Python3.5学习之旅——day4
本节内容
1、装饰器
2、迭代器与生成器
3、内置方法
4、软件目录结构规范
一、装饰器
装饰器是一个用来装饰其他函数的工具,即为其他函数添加附加功能,其本质就是函数。
装饰器需要遵循的以下两个原则:
1、若要新增一个功能,就不能再修改源代码,即不能再修改被装饰函数的源代码。
2、不能修改被装饰函数的调用方式。
实现装饰器的知识储备:
1、函数即变量。
2、高阶函数。
3、函数嵌套。
即要想实现装饰器,首先应对以上三条知识有一定了解。
一、函数即变量
首先我们来简单介绍一下函数即变量这个概念。我们举一个简单的例子来说明:
def bar():
print('in the bar')
def foo():
print('in the foo')
bar()
foo()
代码运行结果如下:

现在大家想象一下,如果把函数bar和函数foo的位置调换一下,还能运行吗?或者说运行结果还是一样吗?
我们试验一下:
def foo():
print('in the foo')
bar()
def bar():
print('in the bar')
foo()
运行结果还是一样。
这说明在python中函数可看做是一个变量,定义一个函数与定义一个变量x并无二致,所以上述代码调换位置之后还是可以运行的。
二、高阶函数
在写一个装饰器函数时,我们也会用到高阶函数这个概念,它的主要思想就是把一个函数名当做实参传给另一个函数,以实现在不修改要装饰程序的源代码的情况下为其添加新功能的作用。下面我们举一个简单的例子进行说明。
def bar():
print('in the bar')
def test1(func):
print(func) #打印函数func的内存地址
func() #调用函数func
return (func) #返回函数func的内存地址
print(test1(bar)) #将函数bar作为实参传给func
上例通过函数test1来调用函数bar,我们可以看到代码运行结果如下:

上面是一个简单的高阶函数的例子,大家可以简单看一下结构,下面我们介绍一个具备简单功能的高阶函数的代码,如下:
import time
def bar():
time.sleep(3) #bar函数实现延迟三秒输出的功能
print('in the bar')
def test(func):
start_time=time.time()
func()
end_time=time.time()
print('the func run time is %s'%(end_time-start_time)) #为func函数添加一个计算函数执行时间的功能
return func #返回函数func的内存地址
bar=test(bar)
bar()
代码执行结果如下:

我们可以看到通过高阶函数test,我们实现了为bar函数添加计算函数执行时间的功能,并且,通过把函数赋值给变量bar,我们实现了不改变原函数调用方式的前提下增加新功能的作用。
这既是装饰器的核心所在。
三、嵌套函数
在这一节我们介绍嵌套函数,函数的嵌套在装饰器中也发挥着非常重要的作用,示例如下:
def foo():
print('in the foo')
def bar():
print('in the bar')
bar()
foo()
代码执行结果如下:
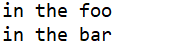
通过上述例子我们可以直观的看到局部作用域和全局作用域的访问顺序:先外后里。
四、装饰器
通过之前的热身,现在我们自己动手来写一个装饰器。
假设刚开始我们有两个函数test1和test2,我们想通过装饰器来添加一个计算函数运行时间的新功能,代码如下:
import time def timmer(func):
def deco(*args,**kwargs): #这里用到参数组*args和**kwargs是针对可能出现func函数的形参个数不固定的情况而设定的
start_time=time.time()
func(*args,**kwargs)
end_time=time.time()
print('the func run time is %s'%(end_time-start_time)) #计算函数func实际运行时间
return deco @timmer #test1=timmer(test1)
def test1():
time.sleep(3)
print('in the test1')
@timmer #test2=timmer(test2)
def test2(name):
print('test2:',name) test1() #因之前@timmer操作,这里实际调用的是deco
test2('abcd') #同理,这里调用的也是deco
这里,大家需要格外注意的是为了简洁,python中可以用@timmer来代替test1=timmer(test1),也就是上面高阶函数讲到的不改变函数调用方式。
代码运行结果如下:
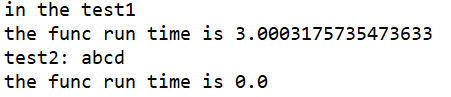
我们可以看到装饰器圆满完成了“装饰”的功能。
学习完上述简单的装饰器程序,我们再挑战一下高难度的——我们用装饰器来写一个为某些网站设置登陆界面的代码,具体如下:
user,passwd='kobe','' #初始化用户名和密码 def auth(func):
def wrapper(*args,**kwargs):
username=input('username:').strip()
password=input('password:').strip()
if user==username and passwd==password: #验证用户名和密码是否正确
print('\033[32;1muser has passed authentication\033[0m')
res=func(*args,**kwargs)
print('--after authentication')
return res
else:
exit('\033[31;1minvalid username or password\033[0m') #错误提示
return wrapper def index():
print('welcome to index page')
@auth
def home():
print('welcome to home page')
return 'from home'
@auth
def bbs():
print('welcome to bbs page') index()
print(home())
bbs()
代码运行结果如下:
首先进入一个home用户登录界面,用于输入用户名和密码:

若输入错误的用户名和密码,则有:

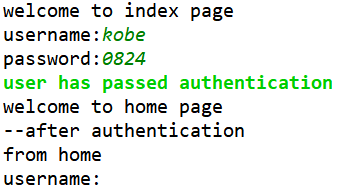
若输入正确的用户名和密码,则会显示欢迎登录home界面,并进入登录下一个bbs界面时所需输入用户名和密码的界面,如下:
我们再输入之前的正确的用户名和密码,则会进入欢迎登录bbs界面的相关信息,如下:
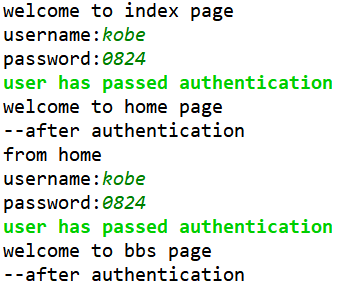
以上我们就用装饰器实现了为某些网站设置登陆界面的功能。
二、迭代器与生成器
一、列表生成式
在学习迭代器前我先向大家介绍一下列表生成式。
假如我们想要输出0到20间所有的偶数,我们可以用列表生成式如下:
>>>a=[i*2 for i in range(11)]
>>>a
[0,2,4,8,10,12,14,16,18,20]
我们可以看到,通过列表生成式我们可以直接创建一个列表。但是,受到内存限制,列表的容量肯定是有限的。而且创建一个包含100个元素的列表不仅占用很大的存储空间,而且如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间就白白浪费啦。所以,如果列表元素可以按照算法推算出来,name我们是否可以在循环过程中不断推算出后续的元素呢?这样的话就不用创建一个完整的list,从而节省大量的空间。在python中,这种一边循环一边计算的机制称为生成器(generator)。
二、生成器
若我们想用生成器来输出0到20间所有的偶数,我们将上述列表生成式的中括号 [ ] 换成小括号 ( ) 即可,代码如下:
>>>a=(i*2 for i in range(11))
>>>a
<generator object <genexpr> at 0x0000027EAA3FE410>
我们可以看到,当我们按照之前列表生成式的方式来输出元素时,却提示创建了一个生成器generator——<generator object <genexpr> at 0x0000027EAA3FE410>。
那么,若我们想要输出生成器中的元素时应该怎么办呢?这里就要用到next ( ) 方法,如下:
>>>a=(i*2 for i in range(11))
>>>a
<generator object <genexpr> at 0x0000027EAA3FE410>
>>>a.__next__()
0
>>>a.__next__()
2
>>>a.__next__()
4
从上述的调用过程我们可以看到,只有在调用时才会生成相应的数据,,这样也就能节省大量的空间。而且注意的是,我们在调用生成器中的元素用到next()方法时,只能不断地向下一级生成数据而不能返回上一级。
以上我们只是举了一个简单的生成偶数的例子,若要推算的算法比较复杂,还可以用到函数。比如我们想要生成一个Fibonacci数列,
注:Fibonacci数列的定义可参见:https://baike.baidu.com/item/%E6%96%90%E6%B3%A2%E9%82%A3%E5%A5%91%E6%95%B0%E5%88%97
我们就可以用函数来完成,代码如下:
def fib(max):
n,a,b=0,0,1
while n<max:
print(b)
a,b=b,a+b
n=n+1
return 'done'
fib(10)
上述代码可以输出前十个fibonacci数列的元素,如下:

那如果我们想以生成器的形式来输出前十个fibonacci数列的元素应该怎么做呢?
其实很简单,就是把上述代码函数中的 print(b)换成 yield b,并用next()方法来输出元素即可,代码如下:
def fib(max):
n,a,b=0,0,1
while n<max:
yield b
a,b=b,a+b
n=n+1
return 'done'
f=fib(10)
print(f.__next__())
print(f.__next__())
print('-----------')
for i in f:
print(i)
代码运行结果如下:
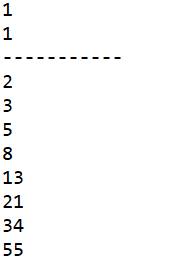
三、迭代器
可直接作用于for循环的有以下几种:
一是集合数据类型,如列表list,元组tuple,字典dict,集合set,字符串str等。
二是generator,包括生成器和带yield的generator function。
这些可以直接作用于for循环的对象统称为可迭代对象:Iterable。
我们可以使用isinstance()判断一个对象是否为Iterable对象,例如:
>>>from collections import Iterable
>>>isinstance('abc',Iterable) #判断字符串'abc'是否为Iterable对象
True
>>>isinstance({},Iterable) #判断{}是否为Iterable对象
True
而生成器不但可以作用于for循环,还可以被next函数不断调用并返回下一个值,直到最后抛出StopIteration错误,即表示无法返回下一个值了。
我们称可被next()方法调用并不断返回下一个值的对象统称为迭代器:Iterator。
以列表为例,我们可以用dir()方法来查看某对象可使用的方法:
>>> a=[,,]
>>> dir(a)
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__',
'__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__iter__', '__le__', '__len__',
'__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__',
'__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
我们可以看到列表a不能使用next()方法,故不是迭代器。
我们也可以用刚才的isinstance方法来验证:
>>> a=[1,2,3]
>>> dir(a)
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__',
'__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__iter__', '__le__', '__len__',
'__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__',
'__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
>>> from collections import Iterator
>>> isinstance(a,Iterator)
False
我们可以看到列表并不是一个迭代器。
通过上节的学习,生成器可以使用next()方法来不断调用下一个元素,那生成器应该就是一个迭代器,验证如下:
>>> from collections import Iterator
>>> isinstance((x for x in range(5)),Iterator)
True
那么,我们同样也可以使用其他方法来使非迭代器对象转化为迭代器对象,这里就需要用到iter函数,示例如下:
>>> a=[1,2,3]
>>> b=iter(a)
>>> dir(b)
['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__',
'__gt__', '__hash__', '__init__', '__iter__', '__le__', '__length_hint__', '__lt__', '__ne__', '__new__',
'__next__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__']
>>> isinstance(b,Iterator)
True
迭代器的好处是它可以表示一个无限大的数据流,如全体自然数,而list是不可能存储全体自然数的。
关于生成器和迭代器总结如下:
1、凡是可以作用于for循环的对象都是Iterable类型。
2、凡是可以作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列。
3、集合数据类型如list,dict,str,等都是Iterable类型但不是Iterator类型,不过可以通过iter函数获得一个Iterator类型对象。
三、内置方法
python解释器有许多可用的内置函数和类型,它们按字母顺序排列如下:

它们的用法可参见https://docs.python.org/3/library/functions.html?highlight=built#ascii,在这里我们就不多做介绍了。
四、软件目录结构规范
完成一个项目时,设计好软件目录结构规范是非常重要的。目录结构规范化可以更好地控制程序结构,让程序具有更高的可读性,并且可维护性更高。
下面介绍一下我的老师教给我的一种目录组织方式,如下:
假设我们要完成的项目名为foo,最方便快捷的目录结构可以写为:
Foo/
|-- bin/
| |-- foo
|
|-- foo/
| |-- tests/
| | |-- __init__.py
| | |-- test_main.py
| |
| |-- __init__.py
| |-- main.py
|
|-- docs/
| |-- conf.py
| |-- abc.rst
|
|-- setup.py
|-- requirements.txt
|-- README下面简单解释一下:
1、bin/: 存放项目的一些可执行文件,当然你可以起名script/之类的也行。
2、foo/: 存放项目的所有源代码。(1) 源代码中的所有模块、包都应该放在此目录。不要置于顶层目录。(2) 其子目录tests/存放单元测试代码; (3) 程序的入口最好命名为main.py。
3、docs/: 存放一些文档。
4、setup.py: 安装、部署、打包的脚本。
5、requirements.txt: 存放软件依赖的外部Python包列表。
6、README: 项目说明文件。
关于readme内容,我们需要注意的是,它应该包含以下五方面内容:
1、软件定位,软件的基本功能。
2、运行代码的方法,安装环境,启动命令等。
3、简要的使用说明。
4、代码目录结构说明,软件的基本原理。
5、常见问题说明。
Python3.5学习之旅——day4的更多相关文章
- Python3.5学习之旅——day2
本节内容: 1.模块初识 2..pyc是什么? 3.Python的数据类型 4.三元运算 5.进制 6.byte类型 7.数据运算 8.列表 9.元组 10.课后练习 一.模块初识 由day1的学习我 ...
- Python3.5学习之旅——day6
面向对象编程的学习 一.定义 首先跟大家介绍一位资深的程序员前辈说过的编程心得: 1.写重复代码是非常不好且低级的行为 2.完成的代码需要经常变更 所以根据以上两个心得,我们可以知道写的代码一定要遵循 ...
- Python3.5学习之旅——day5
模块初识 一.定义 在python中,模块是用来实现某一特定功能的代码集合.其本质上就是以‘.py’结尾的python文件.例如某文件名为test.py,则模块名为test. 二.导入方法 我们在这一 ...
- Python3.5学习之旅——day3
本节内容: 1.字符串操作 2.字典操作 3.集合 4.文件操作 5.字符编码与转码 6.函数与函数式编程 一.字符串操作 name='kobe' name.capitalize() 首字母大写 na ...
- Python3.5学习之旅——day1
本节内容: 1.Python介绍 2.Hello World程序 3.变量\字符编码 4.用户输入 5.if-else语句 6.循环语句 一.Python介绍 Python是一种动态解释性的强类型定义 ...
- WCF学习之旅—第三个示例之四(三十)
上接WCF学习之旅—第三个示例之一(二十七) WCF学习之旅—第三个示例之二(二十八) WCF学习之旅—第三个示例之三(二十九) ...
- Hadoop学习之旅二:HDFS
本文基于Hadoop1.X 概述 分布式文件系统主要用来解决如下几个问题: 读写大文件 加速运算 对于某些体积巨大的文件,比如其大小超过了计算机文件系统所能存放的最大限制或者是其大小甚至超过了计算机整 ...
- WCF学习之旅—第三个示例之二(二十八)
上接WCF学习之旅—第三个示例之一(二十七) 五.在项目BookMgr.Model创建实体类数据 第一步,安装Entity Framework 1) 使用NuGet下载最新版的Entity Fram ...
- WCF学习之旅—第三个示例之三(二十九)
上接WCF学习之旅—第三个示例之一(二十七) WCF学习之旅—第三个示例之二(二十八) 在上一篇文章中我们创建了实体对象与接口协定,在这一篇文章中我们来学习如何创建WCF的服务端代码.具体步骤见下面. ...
随机推荐
- 第二十四篇 玩转数据结构——队列(Queue)
1.. 队列基础 队列也是一种线性结构: 相比数组,队列所对应的操作数是队列的子集: 队列只允许从一端(队尾)添加元素,从另一端(队首)取出元素: 队列的形象化描述如下图: 队列是一种先进 ...
- 树链剖分-Hello!链剖-[NOIP2015]运输计划-[填坑]
This article is made by Jason-Cow.Welcome to reprint.But please post the writer's address. http://ww ...
- 查询数据操作:distinct
1.作用:distinct 去除重复记录.重复记录,指的是字段值,都相同的记录,而不是部分字段值相同的记录 与之相对的是all,表示所有.在MySQL中默认就是all. 2.例子: select ch ...
- SSHException: Error reading SSH protocol banner
当我在使用ssh 远程connect 另一台机器的server 时出现了错误,错误如下,起初以为是自己代码写的有问题,后来本地了一下看了跑的没问题,我就开始根据报错去查寻原因, 起初在论坛博客看到这 ...
- 09-Docker-Volumes数据管理
目录 09-Docker-Volumes数据管理 参考 数据卷类型 数据卷操作 bind数据卷 volume数据卷 tmpfs数据卷 09-Docker-Volumes数据管理 Docker Vers ...
- php将数据写入另外一个文件
有时候,为了验证PHP的运行过程或者了解代码中的变量的使用情况,需要将变量写到另外一个文件中,方便我们查看.最近也是经常用到file_put_contents这个函数,因为只是试验用,暂时还不需要考虑 ...
- thinkphp 3.2链接Oracle数据库,查询数据
ennnn,换工作了,开始用新的东西了,最近就是调用nc接口,数据库是Oracle,首先先把数据查出来,这个比较简单. 在网上看的其他的方法都是改数据库配置文件,然后需要修改tp核心的一个类文件,比较 ...
- SDNU_ACM_ICPC_2020_Winter_Practice_4th
H - Triangle 思路:用了斐波那契数列,因为数列中的任意三数都无法组成三角形,所以将1,2,3,,,n变成斐波那契数列就符合条件: #include <iostream> u ...
- HTTPS 学习
问题 数字签名的作用是什么? 为什么 HTTPS 是安全的 CA存在的动机是什么 客户端的公钥的都是一致的吗? 概述 这一节我们将要讲HTTPS,为什么说HTTPS是安全的,而HTTP是不安全的呢,这 ...
- github 创建gitlab每次提交都要输入账号
在使用git提交代码到github的时候,经常要求输入用户名和密码,类似这种: 除了在 github 上添加 SSH key 网上有这么一种解决方法:使用git提交到github,每次都要输入用户名和 ...