Python菜鸟之路:sqlalchemy/paramiko进阶
前言:ORM中的两种创建方式
数据库优先:指的是先创建数据库,包括表和字段的建立,然后根据数据库生成ORM的代码,它是先创建数据库,再创建相关程序代码
代码优先:就是先写代码,然后根据代码去生成数据库结构。
代码优先创建数据库的本质:拿到类-->转换成table对象, 然后根据table对象生成sql语句--> 生成数据库表结构
SQLalchemy联表操作
一对多
# 表结构
class Group(Base): # 一对多的表,组中可能包含多个用户
__tablename__ = 'group'
nid = Column(Integer, primary_key=True, autoincrement=True)
caption = Column(String(32)) class User(Base):
__tablename__ = 'user'
uid = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(32))
gid = Column(Integer, ForeignKey('group.nid'))
# 创建完表之后,建立连接
Session = sessionmaker(bind=engine)
session = Session() 新增Group表数据
session.add_all([
Group(caption='DBA'),
Group(caption='SA'),
]
)
session.commit()
session.add(Group(caption='QA'))
新建User表数据
session.add_all([
User(name='Bob', gid=1),
User(name='Boss', gid=2),
]
)
session.commit()
user表和group表中插入数据
上边的代码中,定义了2个表,一个是“组”,一个是“用户表”。一对多表示:一个组中可能存在多个用户。那么,需求来了,我想要查找出用户表中每个用户对应的组。
常规的联表查询如下:
ret = session.query(User.name, Group.caption).join(Group).all()
print(ret) # join默认是进行left join
out: [('Bob', 'DBA'), ('Boss', 'SA')]
虽然这样也查询到结果了。但是感觉还是很复杂,那有没有更加简便的方式呢!有,SQLalchemy中为我们提供了relationship类,来帮助我们应对一对多以及多对多的这种复杂表结构。还是以上边的需求为例,用relationship的话,代码如下:
步骤一:需要在创建表的时候建立关系:在创建User表的时候,新增一种虚拟字段类型(数据库中并不真实存在) --> group = relationship("Group")
# 使用relationship,先必须在创建表的时候建立关系
class Group(Base):
__tablename__ = 'group'
nid = Column(Integer, primary_key=True, autoincrement=True)
caption = Column(String(32)) class User(Base):
__tablename__ = 'user'
uid = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(32))
gid = Column(Integer, ForeignKey('group.nid'))
# 仅仅方便查询.
group = relationship("Group")
步骤二:开始查询之“正向查询”
ret = session.query(User).all()
for obj in ret:
# obj 代指user表中的每一行数据,是User对象
# obj.group代指group对象,可以用obj.group.XXX来获取group表中的字段的值
print(obj.uid, obj.name, obj.gid, obj.group, obj.group.nid, obj.group.caption) out: # 1 Bob 1 <__main__.Group object at 0x0000000003B31438> 1 DBA
# 2 Boss 2 <__main__.Group object at 0x0000000003B315F8> 2 SA
可以看出,使用了非常简单的查询就将数据全部取了出来。细心的同学可能已经发现,上边写到了正向查询,那么有没有“反向查询”呢?有!
反向查询需要在创建关系的时候,新增一个字段设置backref
group = relationship("Group", backref='uuu')
查询语句就变为了:
obj = session.query(Group).filter(Group.caption=='DBA').first() 带有筛选条件的语句,筛选DBA组所有成员 print(obj) # obj表示符合条件的Group对象 out: <__main__.Group object at 0x00000000032EB710>
print(obj.uuu) # obj.uuu 就是符合筛选条件的User对象
out: [<__main__.User object at 0x0000000003B15400>, <__main__.User object at 0x0000000003B15470>]
for i in obj.uuu:# obj.uuu需要用for循环来查询结果
print(i.uid, i.name, i.gid) out:
1 Bob 1
2 Boss 2
小结:
relationship()函数:这个函数告诉ORM,通过使用user.Group,Group类应该和User类连接起来
relationship()使用外键明确这两张表的关系。决定User.group属性是多对一的,即多个用户可以在同一个组里。
relationship()的子函数backref()提供表达反向关系的细节:relationship()对象的集合被Group.uuu引用。多对一的反向关系总是一对多,即一个组可以包含多个用户
多对多
上边的内容介绍了一对多的情况,生产环境中,也经常遇到多对多的情况。比如这样一种情形:某公司有好多服务器,员工也很多,业务交错在这些服务器上,就会造成一种现象:某台机器,多个人的业务在上边部署,这多个人具有这台服务器的权限。而对于每个人来说,他的业务不仅仅需要一台服务器,有时会部署在多台服务器。这样的情形,就构成了多对对的情况,即:单台服务器被多人拥有,单人拥有多台服务器的权限。这时候需要额外的一张表,来专门存储主机与用户之间的对应关系。三张表结构如下:
class Host(Base):
__tablename__ = 'host'
nid = Column(Integer, primary_key=True, autoincrement=True)
hostname = Column(String(32))
port = Column(String(32))
ip = Column(String(32)) class HostUser(Base):
__tablename__ = 'host_user'
nid = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(32)) # 多对多
class HostToHostUser(Base):
__tablename__ = 'host_to_host_user'
nid = Column(Integer, primary_key=True, autoincrement=True) # 两个关联的id,以外键的形式存在
host_id = Column(Integer, ForeignKey('host.nid'))
host_user_id = Column(Integer, ForeignKey('host_user.nid'))
# 创建完表之后,建立连接
Session = sessionmaker(bind=engine)
session = Session()
# 新增表数据
session.add_all([
Host(hostname='c1',port='',ip='1.1.1.1'),
Host(hostname='c2',port='',ip='1.1.1.2'),
Host(hostname='c3',port='',ip='1.1.1.3'),
Host(hostname='c4',port='',ip='1.1.1.4'),
Host(hostname='c5',port='',ip='1.1.1.5'),
])
session.commit() session.add_all([
HostUser(username='root'),
HostUser(username='db'),
HostUser(username='nb'),
HostUser(username='sb'),
])
session.commit() session.add_all([
HostToHostUser(host_id=1,host_user_id=1),
HostToHostUser(host_id=1,host_user_id=2),
HostToHostUser(host_id=1,host_user_id=3),
HostToHostUser(host_id=2,host_user_id=2),
HostToHostUser(host_id=2,host_user_id=4),
HostToHostUser(host_id=2,host_user_id=3),
])
session.commit()
新增表数据
上边增加的数据,增加了五台服务器,分别是c1,c2,c3,c4,c5。对应ID:1,2,3,4,5。
增加了四个人,分别是root, db, nb, sb,对应ID:1,2,3,4
关系表中 用户与主机的对应关系:
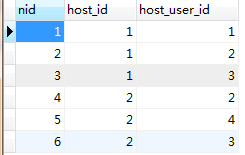
那么,需求来了:获取拥有主机1权限的所有用户。
在没有用到relationship时,查询方式如下:
# 1. 获取主机为c1的对象
host_obj = session.query(Host).filter(Host.hostname == 'c1').first() # 2. 获取查询关系表中拥有主机c1的用户ID
host_2_host_user = session.query(HostToHostUser.host_user_id).filter(HostToHostUser.host_id == host_obj.nid).all()
print(host_2_host_user) # [(1,), (2,), (3,)] r = zip(*host_2_host_user)
print(list(r)) #[(1, 2, 3)] 这就是用户ID列表
# 3. 根据用户ID列表,查询用户名
users = session.query(HostUser.username).filter(HostUser.nid.in_(list(r)[0])).all()
print(users) # [('root',), ('db',), ('nb',)]
可以看出,用普通方法查询,非常的繁琐,实际上进行了3次sql查询。那么使用relationship的话,会有哪些改变?
步骤1:创建关系表-->在创建表的时候,创建关系
class Host(Base):
__tablename__ = 'host'
nid = Column(Integer, primary_key=True, autoincrement=True)
hostname = Column(String(32))
port = Column(String(32))
ip = Column(String(32)) class HostUser(Base):
__tablename__ = 'host_user'
nid = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(32)) # 多对多
class HostToHostUser(Base):
__tablename__ = 'host_to_host_user'
nid = Column(Integer, primary_key=True, autoincrement=True) host_id = Column(Integer, ForeignKey('host.nid'))
host_user_id = Column(Integer, ForeignKey('host_user.nid')) # 新写法中有用
host = relationship('Host', backref='h')
host_user = relationship('HostUser', backref='u')
带有关系的三张表
步骤2:反向查找Host,从Host表中获取到HostToHostUser表中的字段信息
host_obj = session.query(Host).filter(Host.hostname == 'c1').first()
print(host_obj) # <__main__.Host object at 0x0000000003C11128>
print(host_obj.hostname) # 主机名:c1
print(host_obj.h) # host_obj.h表示HostToHostUser表中,符合筛选条件的HostToHostUser数据对象列表 [<__main__.HostToHostUser object at 0x0000000003B3F198>, <__main__.HostToHostUser object at 0x0000000003B3F898>, <__main__.HostToHostUser object at 0x0000000003B3F908>] # 循环获取用户信息
for item in host_obj.h:
# print(item.host_user) # 一行用户的数据, HostUser 表的一行数据对象
print(item.host_user.username)
# root db nb
可以看出,使用relationship,整个查询使用一个sql就搞定了。接下来介绍另外一种方式,和之前的差异也是在创建表的时候,具体看如下代码:
class HostToHostUser(Base):
__tablename__ = 'host_to_host_user'
nid = Column(Integer, primary_key=True, autoincrement=True) host_id = Column(Integer, ForeignKey('host.nid'))
host_user_id = Column(Integer, ForeignKey('host_user.nid')) class Host(Base):
__tablename__ = 'host'
nid = Column(Integer, primary_key=True, autoincrement=True)
hostname = Column(String(32))
port = Column(String(32))
ip = Column(String(32))
# 新的书写方式,不需要在多对多表中建立关系
host_user = relationship('HostUser', secondary=HostToHostUser.__table__, backref='h') class HostUser(Base):
__tablename__ = 'host_user'
nid = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(32))
新方式创建表关系
# 创建完表之后,建立连接
Session = sessionmaker(bind=engine)
session = Session() # 步骤1: 获取主机名为c1的Host对象
host_obj = session.query(Host).filter(Host.hostname=='c1').first() # 步骤2: 通过Host对象,正向查找用户名
print(host_obj.host_user) # [<__main__.HostUser object at 0x0000000003BA1DA0>, <__main__.HostUser object at 0x0000000003BA1E10>, <__main__.HostUser object at 0x0000000003BA1E80>]
for i in host_obj.host_user:
print(i.username) out:root db nb
关于filter和filter_by
用法不同而已,filter 可以像写 sql 的 where 条件那样写 > < 等条件,但引用列名时,需要通过 类名.属性名 的方式,引用列值时使用'=='
filter_by 可以使用 python 的正常参数传递方法传递条件,指定列名时,不需要额外指定类名。,参数名对应名类中的属性名,但似乎不能使用 > < 等条件。
小结:
SQLalchemy联表操作的方式
方式1:使用普通方法:join,多次查询符合筛选条件的数据
方式2:relationshi关系 --》ORM提供的一种便捷查询方法。使用relationship可以方便的实现一对多,以及多对多的查询
一对多关系:
一般情况下:fk与关系放在一起
多对多关系:多一张表,用来存放fk,完成查询需求时有两种方法
方法1、将关系放到关系表中 --》既有正向也有反向
方法2、在某一张表中放关系 --》只有正向
paramiko-基础
paramiko的两种基本用法:基于用户名密码连接、基于公钥私钥连接。主要有两个大类:SSHClient(用于连接远程服务器并执行基本命令)、SFTPClient(用于连接远程服务器并执行上传下载)
SSHClient
基于用户名密码连接:
import paramiko # 创建SSH对象
ssh = paramiko.SSHClient()
# 允许连接不在know_hosts文件中的主机
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 连接服务器
ssh.connect(hostname='172.25.50.13', port=22, username='work', password='') # 执行命令
stdin, stdout, stderr = ssh.exec_command('ls -l')
# 获取命令结果
result = stdout.read()
print(result.decode())
# 关闭连接
ssh.close()
out:
total 8
drwxr-xr-x 2 work work 4096 Mar 18 19:22 cn_market_lua
drwxrwxr-x 3 work work 4096 Mar 18 19:09 www
基于用户名密码实现执行命令
基于公钥密钥连接:
import paramiko # 创建key文件
private_key = paramiko.RSAKey.from_private_key_file('/home/auto/.ssh/id_rsa') # 创建SSH对象
ssh = paramiko.SSHClient()
# 允许连接不在know_hosts文件中的主机
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 连接服务器
ssh.connect(hostname='172.25.50.13', port=22, username='work', key=private_key) # 执行命令
stdin, stdout, stderr = ssh.exec_command('df -h')
# 获取命令结果
result = stdout.read() # 关闭连接
ssh.close()
out:
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 20G 4.2G 15G 23% /
tmpfs 1.9G 0 1.9G 0% /dev/shm
/dev/vdb1 99G 499M 93G 1% /data0
基于公钥私钥实现远程执行命令
SFTPClient
基于用户名密码连接:
import paramiko # 创建transport
transport = paramiko.Transport(('172.25.50.13',22))
transport.connect(username='work',password='') # 创建sftpclient,并基于transport连接,把他俩进行绑定
sftp = paramiko.SFTPClient.from_transport(transport)
# 将location.py 上传至服务器 /tmp/test.py
sftp.put('/tmp/location.py', '/tmp/test.py')
# 将remove_path 下载到本地 local_path
sftp.get('remove_path', 'local_path') # 关闭session
transport.close()
基于用户名密码实现上传下载
基于公钥密钥连接:
import paramiko
# 创建key文件
private_key = paramiko.RSAKey.from_private_key_file('/home/auto/.ssh/id_rsa') transport = paramiko.Transport(('172.25.50.13', 22))
transport.connect(username='work', pkey=private_key ) sftp = paramiko.SFTPClient.from_transport(transport)
# 将location.py 上传至服务器 /tmp/test.py
sftp.put('/tmp/location.py', '/tmp/test.py')
# 将remove_path 下载到本地 local_path
sftp.get('remove_path', 'local_path') transport.close()
基于公钥密钥上传下载
Paramiko进阶
从基础环节,我们学到了基本的使用方法。现在来看下源代码中这块的执行
第一步:创建SSHclient对象,这部没啥说的,关注一个初始化字段self._transport=None
ssh = paramiko.SSHClient()
第二步:连接到SSH主机,完成认证
ssh.connect(hostname='172.25.50.13', port=22, username='work', password='123456')
这步到底做了什么呢?看下源代码
def connect(
self,
hostname,
port=SSH_PORT,
username=None,
password=None,
pkey=None,
key_filename=None,
timeout=None,
allow_agent=True,
look_for_keys=True,
compress=False,
sock=None,
gss_auth=False,
gss_kex=False,
gss_deleg_creds=True,
gss_host=None,
banner_timeout=None
):
"""
Connect to an SSH server and authenticate to it. The server's host key
is checked against the system host keys (see `load_system_host_keys`)
and any local host keys (`load_host_keys`). If the server's hostname
is not found in either set of host keys, the missing host key policy
is used (see `set_missing_host_key_policy`). The default policy is
to reject the key and raise an `.SSHException`. Authentication is attempted in the following order of priority: - The ``pkey`` or ``key_filename`` passed in (if any)
- Any key we can find through an SSH agent
- Any "id_rsa", "id_dsa" or "id_ecdsa" key discoverable in
``~/.ssh/``
- Plain username/password auth, if a password was given If a private key requires a password to unlock it, and a password is
passed in, that password will be used to attempt to unlock the key. :param str hostname: the server to connect to
:param int port: the server port to connect to
:param str username:
the username to authenticate as (defaults to the current local
username)
:param str password:
a password to use for authentication or for unlocking a private key
:param .PKey pkey: an optional private key to use for authentication
:param str key_filename:
the filename, or list of filenames, of optional private key(s) to
try for authentication
:param float timeout:
an optional timeout (in seconds) for the TCP connect
:param bool allow_agent:
set to False to disable connecting to the SSH agent
:param bool look_for_keys:
set to False to disable searching for discoverable private key
files in ``~/.ssh/``
:param bool compress: set to True to turn on compression
:param socket sock:
an open socket or socket-like object (such as a `.Channel`) to use
for communication to the target host
:param bool gss_auth:
``True`` if you want to use GSS-API authentication
:param bool gss_kex:
Perform GSS-API Key Exchange and user authentication
:param bool gss_deleg_creds: Delegate GSS-API client credentials or not
:param str gss_host:
The targets name in the kerberos database. default: hostname
:param float banner_timeout: an optional timeout (in seconds) to wait
for the SSH banner to be presented. :raises BadHostKeyException: if the server's host key could not be
verified
:raises AuthenticationException: if authentication failed
:raises SSHException: if there was any other error connecting or
establishing an SSH session
:raises socket.error: if a socket error occurred while connecting .. versionchanged:: 1.15
Added the ``banner_timeout``, ``gss_auth``, ``gss_kex``,
``gss_deleg_creds`` and ``gss_host`` arguments.
"""
if not sock:
errors = {}
# Try multiple possible address families (e.g. IPv4 vs IPv6)
to_try = list(self._families_and_addresses(hostname, port))
for af, addr in to_try:
try:
sock = socket.socket(af, socket.SOCK_STREAM)
if timeout is not None:
try:
sock.settimeout(timeout)
except:
pass
retry_on_signal(lambda: sock.connect(addr))
# Break out of the loop on success
break
except socket.error as e:
# Raise anything that isn't a straight up connection error
# (such as a resolution error)
if e.errno not in (ECONNREFUSED, EHOSTUNREACH):
raise
# Capture anything else so we know how the run looks once
# iteration is complete. Retain info about which attempt
# this was.
errors[addr] = e # Make sure we explode usefully if no address family attempts
# succeeded. We've no way of knowing which error is the "right"
# one, so we construct a hybrid exception containing all the real
# ones, of a subclass that client code should still be watching for
# (socket.error)
if len(errors) == len(to_try):
raise NoValidConnectionsError(errors) t = self._transport = Transport(sock, gss_kex=gss_kex, gss_deleg_creds=gss_deleg_creds)
t.use_compression(compress=compress)
if gss_kex and gss_host is None:
t.set_gss_host(hostname)
elif gss_kex and gss_host is not None:
t.set_gss_host(gss_host)
else:
pass
if self._log_channel is not None:
t.set_log_channel(self._log_channel)
if banner_timeout is not None:
t.banner_timeout = banner_timeout
t.start_client()
ResourceManager.register(self, t) server_key = t.get_remote_server_key()
keytype = server_key.get_name() if port == SSH_PORT:
server_hostkey_name = hostname
else:
server_hostkey_name = "[%s]:%d" % (hostname, port) # If GSS-API Key Exchange is performed we are not required to check the
# host key, because the host is authenticated via GSS-API / SSPI as
# well as our client.
if not self._transport.use_gss_kex:
our_server_key = self._system_host_keys.get(server_hostkey_name,
{}).get(keytype, None)
if our_server_key is None:
our_server_key = self._host_keys.get(server_hostkey_name,
{}).get(keytype, None)
if our_server_key is None:
# will raise exception if the key is rejected; let that fall out
self._policy.missing_host_key(self, server_hostkey_name,
server_key)
# if the callback returns, assume the key is ok
our_server_key = server_key if server_key != our_server_key:
raise BadHostKeyException(hostname, server_key, our_server_key) if username is None:
username = getpass.getuser() if key_filename is None:
key_filenames = []
elif isinstance(key_filename, string_types):
key_filenames = [key_filename]
else:
key_filenames = key_filename
if gss_host is None:
gss_host = hostname
self._auth(username, password, pkey, key_filenames, allow_agent,
look_for_keys, gss_auth, gss_kex, gss_deleg_creds, gss_host)
SSHClient.connect源码部分
最关键的一步:t = self._transport = Transport(sock, gss_kex=gss_kex, gss_deleg_creds=gss_deleg_creds)
这步源码中说明如下:
Create a new SSH session over an existing socket, or socket-like
object. This only creates the `.Transport` object; it doesn't begin the
SSH session yet. Use `connect` or `start_client` to begin a client
session, or `start_server` to begin a server session.
那么可以看出,实际上是这句只是创建了一个session,或者是socket-like的对象。且这个session并没有启动,只有在调用connect或者start_client方法时,session才会生效。
那么,我们是否也可以自己封装一个tranport来定制一些功能呢?
还是以基础中的案例,现在就定制一个基于用户名密码的transport
步骤1:创建一个transport
# 创建transport
transport = paramiko.Transport(('172.25.50.13', 22))
步骤2:调用connect方法启动session
# 调用connect方法启动session
transport.connect(username='work', password='123456')
步骤3:覆盖原SSHClient对象对于self._transport的定义
ssh = paramiko.SSHClient()
ssh._transport = transport
步骤4:执行命令,执行完毕后关闭session
stdin, stdout, stderr = ssh.exec_command('df -h')
print(stdout.read().decode())
transport.close()
import paramiko
# 创建transport
transport = paramiko.Transport(('172.25.50.13', 22))
# 调用connect方法启动session
transport.connect(username='work', password='') ssh = paramiko.SSHClient()
ssh._transport = transport stdin, stdout, stderr = ssh.exec_command('df -h')
print(stdout.read().decode()) transport.close()
完整代码-定制transport实现基于用户名密码执行命令
import paramiko
private_key = paramiko.RSAKey.from_private_key_file('/home/auto/.ssh/id_rsa')
transport = paramiko.Transport(('172.25.50.13', 22))
transport.connect(username='work', pkey=private_key)
ssh = paramiko.SSHClient()
ssh._transport = transport
stdin, stdout, stderr = ssh.exec_command('df')
print(stdout.read().decode())
transport.close()
完整代码-定制transport实现基于ssh-key执行命令
那么,现在需求又来了。我不仅要实现单纯的执行命令,还要在执行命令之后,上传一个文件,上传文件之后依然能执行命令。
像这样一个复杂的需求,就需要我们自己来封装一个SSHclient,本质上也是对self._transport进行重新封装
# 自己封装一个类似SSHClient的类
import paramiko class SSHConnection(object):
def __init__(self, host='172.25.50.13', port=22, username='work',pwd='123456'):
self.host = host
self.port = port
self.username = username
self.pwd = pwd
self.__k = None def run(self):
self.connect()
pass
self.close() def connect(self):
# 创建transport
transport = paramiko.Transport((self.host,self.port))
# 启动session
transport.connect(username=self.username,password=self.pwd)
self.__transport = transport def close(self):
self.__transport.close() def cmd(self, command):
ssh = paramiko.SSHClient()
ssh._transport = self.__transport
# 执行命令
stdin, stdout, stderr = ssh.exec_command(command)
# 获取命令结果
result = stdout.read()
return result def upload(self,local_path, target_path):
# 连接,上传
sftp = paramiko.SFTPClient.from_transport(self.__transport)
# 将location.py 上传至服务器 /tmp/test.py
sftp.put(local_path, target_path) ssh = SSHConnection()
ssh.connect()
# 执行命令
r1 = ssh.cmd('df')
print(r1.decode())
# 上传文件
ssh.upload('s2.py', "/home/alex/s7.py") ssh.close()
堡垒机
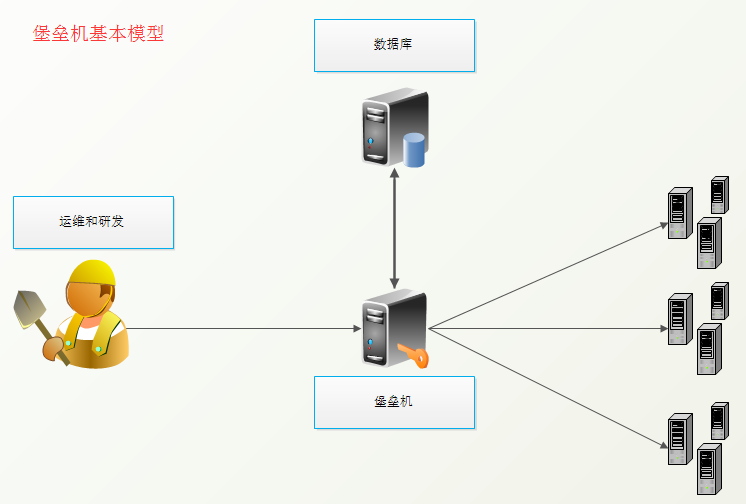
上图是一个基本的堡垒机模型,大概就是:
- 管理员为用户在服务器上创建账号(将公钥放置服务器,或者使用用户名密码)
- 用户登陆堡垒机,输入堡垒机用户名密码,显示当前用户管理的服务器列表
- 用户选择服务器,并自动登陆
- 执行操作并同时记录用户操作
使用paramiko就可以实现上述功能,这里先省略数据库方面:
版本一: 1)用户在终端输入内容,并将内容发送至远程服务器,
2)远程服务器执行命令,并将结果返回
3)用户终端显示内容
import paramiko
import sys
import os
import socket
import select
import getpass
from paramiko.py3compat import u # py27中注释掉这行 tran = paramiko.Transport(('172.25.50.13', 22,))
tran.start_client()
tran.auth_password('work', '') # 打开一个通道
chan = tran.open_session()
# 获取一个终端
chan.get_pty()
# 激活器
chan.invoke_shell() while True:
# 监视用户输入和服务器返回数据
# sys.stdin 处理用户输入
# chan 是之前创建的通道,用于接收服务器返回信息
readable, writeable, error = select.select([chan, sys.stdin, ],[],[],1)
if chan in readable:
try:
x = u(chan.recv(1024)) # py3中 代码
# x = chan.recv(1024) # py2中代码
if len(x) == 0:
print('\r\n*** EOF\r\n')
break
sys.stdout.write(x)
sys.stdout.flush()
except socket.timeout:
pass
if sys.stdin in readable:
inp = sys.stdin.readline()
chan.sendall(inp) chan.close()
tran.close()
版本1
版本二:在版本一中,可以发现和真是的shell环境是有区别的,不支持补全,非常难用。那么版本二就可以完成tab补全等功能,和真是shell一样。
核心要点:用户每次输入1个字符,就立即发送到服务端。然后在client端接收服务端的返回
# 肆意妄为 2 版本 改变终端模式,每输入一个字符,立即发送
import paramiko
import sys
import os
import socket
import select
import getpass
import termios # windows中没有这个模块
import tty
from paramiko.py3compat import u # py2 中需要注释掉这行 tran = paramiko.Transport(('172.25.50.13', 22,))
tran.start_client()
tran.auth_password('work', '') # 打开一个通道
chan = tran.open_session()
# 获取一个终端
chan.get_pty()
# 激活器
chan.invoke_shell() # 获取原tty属性
oldtty = termios.tcgetattr(sys.stdin)
try:
# 为tty设置新属性
# 默认当前tty设备属性:
# 输入一行回车,执行
# CTRL+C 进程退出,遇到特殊字符,特殊处理。 # 这是为原始模式,不认识所有特殊符号
# 放置特殊字符应用在当前终端,如此设置,将所有的用户输入均发送到远程服务器
tty.setraw(sys.stdin.fileno())
chan.settimeout(0.0) while True:
# 监视 用户输入 和 远程服务器返回数据(socket)
# 阻塞,直到句柄可读
r, w, e = select.select([chan, sys.stdin], [], [], 1)
if chan in r:
try:
# x = u(chan.recv(1024)) # py2中需要修改
x = chan.recv(1024)
if len(x) == 0:
print('\r\n*** EOF\r\n')
break
sys.stdout.write(x)
sys.stdout.flush()
except socket.timeout:
pass
if sys.stdin in r:
x = sys.stdin.read(1)
if len(x) == 0:
break
chan.send(x) finally:
# 重新设置终端属性
termios.tcsetattr(sys.stdin, termios.TCSADRAIN, oldtty) chan.close()
tran.close()
版本二
版本二种,实现了一个shell的完善环境。但是实际生产中,还有一个很重要的环节“用户验证”。版本1和版本2中,并不具备这个功能,现在来看版本3
版本三:带有用户验证功能的堡垒机
# 不带日志版 import paramiko
import sys
import os
import socket
import getpass from paramiko.py3compat import u # windows does not have termios...
try:
import termios
import tty
has_termios = True
except ImportError:
has_termios = False def interactive_shell(chan):
if has_termios:
posix_shell(chan)
else:
windows_shell(chan) def posix_shell(chan):
import select oldtty = termios.tcgetattr(sys.stdin)
try:
tty.setraw(sys.stdin.fileno())
tty.setcbreak(sys.stdin.fileno())
chan.settimeout(0.0) flag = False
temp_list = []
while True:
r, w, e = select.select([chan, sys.stdin], [], [])
if chan in r:
try:
x = u(chan.recv(1024))
if len(x) == 0:
sys.stdout.write('\r\n*** EOF\r\n')
break
sys.stdout.write(x)
sys.stdout.flush()
except socket.timeout:
pass
if sys.stdin in r:
x = sys.stdin.read(1)
import json if len(x) == 0:
break
chan.send(x) finally:
termios.tcsetattr(sys.stdin, termios.TCSADRAIN, oldtty) def windows_shell(chan):
import threading sys.stdout.write("Line-buffered terminal emulation. Press F6 or ^Z to send EOF.\r\n\r\n") def writeall(sock):
while True:
data = sock.recv(256)
if not data:
sys.stdout.write('\r\n*** EOF ***\r\n\r\n')
sys.stdout.flush()
break
sys.stdout.write(data)
sys.stdout.flush() writer = threading.Thread(target=writeall, args=(chan,))
writer.start() try:
while True:
d = sys.stdin.read(1)
if not d:
break
chan.send(d)
except EOFError:
# user hit ^Z or F6
pass def run():
# 获取当前登录用户
username = raw_input('Username ')
hostname = raw_input('Hostname: ')
pwd = raw_input('password: ') tran = paramiko.Transport((hostname, 22,))
tran.start_client()
tran.auth_password(username, pwd) # 打开一个通道
chan = tran.open_session()
# 获取一个终端
chan.get_pty()
# 激活器
chan.invoke_shell() interactive_shell(chan) chan.close()
tran.close() if __name__ == '__main__':
run()
版本三
版本三在不考虑数据库的情况下,其实已经相对完善了。但是堡垒机还得有一个必要的功能,“记录用户操作日志”
终极版本:带有用户日志的堡垒机
# 记录用户日志
import paramiko
import sys
import os
import socket
import getpass from paramiko.py3compat import u # windows does not have termios...
try:
import termios
import tty
has_termios = True
except ImportError:
has_termios = False def interactive_shell(chan):
if has_termios:
posix_shell(chan)
else:
windows_shell(chan) def posix_shell(chan):
import select oldtty = termios.tcgetattr(sys.stdin)
try:
tty.setraw(sys.stdin.fileno())
tty.setcbreak(sys.stdin.fileno())
chan.settimeout(0.0)
log = open('handle.log', 'a+', encoding='utf-8')
flag = False
temp_list = []
while True:
r, w, e = select.select([chan, sys.stdin], [], [])
if chan in r:
try:
x = u(chan.recv(1024))
if len(x) == 0:
sys.stdout.write('\r\n*** EOF\r\n')
break
if flag:
if x.startswith('\r\n'):
pass
else:
temp_list.append(x)
flag = False
sys.stdout.write(x)
sys.stdout.flush()
except socket.timeout:
pass
if sys.stdin in r:
x = sys.stdin.read(1)
import json if len(x) == 0:
break if x == '\t':
flag = True
else:
temp_list.append(x)
if x == '\r':
log.write(''.join(temp_list))
log.flush()
temp_list.clear()
chan.send(x) finally:
termios.tcsetattr(sys.stdin, termios.TCSADRAIN, oldtty) def windows_shell(chan):
import threading sys.stdout.write("Line-buffered terminal emulation. Press F6 or ^Z to send EOF.\r\n\r\n") def writeall(sock):
while True:
data = sock.recv(256)
if not data:
sys.stdout.write('\r\n*** EOF ***\r\n\r\n')
sys.stdout.flush()
break
sys.stdout.write(data)
sys.stdout.flush() writer = threading.Thread(target=writeall, args=(chan,))
writer.start() try:
while True:
d = sys.stdin.read(1)
if not d:
break
chan.send(d)
except EOFError:
# user hit ^Z or F6
pass def run():
default_username = getpass.getuser()
username = input('Username [%s]: ' % default_username)
if len(username) == 0:
username = default_username hostname = input('Hostname: ')
if len(hostname) == 0:
print('*** Hostname required.')
sys.exit(1) tran = paramiko.Transport((hostname, 22,))
tran.start_client() default_auth = "p"
auth = input('Auth by (p)assword or (r)sa key[%s] ' % default_auth)
if len(auth) == 0:
auth = default_auth if auth == 'r':
default_path = os.path.join(os.environ['HOME'], '.ssh', 'id_rsa')
path = input('RSA key [%s]: ' % default_path)
if len(path) == 0:
path = default_path
try:
key = paramiko.RSAKey.from_private_key_file(path)
except paramiko.PasswordRequiredException:
password = getpass.getpass('RSA key password: ')
key = paramiko.RSAKey.from_private_key_file(path, password)
tran.auth_publickey(username, key)
else:
pw = getpass.getpass('Password for %s@%s: ' % (username, hostname))
tran.auth_password(username, pw) # 打开一个通道
chan = tran.open_session()
# 获取一个终端
chan.get_pty()
# 激活器
chan.invoke_shell() interactive_shell(chan) chan.close()
tran.close() if __name__ == '__main__':
run()
终极版-Python3执行
Python菜鸟之路:sqlalchemy/paramiko进阶的更多相关文章
- Python菜鸟之路:Django 路由补充1:FBV和CBV - 补充2:url默认参数
一.FBV和CBV 在Python菜鸟之路:Django 路由.模板.Model(ORM)一节中,已经介绍了几种路由的写法及对应关系,那种写法可以称之为FBV: function base view ...
- Python菜鸟之路:Python操作MySQL-即pymysql/SQLAlchemy用法
上节介绍了Python对于RabbitMQ的一些操作,本节介绍Python对于MySQL的一些操作用法 模块1:pymysql(等同于MySQLdb) 说明:pymysql与MySQLdb模块的使用基 ...
- Python菜鸟之路:Django 数据库操作进阶F和Q操作
Model中的F F 的操作通常的应用场景在于:公司对于每个员工,都涨500的工资.这个时候F就可以作为查询条件 from django.db.models import F models.UserI ...
- python 学习笔记十一 SQLALchemy ORM(进阶篇)
SqlAlchemy ORM SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据A ...
- Python菜鸟之路:Django 路由、模板、Model(ORM)
Django路由系统 Django的路由系统让Django可以根据URI进行匹配,进而发送至特定的函数去处理用户请求.有点类似nginx的location功能. Django的路由关系分为三种:普通关 ...
- Python菜鸟之路:Python基础-线程、进程、协程
上节内容,简单的介绍了线程和进程,并且介绍了Python中的GIL机制.本节详细介绍线程.进程以及协程的概念及实现. 线程 基本使用 方法1: 创建一个threading.Thread对象,在它的初始 ...
- 【Python高级工程师之路】入门+进阶+实战+爬虫+数据分析整套教程
点击了解更多Python课程>>> 全网最新最全python高级工程师全套视频教程学完月薪平均2万 什么是Python? Python是一门面向对象的编程语言,它相对于其他语言,更加 ...
- python学习之路-5 基础进阶篇
本篇涉及内容 双层装饰器字符串格式化 双层装饰器 装饰器基础请点我 有时候一个功能需要有2次认证的时候就需要用到双层装饰器了,下面我们来通过一个案例详细介绍一下双层装饰器: 执行顺序:自上而下 解释顺 ...
- Python菜鸟之路:Django Admin后台管理功能使用
前言 用过Django框架的童鞋肯定都知道,在创建完Django项目后,每个app下,都会有一个urls.py文件,里边会有如下几行: from django.contrib import admin ...
随机推荐
- AngularJS: Dynamically loading directives
http://www.codelord.net/2015/05/19/angularjs-dynamically-loading-directives/ ----------------------- ...
- 在vs2010中编译log4cxx-0.10.0具体方法(从下载、编译、解决错误具体介绍)
一. 简单介绍 log4cxx是Java社区著名的log4j的c++移植版.用于为C++程序提供日志功能,以便开发人员对目标程序进行调试和审计,log4cxx是apache软件基金会的开源项目,基于A ...
- VB,Visual Basic如何修改代码文本大小和字体
工具-选项-编辑器格式 修改之后效果如图所示
- defer,panic,recover
Go语言不支持传统的 try…catch…finally 这种异常,因为Go语言的设计者们认为,将异常与控制结构混在一起会很容易使得代码变得混乱.因为开发者很容易滥用异常,甚至一个小小的错误都抛出一个 ...
- 深入浅出java静态代理和动态代理
首先介绍一下.什么是代理: 代理模式,是经常使用的设计模式. 特征是.代理类与托付类有同样的接口,代理类主要负责为托付类预处理消息.过滤消息.把消息转发给托付类.以及事后处理消息. 代理类和托付类,存 ...
- 如何检测一个aspx页面的速度慢的原因
最近读到一篇文章,是关于如何提高一个aspx页面的速度.这是一个常见的面试问题.该问题原文出自这个网站. 出现这个问题的原因会多种多样,我们需要一步一步的排查来定位问题真正出现在哪里. 1. 找出那一 ...
- Iocomp控件教程之LinearGauge--线性刻度尺控件
线性刻度尺-线性刻度尺控件(LinearGauge)是一个具有线性表达式刻度的图像控件.支持多达5种颜色断面和4种指示器样式,相同功能,查看线性对数刻度尺(Linear Log Gauge)控件内容 ...
- PrincetonUniversity-Coursera 算法:算法简单介绍
Course Overview What is this course? Intermediate-level survey course. Programming and proble solvin ...
- maven的一些基础命令
1.显示当前构建的实际pom,包括活动的Profile mvn help:effective-pom 2.打印出项目的世界settings,包含从全局的settings和用户级别settings继承的 ...
- Log4J 基本使用
Log4j由三个重要的组件 构 成:日志 信息 的优先级,日志信息的输出目的地,日志信息的输出格式. 日志信息的优先级 从高到低有ERROR . WARN . INFO . DEBUG ,分别用来指定 ...