Python 和 Elasticsearch 构建简易搜索
Python 和 Elasticsearch 构建简易搜索
作者:白宁超
2019年5月24日17:22:41
导读:件开发最大的麻烦事之一就是环境配置,操作系统设置,各种库和组件的安装。只有它们都正确,软件才能运行。如果从一种操作系统里面运行另一种操作系统,通常我们采取的策略就是引入虚拟机,比如在 Windows 系统里面运行 Linux 系统。这种方式有个很大的缺点就是资源占用多、冗余步骤多、启动慢。目前最流行的 Linux 容器解决方案之一就是Docker,它最大优点就是轻量、资源占用少、启动快。本文从什么是Docker?Docker解决什么问题?有哪些好处?如何去部署实现去全面介绍。
1 ES基本介绍
1.1 概念介绍
Elasticsearch是一个基于Lucene库的搜索引擎。它提供了一个分布式、支持多租户的全文搜索引擎,它可以快速地储存、搜索和分析海量数据。Elasticsearch可以用于搜索各种文档。它提供可扩展的搜索,具有接近实时的搜索,并支持多租户。Elasticsearch至少需要Java 8。Elasticsearch是分布式的,这意味着索引可以被分成分片,每个分片可以有0个或多个副本。每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。
- 集群(Cluster):集群是一个或多个节点(服务器)的集合,它们共同保存您的整个数据,并提供跨所有节点的联合索引和搜索功能。本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic 实例。单个 Elastic 实例称为一个节点(node)。一组节点构成一个集群(cluster)。
- 节点(Node):节点是作为集群一部分的单个服务器,存储数据并参与群集的索引和搜索功能。
- 索引(Index):索引是具有某些类似特征的文档集合。索引由名称标识(必须全部小写),此名称用于在对其中的文档执行索引,搜索,更新和删除操作时引用索引。 数据管理的顶层单位就叫做 Index(索引)。它是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写。
- 文档(Document):文档是可以编制索引的基本信息单元。Index 里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。Document 使用 JSON 格式表示,同一个 Index 里面的 Document,不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。
- 分片和副本(Shards & Replicas):索引可能存储大量可能超过单个节点的硬件限制的数据。为了解决这个问题,Elasticsearch提供了将索引细分为多个称为分片的功能。创建索引时,只需定义所需的分片数即可。每个分片本身都是一个功能齐全且独立的“索引”,可以托管在集群中的任何节点上。
- 副本集很重要:它在分片/节点发生故障时提供高可用性。它允许您扩展搜索量/吞吐量,因为可以在所有副本上并行执行搜索。默认情况下,Elasticsearch中的每个索引都分配了5个主分片和1个副本,这意味着如果群集中至少有两个节点,则索引将包含5个主分片和另外5个副本分片(1个完整副本),总计为每个索引10个分片。
1.2 应用场景
- 在线网上商店,允许客户搜索您销售的产品。在这种情况下,可以使用Elasticsearch存储整个产品目录和库存,并为它们提供搜索和自动填充建议。
- 收集日志或交易数据,并分析和挖掘此数据以查找趋势,统计信息,摘要或异常。在这种情况下,您可以使用Logstash(Elasticsearch / Logstash / Kibana堆栈的一部分)来收集,聚合和解析数据,然后让Logstash将此数据提供给Elasticsearch。一旦数据在Elasticsearch中,您就可以运行搜索和聚合来挖掘您感兴趣的任何信息。
- 价格警报平台,允许精通价格的客户指定一条规则,例如“我有兴趣购买特定的电子产品,如果小工具的价格在下个月内从任何供应商降至X美元以下,我希望收到通知” 。在这种情况下,您可以刮取供应商价格,将其推入Elasticsearch并使用其反向搜索功能来匹配价格变动与客户查询,并最终在发现匹配后将警报推送给客户。
1.3 核心模块
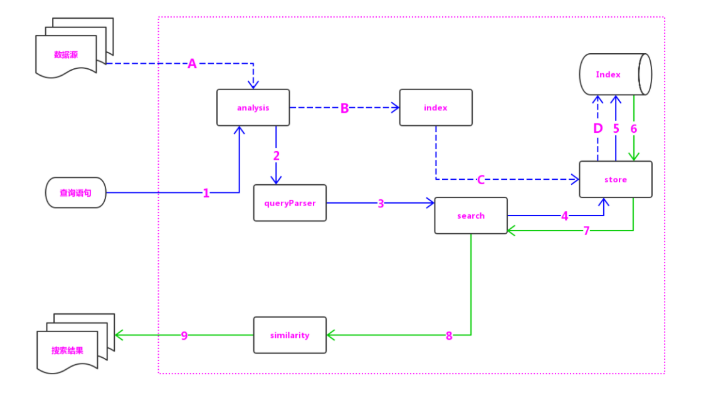
- analysis:主要负责词法分析及语言处理,也就是我们常说的分词,通过该模块可最终形成存储或者搜索的最小单元 Term。
- index 模块:主要负责索引的创建工作。
- store 模块:主要负责索引的读写,主要是对文件的一些操作,其主要目的是抽象出和平台文件系统无关的存储。
- queryParser 模块:主要负责语法分析,把我们的查询语句生成 Lucene 底层可以识别的条件。
- search 模块:主要负责对索引的搜索工作。
- similarity 模块:主要负责相关性打分和排序的实现。
1.4 检索方式
- 单个词查询:指对一个 Term 进行查询。比如,若要查找包含字符串“Lucene”的文档,则只需在词典中找到 Term“Lucene”,再获得在倒排表中对应的文档链表即可。
- AND:指对多个集合求交集。比如,若要查找既包含字符串“Lucene”又包含字符串“Solr”的文档,则查找步骤如下:在词典中找到 Term “Lucene”,得到“Lucene”对应的文档链表。在词典中找到 Term “Solr”,得到“Solr”对应的文档链表。合并链表,对两个文档链表做交集运算,合并后的结果既包含“Lucene”也包含“Solr”。
- OR:指多个集合求并集。比如,若要查找包含字符串“Luence”或者包含字符串“Solr”的文档,则查找步骤如下:在词典中找到 Term “Lucene”,得到“Lucene”对应的文档链表。在词典中找到 Term “Solr”,得到“Solr”对应的文档链表。合并链表,对两个文档链表做并集运算,合并后的结果包含“Lucene”或者包含“Solr”。
- NOT:指对多个集合求差集。比如,若要查找包含字符串“Solr”但不包含字符串“Lucene”的文档,则查找步骤如下:在词典中找到 Term “Lucene”,得到“Lucene”对应的文档链表。在词典中找到 Term “Solr”,得到“Solr”对应的文档链表。合并链表,对两个文档链表做差集运算,用包含“Solr”的文档集减去包含“Lucene”的文档集,运算后的结果就是包含“Solr”但不包含“Lucene”。
通过上述四种查询方式,我们不难发现,由于 Lucene 是以倒排表的形式存储的。所以在 Lucene 的查找过程中只需在词典中找到这些 Term,根据 Term 获得文档链表,然后根据具体的查询条件对链表进行交、并、差等操作,就可以准确地查到我们想要的结果。相对于在关系型数据库中的“Like”查找要做全表扫描来说,这种思路是非常高效的。虽然在索引创建时要做很多工作,但这种一次生成、多次使用的思路也是很高明的。
1.5 ES特性
- Elasticsearch可扩展高达PB级的结构化和非结构化数据。
- Elasticsearch可以用来替代MongoDB和RavenDB等做文档存储。
- Elasticsearch使用非标准化来提高搜索性能。
- Elasticsearch是受欢迎的企业搜索引擎之一,目前被许多大型组织使用,如Wikipedia,The Guardian,StackOverflow,GitHub等。
- Elasticsearch是开放源代码,可在Apache许可证版本
2.0下提供。
1.6 ES优点
- Elasticsearch是基于Java开发的,这使得它在几乎每个平台上都兼容。
- Elasticsearch是实时的,换句话说,一秒钟后,添加的文档可以在这个引擎中搜索得到。
- Elasticsearch是分布式的,这使得它易于在任何大型组织中扩展和集成。
- 通过使用Elasticsearch中的网关概念,创建完整备份很容易。
- 与Apache Solr相比,在Elasticsearch中处理多租户非常容易。
- Elasticsearch使用JSON对象作为响应,这使得可以使用不同的编程语言调用Elasticsearch服务器。
- Elasticsearch支持几乎大部分文档类型,但不支持文本呈现的文档类型。
1.7 ES缺点
- Elasticsearch在处理请求和响应数据方面没有多语言和数据格式支持(仅在JSON中可用),与Apache Solr不同,Elasticsearch不可以使用CSV,XML等格式。
- Elasticsearch也有一些伤脑的问题发生,虽然在极少数情况下才会发生。
2 ES的安装部署
本文主要采用Win10下的Elasticsearch安装,当然Linux安装操作起来更加简便了。完成之后对python安装elasticsearch包,并实现交互案例。
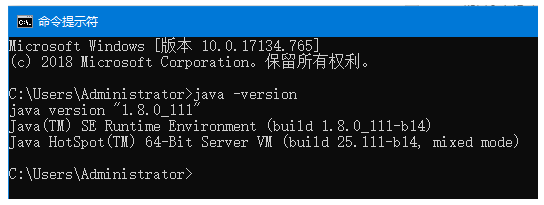
第一步:条件检查:Elasticsearch至少需要Java 8,首先需要java -version查看当前版本。
第二步:安装ES,这里采用elasticsearch-7.1.0-windows-x86_64下载地址链接: https://pan.baidu.com/s/1k5AOGpMy8uJEXtA6KoNb7g 提取码: qtmj 。
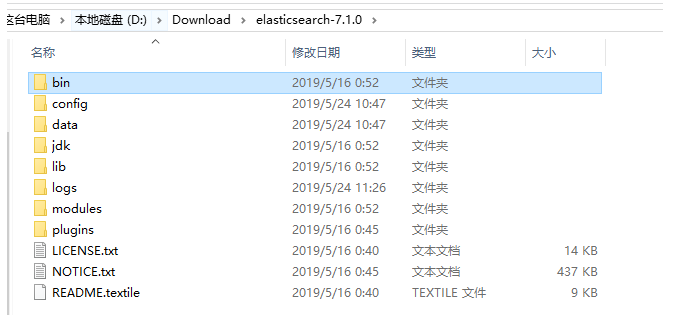
bin :运行Elasticsearch实例和插件管理所需的脚本
confg: 配置文件所在的目录
lib : Elasticsearch使用的库
data : Elasticsearch使用的所有数据的存储位置
logs : 关于事件和错误记录的文件
plugins: 存储所安装插件的地方,比如中文分词工具
work : Elasticsearch使用的临时文件,这个文件我这暂时好像没有,可以根据配置文件来 配置这些个文件的目录位置,比如上面的data,logs,
然后去运行 bin/elasticsearch(Mac 或 Linux)或者 bin\elasticsearch.bat (Windows) 即可启动 Elasticsearch 了。我们启动后发现网页并不现实信息,测试下本地网络是否联通:

发现是一般性故障,查询资料显示由于防火墙的问题,经过测试关闭”公用网络防火墙“即可:
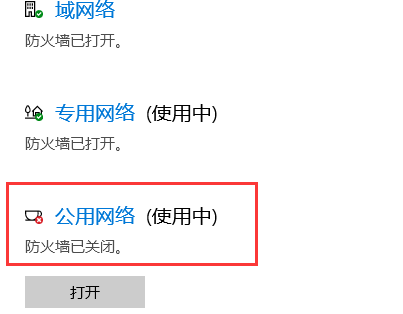
之后我们再去ping下本地IP:
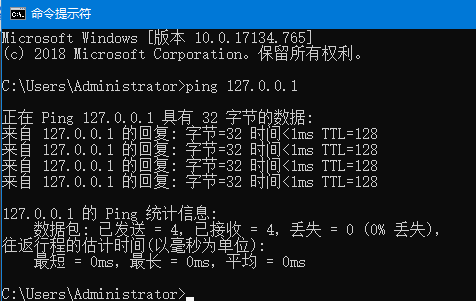
这时已经显示ping通状态,再次启动bin\elasticsearch.bat (Windows),打开http://localhost:9200/显示如下表示成功安装ES。
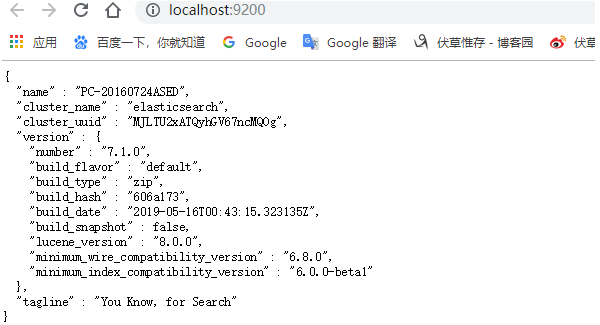
第三步:Python安装ES, 下载地址是https://www.elastic.co/downloads/elasticsearch。如果在windows下安排部署参考文章http://www.cnblogs.com/viaiu/p/5715200.html。如果是Python开发可以使用pip install elasticsearch安装。
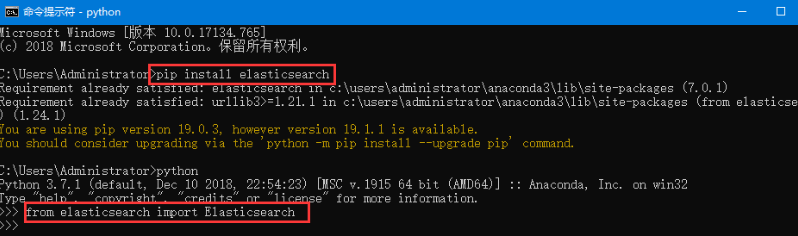
3 Python和ES构建搜索引擎
插入数据:打开python运行环境,首先导入【from elasticsearch import Elasticsearch】,然后编写插入数据的方法:
# 插入数据
def InsertDatas():
# 默认host为localhost,port为9200.但也可以指定host与port
es = Elasticsearch()
es.create(index="my_index",doc_type="test_type",id=11,ignore=[400,409],body={"name":"python","addr":'四川省'})
# 查询结果
result = es.get(index="my_index",doc_type="test_type",id=11)
print('单条数据插入完成:\n',result)
实例化Elasticsearch,其中默认为空即host为localhost,port为9200。为空也可以指定网络IP与端口。通过创建索引index和文档类别doc_type,文档id,body为插入数据的内容,其中ES支持的数据仅为JSON类型,ignore=409忽略异常。运行结果如下:

批量插入数据:上面案例我们插入一条信息,查询显示一系列参数包括索引、文档类型、文档ID唯一标识,版本号等。其中资源中包含数据信息,如果我们想插入多条信息可以参考以下代码:
# 批量插入数据
def AddDatas():
es = Elasticsearch()
datas = [{
'name': '美国留给伊拉克的是个烂摊子',
'addr': 'http://view.news.qq.com/zt2011/usa_iraq/index.htm'
},{
"name":"python",
"addr":'四川省'
}]
for i,data in enumerate(datas):
es.create(index="my_index",doc_type="test_type",
id=i,ignore=[400,409],body=data)
# 查询结果
result = es.get(index="my_index",doc_type="test_type",id=0)
print('\n批量插入数据完成:\n',result['_source'])
我们将数据放在datas列表中,如果我们数据在一个json文件中存储,也可以通过读取文本信息并保存在datas中,之后对其进行插入即可。这里面文件ID我采用枚举的序号,也可以采用随机数或者指定格式。完成所有插入之后我们选择第一条id=0的信息查询,此处查询与上文不同,我们只看文章内容可以采用result['_source']方法,结果如下:

更新数据:如果我们插入数据信息有问题,我们想去修正。可以采用update方法,这里面与我们接触的MySQL,MongoDB等SQL语句差不多。唯一注意的是我们更新数据时候采用{"doc":{"name":"python1","addr":"深圳1"}}字典模式,尤其是doc标识不能忘记,代码实现如下:
# 3 更新数据
def UpdateDatas():
es = Elasticsearch()
es.update(index="my_index",doc_type="test_type",
id=11,ignore=[400,409],body={"doc":{"name":"python1","addr":"深圳1"}})
# 更新结果
result = es.get(index="my_index",doc_type="test_type",id=11)
print('\n数据id=11更新完成:\t',result['_source']['name'])
这里我们假如只想查询更新后信息的name字段,可以采用source后面加['name']方法,为什么这么设置呢?请参看插入数据运行结果分析。

删除数据:这里面比较简单,我们指定文档的索引、文档类型和文档ID即可。
# 删除数据
def DeleteDatas():
es = Elasticsearch()
result = es.delete(index='my_index',doc_type='test_type',id=11)
print('\n数据id=11删除完成:\t')
条件查询数据:我们通过插入数据构建一个简单我数据信息,如果我们想获取索引中的所有文档可以采用{"query":{"match_all":{}}}条件查询,这里面指定关注的是使用的search方法,上文查询数据采用get方法,其实两者都是可以作为查询使用的。代码如下:
# 条件查询
def ParaSearch():
es = Elasticsearch()
query1 = es.search(index="my_index", body={"query":{"match_all":{}}})
print('\n查询所有文档\n',query1)
query2 = es.search(index="my_index", body={"query":{"term":{'name':'python'}}})
print('\n查找名字Python的文档:\n',query2['hits']['hits'][0])
我们获取索引所有文档的信息

获取文档中name为Python的信息

4 技术交流共享QQ群
【机器学习和自然语言QQ群:436303759】:
机器学习和自然语言(QQ群号:436303759)是一个研究深度学习、机器学习、自然语言处理、数据挖掘、图像处理、目标检测、数据科学等AI相关领域的技术群。其宗旨是纯粹的AI技术圈子、绿色的交流环境。本群禁止有违背法律法规和道德的言谈举止。群成员备注格式:城市-自命名。微信订阅号:datathinks
Python 和 Elasticsearch 构建简易搜索的更多相关文章
- 笔记13:Python 和 Elasticsearch 构建简易搜索
Python 和 Elasticsearch 构建简易搜索 1 ES基本介绍 概念介绍 Elasticsearch是一个基于Lucene库的搜索引擎.它提供了一个分布式.支持多租户的全文搜索引擎,它可 ...
- Elasticsearch构建全文搜索系统
目录 前言 一.安装 1.安装elasticsearch 2.启动集群cluster 3.安装管理界面elasticsearch-head 4.安装分词插件elasticsearch-analysis ...
- 分布式搜索ElasticSearch构建集群与简单搜索实例应用
分布式搜索ElasticSearch构建集群与简单搜索实例应用 关于ElasticSearch不介绍了,直接说应用. 分布式ElasticSearch集群构建的方法. 1.通过在程序中创建一个嵌入es ...
- 学习用Node.js和Elasticsearch构建搜索引擎(6):实际项目中常用命令使用记录
1.检测集群是否健康. curl -XGET 'localhost:9200/_cat/health?v' #后面加一个v表示让输出内容表格显示表头 绿色表示一切正常,黄色表示所有的数据可用但是部分副 ...
- python操作Elasticsearch (一、例子)
E lasticsearch是一款分布式搜索引擎,支持在大数据环境中进行实时数据分析.它基于Apache Lucene文本搜索引擎,内部功能通过ReST API暴露给外部.除了通过HTTP直接访问El ...
- python实现elasticsearch操作-CRUD API
python操作elasticsearch常用API 目录 目录 python操作elasticsearch常用API1.基础2.常见增删改操作创建更新删除3.查询操作查询拓展类实现es的CRUD操作 ...
- python使用get在百度搜索并保存第一页搜索结果
python使用get在百度搜索并保存第一页搜索结果 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用在意我的感受 #coding:utf-8 import ur ...
- Lucene核心--构建Lucene搜索(上篇,理论篇)
2.1构建Lucene搜索 2.1.1 Lucene内容模型 一个文档(document)就是Lucene建立索引和搜索的原子单元,它由一个或者多个字段(field)组成,字段才是Lucene的真实内 ...
- elasticsearch的rest搜索--- 查询
目录: 一.针对这次装B 的解释 二.下载,安装插件elasticsearch-1.7.0 三.索引的mapping 四. 查询 五.对于相关度的大牛的文档 四. 查询 1. 查询的官网的文档 ...
随机推荐
- SNP|RELP|genetic polymorphism|
5.3个体基因组呈现广泛变化 遗传多态性:一个基因座上存在多个等位基因(因为野生型不止一种基因)的现象,但是只有这多种等位基因满足:1.多个基因稳定存在2.基因在种群中数目大于1%时,认为该基因座多态 ...
- noip_最后一遍_2-图论部分
大体按照 数学 图论 dp 数据结构 这样的顺序 模板集 这个真的只有模板了……………… ·spfa #include<bits/stdc++.h> using namespace std ...
- [LUOGU] 1717 钓鱼
题目描述 话说发源于小朋友精心设计的游戏被电脑组的童鞋们藐杀之后非常不爽,为了表示安慰和鼓励,VIP999决定请他吃一次"年年大丰收",为了表示诚意,他还决定亲自去钓鱼,但是,因为 ...
- centos7 中安装 mysql5.6 的过程
前提是Centos的环境是好的,并且相关的软件包已经安装好. 1.创建用户,并修改创建的数据目录的属主 [root@bogon ~]# useradd -M mysql -s /sbin/nologi ...
- clipboard 在 vue 中的使用
简介 页面中用 clipboard 可以进行复制粘贴,clipboard能将内容直接写入剪切板 安装 npm install --save clipboard 使用方法一 <template&g ...
- Linux 磁盘相关
挂载文件系统 mount mount [-t fstype] filesystem dir ##mount /dev/sdb /data 卸载文件系统 umount umount /dev/sdb u ...
- Web框架之Django_09 重要组件(Django中间件、csrf跨站请求伪造)
摘要 Django中间件 csrf跨站请求伪造 一.Django中间件: 什么是中间件? 官方的说法:中间件是一个用来处理Django的请求和响应的框架级别的钩子.它是一个轻量.低级别的插件系统,用于 ...
- LeetCode01--回文数
''' 判断一个整数是否是回文数.回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数. 示例 1: 输入: 121 输出: true 示例 2: 输入: -121 输出: false 解释: ...
- Apache 流框架 Flink,Spark Streaming,Storm对比分析(1)
此文已由作者岳猛授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 1.Flink架构及特性分析 Flink是个相当早的项目,开始于2008年,但只在最近才得到注意.Flink是 ...
- Oc_总结
1.定义类: @interface 类名 : 父类 @end 2.使用:(冒号)表示继承一个类 Student : NSObject 3.使用()定义一个Catagory(类别) * 作用:在不改变原 ...