pytorch 加载数据集
pytorch初学者,想加载自己的数据,了解了一下数据类型、维度等信息,方便以后加载其他数据。
1 torchvision.transforms实现数据预处理
transforms.Totensor()操作必须要有,将数据转为张量格式。
2 torch.utils.data.Dataset实现数据读取
要使用自己的数据集,需要构建Dataset子类,定义子类为MyDataset,在MyDataset的init函数中定义path_dict变量,来获取不同类型的数据的路径。
定义子类MyDataset时,必须要重载两个函数 getitem 和 len,
__getitem__:实现数据集的下标索引,返回对应的数据及标签;
__len__:返回数据集的大小。
设加载的数据集大小为L;
定义MyDataset实例:my_datasets = MyDataset(data_dir, transform = data_transform) 。
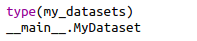
my_datasets 由L个tuple组成,len(my_datasets) = L;
每个tuple长度为2:0:tensor 样本(Channel,Height,Width)
1:int 标签




3 torch.utils.data.DataLoader实现数据集加载
torch.utils.data.DataLoader()合成数据并提供迭代访问,由两部分组成:
—dataset(Dataset):输入要加载的数据,就是上面的my_datasets;
—batch_size,shuffle,sampler,batch_sampler,num_workers,collate_fn, drop_last,timeout,worker_init_fn等参数。
其中:batch_size:批尺寸,默认为1;
shuffle:是否在每个epoch开始随机打乱数据,默认为False;
设data_loader长度为 l ;
加载数据:data_loader = DataLoader(my_datasets, batch_size = BATCH_SIZE, shuffle = True)
data_loader 由 l 个 tuple组成,l = len(data_loader) = len(my_datasets) / batch_size;
迭代访问:


e 长度为2:0:int step 表示第几个batch
1:list(长度为2)表示一个batch包含的所有样本和标签
0:tensor 样本(Batch_size,Channel,Height,Width)
1:tensor 标签 Batch_size
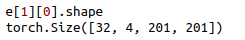

pytorch 加载数据集的更多相关文章
- pytorch 加载mnist数据集报错not gzip file
利用pytorch加载mnist数据集的代码如下 import torchvision import torchvision.transforms as transforms from torch.u ...
- SciKit-Learn 加载数据集
章节 SciKit-Learn 加载数据集 SciKit-Learn 数据集基本信息 SciKit-Learn 使用matplotlib可视化数据 SciKit-Learn 可视化数据:主成分分析(P ...
- pytorch加载语音类自定义数据集
pytorch对一下常用的公开数据集有很方便的API接口,但是当我们需要使用自己的数据集训练神经网络时,就需要自定义数据集,在pytorch中,提供了一些类,方便我们定义自己的数据集合 torch.u ...
- Pytorch加载并可视化FashionMNIST指定层(Udacity)
加载并可视化FashionMNIST 在这个notebook中,我们要加载并查看 Fashion-MNIST 数据库中的图像. 任何分类问题的第一步,都是查看你正在使用的数据集.这样你可以了解有关图像 ...
- [Pytorch]Pytorch加载预训练模型(转)
转自:https://blog.csdn.net/Vivianyzw/article/details/81061765 东风的地方 1. 直接加载预训练模型 在训练的时候可能需要中断一下,然后继续训练 ...
- [Python]-sklearn模块-机器学习Python入门《Python机器学习手册》-02-加载数据:加载数据集
<Python机器学习手册--从数据预处理到深度学习> 这本书类似于工具书或者字典,对于python具体代码的调用和使用场景写的很清楚,感觉虽然是工具书,但是对照着做一遍应该可以对机器学习 ...
- pytorch加载预训练模型参数的方式
1.直接使用默认程序里的下载方式,往往比较慢: 2.通过修改源代码,使得模型加载已经下载好的参数,修改地方如下: 通过查找自己代码里所调用网络的类,使用pycharm自带的函数查找功能(ctrl+鼠标 ...
- pytorch加载数据的方法-没弄,打算弄
参考:https://www.jianshu.com/p/aee6a3d72014 # 网络,netg为生成器,netd为判别器 netg, netd = NetG(opt), NetD(opt) # ...
- pytorch 加载训练好的模型做inference
前提: 模型参数和结构是分别保存的 1. 构建模型(# load model graph) model = MODEL() 2.加载模型参数(# load model state_dict) mode ...
随机推荐
- 快速理解JavaScript面向对象编程—原型
总的来说js语言就是门面向对象编程的语言,对象这个概念几乎贯穿了整个js的学习. 对象 创建对象两种方法:(若要生成对象实例必须调用构造函数) 1.var obj = {name:"jer& ...
- Zynq7000开发系列-6(QT开发环境搭建:Ubuntu、Zynq)
操作系统:Ubuntu14.04.5 LTS 64bit Qt:Qt 5.4.2 (qt-opensource-linux-x64-5.4.2.run.qt-everywhere-opensource ...
- Django (五) modeld进阶
day 05 models进阶 1.models基本操作 django中遵循 Code Frist 的原则,即:根据代码中定义的类来自动生成数据库表. 对于ORM框架里: 我们写的类表示数据库的表 ...
- ICM Technex 2017 and Codeforces Round #400 (Div. 1 + Div. 2, combined) C
Molly Hooper has n different kinds of chemicals arranged in a line. Each of the chemicals has an aff ...
- mysql 维护添加远程主机访问
https://www.cnblogs.com/JNUX/p/6936548.html
- centos7安装mysql5.7 使用yum
https://blog.csdn.net/z13615480737/article/details/78906598 使用yum,比较简单,不用考虑版本依赖问题
- Java编程基础-选择和循环语句
一.选择结构语句 选择结构:也被称为分支结构.选择结构有特定的语法规则,代码要执行具体的逻辑运算进行判断,逻辑运算的结果有两个,所以产生选择,按照不同的选择执行不同的代码. Java语言提供了两种选择 ...
- HDU4035 Maze(期望DP)
题意 抄袭自https://www.cnblogs.com/Paul-Guderian/p/7624039.html 有n个房间,由n-1条隧道连通起来,形成一棵树,从结点1出发,开始走,在每个结点i ...
- jQuery选择器手册
jQuery选择器手册 选择器 实例 选取 * $("*") 所有元素 #id $("#lastname") id="lastname" 的 ...
- vscode设置html默认浏览器
Vscode版本:1.30.2,设置方法:file→preference→settings,剩余设置如下图.