大型分布式C++框架《四:netio之请求包中转站 上》
本来一篇文章就该搞定的。结果要分上下篇了。主要是最近颈椎很不舒服。同时还在做秒杀的需求也挺忙的。 现在不能久坐。看代码的时间变少了。然后还买了两本治疗颈椎的书。在学着,不过感觉没啥用。突然心里好害怕。如果颈椎病越来越重。以后的路怎么走。
现在上下班有跑步,然后坐一个小时就起来活动活动。然后在跟着同时们一起去打羽毛球吧。也快30的人了。现在发觉身体才是真的。其他都没什么意思。兄弟们也得注意~~
废话不多说。下面介绍下netio。
netio在系统中主要是一个分包的作用。netio本事没有任何的业务处理。拿到包以后进行简单的处理。再根据请求的命令字发送到对应的业务处理进程去。
一、多进程下的socket epoll以及“惊群现象”
1)比如我们想创建三个进程同时处理一个端口下到来的请求。
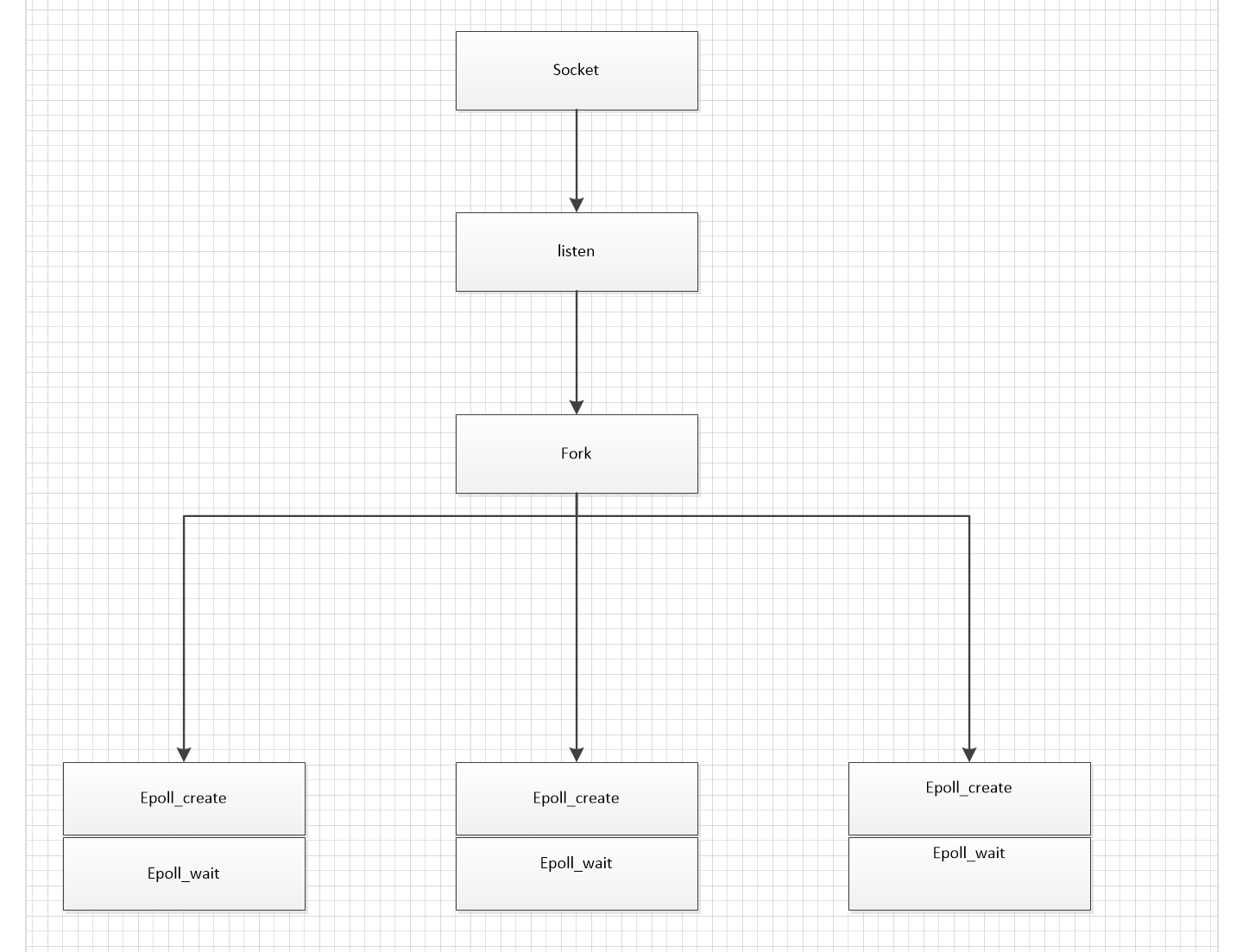
首先如果一个端口正在被使用,无论是TIME_WAIT、CLOSE_WAIT、还是ESTABLISHED状态。 这个端口都不能被复用,这里面自然也是包括不能被用来LISTEN(监听)。所以在三个进程里分别listen和bind端口肯定会失败的
因为SO_REUSEADDR允许在同一端口上启动同一服务器的多个实例,只要每个实例捆绑一个不同的本地IP地址即可。对于TCP,我们根本不可能启动捆绑相同IP地址和相同端口号的多个服务器。
netio起5个进程
james : pts/ :: ./netio netio_config.xml
james : pts/ :: ./netio netio_config.xml
james : pts/ :: ./netio netio_config.xml
james : pts/ :: ./netio netio_config.xml
james : pts/ :: ./netio netio_config.xml
after epoll_wait pid:
after epoll_wait pid:
after epoll_wait pid:
after epoll_wait pid:
after epoll_wait pid:
after epoll_wait pid:
after epoll_wait pid:
after epoll_wait pid:
after epoll_wait pid:
after epoll_wait pid:
after epoll_wait pid:
after epoll_wait pid:
这个时候我们客户端fork8个进程并发请求服务。发现2357和2358开始交替处理
after epoll_wait pid:
after epoll_wait pid:
after epoll_wait pid:
after epoll_wait pid:
after epoll_wait pid:
after epoll_wait pid:
after epoll_wait pid:
after epoll_wait pid:
after epoll_wait pid:
after epoll_wait pid:
after epoll_wait pid:
after epoll_wait pid:
after epoll_wait pid:
after epoll_wait pid:2358
当我们并发两个请求的时候。发现唤醒了两个进程
after epoll_wait pid:
after epoll_wait pid:
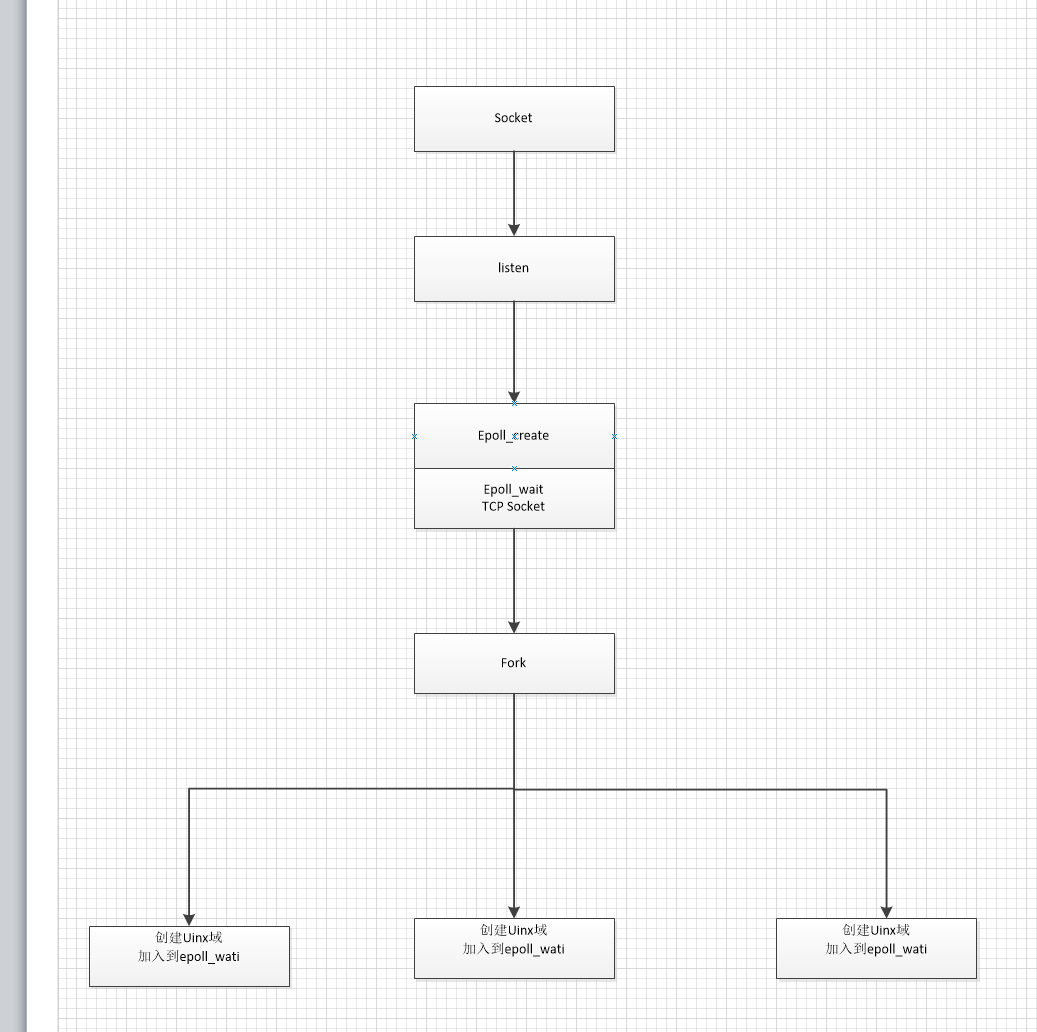

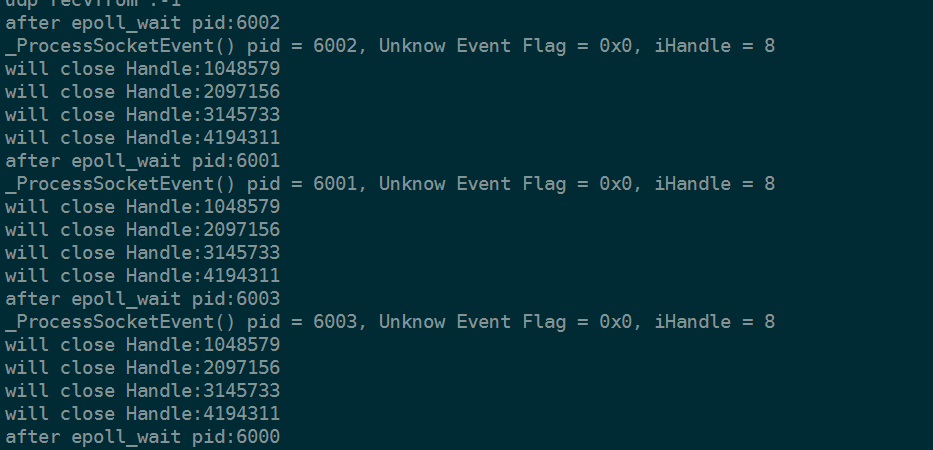
中所以其他进程一直recvfrom =-1
的进程不够及时。这个消息没处理。epoll的特性是会一直通知进程来处理。所以其他进程会一直读自己的unix域。然后就一直recvfrom =-1

二、netio之定时器
const uint32_t DEFAULT_QUEUE_LEN = + ; m_pNodeHeap = new CNode*[DEFAULT_QUEUE_LEN];
struct CNode
{
CNode(ITimerHandler *pTimerHandler = NULL, int iTimerID = )
: m_pTimerHandler(pTimerHandler)
, m_iTimerID(iTimerID)
, m_dwCount()
, bEnable(true)
{ } ITimerHandler *m_pTimerHandler;
int m_iTimerID; CTimeValue m_tvExpired; // TimeValue for first check
CTimeValue m_tvInterval; // Time check interval
unsigned int m_dwCount; // Counter for auto re-schedule
bool bEnable;
};
m_pTimerHandler 主要是用来保存父类指针。当时间事件触发的时候。通过父类指针找到继承类。来处理具体的 时间事件
m_tvExpired 记录过期时间。比如一个事件过期时间是10秒。那么m_tvExpired就是存的当前时间+10秒这个值。每次比较的时候。拿最小堆的的这个值跟当前时间比对。如果当前时间小于m_tvExpired说明 没有任何时间时间被触发。如果当前时间大于这个值。则认为需要处理时间事件
m_dwCount 这个是用来设置自动过期时间的次数。比如我们有一个时间事件。我们希望它执行三次。每次的间隔以为1分钟。那么这个值设置为3. 当第一次到达时间时间的时候。我们发现这个值大于0.则对m_tvExpired赋值当前时间+1分钟 重新进入最小堆。然后m_dwCount减一。
下次依然是这样处理。直到m_dwCount这个值到0.我们就认为不需要再自动给这个时间设置定时任务。
bEnable 这个值是用来判断这个事件事件是否还有效。这里的做法很有意思。当一个时间事件执行完。或者不需要的时候。我们先是帮它设置为false.等下次check时间最堆的时候。如果发现这个时间事件是无效的。这个时候在delete
m_tvInterval 这个是时间事件的间隔时间。比如我的时间事件是每10秒执行一次。则这个值就设置为10秒
m_iTimerID 这个是时间事件的唯一ID
这个值是自增的。每来一个新时间事件。m_iTimerID都会+. 因为初始化的时候。这个值为1了。所以最开始的时间事件m_iTimerID的值为2
if (dwCount > )
m_l_pNode->m_dwCount = dwCount;
else
m_l_pNode->m_dwCount = (unsigned int)-;
三、netio 之日志分析



最后:
1)对大型系统。统计日志很重要。可以时事了解系统的状态
2)一定要处理好多进程的关系
3)最后 一定要保护好身体。 身体才是根本啊~~~
大型分布式C++框架《四:netio之请求包中转站 上》的更多相关文章
- Storm分布式实时流计算框架相关技术总结
Storm分布式实时流计算框架相关技术总结 Storm作为一个开源的分布式实时流计算框架,其内部实现使用了一些常用的技术,这里是对这些技术及其在Storm中作用的概括介绍.以此为基础,后续再深入了解S ...
- 开源分享 Unity3d客户端与C#分布式服务端游戏框架
很久之前,在博客园写了一篇文章,<分布式网游server的一些想法语言和平台的选择>,当时就有了用C#做网游服务端的想法.写了个Unity3d客户端分布式服务端框架,最近发布了1.0版本, ...
- Django准备知识-web应用、http协议、web框架、Django简介
一.web应用 Web应用程序是一种可以通过web访问的应用程序(web应用本质是基于socket实现的应用程序),程序的最大好处是用户很容易访问应用程序,用户只需要有浏览器即可,不需要再安装其他软件 ...
- Unity 游戏框架搭建 2018 (一) 架构、框架与 QFramework 简介
约定 还记得上版本的第二十四篇的约定嘛?现在出来履行啦~ 为什么要重制? 之前写的专栏都是按照心情写的,在最初的时候笔者什么都不懂,而且文章的发布是按照很随性的一个顺序.结果就是说,大家都看完了,都还 ...
- Python分布式爬虫必学框架Scrapy打造搜索引擎
Python分布式爬虫必学框架Scrapy打造搜索引擎 部分课程截图: 点击链接或搜索QQ号直接加群获取其它资料: 链接:https://pan.baidu.com/s/1-wHr4dTAxfd51M ...
- Python分布式爬虫必学框架Scrapy打造搜索引擎 ✌✌
Python分布式爬虫必学框架Scrapy打造搜索引擎 ✌✌ (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 第1章 课程介绍 介绍课程目标.通过课程能学习到 ...
- Django框架-目录文件简介
Rhel6.5 Django1.10 Python3.5 Django框架-目录文件简介 1.介绍Django Django:一个可以使Web开发工作愉快并且高效的Web开发框架. 使用Django, ...
- Net框架下-ORM框架LLBLGen的简介
>对于应用程序行业领域来说,涉及到Net框架的,在众多支持大型项目的商用ORM框架中,使用最多的目前了解的主要有三款: 1.NHibernate(从Java版移植来的Net版). 2.微软的EF ...
- Unity3d&C#分布式游戏服务器ET框架介绍-组件式设计
前几天写了<开源分享 Unity3d客户端与C#分布式服务端游戏框架>,受到很多人关注,QQ群几天就加了80多个人.开源这个框架的主要目的也是分享自己设计ET的一些想法,所以我准备写一系列 ...
- asp.Net Core免费开源分布式异常日志收集框架Exceptionless安装配置以及简单使用图文教程
最近在学习张善友老师的NanoFabric 框架的时了解到Exceptionless : https://exceptionless.com/ !因此学习了一下这个开源框架!下面对Exceptionl ...
随机推荐
- LAMP php5.4编译 _php_image_stream_putc等问题
编译时出现下列问题时: In file included from /usr/local/src/php-5.4.6/ext/gd/gd.c:103: /usr/local/src/php-5.4.6 ...
- 27个Jupyter快捷键、技巧(原英文版)
本文是转发自:https://www.dataquest.io/blog/jupyter-notebook-tips-tricks-shortcuts/ 的一篇文章,先记录在此,等有空时我会翻译成中文 ...
- webpy:页面下载的三种实现方式
python: 1.import urllib urlretrieve() 方法直接将远程数据下载到本地. >>> help(urllib.urlretrieve)Help on f ...
- java反射新的应用
利用java反射动态修改运行中对象的私有final变量,不管有没有get方法获取这个私有final变量. spring aop 本质是cglib,动态代理 可以做很多事情 query.addCrite ...
- 熟悉java堆内存和栈内存和mysql的insert语句中含有id的处理
java的堆内存和栈内存有什么区别呢? 如果mysql数据库表的id是递增的,如果没有插入id,则id自增,如果插入id,则插入什么就显示什么.
- ARGB和RGB
ARGB 一种色彩模式,也就是RGB色彩模式附加上Alpha(透明度)通道,常见于32位位图的存储结构. ARGB---Alpha,Red,Green,Blue. Alpha-图像通道 如果图形卡具有 ...
- nginx+tomcat+memcached搭建服务器集群及负载均衡
在实际项目中,由于用户的访问量很大的原因,往往需要同时开启多个服务器才能满足实际需求.但是同时开启多个服务又该怎么管理他们呢?怎样实现session共享呢?下面就来讲一讲如何使用tomcat+ngin ...
- 高放的python学习笔记之基本语法
python与c++的不同之处 python的语句块不是用{}括起来的而是冒号后面跟一些与比当前语句多一的tab缩进的语句. 1.定义变量 python的变量类型不需要人为指出,会根据赋值的类型决定此 ...
- 安装beautifulsoup的奇怪问题
以前用的python2.7,改成3.4以后就重新下载了beatifulsoup4.解压到c:\Python34后.在cmd界面执行python setup.py install安装完成后.想看看安装成 ...
- AIDL Service
开发AIDL服务的步骤 AIDL(Android Interface Definition Language)是Service的一种重要应用,允许一个应用程序访问另一个应用程序中的对象. 建立AIDL ...