Spark 实践——用决策树算法预测森林植被
本文基于《Spark 高级数据分析》第4章 用决策树算法预测森林植被集。
完整代码见 https://github.com/libaoquan95/aasPractice/tree/master/c4/rdf
1.获取数据集
本 章 用 到 的 数 据 集 是 著 名 的 Covtype 数 据 集, 该 数 据 集 可 以 在 线 下 载(http://t.cn/R2wmIsI),包含一个 CSV 格式的压缩数据文件 covtype.data.gz,附带一个描述数据文件的信息文件 covtype.info。
该数据集记录了美国科罗拉多州不同地块的森林植被类型(也就是现实中的森林,这仅仅是巧合!)每个样本包含了描述每块土地的若干特征,包括海拔、坡度、到水源的距离、遮阳情况和土壤类型, 并且随同给出了地块的已知森林植被类型。我们需要总共 54 个特征中的其余各项来预测森林植被类型。
人们已经用该数据集进行了研究,甚至在 Kaggle 大赛(https://www.kaggle.com/c/forestcover-type-prediction) 中也用过它。本章之所以研究这个数据集, 原因在于它不但包含了数值型特征而且包含了类别型特征。 该数据集有 581 012 个样本,虽然还称不上大数据,但作为一个范例来已经足够大,而且也能够反映出大数据上的一些问题。
下载地址:
2.数据处理
加载数据
val dataDir = "covtype.data"
val dataWithoutHeader = sc.read. option("inferSchema", true).option("header", false). csv(dataDir)
dataWithoutHeader.printSchema
结构化数据
val colNames = Seq(
"Elevation", "Aspect", "Slope",
"Horizontal_Distance_To_Hydrology", "Vertical_Distance_To_Hydrology",
"Horizontal_Distance_To_Roadways",
"Hillshade_9am", "Hillshade_Noon", "Hillshade_3pm",
"Horizontal_Distance_To_Fire_Points"
) ++ (
(0 until 4).map(i => s"Wilderness_Area_$i")
) ++ (
(0 until 40).map(i => s"Soil_Type_$i")
) ++ Seq("Cover_Type")
val data = dataWithoutHeader.toDF(colNames:_*).
withColumn("Cover_Type", $"Cover_Type".cast("double"))
val Array(trainData, testData) = data.randomSplit(Array(0.9, 0.1))
trainData.cache()
testData.cache()
data.printSchema
3.构造决策树
构造特征向量
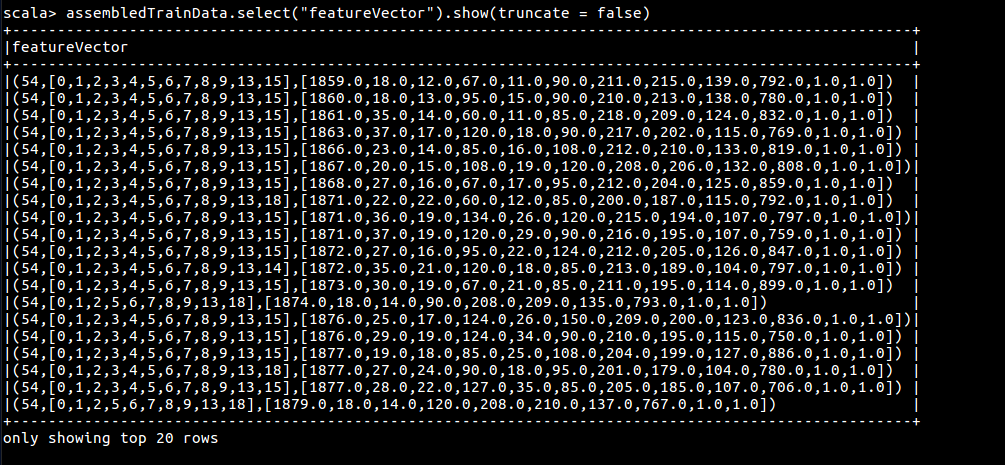
val inputCols = trainData.columns.filter(_ != "Cover_Type")
val assembler = new VectorAssembler().setInputCols(inputCols).setOutputCol("featureVector")
val assembledTrainData = assembler.transform(trainData)
val classifier = new DecisionTreeClassifier().
setSeed(Random.nextLong()).
setLabelCol("Cover_Type").
setFeaturesCol("featureVector").
setPredictionCol("prediction")
训练模型
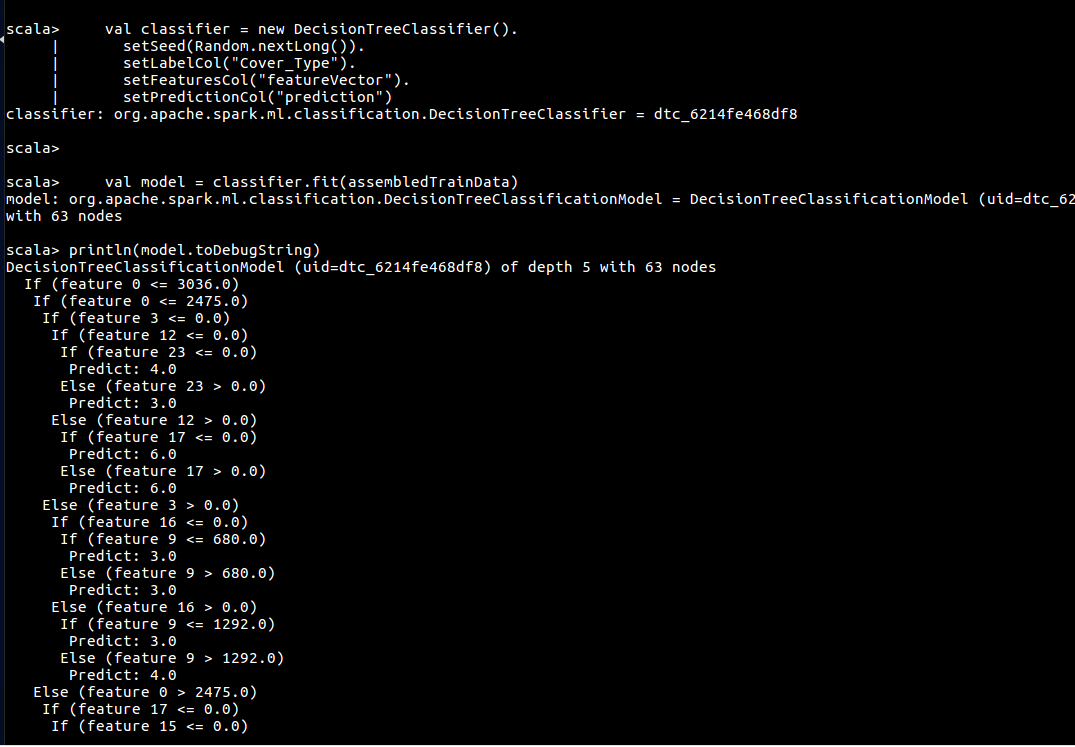
val model = classifier.fit(assembledTrainData)
println(model.toDebugString)
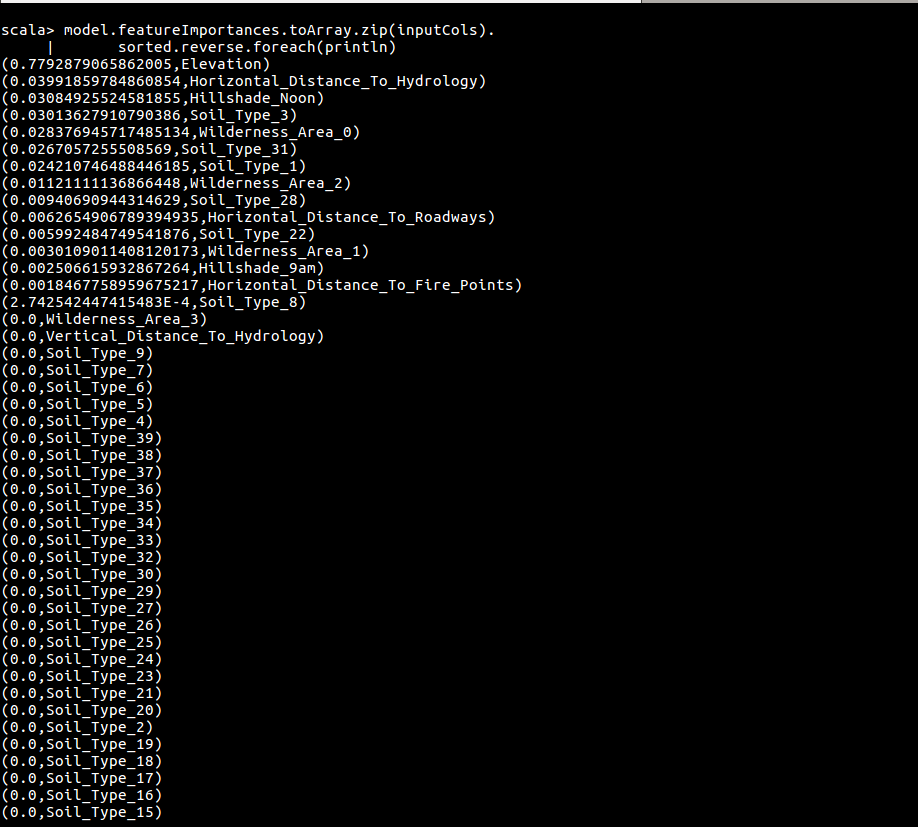
model.featureImportances.toArray.zip(inputCols).sorted.reverse.foreach(println)
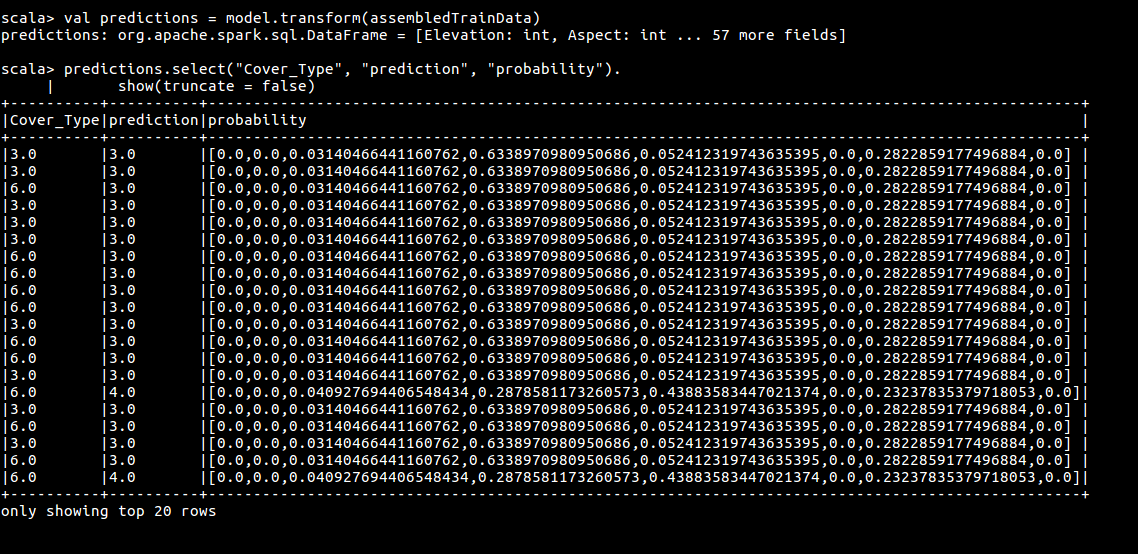
val predictions = model.transform(assembledTrainData)
predictions.select("Cover_Type", "prediction", "probability"). show(truncate = false)
评估模型
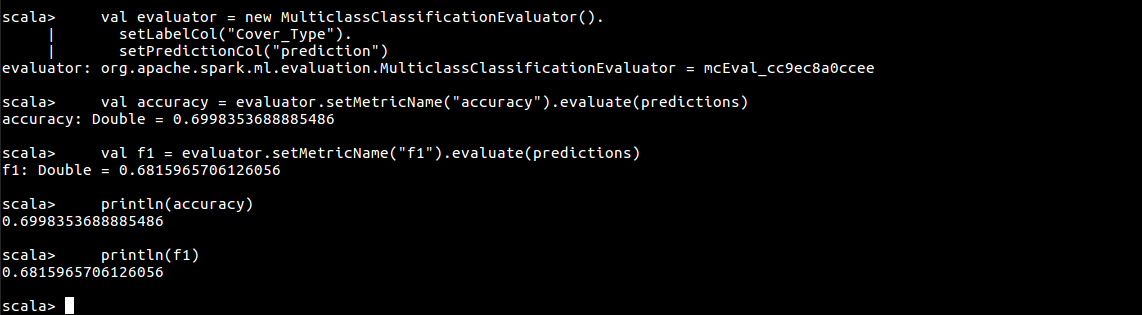
val evaluator = new MulticlassClassificationEvaluator(). setLabelCol("Cover_Type"). setPredictionCol("prediction")
val accuracy = evaluator.setMetricName("accuracy").evaluate(predictions)
val f1 = evaluator.setMetricName("f1").evaluate(predictions)
println(accuracy)
println(f1)
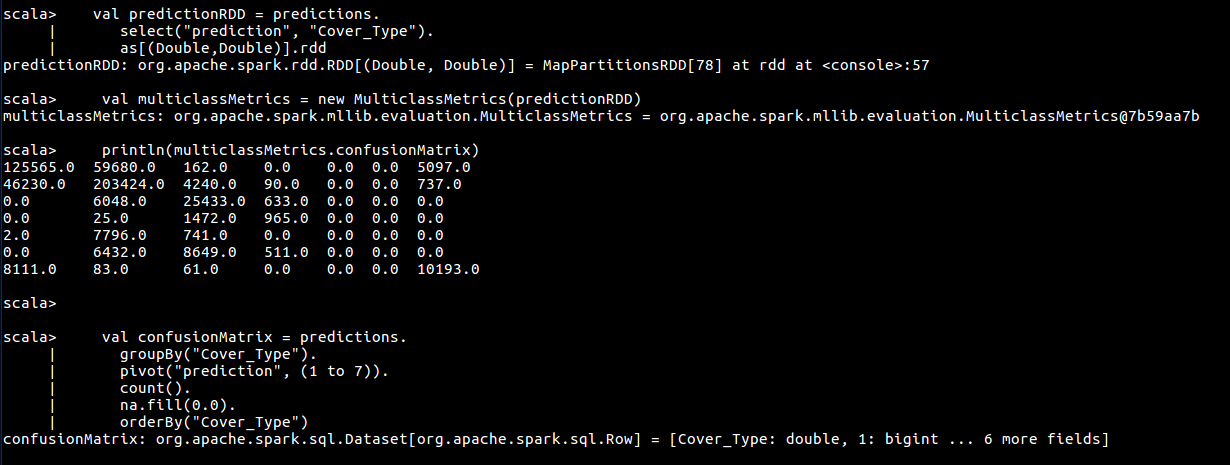
val predictionRDD = predictions.
select("prediction", "Cover_Type").
as[(Double,Double)].rdd
val multiclassMetrics = new MulticlassMetrics(predictionRDD)
println(multiclassMetrics.confusionMatrix)
val confusionMatrix = predictions.
groupBy("Cover_Type").
pivot("prediction", (1 to 7)).
count().
na.fill(0.0).
orderBy("Cover_Type")
confusionMatrix.show()
Spark 实践——用决策树算法预测森林植被的更多相关文章
- 4-Spark高级数据分析-第四章 用决策树算法预测森林植被
预测是非常困难的,更别提预测未来. 4.1 回归简介 随着现代机器学习和数据科学的出现,我们依旧把从“某些值”预测“另外某个值”的思想称为回归.回归是预测一个数值型数量,比如大小.收入和温度,而分类则 ...
- Spark机器学习(6):决策树算法
1. 决策树基本知识 决策树就是通过一系列规则对数据进行分类的一种算法,可以分为分类树和回归树两类,分类树处理离散变量的,回归树是处理连续变量. 样本一般都有很多个特征,有的特征对分类起很大的作用,有 ...
- 2022极端高温!机器学习如何预测森林火灾?⛵ 万物AI
作者:ShowMeAI编辑部 声明:版权所有,转载请联系平台与作者并注明出处 收藏ShowMeAI查看更多精彩内容 今年夏天,重庆北碚区山火一路向国家级自然保护区缙云山方向蔓延.为守护家园,数万名重庆 ...
- scikit-learn决策树算法类库使用小结
之前对决策树的算法原理做了总结,包括决策树算法原理(上)和决策树算法原理(下).今天就从实践的角度来介绍决策树算法,主要是讲解使用scikit-learn来跑决策树算法,结果的可视化以及一些参数调参的 ...
- 决策树算法原理(CART分类树)
决策树算法原理(ID3,C4.5) CART回归树 决策树的剪枝 在决策树算法原理(ID3,C4.5)中,提到C4.5的不足,比如模型是用较为复杂的熵来度量,使用了相对较为复杂的多叉树,只能处理分类不 ...
- python机器学习笔记 ID3决策树算法实战
前面学习了决策树的算法原理,这里继续对代码进行深入学习,并掌握ID3的算法实践过程. ID3算法是一种贪心算法,用来构造决策树,ID3算法起源于概念学习系统(CLS),以信息熵的下降速度为选取测试属性 ...
- 决策树算法原理--good blog
转载于:http://www.cnblogs.com/pinard/p/6050306.html (楼主总结的很好,就拿来主义了,不顾以后还是多像楼主学习) 决策树算法在机器学习中算是很经典的一个算法 ...
- 决策树算法的Python实现—基于金融场景实操
决策树是最经常使用的数据挖掘算法,本次分享jacky带你深入浅出,走进决策树的世界 基本概念 决策树(Decision Tree) 它通过对训练样本的学习,并建立分类规则,然后依据分类规则,对新样本数 ...
- R_Studio(决策树算法)鸢尾花卉数据集Iris是一类多重变量分析的数据集【精】
鸢尾花卉数据集Iris是一类多重变量分析的数据集 通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类 针对 ...
随机推荐
- SGU刷题之路开启
VJ小组:SGU---48h/题 每道做出的题目写成题解,将传送门更新在这里. SGU:101 - 200 SGU - 107 水题 解题报告 SGU - 105 找规律水题 解题报告 SGU - 1 ...
- MySQL多实例.md
MySQL5.7多实例配置 数据库实例1配置文件 # cat /etc/my.cnf [mysqld] datadir=/data/mysql port=3306 socket=/tmp/mysql. ...
- BZOJ2815:[ZJOI2012]灾难(拓扑排序,LCA)
Description 阿米巴是小强的好朋友. 阿米巴和小强在草原上捉蚂蚱.小强突然想,如果蚂蚱被他们捉灭绝了,那么吃蚂蚱的小鸟就会饿死,而捕食小鸟的猛禽也会跟着灭绝,从而引发一系列的生态灾难. 学过 ...
- Jmeter遇到线程链接被重置(Connection reset by peer: socket write error)的解决方法
做性能测试的时候遇到一个很奇怪的问题,多线程的计划,有一个线程第一次能跑过,第二次确跑不过,单独跑这个线程跑多少次都没有问题,把思考时间改短也没有问题,唯独出现在特定的状态下,特定状态是啥,也不得而知 ...
- 20165302 程上杰 Exp2 后门原理与实践
一,后门概念 后门就是不经过正常认证流程而访问系统的通道. 二,后门工具 1.netcat(nc.ncat) 是一个底层工具,进行基本的TCP UDP数据收发.常被与其他工具结合使用,起到后门的作用. ...
- WorldWind源码剖析系列:角度类Angle
PluginSDK中的角度结构体Angle类图如下所示. 角度结构体主要定义了一个弧度表示角度值的字段:double Radians.还有几个表示角度最大值.最小值.非数值和零角度等字段.定义了一个D ...
- docker push images login -u harbor 问题记录 https 证书
1.[root@dev-100 Desktop]# docker login -u clouder -p engine harbor.xiaowei.com 2.docker tag busybox: ...
- 突然的明白--public static 类名 函数名()
public static ImageUtilEngine getImageEngine() { return imageEngine; } 这个是什么啊........纠结了一个多星期的东西 忽然间 ...
- day05-列表类型
列表类型: 用途:存放多个值,根据索引. 定义方式:在[]内用逗号分隔开多个任意类型的值 L1 = list[{a:1,b:2,c:3}] 输出的为字典的key值 常用操作+内置方法 1.按索引取值: ...
- ASP.NET Core MVC 模型绑定 (转载)
ASP.NET Core MVC的Model Binding会将HTTP Request数据,以映射的方式对应到参数中.基本上跟ASP.NET MVC差不多,但能Binding的来源更多了一些.本篇将 ...