【python】-- 装饰器、迭代器、生成器
装饰器
装饰器本质是函数,是用来装饰其他函数,顾名思义就是,为其他的函数添加附件功能的。
一、装饰器原则:
不能修改被装饰函数的源代码
不能修改被装饰函数的调用方式
def logging():
print("logging...") #正确写法,没有修改源码
def test1():
pass #错误写法,不能修改源码
def test1():
pass
logging() # 调用方式,也不能被修改
test1()
二、装饰器知识:
- 函数即"变量"
- 高阶函数+嵌套函数 =》装饰器
1、函数即”变量“
python的内存机制,看如下代码:
#变量
x = 1
#函数
def test():
pass
在内存图中是这样表示的:
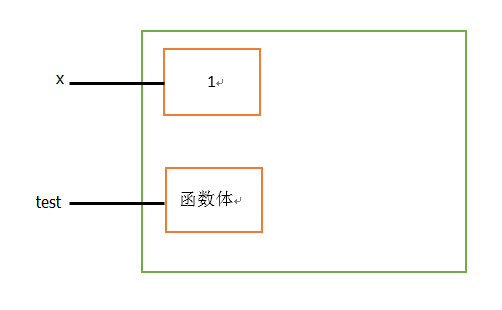
x、test 是变量名,保存在栈内存中,1、函数体 保存在堆内存中
2、高阶函数+嵌套函数 =》装饰器
装饰器实现过程:
第一步:原始代码
def home():
print("---首页----") def TV():
print("----TV----") def music()
print("---music-----")
第二步:想给部分模块加个登陆认证
user_status = False #用户登录了就把这个改成True def login():
_username = "ABC" #假装这是DB里存的用户信息
_password = "" #假装这是DB里存的用户信息
global user_status if user_status == False:
username = input("user:")
password = input("pasword:") if username == _username and password == _password:
print("welcome login....")
user_status = True
else:
print("wrong username or password!")
else:
print("用户已登录,验证通过...") def home():
print("---首页----") def TV():
login() #执行前加上验证
print("----TV----") def music():
print("----music----")
虽然这样实现了认证功能,但是修改了被装饰函数的源代码,违背了装饰器的原则”不能修改被装饰函数的源代码“
第三步:代码改进,使用高阶函数理念,把函数名当参数传递给认证函数login,这样可以不修改被装饰函数源代码的情况下完成登陆认证
user_status = False #用户登录了就把这个改成True def login(func):
_username = "ABC" #假装这是DB里存的用户信息
_password = "" #假装这是DB里存的用户信息
global user_status if user_status == False:
username = input("user:")
password = input("pasword:") if username == _username and password == _password:
print("welcome login....")
user_status = True
else:
print("wrong username or password!")
if user_status == True:
print("用户已登录,验证通过...")
func() #只要验证通过了,就调用相应功能 def home():
print("---首页----") def TV():
print("----TV----") def music():
print("----music----") login(TV) #需要验证就调用 login,把需要验证的功能 当做一个参数传给login
虽然这样可以不修改被装饰函数源代码的情况下完成登陆认证,但是违背了装饰器原则”修改了被装饰函数的调用方式“,本来被装饰函数只需要TV()就可调用,现在变成了login(TV)
第四步:代码改进,使用匿名函数理念,将login(TV)变成 TV = login(TV) ,将函数当成值,赋值给变量名TV,跟关键字def 重新定义了TV是一样的效果,不过这样还有一个问题, TV = login(TV)这个赋值过程中,就把函数TV给调用了,用户自己还没有调用,就自己自动调用肯定是不对的,这个时候需要用到嵌套函数的理念了,在认证函数login里面的再定义一个新函数login_inner,在login函数return(返回)login_inner函数名(对是return login_inner, 不是return login_inner(), 因为return 函数名 返回的是函数在栈内容的内存地址,return 函数名+() 返回的是该函数的执行结果) 这样在TV = login(TV)赋值的时候,TV赋值的就不是 login(TV)的执行结果了,赋值的值是login_inner的内存地址,等用户再调用的时候 就是TV(),这样就没有改变被装饰函数的调用方式了。
user_status = False #用户登录了就把这个改成True def login(func):
#在login 里面增加一个嵌套函数,保证tv = login(tv)的时候 不会自己自动调用 tv函数
def login_inner():
_username = "ABC" #假装这是DB里存的用户信息
_password = "" #假装这是DB里存的用户信息
global user_status if user_status == False:
username = input("user:")
password = input("pasword:") if username == _username and password == _password:
print("welcome login....")
user_status = True
else:
print("wrong username or password!")
if user_status == True:
print("用户已登录,验证通过...")
func() #只要验证通过了,就调用相应功能 return login_inner # return 函数名 返回的是函数在栈内容的内存地址,return 函数名+() 返回的是该函数的执行结果 def home():
print("---首页----") def TV():
print("----TV----") def music():
print("----music----") home()
#login(TV) #改成下面的方式,这样就不会改变调用方式了
TV = login(TV)
TV()
每次使用装饰器都这么麻烦?需要使用匿名函数重新赋值再调用?
第五步:其实可以把TV =login(TV),的赋值过程简化成在被装饰函数前@login 就好了,如下列代码:
user_status = False #用户登录了就把这个改成True def login(func):
#在login 里面增加一个嵌套函数,保证tv = login(tv)的时候 不会自己自动调用 tv函数
def login_inner():
_username = "ABC" #假装这是DB里存的用户信息
_password = "" #假装这是DB里存的用户信息
global user_status if user_status == False:
username = input("user:")
password = input("pasword:") if username == _username and password == _password:
print("welcome login....")
user_status = True
else:
print("wrong username or password!")
if user_status == True:
print("用户已登录,验证通过...")
func() #只要验证通过了,就调用相应功能 return login_inner # return 函数名 返回的是函数在栈内容的内存地址,return 函数名+() 返回的是该函数的执行结果 def home():
print("---首页----") @login
def TV():
print("----TV----") @login
def music():
print("----music----")
装饰器装饰没有参数的函数:
import time #定义装饰器函数
def timmer(func): # 把test1这个函数名作为参数传递进来 func=test1
#定义装饰器中的内置函数
def deco():
start_time = time.time()
func() #相当于运行test1()
stop_time = time.time()
print("the func run time is %s"%(stop_time-start_time)) return deco #装饰test1函数
@timmer # 相当于test1 = timmer(test1)
def test1():
time.sleep(3)
print("in the test1") #直接执行test1函数
test1() #输出
in the test1
the func run time is 3.0002999305725098
装饰器装饰带有参数的函数:
import time def timmer(func): #timmer(test1) func=test1
# 因为之前返回的是这个嵌套数的内存地址,如果这个嵌套函数不传入参数#的话,里面的func,就是被装饰函数本身就没有参数,这样就会报错
def deco(*args,**kwargs): #传入非固定参数
start_time = time.time()
func(*args,**kwargs) #传入非固定参数
stop_time = time.time()
print("the func run time is %s"%(stop_time-start_time)) return deco #不带参数
@timmer # 相当于test1 = timmer(test1)
def test1():
time.sleep(3)
print("in the test1") #带参数
@timmer
def test2(name,age):
print("name:%s,age:%s"%(name,age))
#调用
test1()
test2("zhangqigao",22) #输出
#test1
in the test1
the func run time is 3.0010883808135986
#test2
name:zhangqigao,age:22
the func run time is 0.0 #test2
装饰器装饰有返回值的函数:
def timmer(func): #timmer(test1) func=test1
def deco(*args,**kwargs):
res = func(*args,**kwargs) #这边传入函数结果赋给res
return res # 返回res
return deco @timmer
def test1(): # test1 = timmer(test1)
print("in the test1")
return "from the test1" #执行函数test1有返回值 res = test1()
print(res) #输出
in the test1
from the test1
装饰器本身带有参数:
#本地验证
user,passwd = "zhangqigao","abc123" def auth(auth_type): #传递装饰器的参数
print("auth func:",auth_type)
def outer_wrapper(func): # 将被装饰的函数作为参数传递进来
def wrapper(*args,**kwargs): #将被装饰函数的参数传递进来
print("wrapper func args:",*args,**kwargs)
username = input("Username:").strip()
password = input("Password:").strip()
if auth_type == "local":
if user == username and passwd == password:
print("\033[32mUser has passed authentication\033[0m")
res = func(*args,**kwargs)
print("--after authentication")
return res
else:
exit("Invalid username or password")
elif auth_type == "ldap":
pass
return wrapper
return outer_wrapper def index():
print("welcome to index page") @auth(auth_type="local") #带参数装饰器
def home():
print("welcome to home page")
return "from home" @auth(auth_type="ldap") #带参数装饰器
def bbs():
print("welcome to bbs page") index()
home()
bbs()
生成器
我们在使用一组数据时,通常情况下会定义一个列表,然后循环里面的元素,但是你想过没有,如果你只需要使用列表中的1-2个元素,其他的元素用不到,这样就会造成资源的浪费,这样不能很好的合理的利用我们机器的资源,所以如何合理高效的利用这些利用这些资源,并且提高我们程序的运行速度呢?
一、列表生成式
列表[0,1,2,3,4,5,6,7,8,9],需求是把列表中的每个元素加1
a = [0,1,2,3,4,5,6,7,8,9]
for index,i in enumerate(a):
a[index] += 1
print(a) #输出
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
一个更简便的写法:
>>> [ i+1 for i in range(10)]
输出
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
二、生成器
通过列表生成式,直接去创建一个列表。但是收到内存的限制,列表的容量是有限的。如果我们在创建一个包含100万个元素的列表,甚至更多,不仅占用了大量的内存空间,而且如果我们仅仅需要访问前面几个元素时,那后面很大一部分的占用的空间都白白浪费掉了。这个并不是我们所希望看到的。所以就诞生了一个新的名词叫生成器:generator。
生成器的作用:列表的元素按某种算法推算出来,我们在后续的循环中不断推算出后续的元素,在python中,这种一边循环一边计算的机制,称之为生成器(generator)。
1、创建生成器
>>> m=[i*2 for i in range(10)]
>>> m
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18] #生成一个list
>>> n = (i*2 for i in range(10))
>>> n
<generator object <genexpr> at 0x00000000033A4FC0> #生成一个generator
如果需要访问生成器n中的值,python2是通过next()方法去获得generator的下一个返回值,python3是通过__next__()去获得generator的下一个返回值:
#python 3的访问方式用__next__()
>>> n.__next__()
0
>>> n.__next__()
2
>>> n.__next__()
4
>>> n.__next__()
6
>>> n.__next__()
8
>>> n.__next__() #没有元素时,则会抛出抛出StopIteration的错误
Traceback (most recent call last):
File "<pyshell#4>", line 1, in <module>
n.__next__()
StopIteration #python2的访问方式用next()
>>> n.next() #可以用n.next()
0
>>> next(n) #也可以用next(n)
2
>>> n.next()
4
>>> n.next()
6
>>> n.next()
8
>>> n.next() #没有元素时,则会抛出抛出StopIteration的错误 Traceback (most recent call last):
File "<pyshell#4>", line 1, in <module>
n.next()
StopIteration
①generator保存的是算法,每次调用next方法时,就会计算下一个元素的值,直到计算到最后一个元素,如果没有更多元素,则会抛出StopIteration的错误。
②generator只记住当前位置,它访问不到当前位置元素之前和之后的元素,之前的数据都没有了,只能往后访问元素,不能访问元素之前的元素。
2、用for循环去访问generator中的元素
使用next方法去一个一个访问,不切实际,正确的方法是使用for循环去访问,因为generator也是可迭代对象,代码如下:
>>> res = (i*2 for i in range(3)) #创建一个生成器
>>> res
<generator object <genexpr> at 0x0000000003155C50>
>>> for i in res: #迭代生成器中的元素
print(i) #输出
0
2
4
三、函数生成器
推算比较简单,但是推算的算法比较复杂,用类似列表生成式的for循环无法实现,那怎么办呢?比如下面一个例子,用列表生成式无法实现。
1、斐波那契数列
实现原理:除第一个和第二个数外,任意一个数都可由前两个数相加得到:1, 1, 2, 3, 5, 8, 13, 21, 34, ...,代码如下:
def fib(max):
n,a,b = 0,0,1
while n < max:
print(b)
a , b = b ,a+b
n = n+1 return "----done---" fib(5)
#执行结果
1
1
2
3
5
----done---
虽然根据这种逻辑推算非常类似一个生成器(generator),但是其本质还是函数,下面演示通过关键字yield将函数转换成生成器。
2、用yield函数转换为生成器(generator)
def fib(max):
n,a,b = 0,0,1
while n < max:
yield b #用yield替换print,把fib函数转化成一个生成器
a , b = b ,a+b
n = n+1 return "----done---"
这就是生成器(generator)另外一种定义方法。如果一个函数中包含yield关键字,那么这个函数就不是一个普通的函数,而是一个生成器(generator)
f = fib(5)
print(f) #输出
<generator object fib at 0x0000000000D1B4C0>
注:变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
f = fib(5)
print(f.__next__())
print(f.__next__())
print(f.__next__())
print("我在干别的事情")
print(f.__next__())
print(f.__next__())#访问的是最后一个元素
print(f.__next__()) #没有多余的元素 #输出
1
1
2
-----我在干别的事情-----
3
5
Traceback (most recent call last):
File "D:/PycharmProjects/pyhomework/day4/生成器/fib.py", line 20, in <module>
print(f.__next__())
StopIteration: ----done---
小结:
①访问生成器中的元素,不用是连续的,我可以中间去执行其他程序,向想什么时候执行,可以再回头去执行。
②return在这边作用就是当发生异常时,会打印ruturn后面的值。
四、生成器使用场景
生成器除了能节省资源,还能提高工作效率,如下列例子
1、执行原理
A、第一个__next__方法
def consumer(name):
print("%s 准备吃包子啦!"%name) while True:
baozi = yield print("包子[%s]来了,被[%s]吃了"%(baozi,name)) c = consumer("zhangqigao")
c.__next__() #输出
zhangqigao 准备吃包子啦!
B、再加一个__next__方法
def consumer(name):
print("%s 准备吃包子啦!"%name) while True:
baozi = yield print("包子[%s]来了,被[%s]吃了"%(baozi,name)) c = consumer("zhangqigao")
c.__next__()
c.__next__() #输出
zhangqigao 准备吃包子啦!
包子[None]来了,被[zhangqigao]吃了
A方案没有执行"print("包子[%s]来了,被[%s]吃了"%(baozi,name))",这段代码,接下来我们就来调试一下。
第一步:生成一个生成器

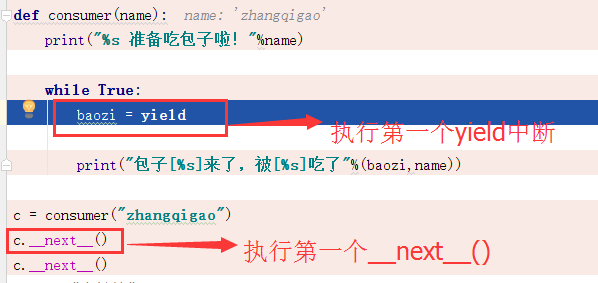
第二步:执行第一个__next__()方法进入函数,执行到yield时中断,把返回值返回给baozi这个变量:
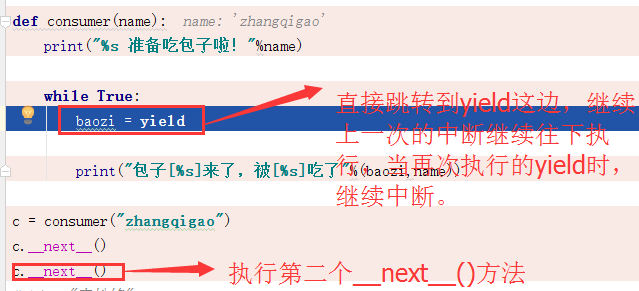
第三步:开始执行下面的程序,也就执行到了第二个__next__()方法,直接跳转到yield这边,继续上一次的中断往下执行,这样就执行了yield下面的程序,当再次执行到yield关键字时,则继续中断,并且把返回值赋给baozi关键字,如果下面没有其他程序,则程序结束。
小结:
- 用yield做生成器,你想把什么返回到外面,你就把yield关键字放在那里。
- yield其实是保留了函数的中断状态,返回当前的值。
- 如果yield没有返回值,就返回一个空值None
二、send()和__next__()方法的区别
def consumer(name):
print("%s 准备吃包子啦!"%name) while True:
baozi = yield print("包子[%s]来了,被[%s]吃了"%(baozi,name)) c = consumer("zhangqigao")
c.__next__() #不使用__next__()方法会报错
b1 = "肉松馅"
c.send(b1) #调用yield,同时给yield传一个值
b2 = "韭菜馅"
c.send(b2) #输出
zhangqigao 准备吃包子啦!
包子[肉松馅]来了,被[zhangqigao]吃了
包子[韭菜馅]来了,被[zhangqigao]吃了
从上面可以看出send()和__next__()方法的区别:
- __next__()只是调用这个yield,也可以说成是唤醒yield,但是不不会给yield传值。
- send()调用这个yield或者说唤醒yield同时,也活给yield传一个值。
- 使用send()函数之前必须使用__next__(),因为先要中断,当第二次调用时,才可传值。
为什么给消费者传值时,必须先执行__next__()方法?
因为如果不执行一个__next__()方法,只是把函数变成一个生成器,你只有__next__()一下,才能走到第一个yield,然后就返回了,调用下一个send()传值时,才会发包子。
三、yield实现并行效果
yield还有一个更强大的功能,就是:单线程实现并发效果。
import time def consumer(name):
print("%s 准备吃包子啦!"%name) while True:
baozi = yield print("包子[%s]来了,被[%s]吃了"%(baozi,name)) def producer(name):
c = consumer("A")
c2 = consumer("B")
c.__next__()
c2.__next__()
print("老子准备吃包子啦!")
for i in range(10):
time.sleep(1)
print("做了一个包子,分两半")
c.send(i)
c2.send(i) producer("zhangqigao")
迭代器
一、可迭代对象
1、for循环数据类型
- 集合数据类型,如:list、tuple、dict、set、str、bytes(字节)等。
- 生成器(generator),包括生成器和带yield的生成器函数。
2、定义
可迭代对象(Iterable):直接用于for循环遍历数据的对象
3、用isinstance()方法判断一个对象是否是Iterable对象
>>> from collections import Iterable
>>> isinstance([],Iterable) #列表
True
>>> isinstance((),Iterable) #元组
True
>>> isinstance({},Iterable) #字典
True
>>> isinstance('abc',Iterable) #字符串
True
>>> isinstance(100,Iterable) #整型
False
注:生成器不但可以作用于for循环,还可以被__next__()函数不断调用,并且返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值而抛出的异常。
二、迭代器
1、定义
迭代器(Iterator):可以用__next__()函数调用并不断的返回下一个值的对象称为迭代器。
2、用isinstance()方法判断一个对象是否是Iterator对象
>>> from collections import Iterator
>>> isinstance((i*2 for i in range(5)),Iterator) #生成器
True
>>> isinstance([],Iterator) #列表
False
>>> isinstance({},Iterator) #字典
False
>>> isinstance('abc',Iterator) #字符串
False
通过上面的例子可以看出,生成器都是IteratorIterableIterator对象。
3、iter()函数
功能:把list、dict、str等Iterable对象变成Iterator对象。
>>> from collections import Iterator
>>> isinstance(iter([]),Iterator)
True
>>> isinstance(iter({}),Iterator)
True
4、为什么list、dict、str等数据类型不是Iterator?
这是因为python的Iterator对象表示的是一个数据流,Iterator对象可以被__next__()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过__next__()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时才会计算。
注:Iterator甚至可以表示一个无限大的数据流,例如:全体自然数。而使用list是永远不可能存储全体自然数的。
小结:
- 凡是可以作用于for循环的对象都是
Iterable类型。 - 凡是作用于__next__()函数的对象都是
Iterator类型,它们表示一个惰性计算的序列。 - 集合数据类型,例如:list、dict、str等,是
Iterable但是不是Iterator - 集合数据类型可以通过
iter()函数获得一个Iterator对象。
【python】-- 装饰器、迭代器、生成器的更多相关文章
- python装饰器,迭代器,生成器,协程
python装饰器[1] 首先先明白以下两点 #嵌套函数 def out1(): def inner1(): print(1234) inner1()#当没有加入inner时out()不会打印输出12 ...
- Python装饰器、生成器、内置函数、json
这周学习了装饰器和生成器,写下博客,记录一下装饰器和生成器相关的内容. 一.装饰器 装饰器,这个器就是函数的意思,连起来,就是装饰函数,装饰器本身也是一个函数,它的作用是用来给其他函数添加新功能,比如 ...
- Python学习---装饰器/迭代器/生成器的学习【all】
Python学习---装饰器的学习1210 Python学习---生成器的学习1210 Python学习---迭代器学习1210
- python笔记3 闭包 装饰器 迭代器 生成器 内置函数 初识递归 列表推导式 字典推导式
闭包 1, 闭包是嵌套在函数中的 2, 闭包是内层函数对外层函数的变量(非全局变量)的引用(改变) 3,闭包需要将其作为一个对象返回,而且必须逐层返回,直至最外层函数的返回值 闭包例子: def a1 ...
- python 装饰器,生成器,迭代器
装饰器 作用:当我们想要增强原来已有函数的功能,但不想(无法)修改原函数,可以使用装饰器解决 使用: 先写一个装饰器,就是一个函数,该函数接受一个函数作为参数,返回一个闭包,而且闭包中执行传递进来的函 ...
- Python中的装饰器,迭代器,生成器
1. 装饰器 装饰器他人的器具,本身可以是任意可调用对象,被装饰者也可以是任意可调用对象. 强调装饰器的原则:1 不修改被装饰对象的源代码 2 不修改被装饰对象的调用方式 装饰器的目标:在遵循1和2的 ...
- python 装饰器、生成器、迭代器
# 装饰器'''由高阶函数(把一个函数名当作实参传递给另一个函数,返回值中包含函数名)和嵌套函数(函数中嵌套函数)组成功能:在不更改原函数的代码和调用方式的前提下添加新的功能装饰器本身就是一个函数.使 ...
- python中的装饰器迭代器生成器
装饰器: 定义:本质是函数(装饰其它函数) 为其它函数添加附加功能 原则: 1 不能修改被装饰函数源代码 2 不修改被装饰函数调用方式 实现装饰器知识储备: 1 函数即‘’变量‘’ 2 高阶函数 ...
- Day4 装饰器——迭代器——生成器
一 装饰器 1.1 函数对象 一 函数是第一类对象,即函数可以当作数据传递 #1 可以被引用 #2 可以当作参数传递 #3 返回值可以是函数 #3 可以当作容器类型的元素 二 利用该特性,优雅的取代多 ...
- day04 装饰器 迭代器&生成器 Json & pickle 数据序列化 内置函数
回顾下上次的内容 转码过程: 先decode 为 Unicode(万国码 ) 然后encode 成需要的格式 3.0 默认是Unicode 不是UTF-8 所以不需要指定 如果非要转为U ...
随机推荐
- java 实体序列化的意义
一.序列化的意义 客户端访问了某个能开启会话功能的资源, web服务器就会创建一个与该客户端对应的HttpSession对象,每个HttpSession对象都要站用一定的内存空间.如果在某一时间段内访 ...
- HUNAN Interesting Integers(爆力枚举)
Undoubtedly you know of the Fibonacci numbers. Starting with F1 = 1 and F2 = 1, every next number is ...
- react-native AsyncStorage 数据持久化方案
1,AsyncStorage介绍 AsyncStorage 是一个简单的.异步的.持久化的 Key-Value 存储系统,它对于 App 来说是全局性的.它用来代替 LocalStorage. 由于它 ...
- 单例模式 - GCD 、兼容ARC和MRC
单例模式 - GCD .兼容ARC和MRC 单例模式的作用: 1,能够保证在程序执行过程.一个类仅仅有一个实例,并且该实例易于供外界訪问 2,从而方便地控制了实例个数,并节约系统资源 单例模式的使用场 ...
- EFFECTIVE JAVA 类和接口
第十六条:复合优先于继承 //这是一个不好的类---执行的结果 addCount = 4(addAll的实现依赖于HashSet的add方法,InstrumentHashSet方法重写了add方法有执 ...
- 乐鑫esp8266的 基于Nonos移植红外线1883,实现遥控器控制
代码地址如下:http://www.demodashi.com/demo/12613.html 一.前言. 距离上篇的8266进阶博文有那么一段时间了,那么本文带来的是基于Nonos的红外线H1838 ...
- 基于Django进行简单的微信开发
代码地址如下:http://www.demodashi.com/demo/11756.html 一.微信公众号的准备: 1. 注册 访问地址:https://mp.weixin.qq.com/ 按照提 ...
- iOS 实现启动屏动画(Swift实现,包含图片适配)
代码地址如下:http://www.demodashi.com/demo/12090.html 准备工作 首先我们需要确定作为宣传的图片的宽高比,这个一般是与 UI 确定的.一般启动屏展示会有上下两部 ...
- 数据文件offline 时oracle 干了那些事?
SQL> oradebug setmypid Statement processed. SQL> oradebug unlimit Statement processed. SQL> ...
- 微软在GitHub上开放源代码
https://github.com/MSOpenTech 点击链接:openFrameworks :https://github.com/openframeworks/openFrameworks ...