34.scrapy解决爬虫翻页问题
这里主要解决的问题: 1.翻页需要找到页面中加载的两个参数。
'__VIEWSTATE': '{}'.format(response.meta['data']['__VIEWSTATE']),
'__EVENTVALIDATION': '{}'.format(response.meta['data']['__EVENTVALIDATION']),
还有一点需要注意的就是 dont_filter=False
yield scrapy.FormRequest(url=response.url, callback=self.parse, formdata=data, method="POST", dont_filter=False)
2.日期 我自己做的时候取的是2008-2018年的数据。
3.还有的就是数据字段入库乱的问题。
4.一些问题比如越界等,我都没做具体的解决只是做了一个抛出异常没做处理。 这个相对较麻烦一点,首先先分析一下网站,地址: http://www.nbzj.net/MaterialPriceList.aspx (宁波造价网) 这里呢我主要是拿这个材料信息价数据。
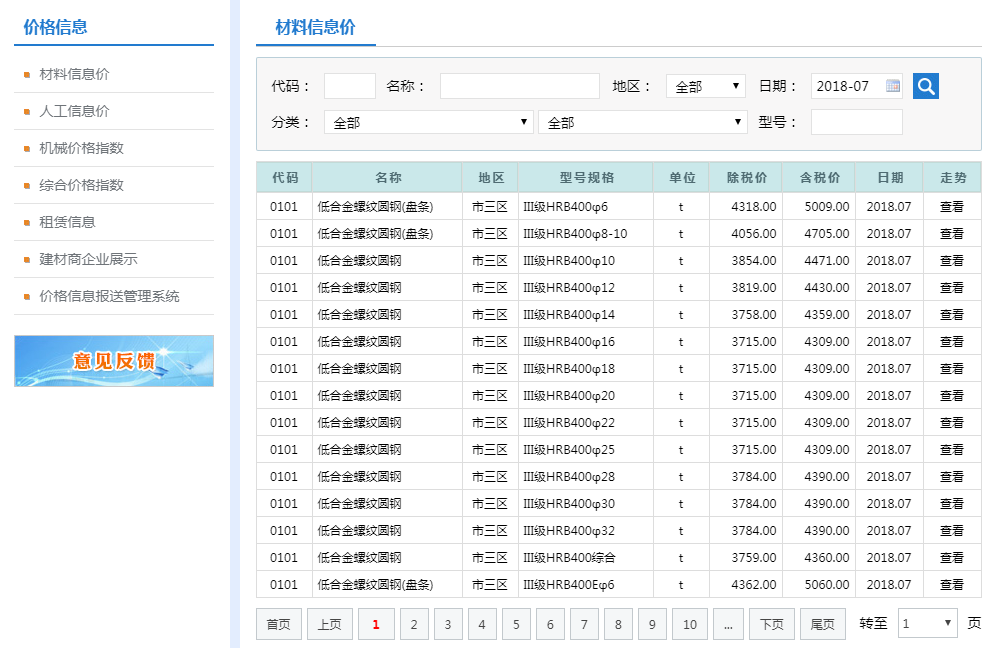
nbzj.py # -*- coding: utf-8 -*-
import scrapy
import re
from nbzj_web.items import NbzjWebItem class NbzjSpider(scrapy.Spider):
name = 'nbzj'
allowed_domains = ['www.nbzj.net']
start_urls = ['http://www.nbzj.net/MaterialPriceList.aspx']
custom_settings = {
"DOWNLOAD_DELAY": 1,
"ITEM_PIPELINES": {
'nbzj_web.pipelines.MysqlPipeline': 300,
},
"DOWNLOADER_MIDDLEWARES": {
'nbzj_web.middlewares.NbzjWebDownloaderMiddleware': 500,
},
}
def parse(self, response):
_response=response.text
# print(_response) #获取翻页参数
__VIEWSTATE=re.findall(r'id="__VIEWSTATE" value="(.*?)" />',_response) A=__VIEWSTATE[0]
# print(A)
__EVENTVALIDATION=re.findall(r'id="__EVENTVALIDATION" value="(.*?)" />',_response)
B=__EVENTVALIDATION[0]
# print(B) #页码
page_num=re.findall(r'>下页</a><a title="转到第(.*?)页"',_response)
# print(page_num[0])
max_page=page_num[0]
# print(max_page) content={
'__VIEWSTATE':A,
'__EVENTVALIDATION':B,
'page_num':max_page,
} # 获取标签列表 tag_list=response.xpath("//div[@class='fcon']/table[@class='mytable']//tr/td").extract()
# print(tag_list)
#这里我直接取文本出现问题,我就直接拿标签数据等下面在做字符串的修改删除
list=[]
try:
tag1=tag_list[:9]
list.append(tag1)
tag2=tag_list[9:18]
list.append(tag2)
tag3=tag_list[18:27]
list.append(tag3)
tag4=tag_list[27:36]
list.append(tag4)
tag5=tag_list[36:45]
list.append(tag5)
tag6=tag_list[45:54]
list.append(tag6)
tag7=tag_list[54:63]
list.append(tag7)
tag8=tag_list[63:72]
list.append(tag8)
tag9=tag_list[72:81]
list.append(tag9)
tag10=tag_list[81:90]
list.append(tag10)
tag11=tag_list[99:108]
list.append(tag11)
tag12=tag_list[108:117]
list.append(tag12)
tag13=tag_list[117:126]
list.append(tag13)
tag14=tag_list[126:135]
list.append(tag14)
tag15=tag_list[135:144]
list.append(tag15) print(list) for tag in list: item=NbzjWebItem()
# print(tag)
#代码
code=tag[0].replace('<td style="text-align: center">','').replace('</td>','')
# print(code)
item['code']=code
#名称
name=tag[1].replace('<td>','').replace('</td>','')
# print(name)
item['name']=name
#地区
district=tag[2].replace('<td style="text-align: center">','').replace('</td>','')
# print(district)
item['district']=district
#型号规格
_type=tag[3].replace('<td>','').replace('</td>','')
# print(_type)
item['_type']=_type
#单位
unit=tag[4].replace('<td style="text-align: center">','').replace('</td>','')
# print(unit)
item['unit']=unit
#除税价
except_tax_price = tag[5].replace('<td style="text-align: right">','').replace('</td>','')
# print(except_tax_price)
item['except_tax_price']=except_tax_price
#含税价
tax_price = tag[6].replace('<td style="text-align: right">','').replace('</td>','')
# print(tax_price)
item['tax_price']=tax_price
#时间
time=tag[7].replace('<td style="text-align: center">','').replace('</td>','')
print(time)
item['time']=time # print('-'*100)
yield item
# print('*'*100)
except:
pass yield scrapy.Request(url=response.url,callback=self.parse_detail,meta={"data": content}) def parse_detail(self,response):
for h in range(2008,2019):
list=['','','','','','','','','','','','']
for j in list:
try:
max_page=response.meta['data']['page_num']
# print(max_page)
for i in range(2,int(max_page)):
data={ '__VIEWSTATE': '{}'.format(response.meta['data']['__VIEWSTATE']),
'__VIEWSTATEGENERATOR': 'E53A32FA',
'__EVENTTARGET': 'ctl00$ContentPlaceContent$Pager',
'__EVENTARGUMENT':'{}'.format(i),
'__EVENTVALIDATION': '{}'.format(response.meta['data']['__EVENTVALIDATION']),
'HeadSearchType': 'localsite',
'ctl00$ContentPlaceContent$txtnewCode':'',
'ctl00$ContentPlaceContent$txtMaterualName':'',
'ctl00$ContentPlaceContent$ddlArea':'',
'ctl00$ContentPlaceContent$txtPublishDate': '{} - 0{}'.format(h,j),
'ctl00$ContentPlaceContent$ddlCategoryOne':'',
'ctl00$ContentPlaceContent$hidCateId':'',
'ctl00$ContentPlaceContent$txtSpecification':'',
'ctl00$ContentPlaceContent$Pager_input': '{}'.format(i-1),
'ctl00$foot$ddlsnzjw': '',
'ctl00$foot$ddlswzjw': '',
'ctl00$foot$ddlqtxgw': ''
}
yield scrapy.FormRequest(url=response.url, callback=self.parse, formdata=data, method="POST", dont_filter=False)
except:
pass
items.py # -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class NbzjWebItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field() code=scrapy.Field()
name=scrapy.Field()
district=scrapy.Field()
_type=scrapy.Field()
unit=scrapy.Field()
except_tax_price=scrapy.Field()
tax_price =scrapy.Field()
time=scrapy.Field()
middlewares.py # -*- coding: utf-8 -*- # Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html from scrapy import signals class NbzjWebSpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects. @classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider. # Should return None or raise an exception.
return None def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response. # Must return an iterable of Request, dict or Item objects.
for i in result:
yield i def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception. # Should return either None or an iterable of Response, dict
# or Item objects.
pass def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated. # Must return only requests (not items).
for r in start_requests:
yield r def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name) class NbzjWebDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects. @classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware. # Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None def process_response(self, request, response, spider):
# Called with the response returned from the downloader. # Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception. # Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
piplines.py # -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html # -*- coding: utf-8 -*-
from scrapy.conf import settings
import pymysql class NbzjWebPipeline(object):
def process_item(self, item, spider):
return item # 数据保存mysql
class MysqlPipeline(object): def open_spider(self, spider):
self.host = settings.get('MYSQL_HOST')
self.port = settings.get('MYSQL_PORT')
self.user = settings.get('MYSQL_USER')
self.password = settings.get('MYSQL_PASSWORD')
self.db = settings.get(('MYSQL_DB'))
self.table = settings.get('TABLE')
self.client = pymysql.connect(host=self.host, user=self.user, password=self.password, port=self.port, db=self.db, charset='utf8') def process_item(self, item, spider):
item_dict = dict(item)
cursor = self.client.cursor()
values = ','.join(['%s'] * len(item_dict))
keys = ','.join(item_dict.keys())
sql = 'INSERT INTO {table}({keys}) VALUES ({values})'.format(table=self.table, keys=keys, values=values)
try:
if cursor.execute(sql, tuple(item_dict.values())): # 第一个值为sql语句第二个为 值 为一个元组
print('数据入库成功!')
self.client.commit()
except Exception as e:
print(e) print('数据已存在!')
self.client.rollback()
return item def close_spider(self, spider): self.client.close()
setting.py # -*- coding: utf-8 -*- # Scrapy settings for nbzj_web project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'nbzj_web' SPIDER_MODULES = ['nbzj_web.spiders']
NEWSPIDER_MODULE = 'nbzj_web.spiders' # mysql配置参数
MYSQL_HOST = "172.16.10.197"
MYSQL_PORT = 3306
MYSQL_USER = "root"
MYSQL_PASSWORD = ""
MYSQL_DB = 'web_datas'
TABLE = "web_nbzj" # Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'nbzj_web (+http://www.yourdomain.com)' # Obey robots.txt rules
ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default)
#COOKIES_ENABLED = False # Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False # Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#} # Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'nbzj_web.middlewares.NbzjWebSpiderMiddleware': 543,
#} # Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'nbzj_web.middlewares.NbzjWebDownloaderMiddleware': 543,
} # Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#} # Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'nbzj_web.pipelines.NbzjWebPipeline': 300,
} # Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
scrapy crawl nbzj 执行结果如下
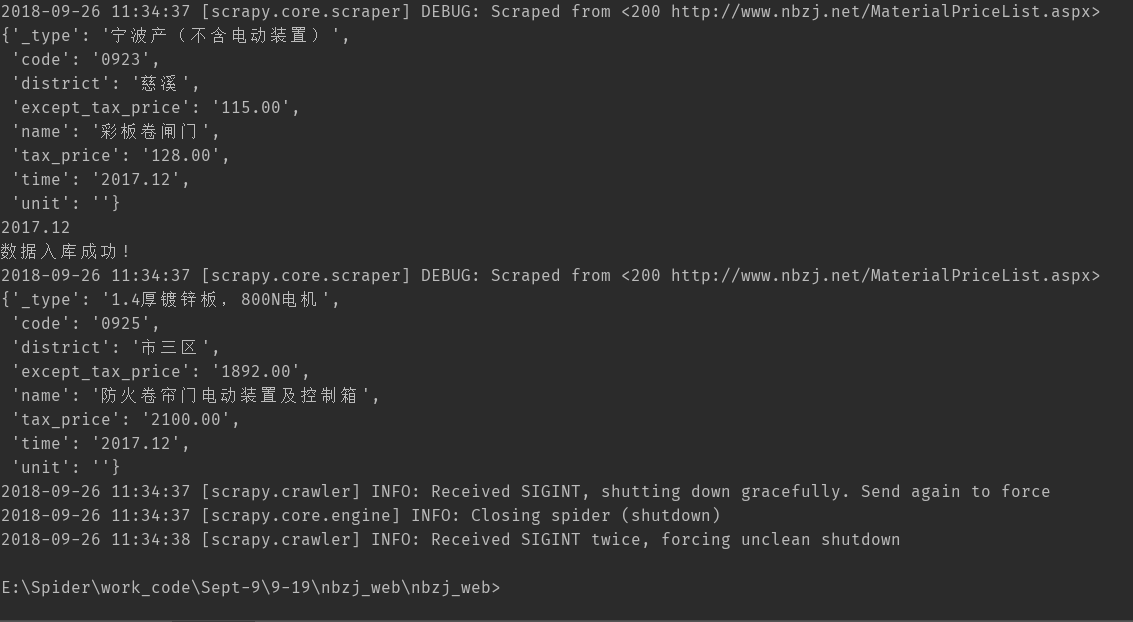

由于设置deloy为 1s 所以速度会比较慢,采集237142条数据。

34.scrapy解决爬虫翻页问题的更多相关文章
- 翻页组件page-flip调用问题
翻页组件重新调用解决方案 翻页组件:page-flip import { PageFlip } from 'page-flip' pagefile() { //绘制翻页 this.pageFlip = ...
- scrapy爬虫系列之二--翻页爬取及日志的基本用法
功能点:如何翻页爬取信息,如何发送请求,日志的简单实用 爬取网站:腾讯社会招聘网 完整代码:https://files.cnblogs.com/files/bookwed/tencent.zip 主要 ...
- 37.scrapy解决翻页及采集杭州造价网站材料数据
1.目标采集地址: http://183.129.219.195:8081/bs/hzzjb/web/list 2.这里的翻页还是较为简单的,只要模拟post请求发送data包含关键参数就能获取下一页 ...
- selenium模块跳过用户名密码验证码输入,加载浏览器标签和cookie,进行翻页爬虫多页动态加载的数据(js)
能解决登陆一次后,之后不需要二次登陆的动态加载数据,网页保存的cookie和标签,加入到selenium自动化测试浏览器中 1 from selenium import webdriver 2 imp ...
- Httpclient: 多层翻页网络爬虫实战(以搜房网为例)
参考:http://blog.csdn.net/qy20115549/article/details/52912532 一.创建数据表 #创建表:用来存储url地址信息 create table so ...
- 【解决ViewPager在大屏上滑动不流畅】 设置ViewPager滑动翻页距离
在项目中做了一个ViewPager+Fragment滑动翻页的效果,在模拟器和小米手机上测试也比较正常.但是换到4.7以上屏幕测试的时候发现老是滑动失效. 因为系统默认的滑动策略是当用户滑动超过半屏之 ...
- python爬虫_入门_翻页
写出来的爬虫,肯定不能只在一个页面爬,只要要爬几个页面,甚至一个网站,这时候就需要用到翻页了 其实翻页很简单,还是这个页面http://bbs.fengniao.com/forum/10384633. ...
- combogrid翻页后保持显示内容为配置的textField解决办法
easyui的combogrid当配置pagination为true进行分页时,当datagrid加载其他数据页,和上一次选中的valueField不匹配时,会导致combogrid直接显示value ...
- 爬虫1:get请求的翻页及思考
刚开始接触爬虫,理解还不透彻,说一些初始阶段的想法{1.因为get请求的方式(请求体无数据,不能通过Request.add_data()函数来添加数据,实现对网址翻页:需要直接对网址进行操作来实现翻页 ...
随机推荐
- python MySQL-Slave从服务器状态检测脚本
#!/bin/bash mysql -e "show slave status\G" > mysql_status.txt array=($(egrep 'Slave_IO_ ...
- 多进程共享数据,真正的通信Manager
Managers A manager object returned by Manager() controls a server process which holds Python objects ...
- 解决js输出汉字乱码问题
当我们需要使用js输出汉字时,偶然会出现输出的中文汉字乱码的情况,在网上收了很多解决方案 1.在mata中加 <meta content="text/html; charset=utf ...
- go get golang.org/x 包失败解决方法
由于墙的原因,国内使用 go get安装golang 官方包可能会失败 解决方法 方法1 [不需要FQ] Win10下相关配置: GOPATH : E:\go 安装记录: E:\>go get ...
- [转][C#]Environment 类
当执行 Environment.GetEnvironmentVariables() 时,可以得到以下结果(受所安装软件影响,每台电脑都不一样) Count = ["SystemDrive&q ...
- 不同AI学科之间的联系
这里只是引用deep learning中的关于不同AI学科之间联系的图示,如果想具体了解相关知识,深入学习深度学习,可以参考网站:http://www.deeplearningbook.org 下面是 ...
- Zabbix 添加主机
#1 #2
- git基本的使用原理
一:Git是什么? Git是目前世界上最先进的分布式版本控制系统. 二:SVN与Git的最主要的区别? SVN是集中式版本控制系统,版本库是集中放在中央服务器的,而干活的时候,用的都是自己的电脑,所以 ...
- host文件的工作原理及应用
host文件的工作原理及应用 Hosts文件是一个用于存储计算机网络中节点信息的文件,它可以将主机名映射到相应的IP地址,实现DNS的功能,它可以由计算机的用户进行控制. 一.Hosts文件基本介绍 ...
- [UE4]单机游戏改网络游戏,不完全清单
把Actor的复制打开 中腰数据的复制打开,且只在服务器修改(比如角色属性血量) 需要同步的Actor,不在客户端Spawn 客户端的操作,先报告到服务器,服务器再广播到所有客户端 某些逻辑只在服务器 ...