Hbase的基本架构以及对应的读写流程
一、HBase简介
1,定义:
HBase 是一种分布式、可扩展、支持海量数据存储的 NoSQL 数据库。
2,HBase的架构图:

架构角色:
1)Master
Master是所有Region Server的管理者,其实现为HRegionServer,主要作用有:
a>对于表的DDL操作:create,delete,alter b>对于RegionServer的操作:分配regions到每个RegionServer,监控每个RegionServer的状态,负载均衡和故障转移。
2)Zookeeper:
HBase通过Zookeeper来做Master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。
3)WAL:
由于数据要经MemStore排序后才能刷写到HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,数据会先写入Write-Ahead logfile的文件中,然后再写入到Memstore中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
4)MemStore:
写缓存,由于HFile中的数据要求是有序的,所以数据是先存储在MemStore中,排好序后,等到达刷写时机才会刷写到HFile,每次刷写都会形成一个新的HFile。
5)StoreFile:
保存实际数据的物理文件,StoreFile以HFile的形式存储在HDFS上。每个Store会有一个或多个StoreFile(HFile),数据在StoreFile上是有序的。
3,数据模型:
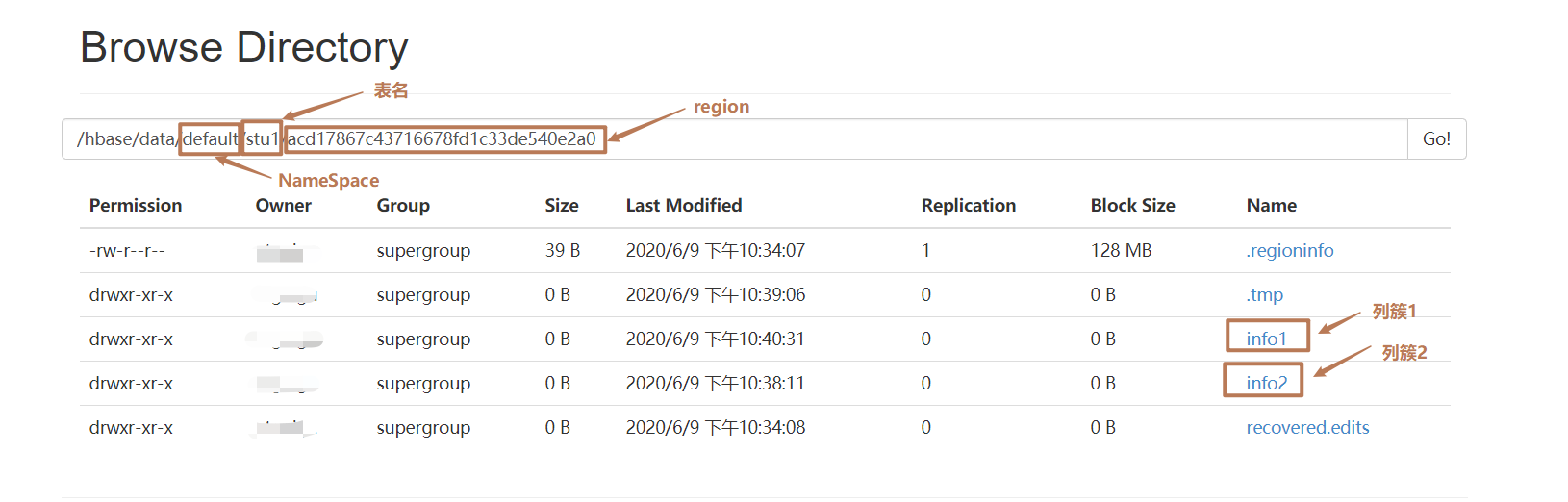
1)Name Space
命名空间,类似于关系型数据库的DataBase概念,每个命名空间下有多个表。HBase有两个自带的命名空间,分别是hbase和default,hbase中存放的是HBase的内置表,default表示用户默认使用的命名空间。
2)Region
类似于关系型数据库的表概念。不同的是,HBase定义表时只需要生命列簇即可,不需要声明具体的列。这意味着,往HBase写入数据时,字段可以动态、按需指定。
3)Row
HBase表中的每行数据都由一个RowKey和多个Column(列)组成,数据是按照RowKey的字典顺序存储的,并且查询时智能根据RowKey进行检索,所以RowKey的书籍十分重要。
4)Cloumn
HBase中的每个列都由Cloumn Family(列簇)和Cloumn Qualifier(列限定符)进行限定,例如info:name,info:age。建表时,只需指明列簇,而列限定符无需预先定义。
5)Time Stamp
用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会自动为其加上该字段,其值为写入HBase的时间。
6)Cell
由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元。cell 中的数据是没有类型的,全部是字节码形式存贮。
二、HBase写数据流程
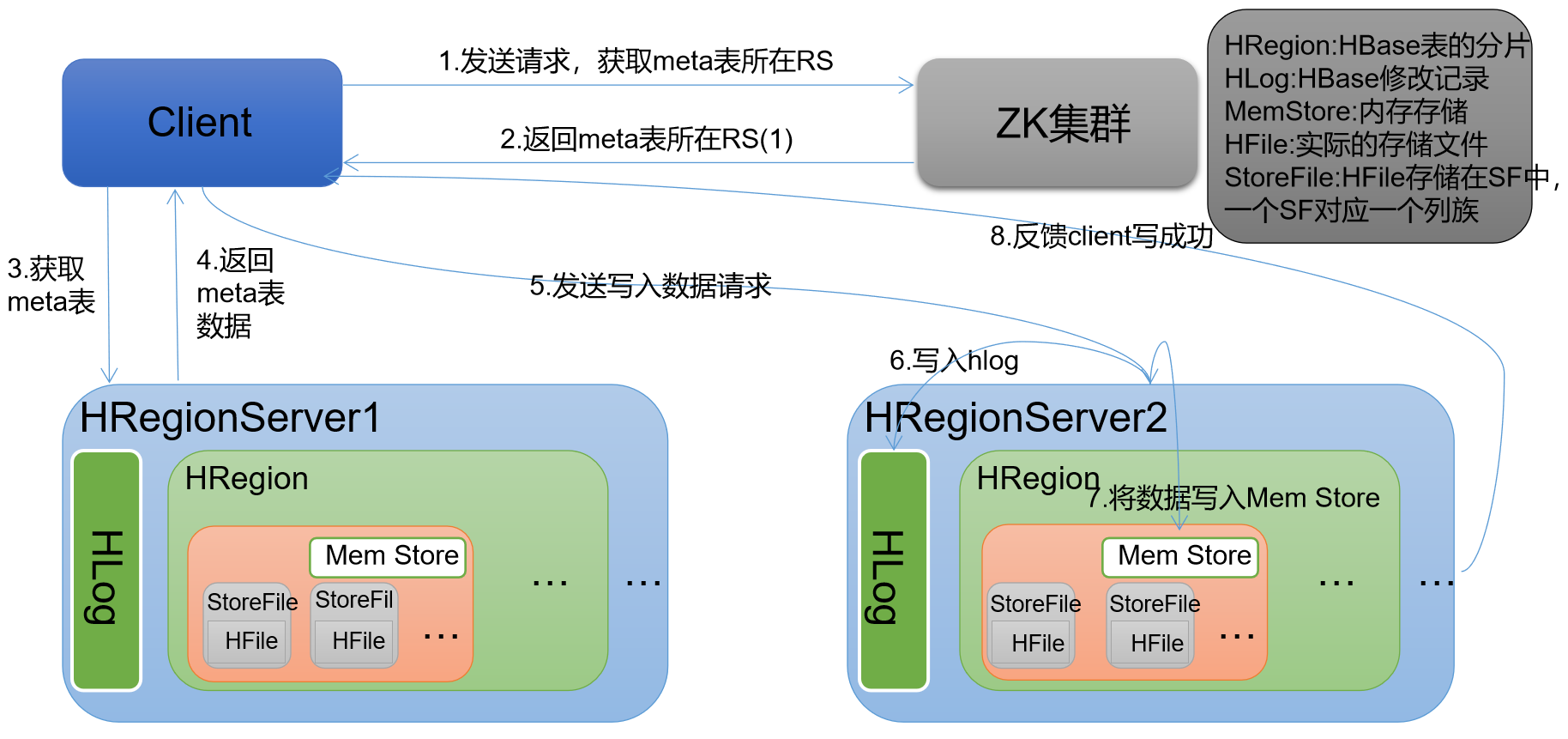
)Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。 #zk get /hbase/meta-region-server
)访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey,查询出目标数据位于哪个 Region Server 中的哪个 Region 中。
并将该 table 的 region 信息以及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。 #hbase scan 'hbase:meta' 查询到具体哪张表由哪个Region Server维护
)与目标 Region Server 进行通讯;
)将数据顺序写入(追加)到 WAL;
)将数据写入对应的 MemStore,数据会在 MemStore 进行排序;
)向客户端发送 ack;
)等达到 MemStore 的刷写时机后,将数据刷写到 HFile。
三、HBase读数据流程
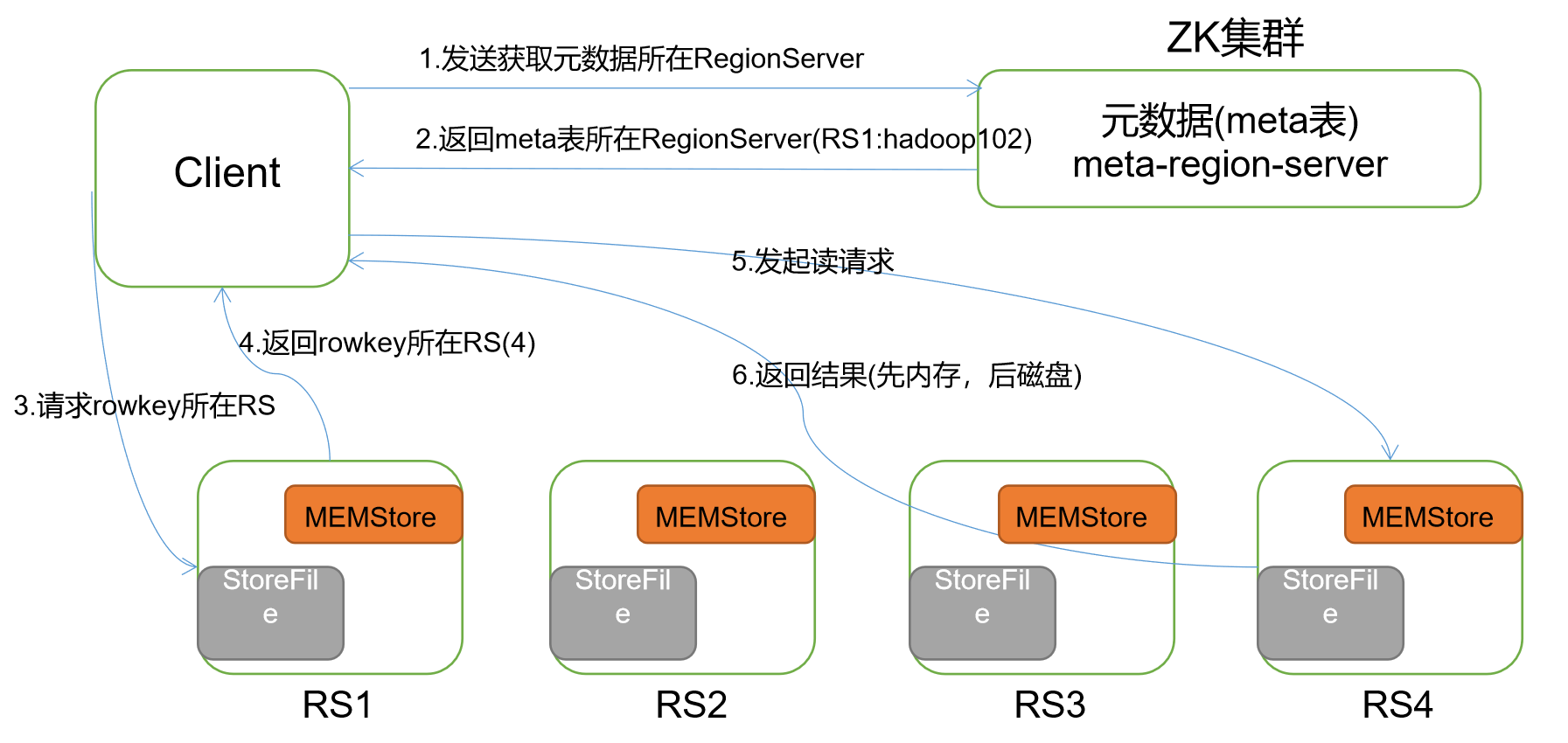
)Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。
)访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey,查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。
)与目标 Region Server 进行通讯;
)分别在 Block Cache(读缓存),MemStore 和 Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)。
)将从文件中查询到的数据块(Block,HFile 数据存储单元,默认大小为 64KB)缓存到Block Cache。
)将合并后的最终结果返回给客户端。
Hbase的基本架构以及对应的读写流程的更多相关文章
- HBase的基本架构及其原理介绍
1.概述:最近,有一些工程师问我有关HBase的基本架构的问题,其实这个问题仅仅说架构是非常简单,但是需要理解.在这里,我觉得可以用HDFS的架构作为借鉴.(其实像Hadoop生态系统中的大部分组建的 ...
- HBase 数据读写流程
HBase 数据读写流程 2016-10-18 杜亦舒 读数据 HBase的表是按行拆分为一个个 region 块儿,这些块儿被放置在各个 regionserver 中 假设现在想在用户表中获取 ro ...
- Mycat分布式数据库架构解决方案--Mycat实现读写分离
echo编辑整理,欢迎转载,转载请声明文章来源.欢迎添加echo微信(微信号:t2421499075)交流学习. 百战不败,依不自称常胜,百败不颓,依能奋力前行.--这才是真正的堪称强大!!! 安装完 ...
- Hbase的读写流程
HBase读写流程 1.HBase读数据流程 HRegionServer保存着meta表以及表数据,要访问表数据,首先Client先去访问zookeeper,从zookeeper里面获取meta表所在 ...
- HBase二级索引、读写流程
HBase二级索引.读写流程 一.HBse二级索引方案 1.1 基于Coprocessor方案 1.2 Phoenix二级索引特点 1.3 Phoenix 二级索引方案 二.HBase读写流程 2.1 ...
- zookeeper的读写流程
zookeeper的读写流程 基本架构 节点数要求是奇数. 常用的接口是 get/set/create/getChildren. 读写流程 写流程 客户端连接到集群中某一个节点 客户端发送写请求 服务 ...
- hbase之createTable完整的netty实现执行流程
hbase的客户端代码并不想hive一样用java编写,shell调用,而是使用ruby编写. 在admin.rb文件中方法create,其中接受两个参数,其中第二个参数类型为变长参数. 而在crea ...
- Hadoop---HDFS读写流程
Hadoop---HDFS HDFS 性能详解 HDFS 天生是为大规模数据存储与计算服务的,而对大规模数据的处理目前还有没比较稳妥的解决方案. HDFS 将将要存储的大文件进行分割,分割到既定的存储 ...
- HDFS文件读写流程
一.HDFS HDFS全称是Hadoop Distributed System.HDFS是为以流的方式存取大文件而设计的.适用于几百MB,GB以及TB,并写一次读多次的场合.而对于低延时数据访问.大量 ...
随机推荐
- R的安装以及包安装
今天看论文,需要用到R语言的库,于是又折腾了半天.. 其实并没有什么太大的问题,只是在第三方包的下载方面还有python中使用R方面遇到了问题: 第三方包的导入 其实在网上有 ...
- 7.2 Go type assertion
7.2 Go type assertion 类型断言是使用在接口值上的操作. 语法x.(T)被称为类型断言,x代表接口的类型,T代表一个类型检查. 类型断言检查它操作对象的动态类型是否和断言类型匹配. ...
- Django路由配置之正则表达式详解
正则表达式详解 urls.py from django.conf.urls import url from . import views urlpatterns = [ url(r'^articles ...
- 201771010128王玉兰《面向对象程序设计(Java)》第十周学习总结
第一部分:理论知识部分总结: (1) 定义简单泛型类: A:泛型:也称参数化类型(parameterizedtype),就是在定义类.接口和方法时,通过类型参数指 示将要处理的对象类型. B:泛型程序 ...
- BZOJ 1050并查集+贪心
1050: [HAOI2006]旅行comf Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 3333 Solved: 1851[Submit][St ...
- Java程序员的两项通用能力
工作这几年来,经历了很多.从小白到中级(手机里有一款叫中国象棋的游戏,里面给对弈中电脑水平分为小白.菜鸟.新手.入门.初级.中级.高级.大师.特级大师,编程我暂且按照这样来区分). 学校教给我的是从小 ...
- uniapp轻轻松松开发各种类型的小程序
1.前言 现在移动端用户使用量占据了市场大部分的比例,今天 给大家说说怎么去开发一个小程序,今天使用的是uniapp 2.什么是uniapp uni-app 是一个使用 Vue.js 开发所有前端应用 ...
- 软件攻城狮究级装B指南
引言 装B于无形,随性而动,顺道而行,待霸业功成之时,你会发现:装B是牛B最好的的试金石. -- SuperDo 第一章.人间兵器(准备工具) <论语·魏灵公>:“工欲善其事,必先利其器. ...
- [Firefox附加组件]0004.上下文菜单项
在我们平常浏览网页是经常要对网页类容进行一些操作处理,如复制,翻译,搜索,打印打印等,今天我们就学习下如何在Firefox中我们如何通过附加组件实现这些操作. 开发步骤 1.终端窗口运行以下命令创建项 ...
- zsh 使用通配符功能
zsh 使用通配符功能 默认情况下 zsh 是不支持通配符 (*) 匹配的: 第一步,打开zsh配置文件 $ vi .zshrc 第二步,最后一行添加下面语句到文本中,保存.退出: setopt no ...