dataset的reparation和coalesce
/**
* Returns a new Dataset that has exactly `numPartitions` partitions, when the fewer partitions
* are requested. If a larger number of partitions is requested, it will stay at the current
* number of partitions. Similar to coalesce defined on an `RDD`, this operation results in
* a narrow dependency, e.g. if you go from 1000 partitions to 100 partitions, there will not
* be a shuffle, instead each of the 100 new partitions will claim 10 of the current partitions.
*
* However, if you're doing a drastic coalesce, e.g. to numPartitions = 1,
* this may result in your computation taking place on fewer nodes than
* you like (e.g. one node in the case of numPartitions = 1). To avoid this,
* you can call repartition. This will add a shuffle step, but means the
* current upstream partitions will be executed in parallel (per whatever
* the current partitioning is).
*
* @group typedrel
* @since 1.6.0
*/
def coalesce(numPartitions: Int): Dataset[T] = withTypedPlan {
Repartition(numPartitions, shuffle = false, planWithBarrier)
}
关于coalsece:
1、用于减少分区数量,如果设置的numPartitions超过目前实际有的分区数,则分区数保持不变。
2、窄依赖,不会发生shuffle
3、极端的coalsece可能会影响性能,比如coalsece(1),则只会在一个节点上运行单个任务。这种情况下建议使用repartition,
虽然repartition会发生shuffle,但是repartition对上游的计算,还是多分区并行执行的。
4、应用场景:多用于对一个大数据集filter以后,执行coalsece
/**
* Returns a new Dataset that has exactly `numPartitions` partitions.
*
* @group typedrel
* @since 1.6.0
*/
def repartition(numPartitions: Int): Dataset[T] = withTypedPlan {
Repartition(numPartitions, shuffle = true, planWithBarrier)
}
关于repartition:
跟coalsece一样,都是用于明确设置多少个分区,但是repartition是个宽依赖,会发生shuffle。主要注意的地方就是repartition不影响上游计算的分区
如果想极端的控制生成的文件数量来避免太多的小文件,建议repartition
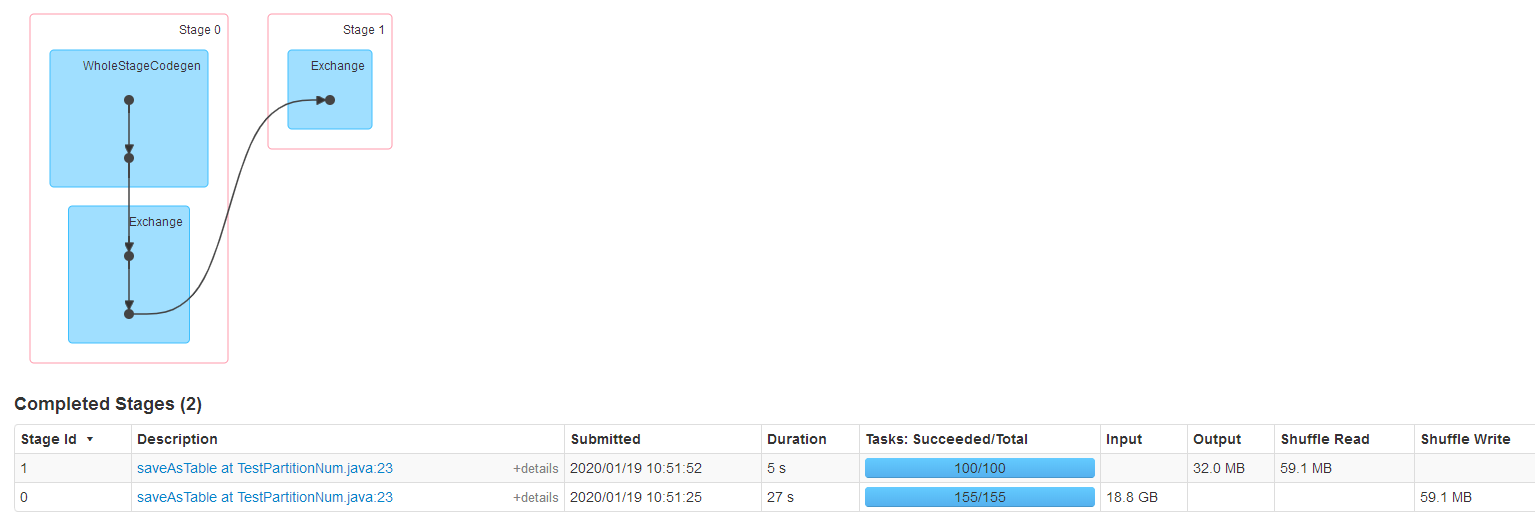
测试:对一个大表查询,将查询的结果写到一张表
coalsece测试,coalsece(100),可以看到只有一个stage,并且并行度是100

repartition测试,repartition(100),发生了shuffle。两个stage,stage0对大表指定条件查询,对应的并行度默认是大表的数据量/128M,在repartition将结果输出到表的时候并行度为我们设置的repartition(100),然后shuffle数据,最后输出
/**
* Return a new RDD that has exactly numPartitions partitions.
*
* Can increase or decrease the level of parallelism in this RDD. Internally, this uses
* a shuffle to redistribute data.
*
* If you are decreasing the number of partitions in this RDD, consider using `coalesce`,
* which can avoid performing a shuffle.
*
* TODO Fix the Shuffle+Repartition data loss issue described in SPARK-23207.
*/
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
} /**
* Return a new RDD that is reduced into `numPartitions` partitions.
*
* This results in a narrow dependency, e.g. if you go from 1000 partitions
* to 100 partitions, there will not be a shuffle, instead each of the 100
* new partitions will claim 10 of the current partitions. If a larger number
* of partitions is requested, it will stay at the current number of partitions.
*
* However, if you're doing a drastic coalesce, e.g. to numPartitions = 1,
* this may result in your computation taking place on fewer nodes than
* you like (e.g. one node in the case of numPartitions = 1). To avoid this,
* you can pass shuffle = true. This will add a shuffle step, but means the
* current upstream partitions will be executed in parallel (per whatever
* the current partitioning is).
*
* @note With shuffle = true, you can actually coalesce to a larger number
* of partitions. This is useful if you have a small number of partitions,
* say 100, potentially with a few partitions being abnormally large. Calling
* coalesce(1000, shuffle = true) will result in 1000 partitions with the
* data distributed using a hash partitioner. The optional partition coalescer
* passed in must be serializable.
*/
def coalesce(numPartitions: Int, shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
(implicit ord: Ordering[T] = null)
: RDD[T] = withScope {
require(numPartitions > 0, s"Number of partitions ($numPartitions) must be positive.")
if (shuffle) {
/** Distributes elements evenly across output partitions, starting from a random partition. */
val distributePartition = (index: Int, items: Iterator[T]) => {
var position = new Random(hashing.byteswap32(index)).nextInt(numPartitions)
items.map { t =>
// Note that the hash code of the key will just be the key itself. The HashPartitioner
// will mod it with the number of total partitions.
position = position + 1
(position, t)
}
} : Iterator[(Int, T)] // include a shuffle step so that our upstream tasks are still distributed
new CoalescedRDD(
new ShuffledRDD[Int, T, T](mapPartitionsWithIndex(distributePartition),
new HashPartitioner(numPartitions)),
numPartitions,
partitionCoalescer).values
} else {
new CoalescedRDD(this, numPartitions, partitionCoalescer)
}
}
dataset的reparation和coalesce的更多相关文章
- Spark编程指南分享
转载自:https://www.2cto.com/kf/201604/497083.html 1.概述 在高层的角度上看,每一个Spark应用都有一个驱动程序(driver program).驱动程序 ...
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
- Spark-RDD之Partition源码分析
概要 Spark RDD主要由Dependency.Partition.Partitioner组成,Partition是其中之一.一份待处理的原始数据会被按照相应的逻辑(例如jdbc和hdfs的spl ...
- spark(二)
一.spark的提交模式 --master(standalone\YRAN\mesos) standalone:-client -cluster 如果我们用client模式去提交程序,我们在哪个地方 ...
- Spark:JavaRDD 转化为 Dataset<Row>的两种方案
JavaRDD 转化为 Dataset<Row>方案一: 实体类作为schema定义规范,使用反射,实现JavaRDD转化为Dataset<Row> Student.java实 ...
- Spark入门之DataFrame/DataSet
目录 Part I. Gentle Overview of Big Data and Spark Overview 1.基本架构 2.基本概念 3.例子(可跳过) Spark工具箱 1.Dataset ...
- Update(Stage4):sparksql:第3节 Dataset (DataFrame) 的基础操作 & 第4节 SparkSQL_聚合操作_连接操作
8. Dataset (DataFrame) 的基础操作 8.1. 有类型操作 8.2. 无类型转换 8.5. Column 对象 9. 缺失值处理 10. 聚合 11. 连接 8. Dataset ...
- SQL Server-分页方式、ISNULL与COALESCE性能分析(八)
前言 上一节我们讲解了数据类型以及字符串中几个需要注意的地方,这节我们继续讲讲字符串行数同时也讲其他内容和穿插的内容,简短的内容,深入的讲解,Always to review the basics. ...
- HTML5 数据集属性dataset
有时候在HTML元素上绑定一些额外信息,特别是JS选取操作这些元素时特别有帮助.通常我们会使用getAttribute()和setAttribute()来读和写非标题属性的值.但为此付出的代价是文档将 ...
随机推荐
- 吴裕雄--天生自然TensorFlow2教程:单输出感知机及其梯度
import tensorflow as tf x = tf.random.normal([1, 3]) w = tf.ones([3, 1]) b = tf.ones([1]) y = tf.con ...
- Visual Studio 2017安装MSDN
在学习Visual Studio 2017的过程中,总会遇到各种各样的难题,这时候你就会求助书或者是网上大佬们的解释,但是在看视频的过程中,我发现了MSDN这个“好东西”,就立马应用于实践,下面把 ...
- nyoj 34
题目:http://acm.nyist.edu.cn/JudgeOnline/problem.php?pid=34 思路:第一种方法是枚举10~100进行计算判断,第二种方法是孙子定理,最近正好学了一 ...
- Tensorflow机器学习入门——AttributeError: module 'scipy.misc' has no attribute 'toimage'
这个bug的解决办法: import cv2 # scipy.misc.toimage(image_array).save('cifar10_data/raw/%d.jpg' % i) cv2.imw ...
- jqgrid自适应宽度
https://blog.csdn.net/duzhanxiaosa/article/details/78922660
- teraterm中log中加入时间戳
步骤: 1.Setup->Additional settings->log->Timestamp(Local Time) 2.记录log.File->log(Teraterm. ...
- Hibernate笔记二
1.延迟加载(懒加载) 概念 需要用到该数据的时候才要加载 种类 类的延迟加载 案例 说明:注意:使用的是Load方法 1. 执行22行代码的时候,不发出sql语句,说明类的延迟加载和主键没有关系 ...
- 《Java Spring框架》Spring IOC 源码分析
1.下载源码 源码部署:https://www.cnblogs.com/jssj/p/11631881.html 并不强求,最好是有源码(方便理解和查问题). 2. 创建子项目 Spring项目中创建 ...
- 调用天气预报webservice接口
1.将 服务端的wsdl文档保存至 本地 http://ws.webxml.com.cn/WebServices/WeatherWS.asmx?WSDL 2.将里面的 <s:element re ...
- HTML 5 <em> <strong> <dfn> <code> <samp> <kbd> <var> <cite> 标签
<em> 呈现为被强调的文本. <strong> 定义重要的文本. <dfn> 定义一个定义项目. <code> 定义计算机代码文本. <samp ...