Java编程的逻辑 (61) - 内存映射文件及其应用 - 实现一个简单的消息队列
本系列文章经补充和完善,已修订整理成书《Java编程的逻辑》,由机械工业出版社华章分社出版,于2018年1月上市热销,读者好评如潮!各大网店和书店有售,欢迎购买,京东自营链接:http://item.jd.com/12299018.html

本节介绍内存映射文件,内存映射文件不是Java引入的概念,而是操作系统提供的一种功能,大部分操作系统都支持。
我们先来介绍内存映射文件的基本概念,它是什么,能解决什么问题,然后我们介绍如何在Java中使用,我们会设计和实现一个简单的、持久化的、跨程序的消息队列来演示内存映射文件的应用。
基本概念
所谓内存映射文件,就是将文件映射到内存,文件对应于内存中的一个字节数组,对文件的操作变为对这个字节数组的操作,而字节数组的操作直接映射到文件上。这种映射可以是映射文件全部区域,也可以是只映射一部分区域。
不过,这种映射是操作系统提供的一种假象,文件一般不会马上加载到内存,操作系统只是记录下了这回事,当实际发生读写时,才会按需加载。操作系统一般是按页加载的,页可以理解为就是一块,页的大小与操作系统和硬件相关,典型的配置可能是4K, 8K等,当操作系统发现读写区域不在内存时,就会加载该区域对应的一个页到内存。
这种按需加载的方式,使得内存映射文件可以方便处理非常大的文件,内存放不下整个文件也不要紧,操作系统会自动进行处理,将需要的内容读到内存,将修改的内容保存到硬盘,将不再使用的内存释放。
在应用程序写的时候,它写的是内存中的字节数组,这个内容什么时候同步到文件上呢?这个时机是不确定的,由操作系统决定,不过,只要操作系统不崩溃,操作系统会保证同步到文件上,即使映射这个文件的应用程序已经退出了。
在一般的文件读写中,会有两次数据拷贝,一次是从硬盘拷贝到操作系统内核,另一次是从操作系统内核拷贝到用户态的应用程序。而在内存映射文件中,一般情况下,只有一次拷贝,且内存分配在操作系统内核,应用程序访问的就是操作系统的内核内存空间,这显然要比普通的读写效率更高。
内存映射文件的另一个重要特点是,它可以被多个不同的应用程序共享,多个程序可以映射同一个文件,映射到同一块内存区域,一个程序对内存的修改,可以让其他程序也看到,这使得它特别适合用于不同应用程序之间的通信。
操作系统自身在加载可执行文件的时候,一般都利用了内存映射文件,比如:
- 按需加载代码,只有当前运行的代码在内存,其他暂时用不到的代码还在硬盘
- 同时启动多次同一个可执行文件,文件代码在内存也只有一份
- 不同应用程序共享的动态链接库代码在内存也只有一份
内存映射文件也有局限性,比如,它不太适合处理小文件,它是按页分配内存的,对于小文件,会浪费空间,另外,映射文件要消耗一定的操作系统资源,初始化比较慢。
简单总结下,对于一般的文件读写不需要使用内存映射文件,但如果处理的是大文件,要求极高的读写效率,比如数据库系统,或者需要在不同程序间进行共享和通信,那就可以考虑内存映射文件。
理解了内存映射文件的基本概念,接下来,我们看怎么在Java中使用它。
用法
映射文件
内存映射文件需要通过FileInputStream/FileOutputStream或RandomAccessFile,它们都有一个方法:
public FileChannel getChannel()
FileChannel有如下方法:
public MappedByteBuffer map(MapMode mode, long position, long size) throws IOException
map方法将当前文件映射到内存,映射的结果就是一个MappedByteBuffer对象,它代表内存中的字节数组,待会我们再来详细看它。map有三个参数,mode表示映射模式,positon表示映射的起始位置,size表示长度。
mode有三个取值:
- MapMode.READ_ONLY:只读
- MapMode.READ_WRITE:既读也写
- MapMode.PRIVATE:私有模式,更改不反映到文件,也不被其他程序看到
这个模式受限于背后的流或RandomAccessFile,比如,对于FileInputStream,或者RandomAccessFile但打开模式是"r",那mode就不能设为MapMode.READ_WRITE,否则会抛出异常。
如果映射的区域超过了现有文件的范围,则文件会自动扩展,扩展出的区域字节内容为0。
映射完成后,文件就可以关闭了,后续对文件的读写可以通过MappedByteBuffer。
看段代码,比如以读写模式映射文件"abc.dat",代码可以为:
RandomAccessFile file = new RandomAccessFile("abc.dat","rw");
try {
MappedByteBuffer buf = file.getChannel().map(MapMode.READ_WRITE, 0, file.length());
//使用buf...
} catch (IOException e) {
e.printStackTrace();
}finally{
file.close();
}
MappedByteBuffer
怎么来使用MappedByteBuffer呢?它是ByteBuffer的子类,而ByteBuffer是Buffer的子类。ByteBuffer和Buffer不只是给内存映射文件提供的,它们是Java NIO中操作数据的一种方式,用于很多地方,方法也比较多,我们只介绍一些主要相关的。
ByteBuffer可以简单理解为就是封装了一个字节数组,这个字节数组的长度是不可变的,在内存映射文件中,这个长度由map方法中的参数size决定。
ByteBuffer有一个基本属性position,表示当前读写位置,这个位置可以改变,相关方法是:
//获取当前读写位置
public final int position()
//修改当前读写位置
public final Buffer position(int newPosition)
ByteBuffer中有很多基于当前位置读写数据的方法,如:
//从当前位置获取一个字节
public abstract byte get();
//从当前位置拷贝dst.length长度的字节到dst
public ByteBuffer get(byte[] dst)
//从当前位置读取一个int
public abstract int getInt();
//从当前位置读取一个double
public abstract double getDouble();
//将字节数组src写入当前位置
public final ByteBuffer put(byte[] src)
//将long类型的value写入当前位置
public abstract ByteBuffer putLong(long value);
这些方法在读写后,都会自动增加position。
与这些方法相对应的,还有一组方法,可以在参数中直接指定position,比如:
//从index处读取一个int
public abstract int getInt(int index);
//从index处读取一个double
public abstract double getDouble(int index);
//在index处写入一个double
public abstract ByteBuffer putDouble(int index, double value);
//在index处写入一个long
public abstract ByteBuffer putLong(int index, long value);
这些方法在读写时,不会改变当前读写位置position。
MappedByteBuffer自己还定义了一些方法:
//检查文件内容是否真实加载到了内存,这个值是一个参考值,不一定精确
public final boolean isLoaded()
//尽量将文件内容加载到内存
public final MappedByteBuffer load()
//将对内存的修改强制同步到硬盘上
public final MappedByteBuffer force()
消息队列
了解了内存映射文件的用法,接下来,我们来看怎么用它设计和实现一个简单的消息队列,我们称之为BasicQueue。
功能
BasicQueue是一个先进先出的循环队列,长度固定,接口主要是出队和入队,与之前介绍的容器类的区别是:
- 消息持久化保存在文件中,重启程序消息不会丢失
- 可以供不同的程序进行协作,典型场景是,有两个不同的程序,一个是生产者,另一个是消费者,生成者只将消息放入队列,而消费者只从队列中取消息,两个程序通过队列进行协作,这种协作方式更灵活,相互依赖性小,是一种常见的协作方式。
BasicQueue的构造方法是:
public BasicQueue(String path, String queueName) throws IOException
path表示队列所在的目录,必须已存在,queueName表示队列名,BasicQueue会使用以queueName开头的两个文件来保存队列信息,一个后缀是.data,保存实际的消息,另一个后缀是.meta,保存元数据信息,如果这两个文件存在,则会使用已有的队列,否则会建立新队列。
BasicQueue主要提供两个方法,出队和入队,如下所示:
//入队
public void enqueue(byte[] data) throws IOException
//出队
public byte[] dequeue() throws IOException
与上节介绍的BasicDB类似,消息格式也是byte数组。BasicQueue的队列长度是有限的,如果满了,调用enqueue会抛出异常,消息的最大长度也是有限的,不能超过1020,如果超了,也会抛出异常。如果队列为空,dequeue返回null。
用法示例
BasicQueue的典型用法是生产者和消费者之间的协作,我们来看下简单的示例代码。生产者程序向队列上放消息,每放一条,就随机休息一会儿,代码为:
public class Producer {
public static void main(String[] args) throws InterruptedException {
try {
BasicQueue queue = new BasicQueue("./", "task");
int i = 0;
Random rnd = new Random();
while (true) {
String msg = new String("task " + (i++));
queue.enqueue(msg.getBytes("UTF-8"));
System.out.println("produce: " + msg);
Thread.sleep(rnd.nextInt(1000));
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
消费者程序从队列中取消息,如果队列为空,也随机睡一会儿,代码为:
public class Consumer {
public static void main(String[] args) throws InterruptedException {
try {
BasicQueue queue = new BasicQueue("./", "task");
Random rnd = new Random();
while (true) {
byte[] bytes = queue.dequeue();
if (bytes == null) {
Thread.sleep(rnd.nextInt(1000));
continue;
}
System.out.println("consume: " + new String(bytes, "UTF-8"));
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
假定这两个程序的当前目录一样,它们会使用同样的队列"task"。同时运行这两个程序,会看到它们的输出交替出现。
设计
我们采用如下简单方式来设计BasicQueue:
- 使用两个文件来保存消息队列,一个为数据文件,后缀为.data,一个是元数据文件.meta。
- 在.data文件中使用固定长度存储每条信息,长度为1024,前4个字节为实际长度,后面是实际内容,每条消息的最大长度不能超过1020。
- 在.meta文件中保存队列头和尾,指向.data文件中的位置,初始都是0,入队增加尾,出队增加头,到结尾时,再从0开始,模拟循环队列。
- 为了区分队列满和空的状态,始终留一个位置不保存数据,当队列头和尾一样的时候表示队列为空,当队列尾的下一个位置是队列头的时候表示队列满。
基本设计如下图所示:
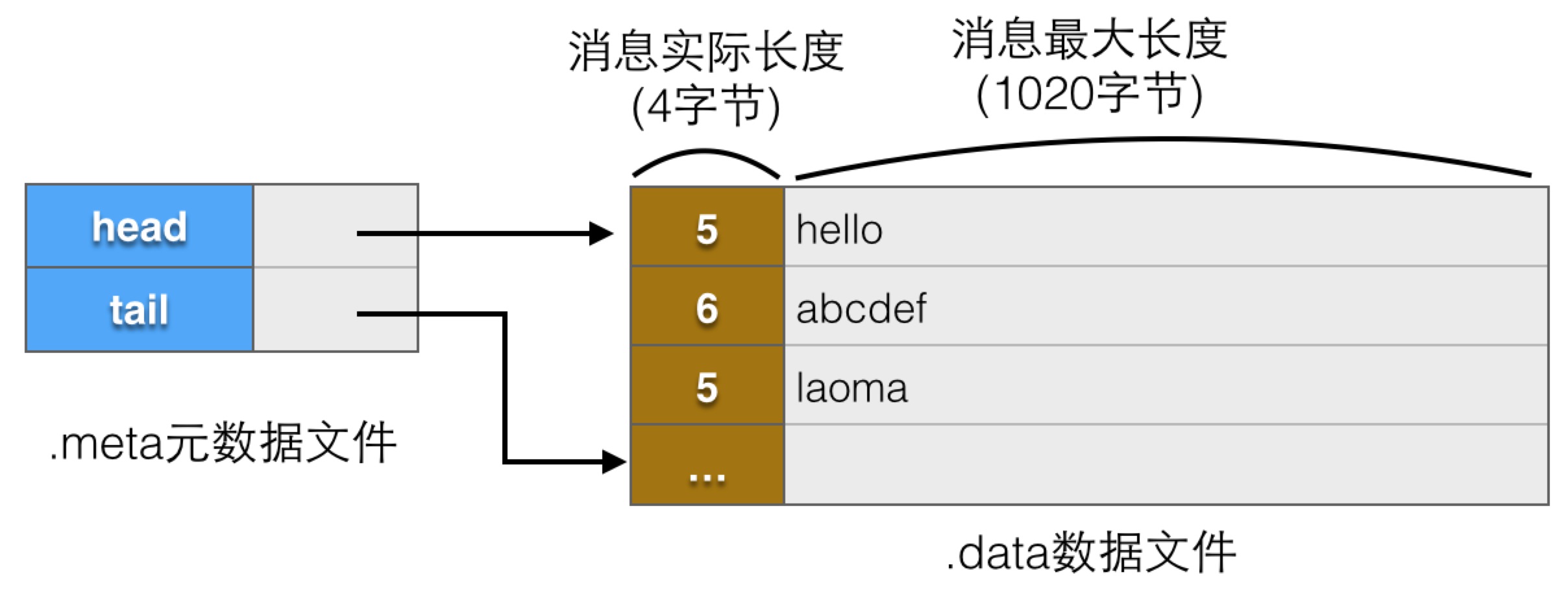
为简化起见,我们暂不考虑由于并发访问等引起的一致性问题。
实现消息队列
下面来看BasicQueue的具体实现代码。
常量定义
BasicQueue中定义了如下常量,名称和含义如下:
// 队列最多消息个数,实际个数还会减1
private static final int MAX_MSG_NUM = 1020*1024;
// 消息体最大长度
private static final int MAX_MSG_BODY_SIZE = 1020;
// 每条消息占用的空间
private static final int MSG_SIZE = MAX_MSG_BODY_SIZE + 4;
// 队列消息体数据文件大小
private static final int DATA_FILE_SIZE = MAX_MSG_NUM * MSG_SIZE;
// 队列元数据文件大小 (head + tail)
private static final int META_SIZE = 8;
内部组成
BasicQueue的内部成员主要就是两个MappedByteBuffer,分别表示数据和元数据:
private MappedByteBuffer dataBuf;
private MappedByteBuffer metaBuf;
构造方法
BasicQueue的构造方法代码是:
public BasicQueue(String path, String queueName) throws IOException {
if (path.endsWith(File.separator)) {
path += File.separator;
}
RandomAccessFile dataFile = null;
RandomAccessFile metaFile = null;
try {
dataFile = new RandomAccessFile(path + queueName + ".data", "rw");
metaFile = new RandomAccessFile(path + queueName + ".meta", "rw");
dataBuf = dataFile.getChannel().map(MapMode.READ_WRITE, 0,
DATA_FILE_SIZE);
metaBuf = metaFile.getChannel().map(MapMode.READ_WRITE, 0,
META_SIZE);
} finally {
if (dataFile != null) {
dataFile.close();
}
if (metaFile != null) {
metaFile.close();
}
}
}
辅助方法
为了方便访问和修改队列头尾指针,我们有如下方法:
private int head() {
return metaBuf.getInt(0);
}
private void head(int newHead) {
metaBuf.putInt(0, newHead);
}
private int tail() {
return metaBuf.getInt(4);
}
private void tail(int newTail) {
metaBuf.putInt(4, newTail);
}
为了便于判断队列是空还是满,我们有如下方法:
private boolean isEmpty(){
return head() == tail();
}
private boolean isFull(){
return ((tail() + MSG_SIZE) % DATA_FILE_SIZE) == head();
}
入队
代码为:
public void enqueue(byte[] data) throws IOException {
if (data.length > MAX_MSG_BODY_SIZE) {
throw new IllegalArgumentException("msg size is " + data.length
+ ", while maximum allowed length is " + MAX_MSG_BODY_SIZE);
}
if (isFull()) {
throw new IllegalStateException("queue is full");
}
int tail = tail();
dataBuf.position(tail);
dataBuf.putInt(data.length);
dataBuf.put(data);
if (tail + MSG_SIZE >= DATA_FILE_SIZE) {
tail(0);
} else {
tail(tail + MSG_SIZE);
}
}
基本逻辑是:
- 如果消息太长或队列满,抛出异常。
- 找到队列尾,定位到队列尾,写消息长度,写实际数据。
- 更新队列尾指针,如果已到文件尾,再从头开始。
出队
代码为:
public byte[] dequeue() throws IOException {
if (isEmpty()) {
return null;
}
int head = head();
dataBuf.position(head);
int length = dataBuf.getInt();
byte[] data = new byte[length];
dataBuf.get(data);
if (head + MSG_SIZE >= DATA_FILE_SIZE) {
head(0);
} else {
head(head + MSG_SIZE);
}
return data;
}
基本逻辑是:
- 如果队列为空,返回null。
- 找到队列头,定位到队列头,读消息长度,读实际数据。
- 更新队列头指针,如果已到文件尾,再从头开始。
- 最后返回实际数据
小结
本节介绍了内存映射文件的基本概念及在Java中的的用法,在日常普通的文件读写中,我们用到的比较少,但在一些系统程序中,它却是经常被用到的一把利器,可以高效的读写大文件,且能实现不同程序间的共享和通信。
利用内存映射文件,我们设计和实现了一个简单的消息队列,消息可以持久化,可以实现跨程序的生产者/消费者通信,我们演示了这个消息队列的功能、用法、设计和实现代码。
前面几节,我们多次提到过序列化的概念,它到底是什么呢?
----------------
未完待续,查看最新文章,敬请关注微信公众号“老马说编程”(扫描下方二维码),从入门到高级,深入浅出,老马和你一起探索Java编程及计算机技术的本质。用心原创,保留所有版权。

Java编程的逻辑 (61) - 内存映射文件及其应用 - 实现一个简单的消息队列的更多相关文章
- Java编程的逻辑 (60) - 随机读写文件及其应用 - 实现一个简单的KV数据库
本系列文章经补充和完善,已修订整理成书<Java编程的逻辑>,由机械工业出版社华章分社出版,于2018年1月上市热销,读者好评如潮!各大网店和书店有售,欢迎购买,京东自营链接:http:/ ...
- Windows核心编程 第十七章 -内存映射文件(下)
17.3 使用内存映射文件 若要使用内存映射文件,必须执行下列操作步骤: 1) 创建或打开一个文件内核对象,该对象用于标识磁盘上你想用作内存映射文件的文件. 2) 创建一个文件映射内核对象,告诉系统该 ...
- JAVA NIO之浅谈内存映射文件原理与DirectMemory
JAVA类库中的NIO包相对于IO 包来说有一个新功能是内存映射文件,日常编程中并不是经常用到,但是在处理大文件时是比较理想的提高效率的手段.本文我主要想结合操作系统中(OS)相关方面的知识介绍一下原 ...
- Windows核心编程 第十七章 -内存映射文件(上)
第1 7章 内存映射文件 对文件进行操作几乎是所有应用程序都必须进行的,并且这常常是人们争论的一个问题.应用程序究竟是应该打开文件,读取文件并关闭文件,还是打开文件,然后使用一种缓冲算法,从文件的各个 ...
- 《windows核心编程》 17章 内存映射文件
内存映射文件主要用于以下三种情况: 系统使用内存映射文件载入并运行exe和dll,这大量节省了页交换文件的空间以及应用程序的启动时间 开发人员可以使用内存映射文件来访问磁盘上的数据文件.这使得我们可以 ...
- 计算机程序的思维逻辑 (60) - 随机读写文件及其应用 - 实现一个简单的KV数据库
57节介绍了字节流, 58节介绍了字符流,它们都是以流的方式读写文件,流的方式有几个限制: 要么读,要么写,不能同时读和写 不能随机读写,只能从头读到尾,且不能重复读,虽然通过缓冲可以实现部分重读,但 ...
- 《Java编程的逻辑》 - 文章列表
<计算机程序的思维逻辑>系列文章已整理成书<Java编程的逻辑>,由机械工业出版社出版,2018年1月上市,各大网店有售,敬请关注! 京东自营链接:https://item.j ...
- 内存映射文件(Memory-Mapped File)
Java Memory-Mapped File所使用的内存分配在物理内存而不是JVM堆内存,且分配在OS内核. 1: 内存映射文件及其应用 - 实现一个简单的消息队列 / 计算机程序的思维逻辑 在一般 ...
- Java编程的逻辑 (56) - 文件概述
本系列文章经补充和完善,已修订整理成书<Java编程的逻辑>,由机械工业出版社华章分社出版,于2018年1月上市热销,读者好评如潮!各大网店和书店有售,欢迎购买,京东自营链接:http:/ ...
随机推荐
- POJ 2584 T-Shirt Gumbo
T-Shirt Gumbo Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 3689 Accepted: 1755 Des ...
- 搜索引擎(Solr-搜索详解)
学习目标 1.掌握SOLR的搜索工作流程: 2.掌握solr搜索的表示语法及查询解析器 3.熟悉solr搜索的JSON格式 API Solr搜索流程介绍 回顾,使用 lucene进行搜索的步骤: So ...
- suoi44 核能显示屏 (cdq分治)
首先二维树状数组肯定开不下 仿照二维树状数组的做法,如果有差分数组$d[i][j]=a[i][j]-a[i-1][j]-a[i][j-1]+a[i-1][j-1]$,那么就有: $$sum[x][y] ...
- 《剑指offer》— JavaScript(30)连续子数组的最大和
连续子数组的最大和 题目描述 HZ偶尔会拿些专业问题来忽悠那些非计算机专业的同学.今天测试组开完会后,他又发话了:在古老的一维模式识别中,常常需要计算连续子向量的最大和,当向量全为正数的时候,问题很好 ...
- 基于asp.net + easyui框架,一步步学习easyui-datagrid——实现分页和搜索(二)
http://blog.csdn.net/jiuqiyuliang/article/details/19967031 目录: 基于asp.net + easyui框架,一步步学习easyui-data ...
- LeetCode 8 有效的括号
给定一个只包括 '(',')','{','}','[',']' 的字符串,判断字符串是否有效. 有效字符串需满足: 左括号必须用相同类型的右括号闭合. 左括号必须以正确的顺序闭合. 注意空字符串可被认 ...
- weblogic11G 修改密码
weblogic11的登录密码修改方法: 1. 登陆到weblogic后选中domain structure下的security Realms(如图一) (图一) 详情如图二: (图二) 2. 双 ...
- Codeforces Round #481 (Div. 3) G. Petya's Exams
http://codeforces.com/contest/978/problem/G 感冒是真的受不了...敲代码都没力气... 题目大意: 期末复习周,一共持续n天,有m场考试 每场考试有如下信息 ...
- springmvc常用注解标签详解-推荐
1.@Controller 在SpringMVC 中,控制器Controller 负责处理由DispatcherServlet 分发的请求,它把用户请求的数据经过业务处理层处理之后封装成一个Model ...
- Kafka 温故(五):Kafka的消费编程模型
Kafka的消费模型分为两种: 1.分区消费模型 2.分组消费模型 一.分区消费模型 二.分组消费模型 Producer : package cn.outofmemory.kafka; import ...