【tensorflow2.0】处理结构化数据-titanic生存预测
1、准备数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras import models,layers dftrain_raw = pd.read_csv('./data/titanic/train.csv')
dftest_raw = pd.read_csv('./data/titanic/test.csv')
dftrain_raw.head(10)
部分数据:
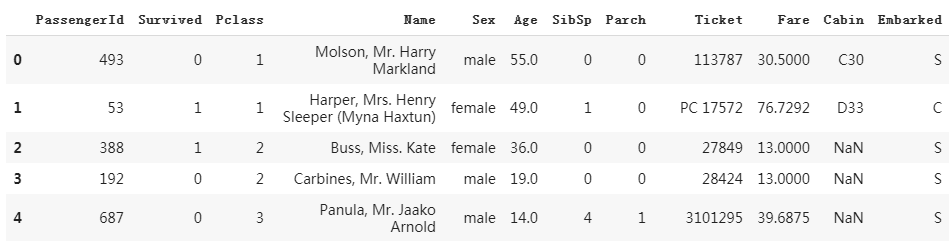
相关字段说明:
- Survived:0代表死亡,1代表存活【y标签】
- Pclass:乘客所持票类,有三种值(1,2,3) 【转换成onehot编码】
- Name:乘客姓名 【舍去】
- Sex:乘客性别 【转换成bool特征】
- Age:乘客年龄(有缺失) 【数值特征,添加“年龄是否缺失”作为辅助特征】
- SibSp:乘客兄弟姐妹/配偶的个数(整数值) 【数值特征】
- Parch:乘客父母/孩子的个数(整数值)【数值特征】
- Ticket:票号(字符串)【舍去】
- Fare:乘客所持票的价格(浮点数,0-500不等) 【数值特征】
- Cabin:乘客所在船舱(有缺失) 【添加“所在船舱是否缺失”作为辅助特征】
- Embarked:乘客登船港口:S、C、Q(有缺失)【转换成onehot编码,四维度 S,C,Q,nan】
2、探索数据
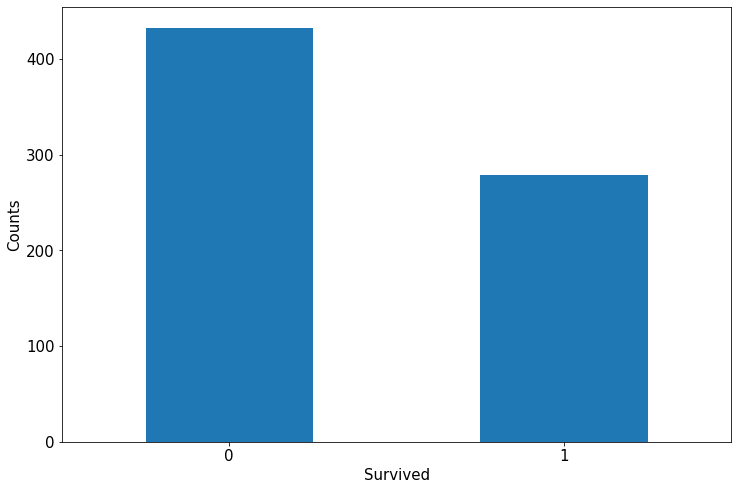
(1)标签分布
%matplotlib inline
%config InlineBackend.figure_format = 'png'
ax = dftrain_raw['Survived'].value_counts().plot(kind = 'bar',
figsize = (12,8),fontsize=15,rot = 0)
ax.set_ylabel('Counts',fontsize = 15)
ax.set_xlabel('Survived',fontsize = 15)
plt.show()
(2) 年龄分布
年龄分布情况 %matplotlib inline
%config InlineBackend.figure_format = 'png'
ax = dftrain_raw['Age'].plot(kind = 'hist',bins = 20,color= 'purple',
figsize = (12,8),fontsize=15) ax.set_ylabel('Frequency',fontsize = 15)
ax.set_xlabel('Age',fontsize = 15)
plt.show()

(3) 年龄和标签之间的相关性
%matplotlib inline
%config InlineBackend.figure_format = 'png'
ax = dftrain_raw.query('Survived == 0')['Age'].plot(kind = 'density',
figsize = (12,8),fontsize=15)
dftrain_raw.query('Survived == 1')['Age'].plot(kind = 'density',
figsize = (12,8),fontsize=15)
ax.legend(['Survived==0','Survived==1'],fontsize = 12)
ax.set_ylabel('Density',fontsize = 15)
ax.set_xlabel('Age',fontsize = 15)
plt.show()

3、数据预处理
(1)将Pclass转换为one-hot编码
dfresult=pd.DataFrame()
#将船票类型转换为one-hot编码
dfPclass=pd.get_dummies(dftrain_raw["Pclass"])
#设置列名
dfPclass.columns =['Pclass_'+str(x) for x in dfPclass.columns]
dfresult = pd.concat([dfresult,dfPclass],axis = 1)
dfresult

(2) 将Sex转换为One-hot编码
#Sex
dfSex = pd.get_dummies(dftrain_raw['Sex'])
dfresult = pd.concat([dfresult,dfSex],axis = 1)
dfresult

(3) 用0填充Age列缺失值,并重新定义一列Age_null用来标记缺失值的位置
#将缺失值用0填充
dfresult['Age'] = dftrain_raw['Age'].fillna(0)
#增加一列数据为Age_null,同时将不为0的数据用0,将为0的数据用1表示,也就是标记出现0的位置
dfresult['Age_null'] = pd.isna(dftrain_raw['Age']).astype('int32')
dfresult

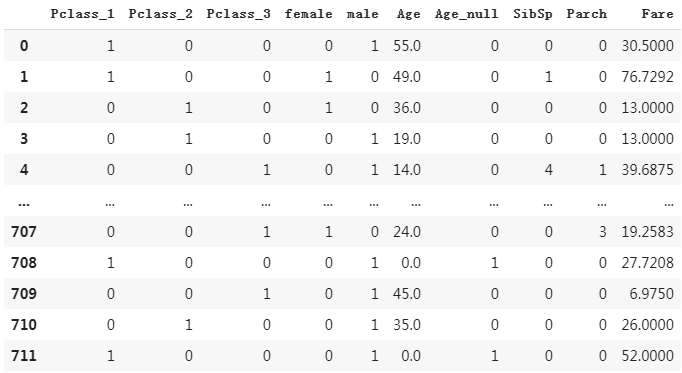
(4) 直接拼接SibSp、Parch、Fare
dfresult['SibSp'] = dftrain_raw['SibSp']
dfresult['Parch'] = dftrain_raw['Parch']
dfresult['Fare'] = dftrain_raw['Fare']
dfresult
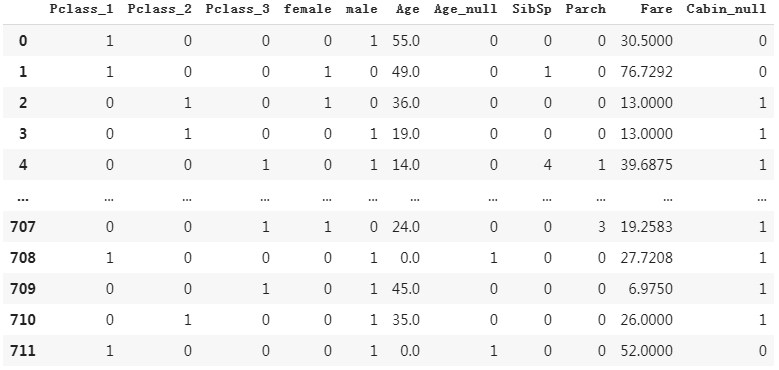
(5) 标记Cabin缺失的位置
#Carbin
dfresult['Cabin_null'] = pd.isna(dftrain_raw['Cabin']).astype('int32')
dfresult
(6)将Embarked转换成one-hot编码
#Embarked
#需要注意的参数是dummy_na=True,将缺失值另外标记出来
dfEmbarked = pd.get_dummies(dftrain_raw['Embarked'],dummy_na=True)
dfEmbarked.columns = ['Embarked_' + str(x) for x in dfEmbarked.columns]
dfresult = pd.concat([dfresult,dfEmbarked],axis = 1)
dfresult
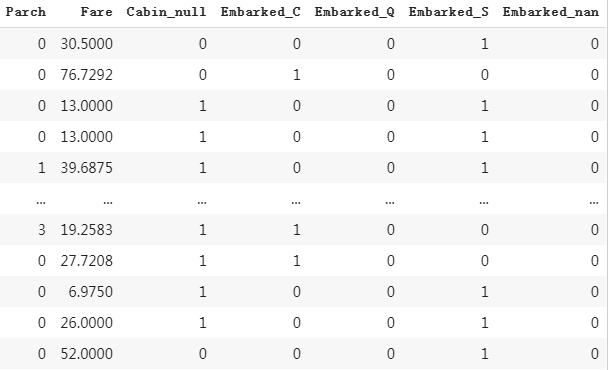
最后,我们将上述操作封装成一个函数:
def preprocessing(dfdata):
dfresult= pd.DataFrame()
#Pclass
dfPclass = pd.get_dummies(dfdata['Pclass'])
dfPclass.columns = ['Pclass_' +str(x) for x in dfPclass.columns ]
dfresult = pd.concat([dfresult,dfPclass],axis = 1)
#Sex
dfSex = pd.get_dummies(dfdata['Sex'])
dfresult = pd.concat([dfresult,dfSex],axis = 1)
#Age
dfresult['Age'] = dfdata['Age'].fillna(0)
dfresult['Age_null'] = pd.isna(dfdata['Age']).astype('int32')
#SibSp,Parch,Fare
dfresult['SibSp'] = dfdata['SibSp']
dfresult['Parch'] = dfdata['Parch']
dfresult['Fare'] = dfdata['Fare']
#Carbin
dfresult['Cabin_null'] = pd.isna(dfdata['Cabin']).astype('int32')
#Embarked
dfEmbarked = pd.get_dummies(dfdata['Embarked'],dummy_na=True)
dfEmbarked.columns = ['Embarked_' + str(x) for x in dfEmbarked.columns]
dfresult = pd.concat([dfresult,dfEmbarked],axis = 1)
return(dfresult)
然后进行数据预处理:
x_train = preprocessing(dftrain_raw)
y_train = dftrain_raw['Survived'].values x_test = preprocessing(dftest_raw)
y_test = dftest_raw['Survived'].values print("x_train.shape =", x_train.shape )
print("x_test.shape =", x_test.shape )
x_train.shape = (712, 15)
x_test.shape = (179, 15)
3、使用tensorflow定义模型
使用Keras接口有以下3种方式构建模型:使用Sequential按层顺序构建模型,使用函数式API构建任意结构模型,继承Model基类构建自定义模型。此处选择使用最简单的Sequential,按层顺序模型。
tf.keras.backend.clear_session() model = models.Sequential()
model.add(layers.Dense(20,activation = 'relu',input_shape=(15,)))
model.add(layers.Dense(10,activation = 'relu' ))
model.add(layers.Dense(1,activation = 'sigmoid' )) model.summary()

4、训练模型
训练模型通常有3种方法,内置fit方法,内置train_on_batch方法,以及自定义训练循环。此处我们选择最常用也最简单的内置fit方法
# 二分类问题选择二元交叉熵损失函数
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['AUC']) history = model.fit(x_train,y_train,
batch_size= 64,
epochs= 30,
validation_split=0.2 #分割一部分训练数据用于验证
)
结果:
Epoch 1/30
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/resource_variable_ops.py:1817: calling BaseResourceVariable.__init__ (from tensorflow.python.ops.resource_variable_ops) with constraint is deprecated and will be removed in a future version.
Instructions for updating:
If using Keras pass *_constraint arguments to layers.
9/9 [==============================] - 0s 30ms/step - loss: 4.3524 - auc: 0.4888 - val_loss: 3.0274 - val_auc: 0.5492
Epoch 2/30
9/9 [==============================] - 0s 6ms/step - loss: 2.7962 - auc: 0.4710 - val_loss: 1.8653 - val_auc: 0.4599
Epoch 3/30
9/9 [==============================] - 0s 6ms/step - loss: 1.6765 - auc: 0.4040 - val_loss: 1.2673 - val_auc: 0.4067
Epoch 4/30
9/9 [==============================] - 0s 7ms/step - loss: 1.1195 - auc: 0.3799 - val_loss: 0.9501 - val_auc: 0.4006
Epoch 5/30
9/9 [==============================] - 0s 6ms/step - loss: 0.8156 - auc: 0.4874 - val_loss: 0.7090 - val_auc: 0.5514
Epoch 6/30
9/9 [==============================] - 0s 5ms/step - loss: 0.6355 - auc: 0.6611 - val_loss: 0.6550 - val_auc: 0.6502
Epoch 7/30
9/9 [==============================] - 0s 6ms/step - loss: 0.6308 - auc: 0.7169 - val_loss: 0.6502 - val_auc: 0.6546
Epoch 8/30
9/9 [==============================] - 0s 6ms/step - loss: 0.6088 - auc: 0.7156 - val_loss: 0.6463 - val_auc: 0.6610
Epoch 9/30
9/9 [==============================] - 0s 6ms/step - loss: 0.6066 - auc: 0.7163 - val_loss: 0.6372 - val_auc: 0.6644
Epoch 10/30
9/9 [==============================] - 0s 6ms/step - loss: 0.5964 - auc: 0.7253 - val_loss: 0.6283 - val_auc: 0.6646
Epoch 11/30
9/9 [==============================] - 0s 7ms/step - loss: 0.5876 - auc: 0.7326 - val_loss: 0.6253 - val_auc: 0.6717
Epoch 12/30
9/9 [==============================] - 0s 6ms/step - loss: 0.5827 - auc: 0.7409 - val_loss: 0.6195 - val_auc: 0.6708
Epoch 13/30
9/9 [==============================] - 0s 6ms/step - loss: 0.5769 - auc: 0.7489 - val_loss: 0.6170 - val_auc: 0.6762
Epoch 14/30
9/9 [==============================] - 0s 6ms/step - loss: 0.5719 - auc: 0.7555 - val_loss: 0.6156 - val_auc: 0.6803
Epoch 15/30
9/9 [==============================] - 0s 6ms/step - loss: 0.5662 - auc: 0.7629 - val_loss: 0.6119 - val_auc: 0.6826
Epoch 16/30
9/9 [==============================] - 0s 6ms/step - loss: 0.5627 - auc: 0.7694 - val_loss: 0.6107 - val_auc: 0.6892
Epoch 17/30
9/9 [==============================] - 0s 6ms/step - loss: 0.5586 - auc: 0.7753 - val_loss: 0.6084 - val_auc: 0.6927
Epoch 18/30
9/9 [==============================] - 0s 6ms/step - loss: 0.5539 - auc: 0.7837 - val_loss: 0.6051 - val_auc: 0.6983
Epoch 19/30
9/9 [==============================] - 0s 7ms/step - loss: 0.5479 - auc: 0.7930 - val_loss: 0.6011 - val_auc: 0.7056
Epoch 20/30
9/9 [==============================] - 0s 9ms/step - loss: 0.5451 - auc: 0.7986 - val_loss: 0.5996 - val_auc: 0.7128
Epoch 21/30
9/9 [==============================] - 0s 7ms/step - loss: 0.5406 - auc: 0.8047 - val_loss: 0.5962 - val_auc: 0.7192
Epoch 22/30
9/9 [==============================] - 0s 6ms/step - loss: 0.5357 - auc: 0.8123 - val_loss: 0.5948 - val_auc: 0.7212
Epoch 23/30
9/9 [==============================] - 0s 6ms/step - loss: 0.5295 - auc: 0.8181 - val_loss: 0.5928 - val_auc: 0.7267
Epoch 24/30
9/9 [==============================] - 0s 6ms/step - loss: 0.5275 - auc: 0.8223 - val_loss: 0.5910 - val_auc: 0.7296
Epoch 25/30
9/9 [==============================] - 0s 6ms/step - loss: 0.5263 - auc: 0.8227 - val_loss: 0.5884 - val_auc: 0.7325
Epoch 26/30
9/9 [==============================] - 0s 7ms/step - loss: 0.5199 - auc: 0.8313 - val_loss: 0.5860 - val_auc: 0.7356
Epoch 27/30
9/9 [==============================] - 0s 6ms/step - loss: 0.5145 - auc: 0.8356 - val_loss: 0.5835 - val_auc: 0.7386
Epoch 28/30
9/9 [==============================] - 0s 6ms/step - loss: 0.5138 - auc: 0.8383 - val_loss: 0.5829 - val_auc: 0.7402
Epoch 29/30
9/9 [==============================] - 0s 7ms/step - loss: 0.5092 - auc: 0.8405 - val_loss: 0.5806 - val_auc: 0.7416
Epoch 30/30
9/9 [==============================] - 0s 6ms/step - loss: 0.5082 - auc: 0.8394 - val_loss: 0.5792 - val_auc: 0.7424
5、评估模型
我们首先评估一下模型在训练集和验证集上的效果。
%matplotlib inline
%config InlineBackend.figure_format = 'svg' import matplotlib.pyplot as plt def plot_metric(history, metric):
train_metrics = history.history[metric]
val_metrics = history.history['val_'+metric]
epochs = range(1, len(train_metrics) + 1)
plt.plot(epochs, train_metrics, 'bo--')
plt.plot(epochs, val_metrics, 'ro-')
plt.title('Training and validation '+ metric)
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend(["train_"+metric, 'val_'+metric])
plt.show()
plot_metric(history,"loss")
plot_metric(history,"auc")


然后看在在测试集上的效果:
model.evaluate(x = x_test,y = y_test)
结果:
6/6 [==============================] - 0s 2ms/step - loss: 0.5286 - auc: 0.7869
[0.5286471247673035, 0.786877453327179]
6、使用模型
(1)预测概率
model.predict(x_test[0:10])
结果:
array([[0.34822357],
[0.4793241 ],
[0.43986577],
[0.7916608 ],
[0.50268507],
[0.536609 ],
[0.29079646],
[0.6085641 ],
[0.34384924],
[0.17756936]], dtype=float32)
(2)预测类别
model.predict_classes(x_test[0:10])
结果:
WARNING:tensorflow:From <ipython-input-36-a161a0a6b51e>:1: Sequential.predict_classes (from tensorflow.python.keras.engine.sequential) is deprecated and will be removed after 2021-01-01.
Instructions for updating:
Please use instead:* `np.argmax(model.predict(x), axis=-1)`, if your model does multi-class classification (e.g. if it uses a `softmax` last-layer activation).* `(model.predict(x) > 0.5).astype("int32")`, if your model does binary classification (e.g. if it uses a `sigmoid` last-layer activation).
array([[0],
[0],
[0],
[1],
[1],
[1],
[0],
[1],
[0],
[0]], dtype=int32)
7、保存模型
可以使用Keras方式保存模型,也可以使用TensorFlow原生方式保存。前者仅仅适合使用Python环境恢复模型,后者则可以跨平台进行模型部署。推荐使用后一种方式进行保存
1)使用keras方式保存
# 保存模型结构及权重
model.save('./data/keras_model.h5')
del model #删除现有模型
(1)加载模型
# identical to the previous one
model = models.load_model('./data/keras_model.h5')
model.evaluate(x_test,y_test)
WARNING:tensorflow:Error in loading the saved optimizer state. As a result, your model is starting with a freshly initialized optimizer.
6/6 [==============================] - 0s 2ms/step - loss: 0.5286 - auc_1: 0.7869
[0.5286471247673035, 0.786877453327179]
(2)保存模型结构和恢复模型结构
# 保存模型结构
json_str = model.to_json()
# 恢复模型结构
model_json = models.model_from_json(json_str)
(3)保存模型权重
# 保存模型权重
model.save_weights('./data/keras_model_weight.h5')
(4)恢复模型结构并加载权重
# 恢复模型结构
model_json = models.model_from_json(json_str)
model_json.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['AUC']
) # 加载权重
model_json.load_weights('./data/keras_model_weight.h5')
model_json.evaluate(x_test,y_test)
6/6 [==============================] - 0s 3ms/step - loss: 0.5217 - auc: 0.8123
[0.521678626537323, 0.8122605681419373]
2)tensorflow原生方式
# 保存权重,该方式仅仅保存权重张量
model.save_weights('./data/tf_model_weights.ckpt',save_format = "tf")
# 保存模型结构与模型参数到文件,该方式保存的模型具有跨平台性便于部署 model.save('./data/tf_model_savedmodel', save_format="tf")
print('export saved model.') model_loaded = tf.keras.models.load_model('./data/tf_model_savedmodel')
model_loaded.evaluate(x_test,y_test)
INFO:tensorflow:Assets written to: ./data/tf_model_savedmodel/assets
export saved model.
6/6 [==============================] - 0s 2ms/step - loss: 0.5286 - auc_1: 0.7869
[0.5286471247673035, 0.786877453327179]
参考:
开源电子书地址:https://lyhue1991.github.io/eat_tensorflow2_in_30_days/
GitHub 项目地址:https://github.com/lyhue1991/eat_tensorflow2_in_30_days
【tensorflow2.0】处理结构化数据-titanic生存预测的更多相关文章
- MySQL 5.7:非结构化数据存储的新选择
本文转载自:http://www.innomysql.net/article/23959.html (只作转载, 不代表本站和博主同意文中观点或证实文中信息) 工作10余年,没有一个版本能像MySQL ...
- 利用Gson和SharePreference存储结构化数据
问题的导入 Android互联网产品通常会有很多的结构化数据需要保存,比如对于登录这个流程,通常会保存诸如username.profile_pic.access_token等等之类的数据,这些数据可以 ...
- seo之google rich-snippets丰富网页摘要结构化数据(微数据)实例代码
seo之google rich-snippets丰富网页摘要结构化数据(微数据)实例代码 网页摘要是搜索引擎搜索结果下的几行字,用户能通过网页摘要迅速了解到网页的大概内容,传统的摘要是纯文字摘要,而结 ...
- 【阿里云产品公测】结构化数据服务OTS之JavaSDK初体验
[阿里云产品公测]结构化数据服务OTS之JavaSDK初体验 作者:阿里云用户蓝色之鹰 一.OTS简单介绍 OTS 是构建在阿里云飞天分布式系统之上的NoSQL数据库服务,提供海量结构化数据的存储和实 ...
- 详解Google-ProtoBuf中结构化数据的编码
本文的主要内容是google protobuf中序列化数据时用到的编码规则,但是,介绍具体的编码规则之前,我觉得有必要先简单介绍一下google protobuf.因此,本文首先会介绍一些google ...
- TensorFlow从1到2(六)结构化数据预处理和心脏病预测
结构化数据的预处理 前面所展示的一些示例已经很让人兴奋.但从总体看,数据类型还是比较单一的,比如图片,比如文本. 这个单一并非指数据的类型单一,而是指数据组成的每一部分,在模型中对于结果预测的影响基本 ...
- Solr系列四:Solr(solrj 、索引API 、 结构化数据导入)
一.SolrJ介绍 1. SolrJ是什么? Solr提供的用于JAVA应用中访问solr服务API的客户端jar.在我们的应用中引入solrj: <dependency> <gro ...
- 零基础学Python之结构化数据(附详细的代码解释和执行结果截图)
3结构化数据 字典(查找表).集合.元组.列表 3.1字典 是有两列任意多行的表,第一列存储一个键,第二列存储一个值. 它存储键/值对,每个唯一的键有一个唯一与之关联的值.(类似于映射.表) 它不会维 ...
- Bigtable:一个分布式的结构化数据存储系统
Bigtable:一个分布式的结构化数据存储系统 摘要 Bigtable是一个管理结构化数据的分布式存储系统,它被设计用来处理海量数据:分布在数千台通用服务器上的PB级的数据.Google的很多项目将 ...
随机推荐
- web前端——美化效果总结
概述 项目开发过程中使用到了不少web前端美化效果的方法,总结一下 1 图片作为背景 要实现的效果是,任意一张图片"img-page-background.png",不需要调整图片 ...
- JZOJ 3928. 【NOIP2014模拟11.6】射击
3928. [NOIP2014模拟11.6]射击 (Standard IO) Time Limits: 1000 ms Memory Limits: 65536 KB Description 有问题, ...
- vs远程调试iis
1.在开发电脑上 找到 D:\Software\VS2010\Common7\IDE\Remote Debugger 下面msvsmon.exe所在的两个文件夹x86和x64,使用x86或者x64是根 ...
- openwrt 外挂usb 网卡 RTL8188CU 及添加 RT5572 kernel支持
RT5572 原来叫 Ralink雷凌 现在被 MTK 收购了,淘宝上买的很便宜50块邮,2.4 5G 双频.在 win10 上插了试试,果然是支持 5G.这上面写着 飞荣 是什么牌子,有知道的和我说 ...
- 【09】openlayers 图片图层
效果: 创建地图: var map = new ol.Map({ //设置显示地图的视图 view: new ol.View({ projection:'EPSG:4326',//投影方式 cent ...
- MATLAB神经网络(1)之R练习
)之R练习 将在MATLAB神经网络中学到的知识用R进行适当地重构,再写一遍,一方面可以加深理解和记忆,另一方面练习R,比较R和MATLAB的不同.如要在R中使用之前的数据,应首先在MATLAB中用w ...
- node 微信退款
基于node 的微信退款 申请微信退款:微信退款, 1.在前端页面访问 /refund var request = require('request'); var WxPayRefund = req ...
- java实现QQ、微信、轰炸机,撩妹,抖图功能,轻松自如
今天交大家一个很牛的功能,让你朋友服你,他不扶你你来找我. 打游戏被骂,骂不过你来找我,我们有神器,直到他怕了为止. 废话少说,代码如下,动手,干就完了 乞丐版如下 参考连接:Java实现QQ微信轰炸 ...
- Axure rp8 注册码,亲测可以用! 可用给个赞呗!!
License:zdfans Key:fZw2VoYzXakllUuLVdTH13QYWnjD6NZrxgubQkaRyxD5+HNMqdr+WZKkaa6IoE5N
- NeurIPS 2019 Spotlight | Cascade RPN,结构的艺术带来极致的提升
论文提出Cascade RPN算法来提升RPN模块的性能,该算法重点解决了RPN在迭代时anchor和feature不对齐的问题,论文创新点足,效果也很惊艳,相对于原始的RPN提升13.4%AR 论文 ...