029.核心组件-Controller Manager
一 Controller Manager原理
1.1 Controller Manager概述

二 Replication Controller
2.1 Replication Controller(副本控制器)作用
- 确保在当前集群中有且仅有N个Pod实例,N是在RC中定义的Pod副本数量。
- 通过调整RC的spec.replicas属性值来实现系统扩容或者缩容。
- 通过改变RC中的Pod模板(主要是镜像版本)来实现系统的滚动升级。
2.2 Replication Controller(副本控制器)场景
- 重新调度(Rescheduling):不管想运行1个副本还是1000个副本,副本控制器都能确保指定数量的副本存在于集群中,即使发生节点故障或Pod副本被终止运行等意外状况。
- 弹性伸缩(Scaling):手动或者通过自动扩容代理修改副本控制器的spec.replicas属性值,非常容易实现增加或减少副本的数量。
- 滚动更新(RollingUpdates):副本控制器被设计成通过逐个替换Pod的方式来辅助服务的滚动更新。推荐的方式是创建一个只有一个副本的新RC,若新RC副本数量加1,则旧RC的副本数量减1,直到这个旧RC的副本数量为0,然后删除该旧RC。通过上述模式,即使在滚动更新的过程中发生了不可预料的错误,Pod集合的更新也都在可控范围内。在理想情况下,滚动更新控制器需要将准备就绪的应用考虑在内,并保证在集群中任何时刻都有足够数量的可用Pod。
三 Node Controller
3.1 Node Controller作用
3.2 Node Controller工作流程
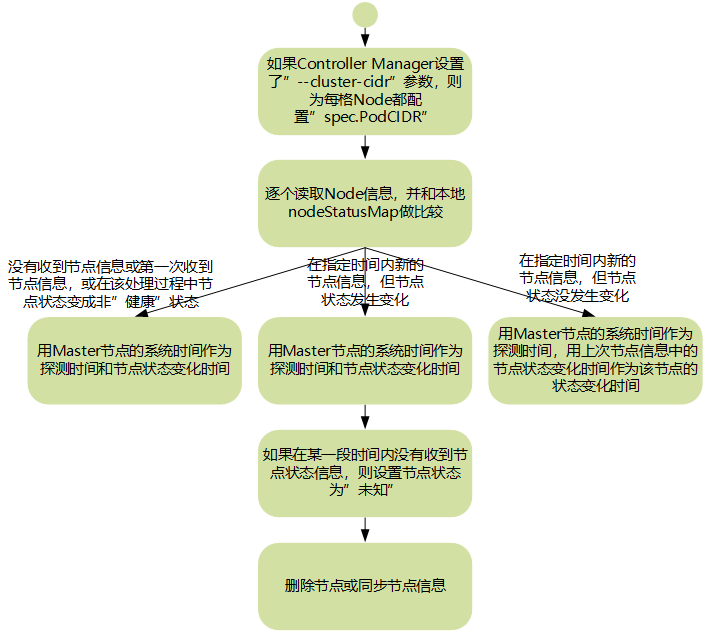
- ControllerM anager在启动时如果设置了--cluster-cidr参数,那么为每个没有设置Spec.PodCIDR的Node都生成一个CIDR地址,并用该CIDR地址设置节点的Spec.PodCIDR属性,这样做的目的是防止不同节点的CIDR地址发生冲突。
- 逐个读取Node信息,多次尝试修改nodeStatusMap中的节点状态信息,将该节点信息和Node Controller的nodeStatusMap中保存的节点信息做比较。如果判断出没有收到kubelet发送的节点信息、第1次收到节点kubelet发送的节点信息,或在该处理过程中节点状态变成非“健康”状态,则在nodeStatusMap中保存该节点的状态信息,并用Node Controller所在节点的系统时间作为探测时间和节点状态变化时间。如果判断出在指定时间内收到新的节点信息,且节点状态发生变化,则在nodeStatusMap中保存该节点的状态信息,并用Node Controller所在节点的系统时间作为探测时间和节点状态变化时间。如果判断出在指定时间内收到新的节点信息,但节点状态没发生变化,则在nodeStatusMap中保存该节点的状态信息,并用Node Controller所在节点的系统时间作为探测时间,将上次节点信息中的节点状态变化时间作为该节点的状态变化时间。如果判断出在某段时间(gracePeriod)内没有收到节点状态信息,则设置节点状态为“未知”,并且通过API Server保存节点状态。
- 逐个读取节点信息,如果节点状态变为非“就绪”状态,则将节点加入待删除队列,否则将节点从该队列中删除。如果节点状态为非“就绪”状态,且系统指定了CloudProvider,则Node Controller调用CloudProvider查看节点,若发现节点故障,则删除etcd中的节点信息,并删除和该节点相关的Pod等资源的信息。
四 ResourceQuota Controller
4.1 ResourceQuota Controller作用
- 容器级别,可以对CPU和Memory进行限制。
- Pod级别,可以对一个Pod内所有容器的可用资源进行限制。
- Namespace级别,为Namespace(多租户)级别的资源限制,包括:
- Pod数量;
- Replication Controller数量;
- Service数量;
- ResourceQuota数量;
- Secret数量;
- 可持有的PV数量。
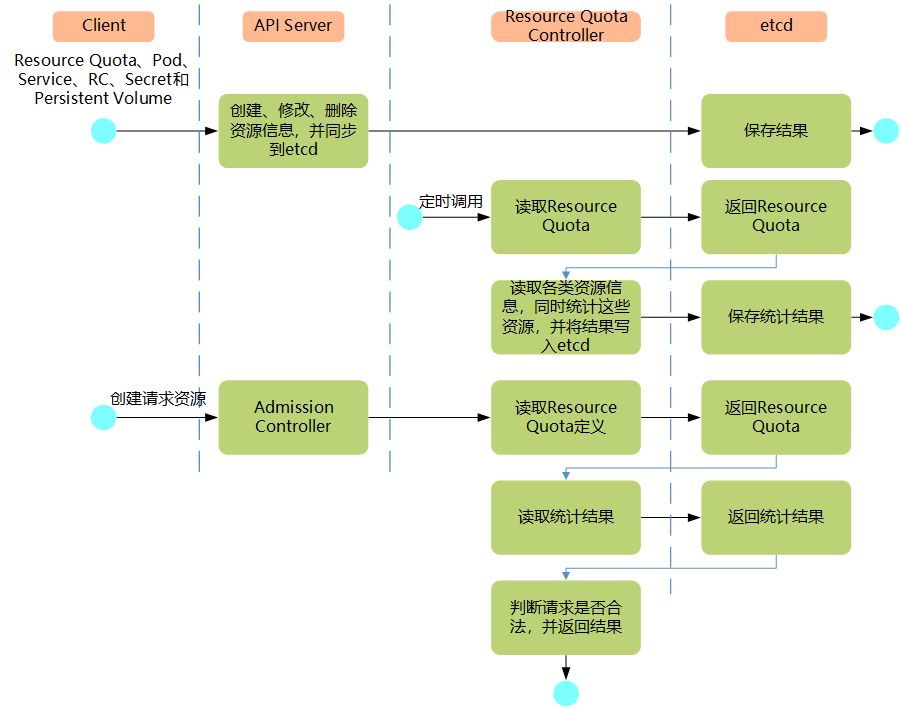
4.2 ResourceQuota Controller工作流程
五 Namespace Controller
5.1 Namespace Controller作用
六 Service Controller与Endpoints Controller
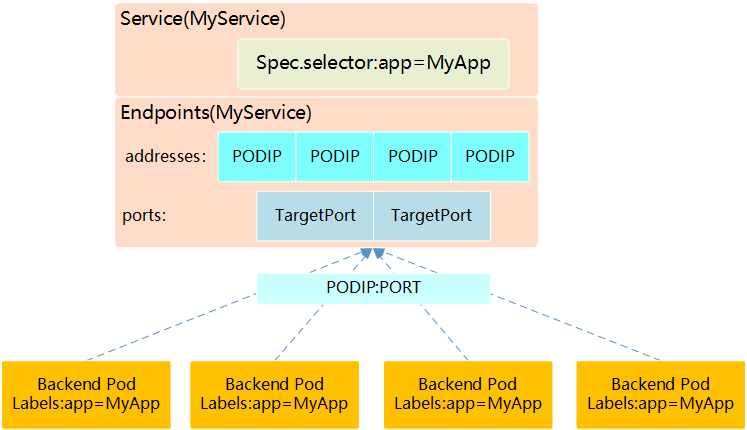
6.1 Service Controller与Endpoints Controller作用
七 Admission Control
7.1 Admission Control概述
7.2 可配置创建列表
- AlwaysAdmit:已弃用,允许所有请求。
- AlwaysPullImages:在启动容器之前总是尝试重新下载镜像。这对于多租户共享一个集群的场景非常有用,系统在启动容器之前可以保证总是使用租户的密钥去下载镜像。如果不设置这个控制器,则在Node上下载的镜像的安全性将被削弱,只要知道该镜像的名称,任何人便都可以使用它们了。
- AlwaysDeny:已弃用,禁止所有请求,用于测试。
- DefaultStorageClass:会关注PersistentVolumeClaim资源对象的创建,如果其中没有包含任何针对特定Storage class的请求,则为其指派指定的Storage class。在这种情况下,用户无须在PVC中设置任何特定的Storage class就能完成PVC的创建了。如果没有设置默认的Storage class,该控制器就不会进行任何操作;如果设置了超过一个的默认Storage class,该控制器就会拒绝所有PVC对象的创建申请,并返回错误信息。因此需要确保Storage class对象的配置只有一个默认值。
- DefaultTolerationSeconds:针对没有设置容忍node.kubernetes.io/not-ready:NoExecute或者node.alpha.kubernetes.io/unreachable:NoExecute的Pod,设置5min的默认容忍时间。
- DenyExecOnPrivileged:已弃用,拦截所有想在Privileged Container上执行命令的请求。如果你的集群支持Privileged Container,又希望限制用户在这些Privileged Container上执行命令,那么强烈推荐使用它。其功能已被合并到DenyEscalatingExec中。
- DenyEscalatingExec:拦截所有exec和attach到具有特权的Pod上的请求。如果你的集群支持运行有escalated privilege权限的容器,又希望限制用户在这些容器内执行命令,那么强烈推荐使用它。
- EventReateLimit:Alpha版本,用于应对事件密集情况下对API Server造成的洪水攻击。
- ExtendedResourceToleration:如果需要创建带有特定资源(例如GPU、FPGA等)的独立节点,则可能会对节点进行Taint处理来进行特别配置。该控制器能够自动为申请这些特别资源的Pod加入Toleration定义,无须人工干预。
- ImagePolicyWebhook:这个插件将允许后端的一个Webhook程序来完成Admission Controller的功能。ImagePolicyWebhook需要使用一个配置文件(通过kube-API Server的启动参数--admission-control-config-file设置)定义后端Webhook的参数。目前是Alpha版本的功能。
- Initializers:Alpha。用于为动态准入控制提供支持,通过修改待创建资源的元数据来完成对该资源的修改。LimitPodHardAntiAffinityTopology:该插件启用了Pod的反亲和性调度策略设置,在设置亲和性策略参数requiredDuringSchedulingRequiredDuringExecution时要求将topologyKey的值设置为“kubernetes.io/hostname”,否则Pod会被拒绝创建。
- LimitRanger:这个插件会监控进入的请求,确保请求的内容符合在Namespace中定义的LimitRange对象里的资源限制。如果要在Kubernetes集群中使用LimitRange对象,则必须启用该插件才能实施这一限制。LimitRanger还能用于为没有设置资源请求的Pod自动设置默认的资源请求,该插件会为default命名空间中的所有Pod设置0.1CPU的资源请求。
- MutatingAdmissionWebhook:Beta。这一插件会变更符合要求的请求的内容,Webhook以串行的方式顺序执行。
- NamespaceAutoProvision:这一插件会检测所有进入的具备命名空间的资源请求,如果其中引用的命名空间不存在,就会自动创建命名空间。
- NamespaceExists:这一插件会检测所有进入的具备命名空间的资源请求,如果其中引用的命名空间不存在,就会拒绝这一创建过程。
- NamespaceLifecycle:如果尝试在一个不存在的Namespace中创建资源对象,则该创建请求将被拒绝。当删除一个Namespace时,系统将会删除该Namespace中的所有对象,包括Pod、Service等,并阻止删除default、kube-system和kube-public这三个命名空间。
- NodeRestriction:该插件会限制kubelet对Node和Pod的修改行为。为了实现这一限制,kubelet必须使用system:nodes组中用户名为system:node:<nodeName>的Token来运行。符合条件的kubelet只能修改自己的Node对象,也只能修改分配到各自Node上的Pod对象。在Kubernetes1.11以后的版本中,kubelet无法修改或者更新自身Node的taint属性。在Kubernetes1.13以后,这一插件还会阻止kubelet删除自己的Node资源,并限制对有kubernetes.io/或k8s.io/前缀的标签的修改。
- OnwerReferencesPermissionEnforcement:在该插件启用后,一个用户要想修改对象的metadata.ownerReferences,就必须具备delete权限。该插件还会保护对象的metadata.ownerReferences[x].blockOwnerDeletion字段,用户只有在对finalizers子资源拥有update权限的时候才能进行修改。
- PersistentVolumeLabel:弃用。这一插件自动根据云供应商(例如GCE或AWS)的定义,为PersistentVolume对象加入region或zone标签,以此来保障PersistentVolume和Pod同处一区。如果插件不为PV自动设置标签,则需要用户手动保证Pod和其加载卷的相对位置。该插件正在被Cloudcontrollermanager替换,从Kubernetes1.11版本开始默认被禁止。
- PodNodeSelector:该插件会读取命名空间的annotation字段及全局配置,来对一个命名空间中对象的节点选择器设置默认值或限制其取值。
- PersistentVolumeClaimResize:该插件实现了对PersistentVolumeClaim发起的resize请求的额外校验。
- PodPreset:该插件会使用PodSelector选择Pod,为符合条件的Pod进行注入。
- PodSecurityPolicy:在创建或修改Pod时决定是否根据Pod的securitycontext和可用的PodSecurityPolicy对Pod的安全策略进行控制。
- PodTolerationRestriction:该插件首先会在Pod和其命名空间的Toleration中进行冲突检测,如果其中存在冲突,则拒绝该Pod的创建。它会把命名空间和Pod的Toleration进行合并,然后将合并的结果与命名空间中的白名单进行比较,如果合并的结果不在白名单内,则拒绝创建。如果不存在命名空间级的默认Toleration和白名单,则会采用集群级别的默认Toleration和白名单。
- Priority:这一插件使用priorityClassName字段来确定优先级,如果没有找到对应的PriorityClass,该Pod就会被拒绝。
- ResourceQuota:用于资源配额管理目的,作用于Namespace。该插件拦截所有请求,以确保在Namespace上的资源配额使用不会超标。推荐在Admission Control参数列表中将这个插件排最后一个,以免可能被其他插件拒绝的Pod被过早分配资源。
- SecurityContextDeny:这个插件将在Pod中定义的SecurityContext选项全部失效。SecurityContext在Container中定义了操作系统级别的安全设定(uid、gid、capabilities、SELinux等)。在未设置PodSecurityPolicy的集群中建议启用该插件,以禁用容器设置的非安全访问权限。
- ServiceAccount:这个插件将ServiceAccount实现了自动化,如果想使用ServiceAccount对象,那么强烈推荐使用它。
- StorageObjectInUseProtection:这一插件会在新创建的PVC或PV中加入kubernetes.io/pvc-protection或kubernetes.io/pv-protection的finalizer。如果想要删除PVC或者PV,则直到所有finalizer的工作都完成,删除动作才会执行。
- ValidatingAdmissionWebhook:在Kubernetes1.8中为Alpha版本,在Kubernetes1.9中为Beta版本。该插件会针对符合其选择要求的请求调用校验Webhook。目标Webhook会以并行方式运行;如果其中任何一个Webhook拒绝了该请求,该请求就会失败。
1 --enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultsStorageClass,DefaultTolerationSeconds,MutatingAdmissionWebhook,ValidatingAdmissionWebhook,ResourceQuota
1 --enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,MutatingAdmissionWebhook,CalidatingAdmissionWebhook,ResourceQuota
029.核心组件-Controller Manager的更多相关文章
- kubernetes的Controller Manager
1. Controller Manager简介 Controller Manager作为集群内部的管理控制中心,负责集群内的Node.Pod副本.服务端点(Endpoint).命名空间(Namespa ...
- Kubernetes Controller Manager
Controller Manager 作为集群内部的管理控制中心,负责集群内的Node.Pod副本.Service Endpoint.NameSpace.ServiceAccount.Resource ...
- kubernetes之Controller Manager原理分析
Controller Manager作为集群内部的管理控制中心,负责集群内的Node.Pod副本.服务端点(Endpoint).命名空间(Namespace).服务账号(ServiceAccount) ...
- 附024.Kubernetes全系列大总结
Kubernetes全系列总结如下,后期不定期更新.欢迎基于学习.交流目的的转载和分享,禁止任何商业盗用,同时希望能带上原文出处,尊重ITer的成果,也是尊重知识.若发现任何错误或纰漏,留言反馈或右侧 ...
- kubernetes进阶之五:Replication Controller&Replica Sets&Deployments
一:Replication Controller RC是kubernetes的核心概念之一.它定义了一个期望的场景即声明某种Pod的副本数量在任意时候都要符合某个预期值. 它由以下几个部分组成: 1. ...
- Docker Manager for Kubernetes
一.Kubernetes介绍 Kubernets是Google开源的容器集群系统,是基于Docker构建一个容器的调度服务,提供资源调度,均衡容灾,服务注册,动态伸缩等功能套件: Kubernets提 ...
- Kubernetes 学习11 kubernetes ingress及ingress controller
一.上集回顾 1.Service 3种模型:userspace,iptables,ipvs 2.Service类型 ClusterIP,NodePort NodePort:client -> N ...
- 030.Kubernetes核心组件-Scheduler
一 Scheduler原理 1.1 原理解析 Kubernetes Scheduler是负责Pod调度的重要功能模块,Kubernetes Scheduler在整个系统中承担了"承上启下&q ...
- 揭秘 Kubernetes attach/detach controller 逻辑漏洞致使 pod 启动失败
前言 本文主要通过深入学习k8s attach/detach controller源码,了解现网案例发现的attach/detach controller bug发生的原委,并给出解决方案. 看完本文 ...
随机推荐
- 如何使用Outlook 客户端配置其他邮箱客户端收发邮件
本文介绍Outlook2016客户端配置QQ邮箱收发邮件 1.打开Outlook客户端,文件->信息->-添加账户 2.输入需要添加的邮箱账户,点击连接 3.输入密码并连接 4.打开QQ邮 ...
- Java IO: Buffered和Data
作者:Jakob Jenkov 译者: 李璟(jlee381344197@gmail.com) 本小节会简要概括Java IO中Buffered和data的输入输出流,主要涉及以下4个类型的流:Bu ...
- [LC] 48. Rotate Image
You are given an n x n 2D matrix representing an image. Rotate the image by 90 degrees (clockwise). ...
- [LC] 209. Minimum Size Subarray Sum
Given an array of n positive integers and a positive integer s, find the minimal length of a contigu ...
- JavaScript学习总结(四)function函数部分
转自:http://segmentfault.com/a/1190000000660786 概念 函数是由事件驱动的或者当它被调用时执行的可重复使用的代码块. js 支持两种函数:一类是语言内部的函数 ...
- ionic2踩坑之自定义插件开发及调用
关于ionic2自定义插件开发的文章,插件怎么调用的文章,好像网上都有,不过作为一个新手来说,从插件的开发到某个页面怎么调用,没有一个完整的过程的话,两篇没有关联的文章也容易看的迷糊.这里放到一起来方 ...
- idea(or maven) 未结束字符串字面值 非法的表达式开始
[ERROR] *.java:[38,27] 未结束的字符串字面值 [ERROR] *.java:[38,53] 需要 ';' [ERROR] *.java:[41,19] 需要 ')' [ERROR ...
- axios 传对象(JavaBean)到后台
//user对象 let user = JSON.stringify({ userAccountNumber: own.userName, userPassword: own.userPassword ...
- nginx安装与fastdfs配置--阿里云
上一篇文章:fastDFS 一二事 - 简易服务器搭建之--阿里云 做了fastDFS的服务安装和配置,接下来我们来看nginx的安装 第一步:安装nginx需要安装的一些环境: 1.例如: yum ...
- 悖论当道,模式成空:汽车O2O真是死得其所?
O2O热潮的兴起似乎来得颇为蹊跷--或许是线上连接线下的模式太过空泛,具有极大的包容性,让各个行业都忍不住在其中横插一脚.在经历过最初的崛起和后来的火爆之后,最终形成目前的寒冬.究其原因,O2O并不是 ...