Python—一个简单搜索引擎索引库
因为课业要求,搭建一个简单的搜索引擎,找了一些相关资料并进行了部分优化(坑有点多)
一.数据
数据是网络上爬取的旅游相关的攻略页面

这个是travels表,在索引中主要用到id和url两个字段。
页面中文文章内容的爬取用了newspaper3k这个包(如果页面里面文章字数过多,需要设置一下超时时间,不然会报错)
def article(url):
try:
a=Article(url,language="zh")
a.download()
a.parse()
return a.text
except:
pass
return -1
如果报错不退出程序,返回-1
二.分词
文章爬取下来之后的分词有两种模式,全文分词,分词后提取关键词
全文分词
def cutworf(url):
text=article(url)
seg_list=jieba.cut_for_search(text)
return seg_list
如果有很多的页面需要爬取,全文分词的速度会很慢,所以我用了关键词分词
jieba有提供两个关键词分词的方式 TF-IDF以及TextRank算法,在这里我不多详细的说明两个算法的区别。在经过分词结果的比较后,我选择了TF-IDF。
textrank = analyse.textrank
tfidf = analyse.extract_tags
def keyword(url): text =article(url)
if text==-1:
return -1
else:
# 基于TF-IDF算法进行关键词抽取
keywords = tfidf(text)
#print ("keywords by tfidf:")
# 输出抽取出的关键词
#for keyword in keywords:
#print (keyword + "/")
return keywords
三.建立索引
建立索引的数据结构,我参考了https://blog.csdn.net/qq_27483535/article/details/53149021这位博主的文章
创建3个链表类型,3个节点类型(括号中表示)。
Linklist(Node):对每一个网页分词后,将词加入此链表。
Weblist(Web):把网页按照所拥有的词加入词链表,接在词的后面。
Resultlist(Result):搜索结果加入此链表。
设定停用词
ignorewords=set(['的','但是','然而','能','在','以及','可以','使','我','我们','大家','高兴','啊','哦'])
停用词可以根据文章进行添加
把分词加入链表
def index(url,count):
#words=cutworf(url)
keys=keyword(url)
if keys==-1:
return -1
dickey=list(keys)
#dicn=list(words)
# for i in range(len(dicn)):
# word = dicn[i]
# if word in ignorewords: continue
# if ll.getlength() == 0:
# wl = linklist.WebList()
# wl.initlist(count)
# ll.initlist(word, wl)
#
# if ll.getlength() > 0:
# i = ll.index(word)
# if i == -1:
# wl = linklist.WebList()
# wl.initlist(count)
# ll.append(word, wl)
# # print(word)
# if i != -1:
# j = ll.getwh(i).index(count)
# if j == -1:
# ll.getwh(i).append(count) for i in range(len(dickey)):
word = dickey[i]
if word in ignorewords: continue
if kl.getlength() == 0:
wl = linklist.WebList()
wl.initlist(count)
kl.initlist(word, wl) if kl.getlength() > 0:
i = kl.index(word)
if i == -1:
wl = linklist.WebList()
wl.initlist(count)
kl.append(word, wl)
# print(word)
if i != -1:
j = kl.getwh(i).index(count)
if j == -1:
kl.getwh(i).append(count)
return 1
注释掉的部分是全文分词
最后就是遍历链表,加入索引库

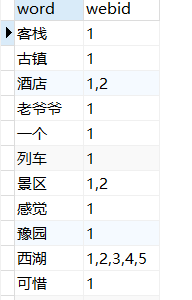
对14000多条url进行处理大概花费25个小时
建议放到服务器上运行,用nohup命令,可以在关闭远程连接后让程序继续运行。会自动生成nohup.out文件,报错输出结果什么的可以在里面看到。
四.源代码
https://github.com/zucc31701019/SearchIndex
五.一些坑
这些运行时间很长的程序一定要加异常处理!!!不然运行一半报错了又要重头开始...
连接数据库不要在还没用到的时候连,在用之前再连接。我在分词之前连了数据库,然后运行 20多个小时以后,链表处理完了...数据库链接失效报错...因为连接之后太长时间没有进行操作,数据库会断开连接。
Python—一个简单搜索引擎索引库的更多相关文章
- C 封装一个通用链表 和 一个简单字符串开发库
引言 这里需要分享的是一个 简单字符串库和 链表的基库,代码也许用到特定技巧.有时候回想一下, 如果我读书的时候有人告诉我这些关于C开发的积淀, 那么会走的多直啊.刚参加工作的时候做桌面开发, 服务是 ...
- C 封装一个简单二叉树基库
引文 今天分享一个喜欢佩服的伟人,应该算人类文明极大突破者.收藏过一张纸币类型如下 那我们继续科普一段关于他的简介 '高斯有些孤傲,但令人惊奇的是,他春风得意地度过了中产阶级的一生,而 没有遭受到冷 ...
- python -----一个简单的小程序(监控电脑内存,cpu,硬盘)
一个简单的小程序 用函数实现!~~ 实现: cpu 使用率大于百分之50 时 , C 盘容量不足5 G 时, 内存 低于2G 时. 出现以上其中一种情况,发送自动报警邮件! 主要运用 到了两个 模 ...
- python的一个简单日志记录库glog的使用
一. glog的简介 glog所记录的日志信息总是记录到标准的stderr中,即控制台终端. 每一行日志记录总是会添加一个谷歌风格的前缀,即google-style log prefix, 它的形式如 ...
- C 构造一个 简单配置文件读取库
前言 最近看到这篇文章, json引擎性能对比报告 http://www.oschina.net/news/61942/cpp-json-compare?utm_source=tuicool 感觉技术 ...
- python一个简单的打包例子
最近写了一些工具,想到分享给同事时好麻烦,并且自己每次用也是需要打开pycharm这些工具,感觉很麻烦,因此想到打包,网上有些例子,照做后又摸索很久方成,索性记录一下,以备不时之需. 主要参考:htt ...
- 一个简单搜索引擎的搭建过程(Solr+Nutch+Hadoop)
最近,因为未来工作的需要,我尝试安装部署了分布式爬虫系统Nutch,并配置了伪分布式的Hadoop来存储爬取的网页结果,用solr来对爬下来的网页进行搜索.我主要通过参考网上的相关资料进行安装部署的. ...
- Parallel Python——一个简单的分布式计算系统
如何建立一个高速的分布式计算平台?Parallel python此目的. Parallel Python(http://www.parallelpython.com/content/view/15/3 ...
- Python——一个简单的进度条的实现
import math def process_bar(total_work,work_index,length): times = total_work / length # 长度倍数,用来缩放或扩 ...
随机推荐
- 关于PS切图
现在前端项目中碰到越来越多的图片处理问题,虽然找自己公司UI小哥哥小姐姐可以解决,但是每次都找不仅要看别人有没有时间,更得看人家脸色 唉,自己摸索着来吧(多图,流量党请注意切换WiFi): 通常切图的 ...
- CF1324A Yet Another Tetris Problem 题解
原题链接 简要题意: 再简要一波: 每次可以把一个数增加 \(2\),问最后能不能让所有数相等.(也就是抵消掉) 什么?题意变成这样子还做个啥? 你会发现,必须所有数的奇偶性都相同,才可以:反之就不可 ...
- 动态规划-区间dp-Palindrome Removal
2019-11-09 10:31:09 问题描述: 问题求解: n = 100,典型的O(n ^ 3)的动规问题.一般来说这种O(n ^ 3)的问题可以考虑使用区间dp来解决. 区间dp是典型的三层结 ...
- java获取近几天的日期
最近在写接口的时候老遇见从mysql中获取近几天数据的需求,获取日期这块不是很熟,网上看了很多但是代码量都太大,还是问了下别人,写了三行代码就解决了,不多说 贴代码了 下面是我获取近十天,每天的日期: ...
- C# 录音和播放录音-NAudio
在使用C#进行录音和播放录音功能上,使用NAudio是个不错的选择. NAudio是个开源,相对功能比较全面的类库,它包含录音.播放录音.格式转换.混音调整等操作,具体可以去Github上看看介绍和源 ...
- 一篇漫画故事带你理解透HTTPS(下)
上下集知识点总结: 前情提要: 蝙蝠纪元,疫情之下.二丫欲访问京东购物,不料弹出安全提示,遂找二毛一探究竟.二毛一顿排查后,开始用通俗易懂的语言深入浅出的向二丫解释 HTTP作用及优缺点.HTTPS的 ...
- centos7中安装redis
http://www.open-open.com/lib/view/open1426468117367.html https://www.cnblogs.com/cndavidwang/p/64294 ...
- [noip模拟]画展<队列的基础知识>
Description 博览馆正在展出由世上最佳的M位画家所画的图画.人们想到博览馆去看这几位大师的作品.可是,那里的博览馆有一个很奇怪的规定,就是在购买门票时必须说明两个数字,a和b,代表要看展览中 ...
- MATLAB 随机过程基本理论
一.平稳随机过程 1.严平稳随机过程 clc clear n=0:1000; x=randn(1,1001); subplot(211),plot(n,x); xlabel('n');ylabel(' ...
- html前端之基础篇
HTML介绍 Web服务本质 import socket sk = socket.socket() sk.bind(("127.0.0.1", 8080)) sk.listen ...