大数据学习——hadoop安装
上传centOS6.7-hadoop-2.6.4.tar.gz
解压 tar -zxvf centOS6.7-hadoop-2.6.4.tar.gz
hadoop相关修改配置
1 修改 /root/apps/hadoop/etc/hadoop 目录下的hadoop-env.sh
vi hadoop-env.sh 中 export JAVA_HOME=${JAVA_HOME}修改为 export JAVA_HOME=/root/apps/jdk1.7.0_80保存退出
2 修改 core-site.xml
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mini:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/apps/hadoop/tmp</value>
</property>
修改后的文件内容如下:
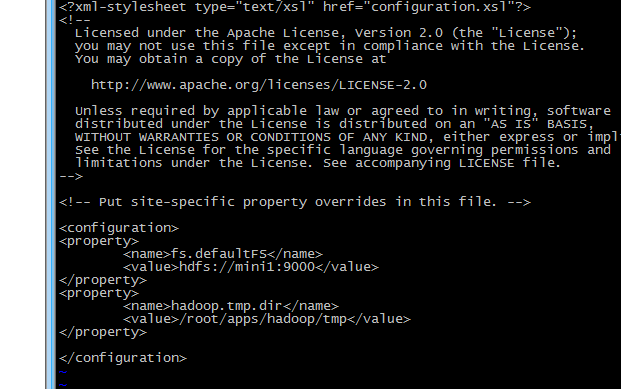
保存退出。
3修改hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>mini1:50090</value>
</property>
修改后的文件为:
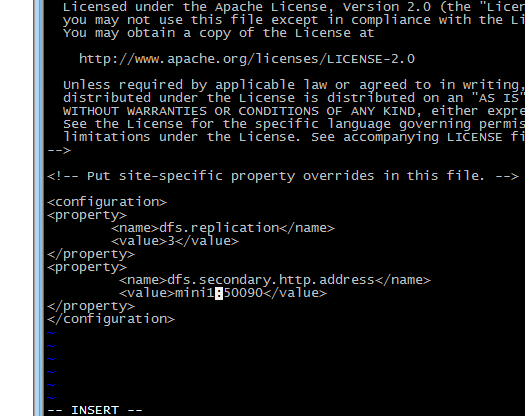
4 修改 mapred-site.xml(mv mapred-site.xml.template mapred-site.xml)
没有该文件,先cp一份(cp mapred-site.xml.template mapred-site.xml)
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
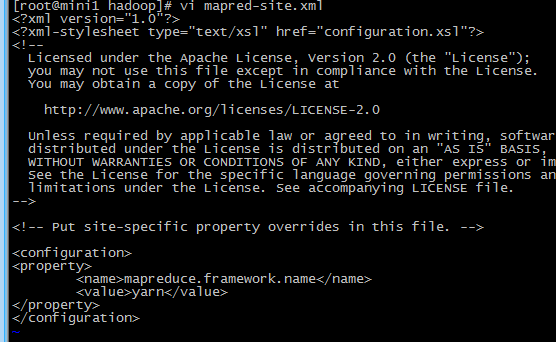
5修改yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>weekend-1206-01</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
将hadoop添加到环境变量
vi /etc/proflie
export JAVA_HOME=/root/apps/jdk1.7.0_80
export HADOOP_HOME=/root/apps/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
修改后的文件如下
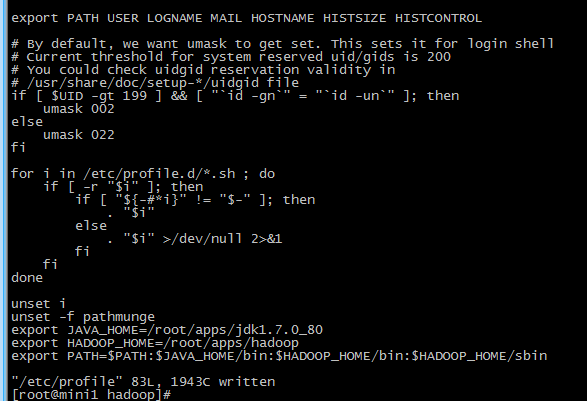
把修改后的hadoop发送到mini2,mini3
scp -r /root/apps/hadoop/ root@mini2:/root/apps/
scp -r /root/apps/hadoop/ root@mini3:/root/apps/

把修改的环境变量文件cp到mini2,mini3
scp -r /etc/profile root@mini2:/etc/profile
scp -r /etc/profile root@mini3:/etc/profile
在mini1,mini2,mini3上重新加载一下
source /etc/profile
完成
大数据学习——hadoop安装的更多相关文章
- 大数据学习——HADOOP集群搭建
4.1 HADOOP集群搭建 4.1.1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主 ...
- 大数据学习——Hadoop第一天
1.1 什么是HADOOP HADOOP是apache旗下的一套开源软件平台 HADOOP提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理 HADOOP的核心组件有 HD ...
- 大数据学习——flume安装部署
1.Flume的安装非常简单,只需要解压即可,当然,前提是已有hadoop环境 上传安装包到数据源所在节点上 然后解压 tar -zxvf apache-flume-1.6.0-bin.tar.gz ...
- 大数据学习——hive安装部署
1上传压缩包 2 解压 tar -zxvf apache-hive-1.2.1-bin.tar.gz -C apps 3 重命名 mv apache-hive-1.2.1-bin hive 4 设置环 ...
- 大数据学习——hadoop集群搭建2.X
1.准备Linux环境 1.0先将虚拟机的网络模式选为NAT 1.1修改主机名 vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=itcast ### ...
- 大数据学习——VMware安装
---恢复内容开始--- 一.下载VMware,安装 二.新建虚拟机 1.FIle-->new virtual machine 后面进入硬件资源分配,其中cpu给1个,内存至少给1G,网卡的选择 ...
- 大数据学习——hadoop的RPC框架
项目结构 服务端代码 test-hadoop-rpc pom.xml <?xml version="1.0" encoding="UTF-8"?> ...
- 大数据学习——redis安装
用源码工程来编译安装 / 到官网下载最新stable版 / 解压源码并进入目录 .tar.gz -C ./redis-src/ / make 如果报错提示缺少gcc,则安装gcc : yum inst ...
- 大数据学习——yum安装tomcat
https://www.cnblogs.com/jtlgb/p/5726161.html 安装tomcat6 yum install tomcat6 tomcat6-webapps tomcat6-a ...
随机推荐
- linux常用的shell命令
1.shell介绍 shell(外壳)是linux系统的最外层,简单的说,它就是用户和操作系统之间的一个命令解释器. 2.shell命名的使用 ls :查看当前目录的信息,list . ...
- hadoop-0.20.2伪分布式安装简记
1.准备环境 虚拟机(redhat enterprise linux 6.5) jdk-8u92-linux-x64.tar.gz hadoop-0.20.2.tar.gz 2.关闭虚拟机的防火墙,s ...
- RHEL7.2安装及配置实验环境
截图太多了,就不一一上传了,请查看这个分享网址 http://pan.baidu.com/s/1kVeYANH 什么时候博客更新下能直接把图一下复制进来多好!省事.
- P1116 车厢重组
题目描述 在一个旧式的火车站旁边有一座桥,其桥面可以绕河中心的桥墩水平旋转.一个车站的职工发现桥的长度最多能容纳两节车厢,如果将桥旋转180度,则可以把相邻两节车厢的位置交换,用这种方法可以重新排列车 ...
- ios 苹果原生系统定位 CLLocationManager
首先要干这些事 下面的方法亲测可用 ------------------------------------------------------------ DNLogFUNC //初始化位置管理对象 ...
- java 之 插入排序
思想:将一个数组分成两组,左边那组始终有序,每次取右边那组插入到左边适当的位置,保证左边有序,当右边没有需要插入的数据的时候,整个数组是有序的.插入排序是稳定排序. 注:此图引用自https://ww ...
- ubuntu下php安装目录说明
php当前安装目录 /etc/php5/ apache2: 采用APACHE2HANDLER启动 cli: 采用命令启动 fpm php-fpm启动 fpm2 php-fpm多实例 m ...
- Selenium私房菜系列--总章
前言 在这段期间,我一直在找关于服务器的端测试方案,自动化工具等等,无意间我发现了Selenium这个工具.在试用一段时间后,觉得Selenium确实是一个很不错的Web测试工具.在和强大的QTP比较 ...
- dzzoffice网盘应用有着最强大的团队、企业私有网盘功能,并且全开源无功能限制。
企业,团队多人使用dzzoffice的网盘应用,灵活并且功能强大. 支持个人网盘,机构部门,群组,并可根据使用情况开启关闭.例如可只开启群组功能. 可通过后缀,标签自定义类型进行快捷筛选 全面 ...
- dumpkeys - 转储显示键盘翻译表
总览 (SYNOPSIS) dumpkeys [ -hilfn1 -Sshape -ccharset --help --short-info --long-info --numeric --full- ...