python爬虫之urllib库(一)
python爬虫之urllib库(一)
urllib库
urllib库是python提供的一种用于操作URL的模块,python2中是urllib和urllib2两个库文件,python3中整合在了urllib一个库中。即在Python中导入和调用方法也发生了改变。
| python2 | python3 |
| import urllib2 | import urllib.request,urllib.request |
| import urllib | import urllib.reqest,urllib.error,urllib.parse |
| import parse | import urllib.parse |
| urllib2.urlopen | urllib.request.urlopen |
| urllib.urlencode | urllib.parse.urlencode |
| urllib.quote | urllib.request.quote |
| cookielib.CookieJar | http.CookieJar |
| urllib2.Request | urllib.request.Request |
使用urllib库快速爬取网页
使用urllib库需要导入urllib库中对应的模块。
import urllib.request
导入对应模块以后,使用模块中的urlopen()方法打开并爬取网页。例如,爬取百度首页(http://www.baidu.com),并保存在变量file中。
file = urllib.request.urlopen(‘http://www.baidu.com’)
使用print(file)查看一下变量file中保存的内容,查看结果为:<http.client.HTTPResponse object at 0x0000000002DCBB38>。由此看出,urlopen()方法爬取网页返回的结果是一个HTTP响应对象,读取对象中的内容需要其他方式。
读取内容的三种方式及其用法:
- file.read()读取文件的全部内容,read()方法读取的内容赋值给一个字符串变量。
- file.readlines()读取文件的全部内容,readlines()方法读取的内容赋值给一个列表变量。
- file.readline()读取文件的一行内容。
data = file.read() # 所有内容赋值给字符串
print(data)
data_lines = file.readlines() # 所有内容赋值给列表
print(data_lines)
data_line = file.readline() # 单行内容
print(data_line)
data_line_next = file.readline()
print(data_line_next) # 读取下一行
成功爬取了一个网页以后,将网页保存在本地需要使用文件读写操作。文件读写的具有两种写法:
法一:
fhandle = open('D:/Spider/test/baidu.html', 'wb')
fhandle.write(data)
fhandle.close()
法二:
with open('D:/Spider/test/baidu.html', 'wb') as fhandle:
fhandle.write(data)
两种写法都是先使用open()方法按照文件目录D:/Spider/test/ 找到并打开名为baidu.html的文件,文件操作模式为'wb',表示bytes类型数据写模式,然后使用write()方法写入。区别在于with方法在数据写入以后会自动关闭文件,而法一需要调用close()方法关闭文件。
注意一个问题:urlopen()返回的HTTP响应对象通过head()读取以后,可以看到b‘ ’形式的字符串,此类型数据为bytes类型,对应文件写入的中'wb',‘rb’等。我们知道python中,bytes类型数据是适合用于数据的传输和存储,而如果bytes类型数据需要处理,则需要转化为str类型数据。
str类型与bytes类型之间的数据转换方式:
- str类型数据转化为bytes类型数据:编码,str.encode('utf-8'),其中utf-8为统一码,是一种编码格式。
- bytes类型数据转化为str类型数据:解码,bytes.decode('utf-8')。
import urllib.request
file = urllib.request.urlopen('http://www.baidu.com')
data = file.read().decode() # decode()转bytes为str
with open('D:/Spider/test/baidu.html', 'w') as fhandle: # 以str类型写入文件
fhandle.write(data)
按照文件目录找到baidu.html文件,使用浏览器打开,可以看到本地版百度首页。只是图片暂时没有爬取过来。
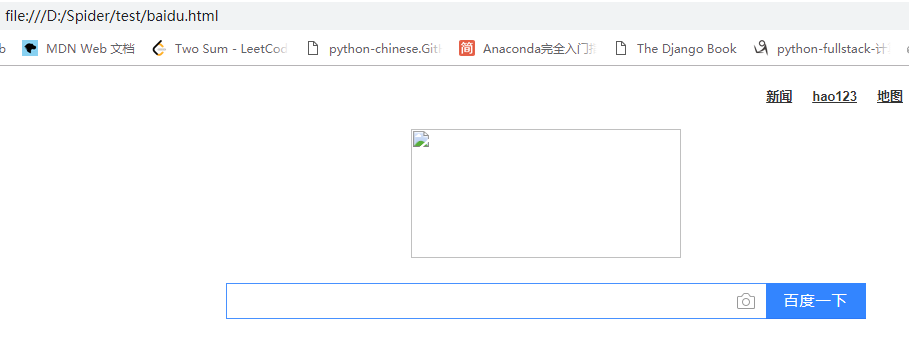
此外,可以使用getcode()方法查看爬取网页时的状态码,geturl()方法获取当时爬取的url地址。
import urllib.request
file = urllib.request.urlopen('http://www.baidu.com')
code = file.getcode()
url = file.geturl()
print(code)
print(url)
除了上面使用的方法,还可以使用urllib.request中urlretrieve()方法直接将对应信息写入本地文件,格式:urllib.request.urlretrieve(url, filename = '本地文件地址')。
import urllib.request url = 'http://www.baidu.com'
filename = urllib.request.urlretrieve(url, filename='D:/Spider/test/baidu-2.html')
按照文件目录找到baidu-2.html文件,使用浏览器打开,可以看到本地版百度首页。此外,使用print(filename)查看,得出('D:/Spider/test/baidu-2.html', <http.client.HTTPMessage object at 0x0000000002DEC2E8>),filename是以元组形式存储了本地文件地址和HTTP响应消息对象。
使用urllib.request.retrieve()方法爬取网页本地化保存会产生一些缓存,可以使用urlcleanup()方法清除缓存。
urllib.request.urlcleanup()
URL编码:一般来说,URL标准只允许一部分ASCII字符在url中使用,像汉字、“:”、“&”等字符是不符合URL标准的,需要进行URL编码。根据传参形式不同,URL编码又分为两种方式。
方式一:使用urllib.request.quote()对单一参数进行编码。
url = 'http://www.baidu.com/s?wd='
search = '编程' # 单一参数
search_url = url + urllib.request.quote(search) # 参数编码,合并url
print(search_url)
方式二:使用urllib.parse.urlencode()对多个参数以字典形式传入进行编码。
import urllib.parse url = 'http://www.baidu.com/s?'
params = {
'wd': '中文',
'key': '张',
'value': '三'
} str_params = urllib.parse.urlencode(params) # 字典传参拼接方式,urlencode()和quote()相似,urlencode对多个参数转义
print(str_params) # wd=%E4%B8%AD%E6%96%87&key=%25E5%25BC%25A0&value=%E4%B8%89
search_url = url + str_params
print(search_url)
使用headers属性模拟浏览器
有时,使用爬虫爬取一些网页的时候,会返回403错误,即禁止访问的错误。是因为网页为了防止恶意采集信息的行为设置了一些反爬措施。对于这部分网页,我们可以尝试设置一些headers信息,模拟成浏览器去访问这些网页。由于urlopen()不支持一些HTTP的高级特性,要添加可以使用opener对象或者Request类来进行。
三种添加headers信息的方式,参阅python爬虫之User-Agent用户信息。
方法一:使用build_opener()修改报头
import urllib.request url= "http://blog.csdn.net/weiwei_pig/article/details/51178226"
headers=("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0") opener = urllib.request.build_opener()
opener.addheaders = [headers]
data=opener.open(url).read()
通过build_opener()方法创建opener对象,而opener对象是由OpenerDirector类实例化来的。

OpenerDirector类的实例属性self.addheaders默认初始值为[('User-agent', client_version)](列表元素为元组型嵌套),外部调用赋值修改opener.addheaders属性。
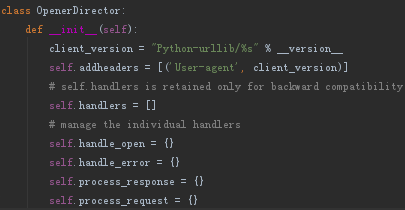
后调用OpenerDirector类的实例方法open()发送HTTP请求。
方法二:使用Request类实例化静态添加报头
import urllib.request url= "http://www.baidu.com"
headers=("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0") req=urllib.request.Request(url, headers= headers)
data=urllib.request.urlopen(req).read()
方法三:使用Request类的实例方法add_headers()动态添加报头(注意源码中add_headers()方法的首字母大写的key才可以取value)
import urllib.request url= "http://www.baidu.com" req=urllib.request.Request(url)
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0')
data=urllib.request.urlopen(req).read()
方法二和方法三都是对Request类的操作,方法二是通过对类的初始化添加headers,方法三是调用类中的实例方法add_header()添加headers,Request类源码:
class Request:
def __init__(self, url, data=None, headers={},
origin_req_host=None, unverifiable=False,
method=None):
self.full_url = url
self.headers = {}
self.unredirected_hdrs = {}
self._data = None
self.data = data
self._tunnel_host = None
for key, value in headers.items():
self.add_header(key, value)
if origin_req_host is None:
origin_req_host = request_host(self)
self.origin_req_host = origin_req_host
self.unverifiable = unverifiable
if method:
self.method = method
@property
def full_url(self):
if self.fragment:
return '{}#{}'.format(self._full_url, self.fragment)
return self._full_url
@full_url.setter
def full_url(self, url):
# unwrap('<URL:type://host/path>') --> 'type://host/path'
self._full_url = unwrap(url)
self._full_url, self.fragment = splittag(self._full_url)
self._parse()
@full_url.deleter
def full_url(self):
self._full_url = None
self.fragment = None
self.selector = ''
@property
def data(self):
return self._data
@data.setter
def data(self, data):
if data != self._data:
self._data = data
# issue 16464
# if we change data we need to remove content-length header
# (cause it's most probably calculated for previous value)
if self.has_header("Content-length"):
self.remove_header("Content-length")
@data.deleter
def data(self):
self.data = None
def _parse(self):
self.type, rest = splittype(self._full_url)
if self.type is None:
raise ValueError("unknown url type: %r" % self.full_url)
self.host, self.selector = splithost(rest)
if self.host:
self.host = unquote(self.host)
def get_method(self):
"""Return a string indicating the HTTP request method."""
default_method = "POST" if self.data is not None else "GET"
return getattr(self, 'method', default_method)
def get_full_url(self):
return self.full_url
def set_proxy(self, host, type):
if self.type == 'https' and not self._tunnel_host:
self._tunnel_host = self.host
else:
self.type= type
self.selector = self.full_url
self.host = host
def has_proxy(self):
return self.selector == self.full_url
def add_header(self, key, val):
# useful for something like authentication
self.headers[key.capitalize()] = val
def add_unredirected_header(self, key, val):
# will not be added to a redirected request
self.unredirected_hdrs[key.capitalize()] = val
def has_header(self, header_name):
return (header_name in self.headers or
header_name in self.unredirected_hdrs)
def get_header(self, header_name, default=None):
return self.headers.get(
header_name,
self.unredirected_hdrs.get(header_name, default))
def remove_header(self, header_name):
self.headers.pop(header_name, None)
self.unredirected_hdrs.pop(header_name, None)
def header_items(self):
hdrs = self.unredirected_hdrs.copy()
hdrs.update(self.headers)
return list(hdrs.items())
考虑:实例属性self.headers初始值为空字典{},能否像方法一,在外部调用时赋值修改实例属性。
import urllib.request url = "http://www.baidu.com"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0"} req = urllib.request.Request(url)
req.headers = headers
data = urllib.request.urlopen(req).read() with open('t.html', 'wb') as fhandle:
fhandle.write(data)
测试验证方法,找到t.html文件使用浏览器打开,按F12切换到DevTools-Network选项,刷新页面,出现
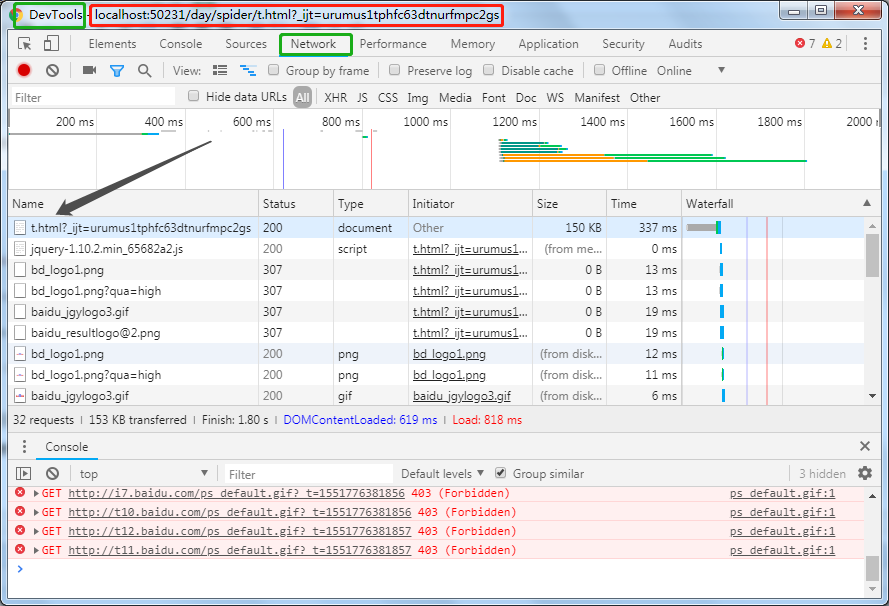
点击黑色箭头所指列表项的任意一下,右侧出现
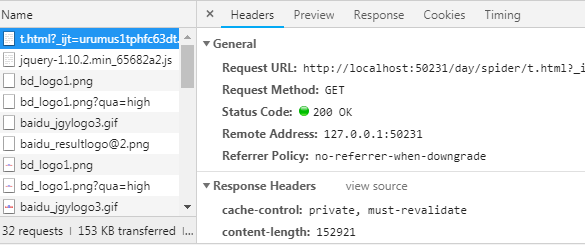
下拉找到Request Headers,展开找到User-Agent项,对照上述代码User-Agent信息验证可以使用外部调用实例属性修改。
上述过程反过来,则为手动抓包,获取User-Agent信息了。
python爬虫之urllib库(一)的更多相关文章
- python爬虫之urllib库(三)
python爬虫之urllib库(三) urllib库 访问网页都是通过HTTP协议进行的,而HTTP协议是一种无状态的协议,即记不住来者何人.举个栗子,天猫上买东西,需要先登录天猫账号进入主页,再去 ...
- python爬虫之urllib库(二)
python爬虫之urllib库(二) urllib库 超时设置 网页长时间无法响应的,系统会判断网页超时,无法打开网页.对于爬虫而言,我们作为网页的访问者,不能一直等着服务器给我们返回错误信息,耗费 ...
- python爬虫之urllib库介绍
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
- python 爬虫之 urllib库
文章更新于:2020-03-02 注:代码来自老师授课用样例. 一.初识 urllib 库 在 python2.x 版本,urllib 与urllib2 是两个库,在 python3.x 版本,二者合 ...
- Python 爬虫之urllib库的使用
urllib库 urllib库是Python中一个最基本的网络请求库.可以模拟浏览器的行为,向指定的服务器发送一个请求,并可以保存服务器返回的数据. urlopen函数: 在Python3的urlli ...
- python爬虫入门urllib库的使用
urllib库的使用,非常简单. import urllib2 response = urllib2.urlopen("http://www.baidu.com") print r ...
- python爬虫之urllib库
请求库 urllib urllib主要分为几个部分 urllib.request 发送请求urllib.error 处理请求过程中出现的异常urllib.parse 处理urlurllib.robot ...
- Python爬虫系列-Urllib库详解
Urllib库详解 Python内置的Http请求库: * urllib.request 请求模块 * urllib.error 异常处理模块 * urllib.parse url解析模块 * url ...
- python爬虫03 Urllib库
Urllib 这可是 python 内置的库 在 Python 这个内置的 Urllib 库中 有这么 4 个模块 request request模块是我们用的比较多的 就是用它来发起请求 所以我 ...
随机推荐
- sql查询层级分类
先上个效果图吧 CTE递归查询里面用了一些小的技巧,查询出结果以后在前端用表格展示出来,层级视觉效果还是很明显的 with tree as(select [ID],[Name],[Address],[ ...
- 'for' loop initial declarations are only allo
linux系统下的c编程与windows有所不同,如果你在用gcc编译代码的时候提示‘for’ loop initial declarations are only allowed in C99 mo ...
- 如何设置才能远程登录Mysql数据库
可以在一台机器上访问另一台机器的MySQL,但是需要一些设置. 进入MySQL后,输入以下命令: GRANT ALL PRIVILEGES ON *.* TO 'tigase'@'%' IDENTIF ...
- .NET基础 (04)基础类型和语法
基础类型和语法1 .NET中所有内建类型的基类是什么2 System.Object中包含哪些方法,哪些是虚方法3 值类型和引用类型的区别4 简述装箱和拆箱原理5 C#中是否有全局变量6 struct和 ...
- 编写高质量代码改善C#程序的157个建议——建议154:不要过度设计,在敏捷中体会重构的乐趣
建议154:不要过度设计,在敏捷中体会重构的乐趣 有时候,我们不得不随时更改软件的设计: 如果项目是针对某个大型机构的,不同级别的软件使用者,会提出不同的需求,或者随着关键岗位人员的更替,需求也会随个 ...
- 我的CSS3学习笔记
1.元字符使用: []: 全部可选项 ||:并列 |:多选一 ?: 0个或者一个 *:0个或者多个 {}: 范围 2.CSS3属性选择器: E[attr]:存在attr属性即可: E[attr=val ...
- Mac开发者常用的工具
http://www.oschina.net/news/53946/mac-dev-tools
- VS 和Visual Assist X快捷键(转)
Visual Assist X 最有用的快捷键 1.Alt + G: 在定义与声明之间互跳. 2.Alt + O: 在.h与.cpp之间互跳.(O是字母O,不是数字零) 3.Alt + Shift + ...
- java学习(二)运算符
一.运算符 赋值运算符:= += -= *= /= %= 算术运算符:+ - * / % ++ -- int x = 3; int y = 4 int c = x*1.0 ...
- Android-AndroidStudio Run 'app'安装APK到设备的过程
1.AndroidStudio 点击Run ‘app’. 2.点击Run ‘app’就会将所有.class文件用SDK工具集处理成.dex, 用SDK工具集将图片/资源/布局文件/AndroidMan ...