HBase介绍(3)---框架结构及流程
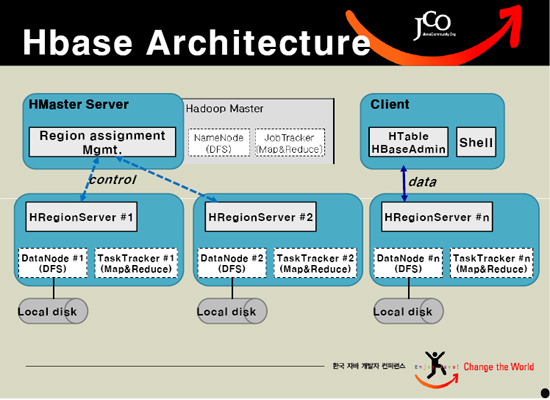
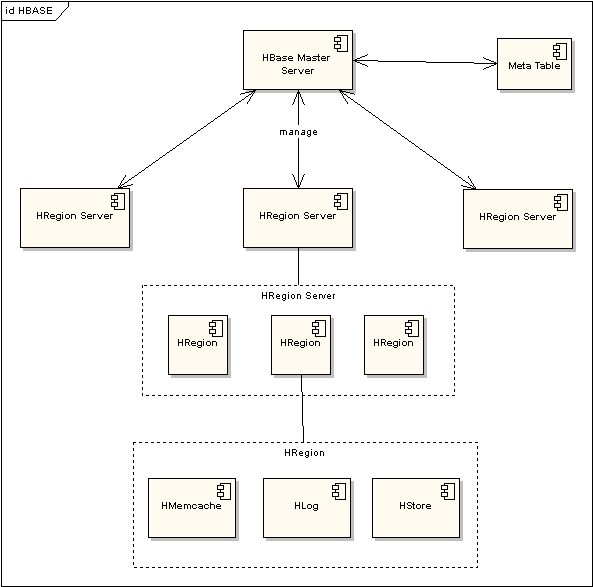
HBASE依托于Hadoop的HDFS作为存储基础,因此结构也很类似于Hadoop的Master-Slave模式,Hbase Master Server 负责管理所有的HRegion Server,但Hbase Master Server本身并不存储HBASE中的任何数据。HBASE逻辑上的Table被定义成为一个Region存储在某一台HRegion Server上,HRegion Server 与Region的对应关系是一对多的关系。每一个HRegion在物理上会被分为三个部分:Hmemcache、Hlog、HStore,分别代表了缓存,日志,持久层。通过一次更新流程来看一下这三部分的作用:
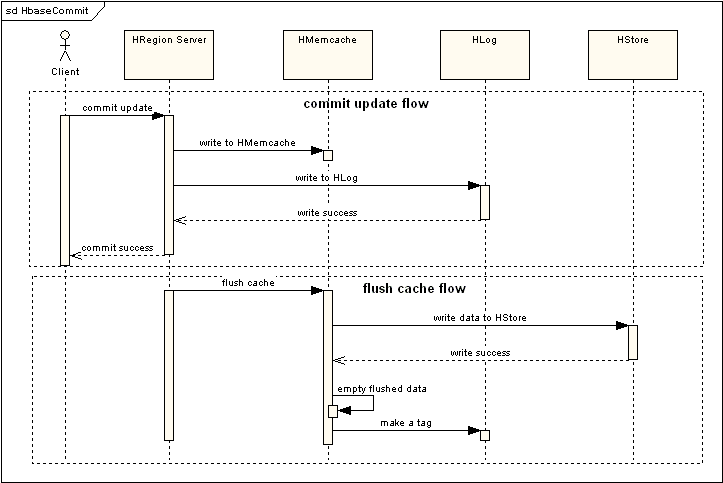
由流程可以看出,提交更新操作将会写入到两部分实体中,HMemcache和Hlog中,HMemcache就是为了提高效率在内存中建立缓存,保证了部分最近操作过的数据能够快速的被读取和修改,Hlog是作为同步Hmemcache和Hstore的事务日志,在HRegion Server周期性的发起Flush Cache命令的时候,就会将Hmemcache中的数据持久化到Hstore中,同时会清空Hmemecache中的数据,这里采用的是比较简单的策略来做数据缓存和同步,复杂一些其实可以参照java的垃圾收集机制来做。
在读取Region信息的时候,优先读取HMemcache中的内容,如果未取到再去读取Hstore中的数据。
几个细节:
1. 由于每一次Flash Cache,就会产生一个Hstore File,在Hstore中存储的文件会越来越多,对性能也会产生一定影响,因此达到设置文件数量阀值的时候就会Merge这些文件为一个大文件。
2. Cache大小的设置以及flush的时间间隔设置需要考虑内存消耗以及对性能的影响。
3. HRegion Server每次重新启动的时候会将Hlog中没有被Flush到Hstore中的数据再次载入到Hmemcache,因此Hmemcache过大对于启动的速度也有直接影响。
4. Hstore File中存储数据采用B-tree的算法,因此也支持了前面提到对于Column同Family数据操作的快速定位获取。
5. HRegion可以Merge也可以被Split,根据HRegion的大小决定。不过在做这些操作的时候HRegion都会被锁定不可使用。
6. Hbase Master Server通过Meta-info Table来获取HRegion Server的信息以及Region的信息,Meta最顶部的一个Region是虚拟的一个叫做Root Region,通过Root Region可以找到下面各个实际的Region。
7. 客户端通过Hbase Master Server获得了Region所在的Region Server,然后就直接和Region Server进行交互,而对于Region Server相互之间不通信,只和Hbase Master Server交互,受到Master Server的监控和管理。
http://wiki.apache.org/hadoop/Hbase/HbaseArchitecture
Architecture and Implementation
There are three major components of the HBase architecture:
The H!BaseMaster (analogous to the Bigtable master server)
The H!RegionServer (analogous to the Bigtable tablet server)
- The HBase client, defined by org.apache.hadoop.hbase.client.HTable
Each will be discussed in the following sections.
HBaseMaster
The H!BaseMaster is responsible for assigning regions to H!RegionServers. The first region to be assigned is the ROOT region which locates all the META regions to be assigned. Each META region maps a number of user regions which comprise the multiple tables that a particular HBase instance serves. Once all the META regions have been assigned, the master will then assign user regions to the H!RegionServers, attempting to balance the number of regions served by each H!RegionServer.
It also holds a pointer to the H!RegionServer that is hosting the ROOT region.
The H!BaseMaster also monitors the health of each H!RegionServer, and if it detects a H!RegionServer is no longer reachable, it will split the H!RegionServer's write-ahead log so that there is now one write-ahead log for each region that the H!RegionServer was serving. After it has accomplished this, it will reassign the regions that were being served by the unreachable H!RegionServer.
In addition, the H!BaseMaster is also responsible for handling table administrative functions such as on/off-lining of tables, changes to the table schema (adding and removing column families), etc.
Unlike Bigtable, currently, when the H!BaseMaster dies, the cluster will shut down. In Bigtable, a Tabletserver can still serve Tablets after its connection to the Master has died. We tie them together, because we do not currently use an external lock-management system like Bigtable. The Bigtable Master allocates tablets and a lock manager (Chubby) guarantees atomic access by Tabletservers to tablets. HBase uses just a single central point for all H!RegionServers to access: the H!BaseMaster.
The META Table
The META table stores information about every user region in HBase which includes a H!RegionInfo object containing information such as the start and end row keys, whether the region is on-line or off-line, etc. and the address of the H!RegionServer that is currently serving the region. The META table can grow as the number of user regions grows.
The ROOT Table
The ROOT table is confined to a single region and maps all the regions in the META table. Like the META table, it contains a H!RegionInfo object for each META region and the location of the H!RegionServer that is serving that META region.
Each row in the ROOT and META tables is approximately 1KB in size. At the default region size of 256MB, this means that the ROOT region can map 2.6 x 105 META regions, which in turn map a total 6.9 x 1010 user regions, meaning that approximately 1.8 x 1019 (264) bytes of user data.
HRegionServer
The H!RegionServer is responsible for handling client read and write requests. It communicates with the H!BaseMaster to get a list of regions to serve and to tell the master that it is alive. Region assignments and other instructions from the master "piggy back" on the heart beat messages.
Write Requests
When a write request is received, it is first written to a write-ahead log called a HLog. All write requests for every region the region server is serving are written to the same log. Once the request has been written to the HLog, it is stored in an in-memory cache called the Memcache. There is one Memcache for each HStore.
Read Requests
Reads are handled by first checking the Memcache and if the requested data is not found, the MapFiles are searched for results.
Cache Flushes
When the Memcache reaches a configurable size, it is flushed to disk, creating a new MapFile and a marker is written to the HLog, so that when it is replayed, log entries before the last flush can be skipped. A flush may also be triggered to relieve memory pressure on the region server.
Cache flushes happen concurrently with the region server processing read and write requests. Just before the new MapFile is moved into place, reads and writes are suspended until the MapFile has been added to the list of active MapFiles for the HStore.
Compactions
When the number of MapFiles exceeds a configurable threshold, a minor compaction is performed which consolidates the most recently written MapFiles. A major compaction is performed periodically which consolidates all the MapFiles into a single MapFile. The reason for not always performing a major compaction is that the oldest MapFile can be quite large and reading and merging it with the latest MapFiles, which are much smaller, can be very time consuming due to the amount of I/O involved in reading merging and writing the contents of the largest MapFile.
Compactions happen concurrently with the region server processing read and write requests. Just before the new MapFile is moved into place, reads and writes are suspended until the MapFile has been added to the list of active MapFiles for the HStore and the MapFiles that were merged to create the new MapFile have been removed.
Region Splits
When the aggregate size of the MapFiles for an HStore reaches a configurable size (currently 256MB), a region split is requested. Region splits divide the row range of the parent region in half and happen very quickly because the child regions read from the parent's MapFile.
The parent region is taken off-line, the region server records the new child regions in the META region and the master is informed that a split has taken place so that it can assign the children to region servers. Should the split message be lost, the master will discover the split has occurred since it periodically scans the META regions for unassigned regions.
Once the parent region is closed, read and write requests for the region are suspended. The client has a mechanism for detecting a region split and will wait and retry the request when the new children are on-line.
When a compaction is triggered in a child, the data from the parent is copied to the child. When both children have performed a compaction, the parent region is garbage collected.
HBase Client
The HBase client is responsible for finding H!RegionServers that are serving the particular row range of interest. On instantiation, the HBase client communicates with the H!BaseMaster to find the location of the ROOT region. This is the only communication between the client and the master.
Once the ROOT region is located, the client contacts that region server and scans the ROOT region to find the META region that will contain the location of the user region that contains the desired row range. It then contacts the region server that is serving that META region and scans that META region to determine the location of the user region.
After locating the user region, the client contacts the region server serving that region and issues the read or write request.
This information is cached in the client so that subsequent requests need not go through this process.
Should a region be reassigned either by the master for load balancing or because a region server has died, the client will rescan the META table to determine the new location of the user region. If the META region has been reassigned, the client will rescan the ROOT region to determine the new location of the META region. If the ROOT region has been reassigned, the client will contact the master to determine the new ROOT region location and will locate the user region by repeating the original process described above.
HBase介绍(3)---框架结构及流程的更多相关文章
- HBase之Table.put客户端流程(续)
上篇博文中已经谈到,有两个流程没有讲到.一个是MetaTableAccessor.getRegionLocations,另外一个是ConnectionImplementation.cacheLocat ...
- HBase之Table.put客户端流程
首先,让我们从HTable.put方法开始.由于这一节有很多方法只是简单的参数传递,我就简单略过,但是,关键的方法我还是会截图讲解,所以希望大家尽可能对照源码进行流程分析.另外,在这一节,我单单介绍p ...
- HBase(一)——HBase介绍
HBase介绍 1.关系型数据库与非关系型数据库 (1)关系型数据库 关系型数据库最典型的数据机构是表,由二维表及其之间的联系所组成的一个数据组织 优点: 1.易于维护:都是使用表结构,格 ...
- HBase介绍及简易安装(转)
HBase介绍及简易安装(转) HBase简介 HBase是Apache Hadoop的数据库,能够对大型数据提供随机.实时的读写访问,是Google的BigTable的开源实现.HBase的目标是存 ...
- Hadoop生态圈-hbase介绍-完全分布式搭建
Hadoop生态圈-hbase介绍-完全分布式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop生态圈-hbase介绍-伪分布式安装
Hadoop生态圈-hbase介绍-伪分布式安装 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HBase简介 HBase是一个分布式的,持久的,强一致性的存储系统,具有近似最 ...
- HBase介绍、安装与应用案例
搭建环境 部署节点操作系统为CentOS,防火墙和SElinux禁用,创建了一个shiyanlou用户并在系统根目录下创建/app目录,用于存放 Hadoop等组件运行包.因为该目录用于安装hadoo ...
- HBase二级索引、读写流程
HBase二级索引.读写流程 一.HBse二级索引方案 1.1 基于Coprocessor方案 1.2 Phoenix二级索引特点 1.3 Phoenix 二级索引方案 二.HBase读写流程 2.1 ...
- HBase读写数据的详细流程及ROOT表/META表介绍
一.HBase读数据流程 1.Client访问Zookeeper,从ZK获取-ROOT-表的位置信息,通过访问-ROOT-表获取.META.表的位置,然后确定数据所在的HRegion位置: 2.Cli ...
随机推荐
- 读《分布式一致性原理》CURATOR客户端3
分布式锁 在分布式环境中,为了保证数据的一致性,经常在程序运行的某个运行点.需要进行同步控制. package master; import java.text.SimpleDateFormat; i ...
- Hibernate多对多关联映射的HQL中的in条件查询问题
群里有朋友求解一个问题,高分求一条HQL多对多查询语句 . 问题描述见 http://topic.csdn.net/u/20090621/16/4eac6fe0-bf3e-422e-a697-f758 ...
- Proxmox 安装 dsm 黑群 备忘
备忘:Proxmox 虚拟机使用 E1000网卡(用Virlo找不到引导),直通数据硬盘 . 使用的引导文件是 DS918+_6.21-23824-1.04b.img 虚拟机启动使用第三项EX ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 13—Clustering 聚类
Lecture 13 聚类 Clustering 13.1 无监督学习简介 Unsupervised Learning Introduction 现在开始学习第一个无监督学习算法:聚类.我们的数据没 ...
- 中文分词工具jieba中的词性类型
jieba为自然语言语言中常用工具包,jieba具有对分词的词性进行标注的功能,词性类别如下: Ag 形语素 形容词性语素.形容词代码为 a,语素代码g前面置以A. a 形容词 取英语形容词 adje ...
- Servlet小案例总结
亮点: 没有使用任何框架,视图层和业务层使用Servlet技术进行交互,持久层用java的jdbc工具类进行数据交互 较为底层,比较基础的工具类比较多,比如: BeanFactory工具类使用dom4 ...
- eclipse插件jd-eclipse的使用
https://blog.csdn.net/u013215289/article/details/51275527
- jQuery代码在移动端不运行
今天写了个html网页发现在iOS系统上边不运行,于是真机连上Sarfari查看报错,于是乎 其实这是由于iOS的安全策略决定的,不允许加载非https的连接 报错:was not allowed t ...
- code1169 传纸条
来自:http://www.cnblogs.com/DSChan/p/4862019.html 题目说找来回两条不相交路径,其实也可以等价为从(1,1)到(n,m)的两条不相交路径. 如果是只找一条, ...
- ajax 整个表单的提交
重点:data: $("#form1").serialize() function setSaveNext() { setSaveData(); var cx = pageInde ...