HubbleDotNet引擎查询技术
系统简介
HubbleDotNet 是一个基于.net framework 的开源免费的全文搜索数据库组件。开源协议是 Apache 2.0。HubbleDotNet提供了基于SQL的全文检索接口,使用者只需会操作SQL,就可以很快学会使用HubbleDotNet进行全文检索。 HubbleDotNet可以实现全文索引和查询、多域检索和排序、分组统计、消重、分类、聚类、多表关联查询等等一系列全文检索和数据挖掘功能。 HubbleDotNet提供开放的数据库适配器接口,可以和各种数据库完美整合,为各种数据库系统附加全文检索和数据挖掘功能。 HubbleDotNet设计了较为完善的并发控制程序,数据的增删改查可以多线程同时并发进行,没有任何冲突。HubbleDotNet还进行了缓存和内存管理设计,可以帮助用户最大限度的提高查询的效率。HubbleDotNet力争在未来的几年内超过Lucene.net成为.net开发环境中最受欢迎的全文检索组件。
相关资源
Hubble.net 的相关资源
0.9 版本功能列表
1. 索引
2. 查询
3. 删除
4. 更新
5. 基于 SQL 的SQLClient 接口
6. 索引级别缓存
7. 查询级别缓存
8. 数据级别缓存
9. 多字段排序
10. 全文和元数据组合查询
11. 关键字权重指定
12. 字段权重指定
13. 记录权重指定
14. 索引自动优化
15. 索引手工优化
16. 自定义分词器
17. 自定义数据库适配器
18. 系统存储过程
19. 查询分析器
20. 建表,删表
21. 基于数据库现有表或视图创建索引
22. 和数据库现有表或视图索引同步
23. 分组统计
24. Match, Contains, Like 三种查询方式
25. 拆离和附加 (备份和恢复)索引
物理视图
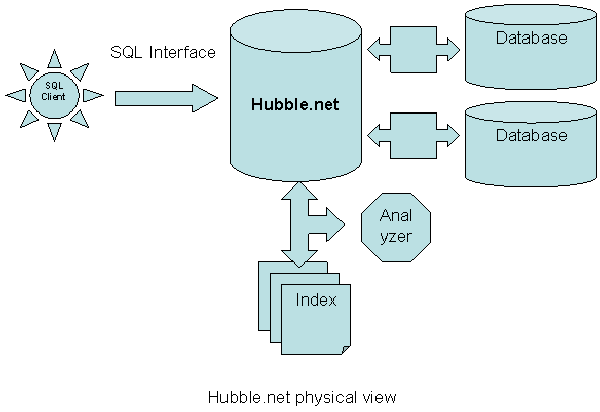
HubbleDotNet 将全文搜索和关系数据库整合到一起,通过SQL语句对数据库中的数据进行全文和关系查询。HubbleDotNet组件本身负责对全文数据进行倒排索引,并将索引存储到表所指定的目录下,数据的存储则由和Hubble.net 关联的关系数据库完成。HubbleDotNet提供了一个 IDBAdpter 接口,用户可以根据这个接口实现自定义的数据库适配。如何添加自定义的数据库适配器,将在存储过程一节中阐述。建立倒排索引时需要对输入的全文文本进行分词,HubbleDotNet为用户提供了一个 IAnalyzer 接口来完成自定义的分词器。如何添加自定义的分词器,将在存储过程一节中阐述。HubbleDotNet在安装后以一个系统服务的形式存在。 Hubble.net 提供一个 Hubble.SQLClient 组件来和HubbleDotNet的系统服务进行交互,SQLClient 的接口和Ado.net 中的SqlClient接口类型,具体将在SQLClient一节中阐述。
逻辑视图
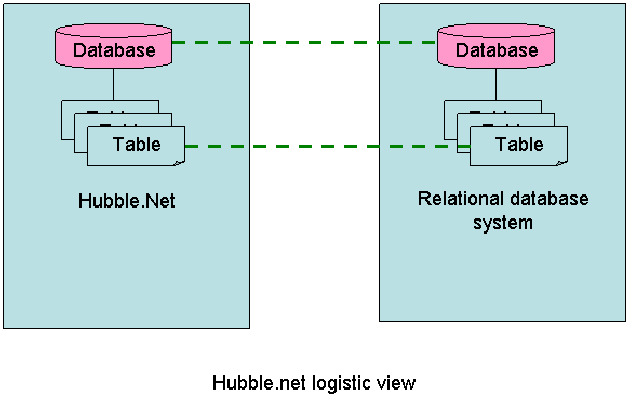
HubbleDotNet 和 关系数据库一样,存在数据库和数据库表的概念。Hubble.net 的数据库和数据表只是提供一个和对应关系数据库的映射描述关系,并不存在数据库和数据表的实体。用户在通过SQL 语句操作Hubble.net 的数据库和数据表是,Hubble.net 将自动和对应的关系数据库实体进行关联,从用户侧看,Hubble.net就像一个数据库实体。
HubbleDotNet负责建立文本字段的倒排索引和Untokenized字段的单值索引。关系数据库负责建立B+树索引。如果查询语句不包括对全文字段的搜索,则直接转发给数据库利用数据库的索引进行查询。
三级缓存
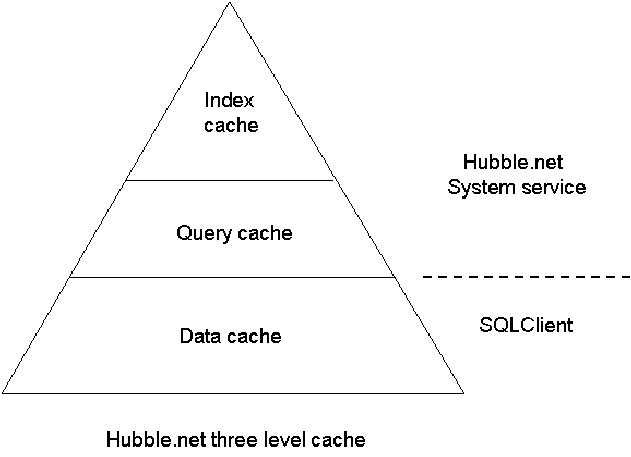
如上图所示,HubbleDotNet提供三种级别的缓存方案。
Index cache :索引级别缓存用于缓存倒排索引和单值索引。这种缓存为系统自动管理,不能关闭。索引级别缓存会自动监控数据的增删改,并进行相应修改。
Query cache :查询级别缓存对查询的条件进行缓存,Hubble.net 系统服务会将不同查询条件对应的文档ID(DocId)缓存下来,下次查询时直接从缓存中获取符合条件的文档ID,不再访问低级别缓存或索引。和索引级别缓存不同的是,当表的数据发生变化时,查询级别缓存将会失效,需要重新缓存。
Data cache :数据级别缓存运行在客户端,客户端查询得到的数据被缓存下来,下次查询时将从数据缓存中直接获取数据,而不再到Hubble.net 系统服务中去获取数据。和查询级别缓存一样,表的数据发生变化时,数据级别缓存将会失效,需要重新缓存。
并发控制
HubbleDotNet设计了非常完善的并发控制机制,用户的增删改查可以同时进行,不会存在任何冲突。
内存管理
HubbleDotNet 以系统服务存在,不会像Lucene那样和应用程序共用内存。HubbleDotNet设计了一套内存管理机制,用户可以设置最大内存使用数量,一旦 HubbleDotNet使用内存超过这个数量,HubbleDotNet就会自动启动内存整理程序,将一些不经常使用的缓存从内存中清理掉以腾出更多的内存空间给用户。用户可以通过 SP_CONFIGURE 存储过程来查看和管理内存。
HubbleDotNet 与 Lucene.net 的功能对比
|
功能 |
Lucene.net | HubbleDotNet |
| 按词条搜索—TermQuery | 支持 | 支持 |
| “与或”搜索—BooleanQuery | 支持 | 支持 |
| 在某一范围内搜索—RangeQuery | 支持 | 支持 |
| 使用前缀搜索—PrefixQuery | 支持 | 支持 |
| 多关键字的搜索—PhraseQuery | 支持 | 支持 |
| 相近词语的搜索—FuzzyQuery | 支持 | 通过分词来实现,EnglishAnalyzer 可以完成类似功能 |
| 使用通配符搜索—WildcardQuery | 支持 | 通过分词来解决,盘古分词的最新版本已经提供类似解决方案 |
| Contains-多个关键字之间按与方式匹配 | 不支持 | 支持 |
| Like-类似数据库的Like '%xx%' | 不支持 | 支持 |
| 更新数据-Update | 需要删除后再添加 | 直接调用 Update 语句完成,如果只更新非全文字段,不重新索引,速度非常快 |
| 增量索引 | 支持 | 支持 |
| 不同字段指定不同分词器 | 不支持 | 支持 |
| 分组统计-Group by | 不支持 | 支持 |
| 与关系数据库关联 | 不支持 | 可以单表管理,多表关联,基于现有表或视图创建索引 |
| 并发控制 | 读、写、优化等不能同时进行 | 读、写、优化等可以同时进行 |
| 内存管理 | 不支持 | 可设定最大内存使用阈值,到这个阈值后会自动将不常访问的缓存清理掉 |
| 重建索引(数据不动,只重建全文索引) | 不支持 | 支持 |
| 多表关联查询 | 不支持 | 0.9 版本部分支持 |
| 消重-Distinct | 不支持 | 1.0 版本提供支持 |
| 分类,聚类等数据挖掘功能 | 不支持 | 后续版本开发 |
HubbleDotNet引擎查询技术的更多相关文章
- 海胜专访--MaxCompute 与大数据查询引擎的技术和故事
摘要:在2019大数据技术公开课第一季<技术人生专访>中,阿里巴巴云计算平台高级技术专家苑海胜为大家分享了<MaxCompute 与大数据查询引擎的技术和故事>,主要介绍了Ma ...
- 万亿级日志与行为数据存储查询技术剖析(续)——Tindex是改造的lucene和druid
五.Tindex 数果智能根据开源的方案自研了一套数据存储的解决方案,该方案的索引层通过改造Lucene实现,数据查询和索引写入框架通过扩展Druid实现.既保证了数据的实时性和指标自由定义的问题,又 ...
- 万亿级日志与行为数据存储查询技术剖析——Hbase系预聚合方案、Dremel系parquet列存储、预聚合系、Lucene系
转自:http://www.infoq.com/cn/articles/trillion-log-and-data-storage-query-techniques?utm_source=infoq& ...
- 让AI简单且强大:深度学习引擎OneFlow技术实践
本文内容节选自由msup主办的第七届TOP100summit,北京一流科技有限公司首席科学家袁进辉(老师木)分享的<让AI简单且强大:深度学习引擎OneFlow背后的技术实践>实录. 北京 ...
- Hibernate 查询技术
转载: http://blog.csdn.net/u014078192/article/details/24986475 一.Hibernate的三种查询方式(掌握) Hibernate中提供了三种查 ...
- es的scoll滚动查询技术
如果一次性要查出来比如10万条数据,那么性能会很差,此时一般会采取用scoll滚动查询,一批一批的查,直到所有数据都查询完处理完 使用scoll滚动搜索,可以先搜索一批数据,然后下次再搜索一批数据,以 ...
- SQL注入原理-手工联合注入查询技术
实验报告记录 得到实验结果
- 《parsing techniques》中文翻译和正则引擎解析技术入门
http://parsing-techniques.duguying.net/ (中文版) https://swtch.com/~rsc/regexp/ https://blog.csdn.net/m ...
- 微博大数据即席查询(OLAP)引擎实践
前言 适用于 即席查询 场景的开源查询引擎有很多,如:Elasticsearch.Druid.Presto.ClickHouse等:每种系统各有利弊,有的擅长检索,有的擅长统计:实践证明,All In ...
随机推荐
- jenkins在linux环境搭建需要用到的linux命令
需要用到的linux命令如下: 服务器jdk1.7/usr/java/jdk1.7.0_80 jdk1.8/home/hujb/javaJDK/jdk1.8.0_171保存文件时用 : w ! sud ...
- URAL 1277 Cops and Thieves
Cops and Thieves Time Limit: 1000ms Memory Limit: 16384KB This problem will be judged on Ural. Origi ...
- 亲历dataguard的一些经验问答题
问题1:是否log_archive_dest_n=service中进程使用lgwr时(如log_archive_dest_2='service=DBSTD LGWR SYNC'),备库就一定要建立st ...
- 【BZOJ1061】志愿者招募(单纯形,对偶性)
题意: 这个项目需要N 天才能完成,其中第i 天至少需要 Ai 个人. 布布通过了解得知,一共有M 类志愿者可以招募.其中第i 类可以从第Si 天工作到第Ti 天,招募费用 是每人Ci 元.新官上任三 ...
- Java开发一些小的思想与功能小记(二)
1.用if+return代替复杂的if...else(if+return) public static void test1(String str) { if ("1".equal ...
- mysql 获取所有的数据库名字
mysql 获取所有的数据库名字 一.如果使用的是mysqli: $con = @mysqli_connect("localhost", "root", &qu ...
- hdu6080(最小环)
题目 http://acm.hdu.edu.cn/showproblem.php?pid=6080 分析 很妙的思路,将里面的点集当作A,将外面的点集当作B 然后O(n^2)枚举两两B点,设一个是u, ...
- HDU 4115 Eliminate the Conflict(2-sat)
HDU 4115 Eliminate the Conflict pid=4115">题目链接 题意:Alice和Bob这对狗男女在玩剪刀石头布.已知Bob每轮要出什么,然后Bob给Al ...
- 为RAC私有网络配置网卡Bonding
在RAC的安装部署过程中.并不不过简单的安装完毕了事.整个安装过程要考虑可能出现的单点问题,当中比較重要的是私有网络. 私有网络是RAC节点间通信的通道.包含节点间的网络心跳信息.Cache fusi ...
- 有关java构造器的笔记
当程序中首次出现使用一个类A时, 无论是使用A的静态成员还是创建一个对象(声明一个A类对象不算), 那么类加载器就会首先对A进行加载, 在对A进行加载的过程中, 如果A有一个extends的父类B, ...