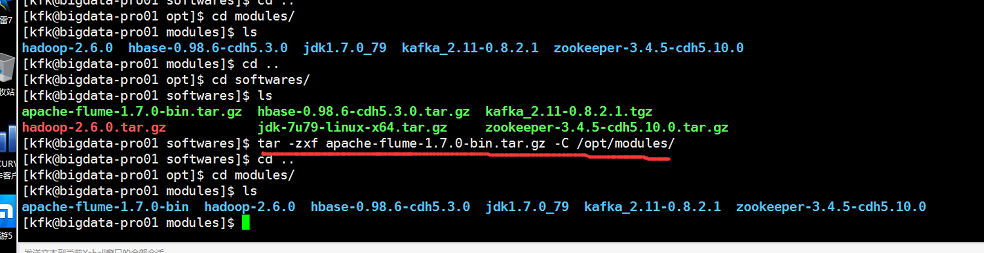
解压
改下名字

把不必要的文件删除
flume用户指南官网地址:https://cwiki.apache.org//confluence/display/FLUME/Getting+Started
把节点1的flume分发到节点2 和节点3上去


通过noteap++连接到节点2上
修改下名字
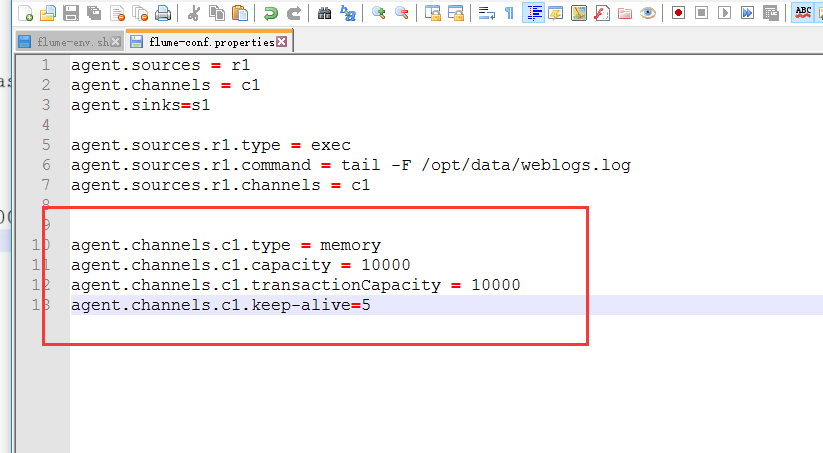
修改配置文件

因为这个配置文件比较乱
我们直接把内容干掉然后自己重新配置
我们可以参考官网 http://flume.apache.org/FlumeUserGuide.html
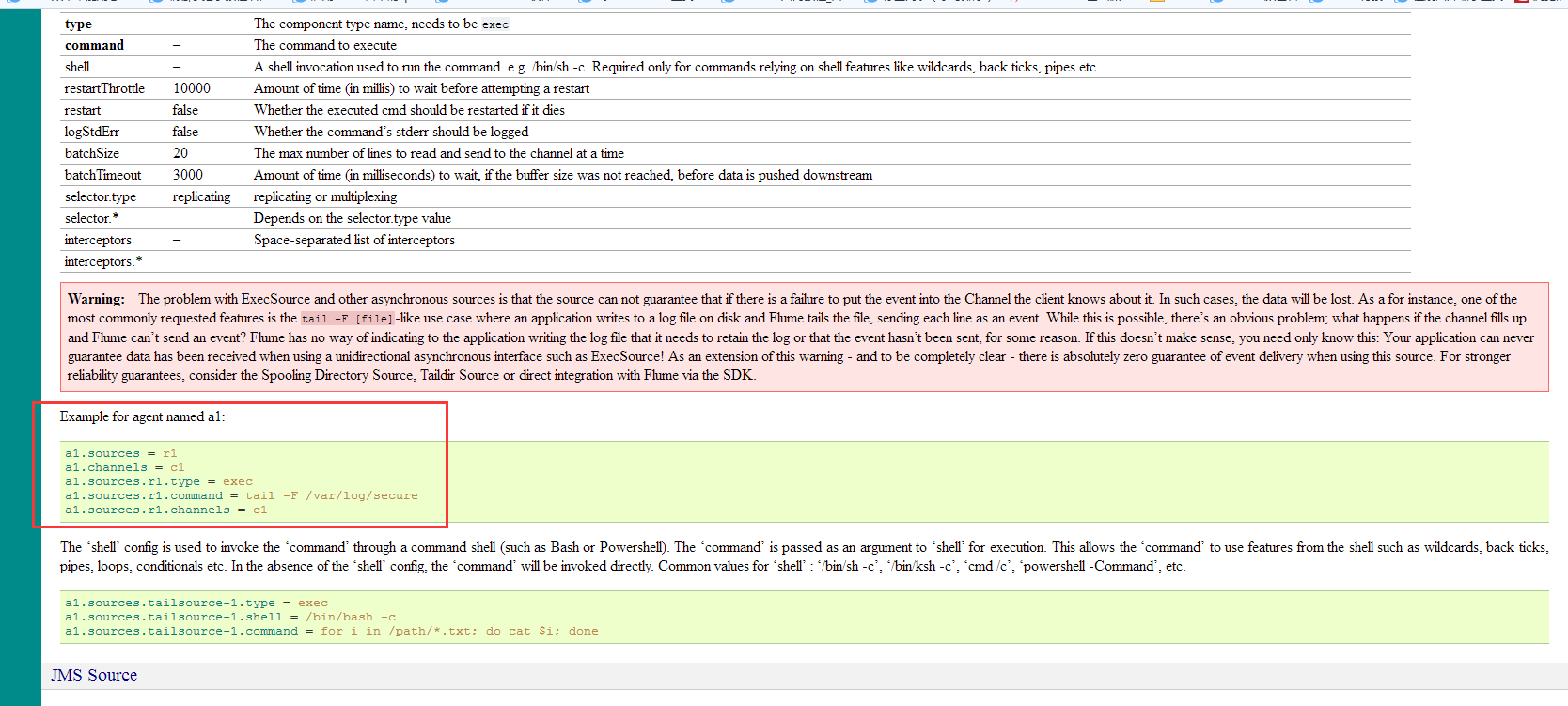
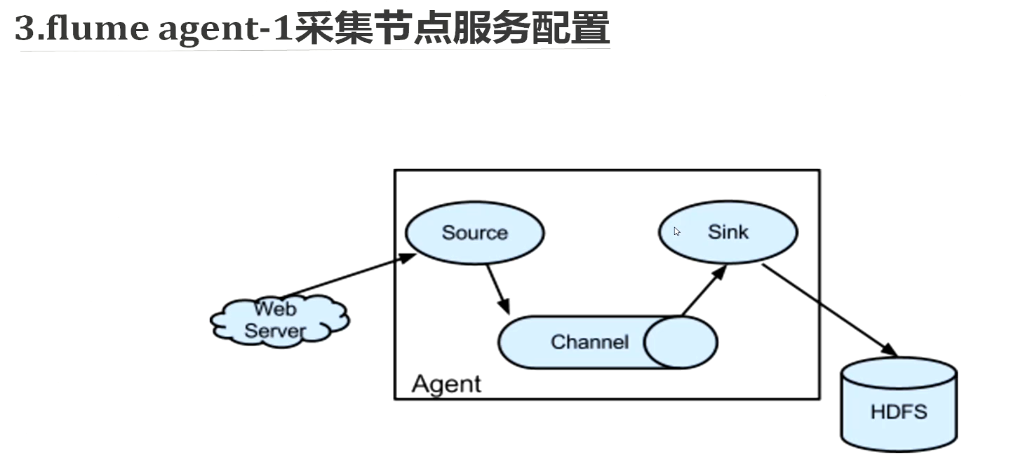
画红线的地方是数据源的路径
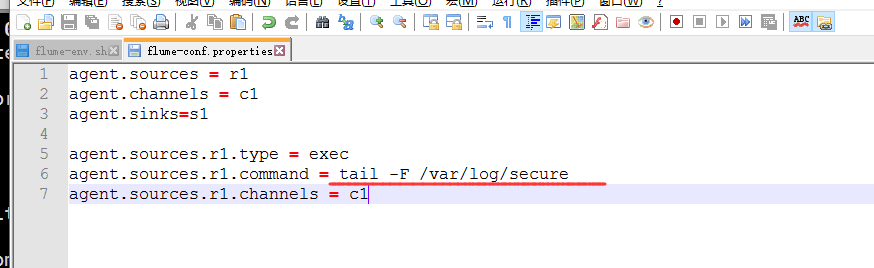
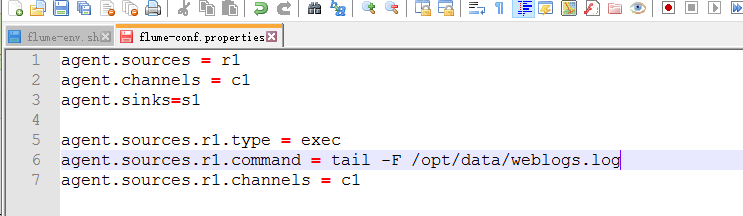
下面配置channel
http://flume.apache.org/FlumeUserGuide.html#memory-channel
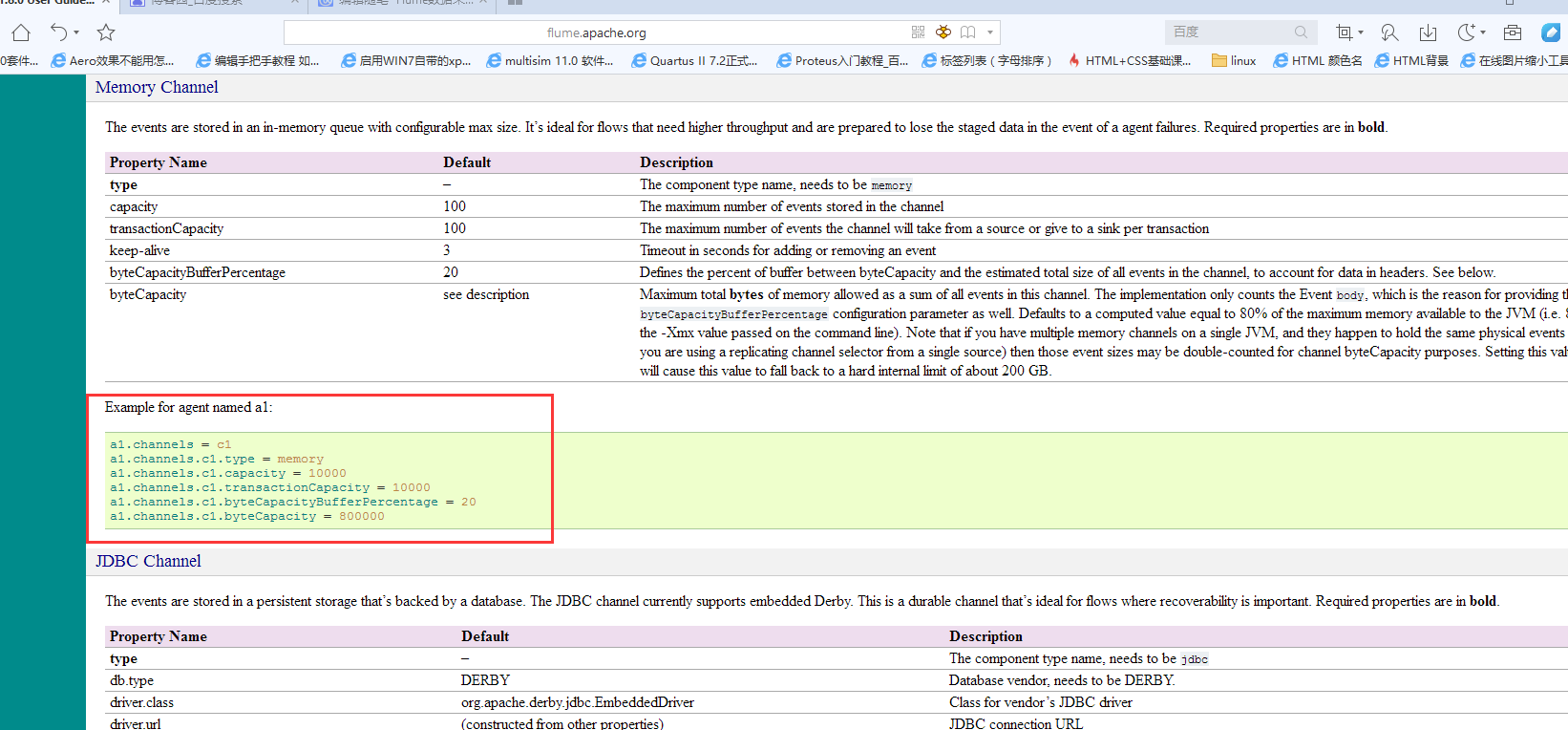
下面配置sink
http://flume.apache.org/FlumeUserGuide.html#avro-sink
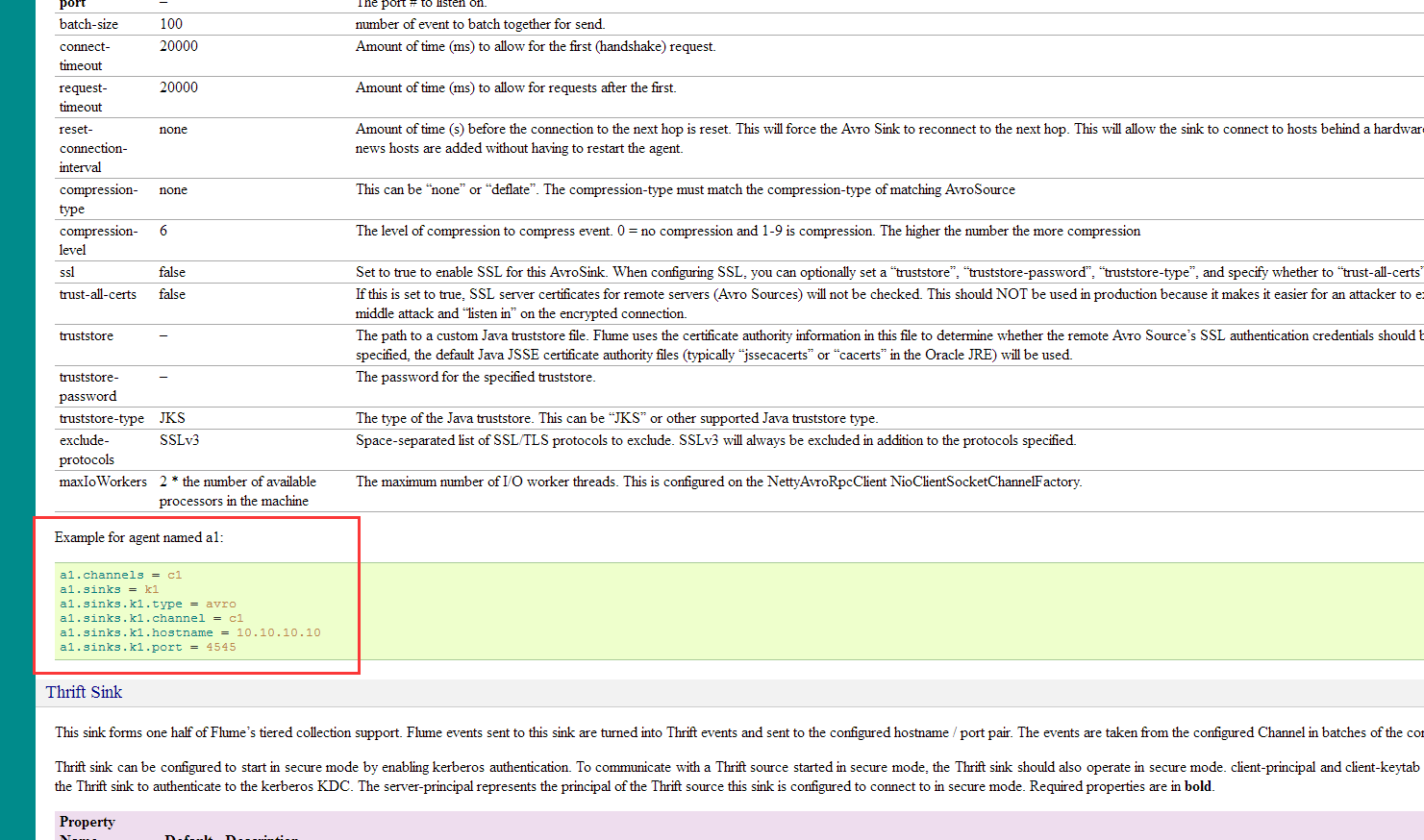
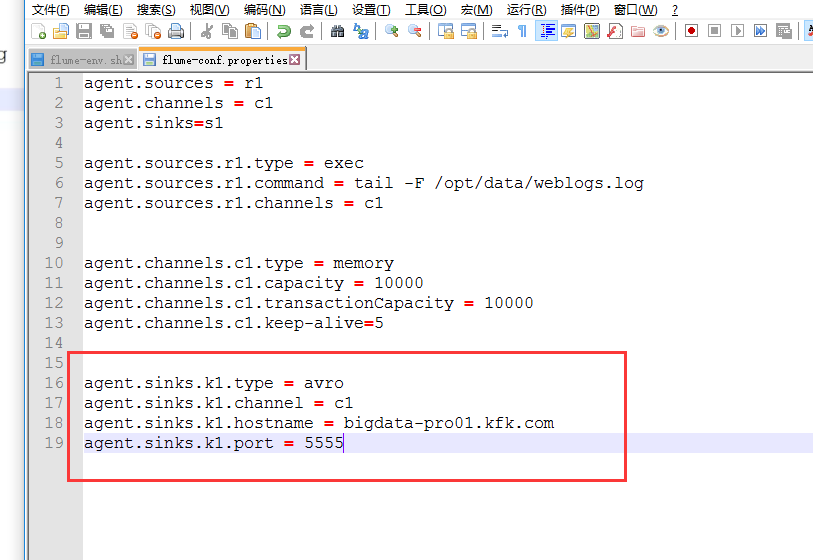
这里为什么sink的hostname是配置到节点1 呢,因为我们这里节点2 和节点3是各自通过一个flume初步收集数据,节点1再通过一个flume来合并数据

为了方便我们看到配置文件知道是节点2,我们修改一下

把weblogs.log文件分发给节点3

因为节点3的flume没有配置,我们现在就直接用节点2的flume把节点3的覆盖掉了

这个是节点3的,现在看到的是保留了节点2的配置,因为刚刚从节点2复制过来的,现在我们需要修改一下

这个是修改后的

Flume数据采集准备的更多相关文章
- Flume数据采集结合etcd作为配置中心在爬虫数据采集处理中的架构实践。
Apache Flume是一个分布式的.可靠的.可用的系统,用于有效地收集. 聚合和将大量日志数据从许多不同的源移动到一个集中的数据存储,但是其本身是以本地properties作为配置的,配置无法做到 ...
- 新闻实时分析系统-Flume数据采集准备
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并 ...
- 新闻网大数据实时分析可视化系统项目——8、Flume数据采集准备
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并 ...
- Flume初始
一.Flume是什么 Flume是一个数据,日志收集的一个组件,可以用于对程序,nginx等日志的收集,而且非常简单,省时的做完收集的工作.Flume是一个分布式.可靠.和高可用的海量日志采集聚合和传 ...
- Flume笔记
flume自定义拦截器:实现Interceptor接口flume自定义source:继承AbstractSourceflume自定义sink:继承AbstractSink azkaban:任务调度工具 ...
- mongodb副本集搭建过程中的问题和解决技巧
在我以往的认知中,一个系统一旦正式上线,多半不会轻易的迁移服务器,尤其是那种涉及到多个关联应用,涉及到多台硬件服务器的系统,因为这种迁移将是牵一发而动全身的. 但是,却仍然有这种情况存在,就如我这几天 ...
- 什么是RDD?
顾名思义,从字面理解RDD就是 Resillient Distributed Dataset,即弹性分布式数据集. 它是Spark提供的核心抽象. RDD在抽象上来讲是一种抽象的分布式的数据集.它是被 ...
- Hadoop(一) HADOOP简介
1. HADOOP背景介绍 1.1 什么是HADOOP HADOOP是apache旗下的一套开源软件平台 HADOOP提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理 H ...
- hadoop之HDFS学习笔记(一)
主要内容:hdfs的整体运行机制,DATANODE存储文件块的观察,hdfs集群的搭建与配置,hdfs命令行客户端常见命令:业务系统中日志生成机制,HDFS的java客户端api基本使用. 1.什么是 ...
随机推荐
- python之路---05 字典 集合
二十.字典 可变数据类型 {key:value}形式 查找效率高 key值必须是不可变的数据类型 1.增删改查 1).增 dic["新key"] = "新v ...
- [转]一个故事讲清楚NIO
假设某银行只有10个职员.该银行的业务流程分为以下4个步骤: 1) 顾客填申请表(5分钟): 2) 职员审核(1分钟): 3) 职员叫保安去金库取钱(3分钟): 4) 职员打印票据,并将钱和票据返回给 ...
- oracle之 反向键索引
反向键索引是一种B-tree索引,它在保持列顺序的同时,物理地改变每个索引键的字节(反向键索引除了ROWID和still之外,反转每个索引列的字节).例如,如果索引键为20,如果在十六进制中存储为这个 ...
- C166 8位字节位运算赋值-代码优化
8位字节位运算赋值优化特记录下: unsigned short func1(){ unsigned short a; return a;} unsigned char func2(){ unsigne ...
- hanlp在Python环境中的安装失败后的解决方法
Hanlp是由一系列模型与算法组成的javag工具包,目标是普及自然语言处理再生环境中的应用.有很多人在安装hanlp的时候会遇到安装失败的情况,下面就是某大神的分享的在python环境中安装失败的解 ...
- HADOOP1.X中HDFS工作原理
转载自:http://www.daniubiji.cn/archives/596 HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据googl ...
- nginx只允许移动端访问( 判断拦截pc浏览器访问)
set $mobile_request '0'; if ($http_user_agent ~* (Android|webOS|iPhone|iPod|BlackBerry)) { set $mobi ...
- StyleCop(C#代码检测工具)
StyleCop(C#代码检测工具) 一.StyleCop是微软的一个开源的静态代码分析工具,检查c#代码一致性和编码风格. 二.下载地址 http://stylecop.codeplex.c ...
- delphi中Time消息的使用方法
unit Unit1; interface uses Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms ...
- js页面滚动时层智能浮动定位实现
直接上代码 $.fn.smartFloat = function (className) { var position = function (element) { var top = element ...