Solr学习笔记(1) —— Solr概述&Solr的安装
一、概述
使用Solr实现电商网站中商品信息搜索功能,可以根据关键字、分类、价格搜索商品信息,也可以根据价格进行排序。
1.1 实现方法
在一些大型门户网站、电子商务网站等都需要站内搜索功能,使用传统的数据库查询方式实现搜索无法满足一些高级的搜索需求,比如:搜索速度要快、搜索结果按相关度排序、搜索内容格式不固定等,这里就需要使用全文检索技术实现搜索功能。
使用Lucene实现:单独使用Lucene实现站内搜索需要开发的工作量较大,主要表现在:索引维护、索引性能优化、搜索性能优化等,因此不建议采用。
使用solr实现:基于Solr实现站内搜索扩展性较好并且可以减少程序员的工作量,因为Solr提供了较为完备的搜索引擎解决方案,因此在门户、论坛等系统中常用此方案。
1.2 什么是solr
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引 。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
1.3 Solr与Lucene的区别
Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,Lucene提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索引擎。
Solr的目标是打造一款企业级的搜索引擎系统,它是一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。
二、Solr安装及配置
2.1 Solr的下载
Solr官方网站:http://lucene.apache.org/solr/
2.2 Solr的文件夹结构
将solr-4.10.3.zip解压:
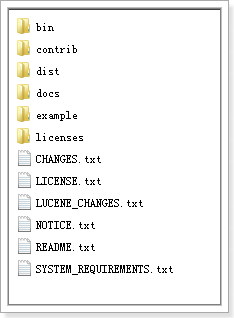
bin:solr的运行脚本
contrib:solr的一些贡献软件/插件,用于增强solr的功能。
dist:该目录包含build过程中产生的war和jar文件,以及相关的依赖文件。
docs:solr的API文档
example:solr工程的例子目录:
- example/solr:该目录是一个包含了默认配置信息的Solr的Core目录。
example/multicore:该目录包含了在Solr的multicore中设置的多个Core目录。
example/webapps:该目录中包括一个solr.war,该war可作为solr的运行实例工程。
- licenses:solr相关的一些许可信息
2.3 运行环境
solr 需要运行在一个Servlet容器中,Solr4.10.3要求jdk使用1.7以上,Solr默认提供Jetty(java写的Servlet容器),本教程使用Tocmat作为Servlet容器。
2.4 Solr整合tomcat
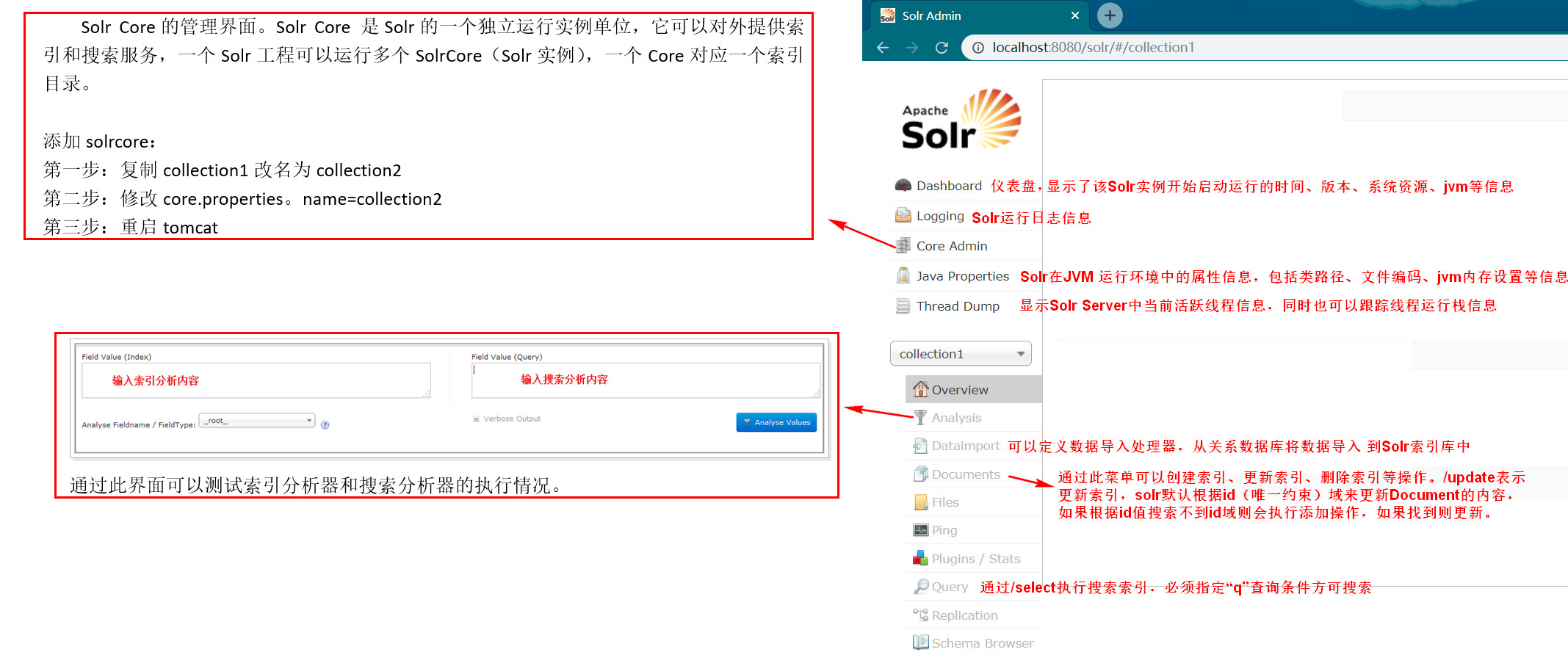
【Solr Home与SolrCore】
创建一个SolrHome目录,SolrHome是Solr运行的主目录,目录中包括了运行Solr实例所有的配置文件和数据文件,Solr实例就是SolrCore,一个SolrHome可以包括多个SolrCore(Solr实例),每个SolrCore提供单独的搜索和索引服务。
example\solr是一个solr home目录结构,如下:

上图中“collection1”是一个SolrCore(Solr实例)目录 ,目录内容如下所示:

说明:
- collection1:叫做一个Solr运行实例SolrCore,SolrCore名称不固定,一个solr运行实例对外单独提供索引和搜索接口。
- solrHome中可以创建多个solr运行实例SolrCore。
- 一个solr的运行实例对应一个索引目录。
- conf是SolrCore的配置文件目录 。
- data目录存放索引文件需要创建
【整合步骤】
第一步:把\solr-4.10.3\dist\solr-4.10.3.war复制到tomcat 的webapp目录下,改名为solr.war。
第二步:solr.war解压。使用压缩工具解压或者启动tomcat自动解压。解压之后删除solr.war
第三步:把\solr-4.10.3\example\lib\ext目录下的所有的jar包添加到solr工程中
第四步:配置solrHome和solrCore
1)创建一个solrhome(存放solr所有配置文件的一个文件夹)。\solr-4.10.3\example\solr目录就是一个标准的solrhome。
2)把\solr-4.10.3\example\solr文件夹复制到D:\temp路径下,改名为solrhome,改名不是必须的,是为了便于理解。
3)在solrhome下有一个文件夹叫做collection1这就是一个solrcore。就是一个solr的实例。一个solrcore相当于mysql中一个数据库。Solrcore之间是相互隔离。
- 在solrcore中有一个文件夹叫做conf,包含了索引solr实例的配置信息。
- 在conf文件夹下有一个solrconfig.xml。配置实例的相关信息。如果使用默认配置可以不用做任何修改
<!-- solr服务依赖的扩展包,默认的路径是collection1\lib文件夹,如果没有就创建一个 -->
<lib dir="${solr.install.dir:../../..}/contrib/extraction/lib" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../..}/dist/" regex="solr-cell-\d.*\.jar" /> <lib dir="${solr.install.dir:../../..}/contrib/clustering/lib/" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../..}/dist/" regex="solr-clustering-\d.*\.jar" /> <lib dir="${solr.install.dir:../../..}/contrib/langid/lib/" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../..}/dist/" regex="solr-langid-\d.*\.jar" /> <!-- 配置了索引库的存放路径。默认路径是collection1\data文件夹,如果没有data文件夹,会自动创建。-->
<dataDir>${solr.data.dir:}</dataDir>
<!-- name="/select":查询时使用的URL -->
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
<int name="rows">10</int>
<str name="df">text</str>
</lst>
</requestHandler> <!-- name="/update":维护索引时使用的URL -->
<requestHandler name="/update" class="solr.UpdateRequestHandler">
<!-- See below for information on defining
updateRequestProcessorChains that can be used by name
on each Update Request
-->
<!--
<lst name="defaults">
<str name="update.chain">dedupe</str>
</lst>
-->
</requestHandler>
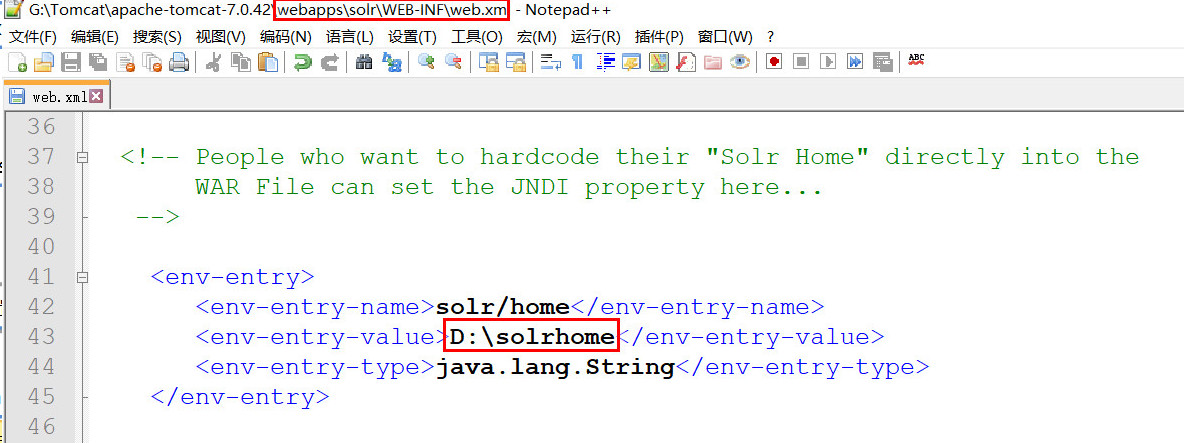
第五步:告诉solr服务器配置文件也就是solrHome的位置。修改solr项目的web.xml。
第六步:启动tomcat
第七步:访问http://localhost:8080/solr/,进入solr后台管理
2.5 配置中文分析器(IKAnalyzer)
第一步:把IKAnalyzer2012FF_u1.jar添加到solr/WEB-INF/lib目录下。
第二步:复制IKAnalyzer的配置文件和自定义词典和停用词词典到solr的classpath下。

第三步:修改 Solrhome 的 schema.xml 文件,配置一个 FieldType,使用 IKAnalyzer
<!-- IKAnalyzer-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
第四步:定义field,指定field的type属性为text_ik
<!--IKAnalyzer Field-->
<field name="title_ik" type="text_ik" indexed="true" stored="true" />
<field name="content_ik" type="text_ik" indexed="true" stored="false" multiValued="true"/>
第五步:重启tomcat
测试:

2.6 配置域
域相当于数据库的表字段,用户存放数据,因此用户根据业务需要去定义相关的Field(域),一般来说,每一种对应着一种数据,用户对同一种数据进行相同的操作。配置域需要修改solrhome的schema.xml 文件。schema.xml,在SolrCore的conf目录下,它是Solr数据表配置文件,它定义了加入索引的数据的数据类型的。主要包括FieldTypes、Fields和其他的一些缺省设置。
【FieldType域类型定义】
<!--“text_general”是Solr默认提供的FieldType,通过它说明FieldType定义的内容。
FieldType子结点包括:name,class,positionIncrementGap等一些参数:
name:是这个FieldType的名称
class:是Solr提供的包solr.TextField,solr.TextField 允许用户通过分析器来定制索引和
查询,分析器包括一个分词器(tokenizer)和多个过滤器(filter)
positionIncrementGap:可选属性,定义在同一个文档中此类型数据的空白间隔,避免短语匹配错误,
此值相当于Lucene的短语查询设置slop值,根据经验设置为100。
-->
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<!--在FieldType定义的时候最重要的就是定义这个类型的数据在建立索引和进行查询的时候要使用的分析器analyzer,
包括分词和过滤 -->
<!--索引分析器-->
<analyzer type="index">
<!--solr.StandardTokenizerFactory标准分词器-->
<tokenizer class="solr.StandardTokenizerFactory"/>
<!--solr.StopFilterFactory停用词过滤器-->
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<!--LowerCaseFilterFactory小写过滤器-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<!--搜索分析器-->
<analyzer type="query">
<!--StandardTokenizerFactory标准分词器-->
<tokenizer class="solr.StandardTokenizerFactory"/>
<!--solr.StopFilterFactory停用词过滤器-->
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!--SynonymFilterFactory同义词过滤器-->
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
【Field定义】
<!--在fields结点内定义具体的Field,filed定义包括name,type(为之前定义过的各种FieldType),indexed(是否被索引),
stored(是否被储存),multiValued(是否存储多个值)等属性。-->
<!--multiValued:该Field如果要存储多个值时设置为true,solr允许一个Field存储多个值,
比如存储一个用户的好友id(多个),商品的图片(多个,大图和小图),通过使用solr查询要看出返回给客户端是数组-->
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="sku" type="text_en_splitting_tight" indexed="true" stored="true" omitNorms="true"/>
<field name="name" type="text_general" indexed="true" stored="true"/>
<field name="manu" type="text_general" indexed="true" stored="true" omitNorms="true"/>
<field name="cat" type="string" indexed="true" stored="true" multiValued="true"/>
【uniqueKey】——Solr中默认定义唯一主键key为id域
<!--Solr在删除、更新索引时使用id域进行判断,也可以自定义唯一主键。
注意在创建索引时必须指定唯一约束-->
<uniqueKey>id</uniqueKey>
【copyField复制域】——可以将多个Field复制到一个Field中,以便进行统一的检索
比如,输入关键字(product_keywords)搜索商品名称(product_name)和商品描述(product_description)
定义product_keywords、product_name、product_description的域:

根据关键字只搜索product_keywords域的内容就相当于搜索product_name和product_description,将product_name和product_description复制到product_keywords中,如下:

【dynamicField】
动态字段就是不用指定具体的名称,只要定义字段名称的规则,例如定义一个 dynamicField,name 为*_i,定义它的type为text,那么在使用这个字段的时候,任何以_i结尾的字段都被认为是符合这个定义的,例如:name_i,gender_i,school_i等。
自定义Field名为:product_title_t,“product_title_t”和scheam.xml中的dynamicField规则匹配成功,如下:

“product_title_t”是以“_t”结尾。
例如,我们需要实现如下效果:

就需要在Schema.xml中添加配置:
<dynamicField name="item_spec_*" type="string" indexed="true" stored="true" />
2.7 设置业务系统Field
如果不使用Solr提供的Field可以针对具体的业务需要自定义一套Field,如下是商品信息Field:
<!--product-->
<field name="product_name" type="text_ik" indexed="true" stored="true"/>
<field name="product_price" type="float" indexed="true" stored="true"/>
<field name="product_description" type="text_ik" indexed="true" stored="false" />
<field name="product_picture" type="string" indexed="false" stored="true" />
<field name="product_catalog_name" type="string" indexed="true" stored="true" /> <field name="product_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<copyField source="product_name" dest="product_keywords"/>
<copyField source="product_description" dest="product_keywords"/>
Solr学习笔记(1) —— Solr概述&Solr的安装的更多相关文章
- Solr学习笔记之3、Solr dataimport - 从SQLServer导入数据建立索引
Solr学习笔记之3.Solr导入SQLServer数据建立索引 一.下载MSSQLServer的JDBC驱动 下载:Microsoft JDBC Driver 4.0 for SQL Server ...
- Solr学习笔记之4、Solr配置文件简介
Solr学习笔记之4.Solr配置文件简介 摘自<Solr in Action>. 1. solr.xml – Defines one or more cores per Solr ser ...
- solr学习笔记-linux下配置solr(转)
本文地址: http://zhoujianghai.iteye.com/blog/1540176 首先介绍一下solr: Apache Solr (读音: SOLer) 是一个开源.高性能.采用Jav ...
- Solr学习笔记之6、Solr学习资源
一.官方资源 1.官网:http://lucene.apache.org/solr/ 2.wiki:http://wiki.apache.org/solr/FrontPage 3.solr中文网:ht ...
- Solr学习笔记之2、集成IK中文分词器
Solr学习笔记之2.集成IK中文分词器 一.下载IK中文分词器 IK中文分词器 此文IK版本:IK Analyer 2012-FF hotfix 1 完整分发包 二.在Solr中集成IK中文分词器 ...
- Solr学习笔记之1、环境搭建
Solr学习笔记之1.环境搭建 一.下载相关安装包 1.JDK 2.Tomcat 3.Solr 此文所用软件包版本如下: 操作系统:Win7 64位 JDK:jdk-7u25-windows-i586 ...
- Solr学习笔记之5、Component(组件)与Handler(处理器)学习
Solr学习笔记之5.Component(组件)与Handler(处理器)学习 一.搜索篇 拼写检查(spellCheck) 作用:用来检查用户输入的检索内容是否存在,如果不存在则给它提示出相近或相似 ...
- solr学习笔记-入门
solr学习笔记 1.安装前准备 solr依赖java 8 运行环境,所以我们先安装java.如果没有java环境无法启动solr服务,并且会看到如下提示: [root@localhost solr- ...
- OGG学习笔记01-基础概述
OGG学习笔记01-基础概述 OGG(Oracle Golden Gate),最近几年在数据同步.容灾领域特别火,甚至比Oracle自己的原生产品DataGuard还要风光,主要是因为其跨平台.跨数据 ...
- X-Cart 学习笔记(一)了解和安装X-Cart
目录 X-Cart 学习笔记(一)了解和安装X-Cart X-Cart 学习笔记(二)X-Cart框架1 X-Cart 学习笔记(三)X-Cart框架2 X-Cart 学习笔记(四)常见操作 一.了解 ...
随机推荐
- leetcode645
vector<int> findErrorNums(vector<int>& nums) { ; int S[N]; int n = nums.size(); ; i ...
- Excel向数据库插入数据(执行一次只需连接一次)-batch简单使用
由于前端时间向数据库插入excel中的数据时,每插入一条数据,就得连接一次数据库:后来发现这种做法不好,如果excel中有很多条数据,就得连接很多次数据库,这样就很浪费资源而且不安全,有时数据库也会报 ...
- Android上 dip、dp、px、sp等单位说明
dip: device independent pixels(设备独立像素). 不同设备有不同的显示效果,这个和设备硬件有关,一般我们为了支持WVGA.HVGA和QVGA 推荐使用这个,不依赖像素. ...
- LINUX 使用DBCA创建ORACLE数据库
- 第3章 springboot接口返回json 3-2 Jackson的基本演绎法
@JsonIgnore private String password; @JsonFormat(pattern="yyyy-MM-dd hh:mm:ss a",locale=&q ...
- Emgu cv3.0.0 图像收集
using System;using System.Collections.Generic;using System.ComponentModel;using System.Data;using Sy ...
- Luogu 4281 [AHOI2008]紧急集合 / 聚会
BZOJ 1832 写起来很放松的题. 首先发现三个点在树上一共只有$3$种形态,大概长这样: 这种情况下显然走到三个点的$lca$最优. 这种情况下走到中间那个点最优. 这种情况下走到$2$最优. ...
- Luogu 4777 【模板】扩展中国剩余定理(EXCRT)
复习模板. 两两合并同余方程 $x\equiv C_{1} \ (Mod\ P_{1})$ $x\equiv C_{2} \ (Mod\ P_{2})$ 把它写成不定方程的形式: $x = C_{1} ...
- python 根据字典中的key,value进行排序
#coding=utf-8 import requests,json,collections,base64,datetime def sort(datas): data=json.dumps(data ...
- 【转】C#对XML文件的各种操作实现方法
[转]C#对XML文件的各种操作实现方法 原文:http://www.jb51.net/article/35568.htm XML:Extensible Markup Language(可扩展标记语言 ...