dns原理介绍及实践问题总结
1 问题引入:
a) 域名劫持: dns过程中某个环节被攻击/篡改,导致dns结果为劫持者的服务器。例如竞争对手将你方的app下载地址篡改为他方的app下载地址。
b) 对现网用户进行监控时,发现个别用户请求时间为几十秒,而客户端设置的connectTimeout时间为二十秒。
原因:初步判断为dns解析时间耗时过长导致整个接口请求时间远远超过了10s。
解决办法: 自定义dns,设置超时时间。 (使用的的是OkHttp,支持自定义dns)
c) 测试环境dns几十秒,现网正常
原因: 旧的代码里面对url解析为host有bug,当传入一个测试环境地址,例如 10.10.10.10:6026/path,最终解析出来的host为10.10.10.10:6026,
当调用系统的InetAddress.getAllByName("10.10.10.10:6026"),耗时非常长(几十秒)
分析: 首先10.10.10.10:6026不是一个host地址也不是一个ip地址,所以dns是无法解析的。 方法内部会把它当成一个host在到不同的dns服务器上去查找它的ip,最后返回失败。
解决办法: 使用InetAddress中提供的方法来获取host,拒绝自己实现一套
d) no route to host
2 dns过程介绍
2.1 什么是dns
DNS (Domain Name System 的缩写)的作用非常简单,就是根据域名查出IP地址。你可以把它想象成一本巨大的电话本。
举例来说,如果你要访问域名math.stackexchange.com,首先要通过DNS查出它的IP地址是151.101.129.69。
DNS是应用层协议,事实上他是为其他应用层协议工作的,包括不限于HTTP和SMTP以及FTP,用于将用户提供的主机名解析为ip地址。
2.2 主机名结构
举例来说,www.example.com真正的域名是www.example.com.root,简写为www.example.com.。因为,根域名.root对于所有域名都是一样的,所以平时是省略的。
域名的层次结构如下:
主机名.次级域名.顶级域名.根域名
2.3 DNS服务及域名解析过程
1. 假设运行在用户主机上的某些应用程序(如Webl浏览器或者邮件阅读器)需要将主机名转换为IP地址。这些应用程序将调用DNS的客户机端,并指明需要被转换的主机名。(在很多基于UNIX的机器上,应用程序为了执行这种转换需要调用函数gethostbyname())。
2. 用户主机的DNS客户端接收到后,向网络中发送一个DNS查询报文。所有DNS请求和回答报文使用的UDP数据报经过端口53发送.
3. 经过若干ms到若干s的延时后,用户主机上的DNS客户端接收到一个提供所希望映射的DNS回答报文,这个查询结果则被传递到调用DNS的应用程序。
从用户主机上调用应用程序的角度看,DNS是一个提供简单、直接的转换服务的黑盒子。但事实上,实现这个服务的黑盒子非常复杂,**它由分布于全球的大量DNS服务器以及定义了DNS服务器与查询主机通信方式的应用层协议组成。**
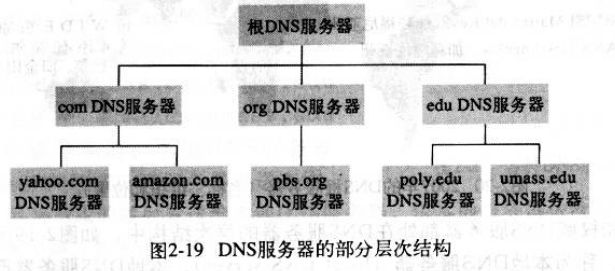
DNS查询采用分级查询的方式,所谓"分级查询",就是从根域名开始,依次查询每一级域名的NS记录,直到查到最终的IP地址,过程大致如下。
- 从"根域名服务器"查到"顶级域名服务器"的NS记录和A记录(IP地址)
- 从"顶级域名服务器"查到"次级域名服务器"的NS记录和A记录(IP地址)
- 从"次级域名服务器"查出"主机名"的IP地址、
仔细看上面的过程,你可能发现了,没有提到DNS服务器怎么知道"根域名服务器"的IP地址。回答是"根域名服务器"的NS记录和IP地址一般是不会变化的,所以内置在DNS服务器里面。
下面一张图以www.qq.com为例,介绍了dns的过程:
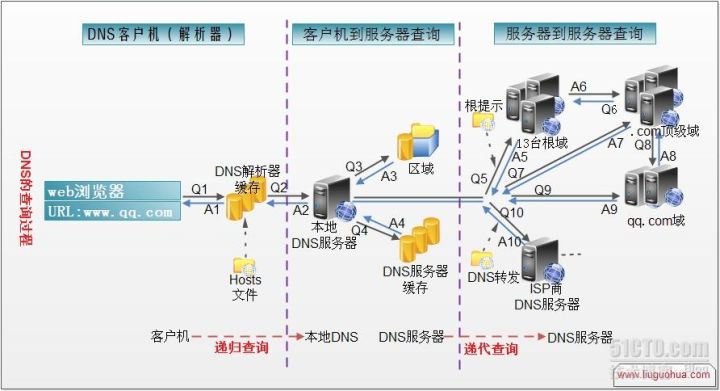
解析顺序
1) 浏览器缓存
当用户通过浏览器访问某域名时,浏览器首先会在自己的缓存中查找是否有该域名对应的IP地址(若曾经访问过该域名且没有清空缓存便存在);
2) 系统缓存
当浏览器缓存中无域名对应IP则会自动检查用户计算机系统Hosts(linux中是/etc/hosts)文件DNS缓存是否有该域名对应IP;
3) 路由器缓存
当浏览器及系统缓存中均无域名对应IP则进入路由器缓存中检查,以上三步均为客服端的DNS缓存;
4) ISP(互联网服务提供商)DNS缓存
当在用户客服端查找不到域名对应IP地址,则将进入ISP DNS缓存中进行查询。比如你用的是电信的网络,则会进入电信的DNS缓存服务器中进行查找;
5) 根域名服务器
当以上均未完成,则进入根服务器进行查询。全球仅有13台根域名服务器,1个主根域名服务器,其余12为辅根域名服务器。根域名收到请求后会查看区域文件记录,若无则将其管辖范围内顶级域名(如.com)服务器IP告诉本地DNS服务器;
6) 顶级域名服务器
顶级域名服务器收到请求后查看区域文件记录,若无则将其管辖范围内主域名服务器的IP地址告诉本地DNS服务器;
7) 主域名服务器
主域名服务器接受到请求后查询自己的缓存,如果没有则进入下一级域名服务器进行查找,并重复该步骤直至找到正确纪录;
8)保存结果至缓存
本地域名服务器把返回的结果保存到缓存,以备下一次使用,同时将该结果反馈给客户端,客户端通过这个IP地址与web服务器建立链接。
了解了上面的过程就不难理解dns解析一个错误的host为什么需要几十秒的时间了。
DNS的记录类型
域名与IP之间的对应关系,称为"记录"(record)。根据使用场景,"记录"可以分成不同的类型(type),前面已经看到了有A记录和NS记录。
常见的DNS记录类型如下。
(1) A:地址记录(Address),返回域名指向的IP地址。
(2) NS:域名服务器记录(Name Server),返回保存下一级域名信息的服务器地址。该记录只能设置为域名,不能设置为IP地址。
(3)MX:邮件记录(Mail eXchange),返回接收电子邮件的服务器地址。
(4)CNAME:规范名称记录(Canonical Name),返回另一个域名,即当前查询的域名是另一个域名的跳转,详见下文。
(5)PTR:逆向查询记录(Pointer Record),只用于从IP地址查询域名,详见下文。
一般来说,为了服务的安全可靠,至少应该有两条NS记录,而A记录和MX记录也可以有多条,这样就提供了服务的冗余性,防止出现单点失败。
3 dns问题定位工具:dig
a) dig命令的+trace参数可以显示DNS的整个分级查询过程,例如:
dig +trace www.baidu.com
b) 查询每一级域名的NS记录
dig ns com (可以查看包含com域名记录的十三台root服务器信息)
dig ns stackexchange.com (stackexchange.com 次级域名记录的服务器信息)
参考:http://ruanyifeng.com/blog/2016/06/dns.html
dns原理介绍及实践问题总结的更多相关文章
- Tengine HTTPS原理解析、实践与调试【转】
本文邀请阿里云CDN HTTPS技术专家金九,分享Tengine的一些HTTPS实践经验.内容主要有四个方面:HTTPS趋势.HTTPS基础.HTTPS实践.HTTPS调试. 一.HTTPS趋势 这一 ...
- DNS原理及其解析过程 精彩剖析
本文章转自下面:http://369369.blog.51cto.com/319630/812889 DNS原理及其解析过程 精彩剖析 网络通讯大部分是基于TCP/IP的,而TCP/IP是基于IP地址 ...
- Atitit.软件架构高扩展性and兼容性原理与概论实践attilax总结
Atitit.软件架构高扩展性and兼容性原理与概论实践attilax总结 1. 什么是可扩展的应用程序?1 2. 松耦合(ioc)2 3. 接口的思考 2 4. 单一用途&模块化,小粒度化2 ...
- DNS原理及其解析过程【精彩剖析】(转)
2012-03-21 17:23:10 标签:dig wireshark bind nslookup dns 原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否 ...
- 高性能消息队列 CKafka 核心原理介绍(上)
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~ 作者:闫燕飞 1.背景 Ckafka是基础架构部开发的高性能.高可用消息中间件,其主要用于消息传输.网站活动追踪.运营监控.日志聚合.流式 ...
- 《分布式系统原理介绍》【PDF】下载
内容简介 分布式系统理论体系非常庞大,涉及知识面也非常广博,本文精心选择了部分在工程实践中应用广泛.简单有效的分布式理论.算法.协议加以介绍.全文分为两大部分,第一部分介绍了分布式系统的一些基本概念并 ...
- MapReduce 原理与 Python 实践
MapReduce 原理与 Python 实践 1. MapReduce 原理 以下是个人在MongoDB和Redis实际应用中总结的Map-Reduce的理解 Hadoop 的 MapReduce ...
- RabbitMQ系列(三)RabbitMQ交换器Exchange介绍与实践
RabbitMQ交换器Exchange介绍与实践 RabbitMQ系列文章 RabbitMQ在Ubuntu上的环境搭建 深入了解RabbitMQ工作原理及简单使用 RabbitMQ交换器Exchang ...
- Spark Shuffle调优原理和最佳实践
对性能消耗的原理详解 在分布式系统中,数据分布在不同的节点上,每一个节点计算一部份数据,如果不对各个节点上独立的部份进行汇聚的话,我们计算不到最终的结果.我们需要利用分布式来发挥Spark本身并行计算 ...
随机推荐
- (转)Navicat Premium 12.1.8.0安装与激活
http://www.mamicode.com/info-detail-2493067.html
- 量化投资_TB交易开拓者A函数和Q函数常见组合应用
1 在交易开拓者当中,关于交易的做单方式一般分为:图表函数和A函数两类. 两类的主要区别为:如果采用图表函数的话,所有的交易内容都是以图表上面的信号为准,当前仓位运行的实际状态是没有的,但是可以显示交 ...
- DateTimePicket jQuery 日期插件,开始时间和结束时间示例
需要引入的js文件: <input type="text" id="startTime" placeholder="开始时间"/> ...
- Tricks of Android's GUI
Tricks of Android's GUI */--> Tricks of Android's GUI 1 layoutweight In LinearLayout, the default ...
- UTF虚拟对象
虚拟对象: 虚拟对象是为了让UFT识别某些不能识别的控件,把这些控件的范围定义为虚拟对象. 新建虚拟对象 管理虚拟对象 创建虚拟对象之后可通过菜单tools-Virutal Objects-Virut ...
- MS12-020 3389蓝屏攻击
MS12-020 3389蓝屏攻击 search ms12_020 use exploit/dos/windows/rdp/ms12_020_maxchannelids set rhost 192.1 ...
- Linux查看后台任务,关闭后台任务
jobs查看后台任务, kill %num关闭相应的后台任务
- Android目录结构(详解)
Android目录结构(详解) 下面是HelloAndroid项目在eclipse中的目录层次结构: 由上图可以看出项目的根目录下共有九个文件(夹),下面就这九个文件(夹)进行详解: 1.1src文件 ...
- Python sorted函数详解(高级篇)
sorted() 函数对所有可迭代的对象进行排序操作. sort 与 sorted 区别: sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作. list 的 s ...
- JavaScript的数据类型有哪些?
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...