第4章 最基础的分类算法-k近邻算法
思想极度简单
应用数学知识少
效果好(缺点?)
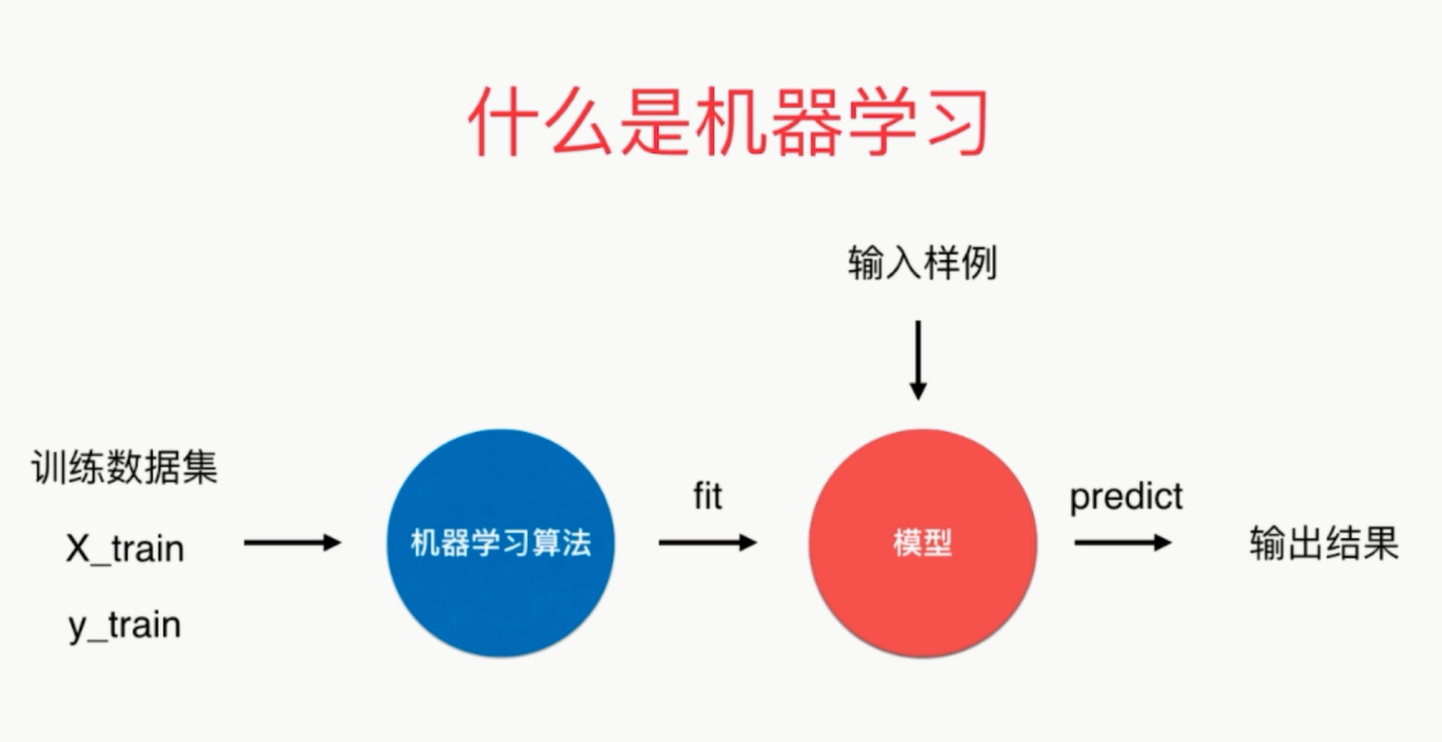
可以解释机器学习算法使用过程中的很多细节问题
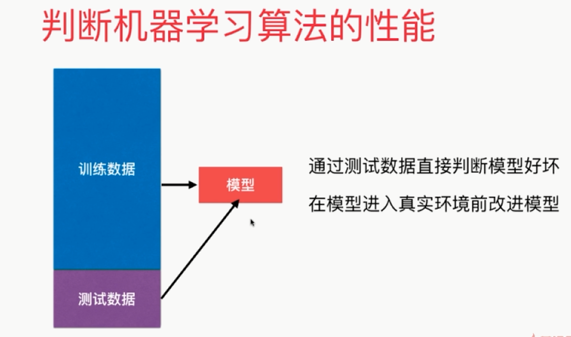
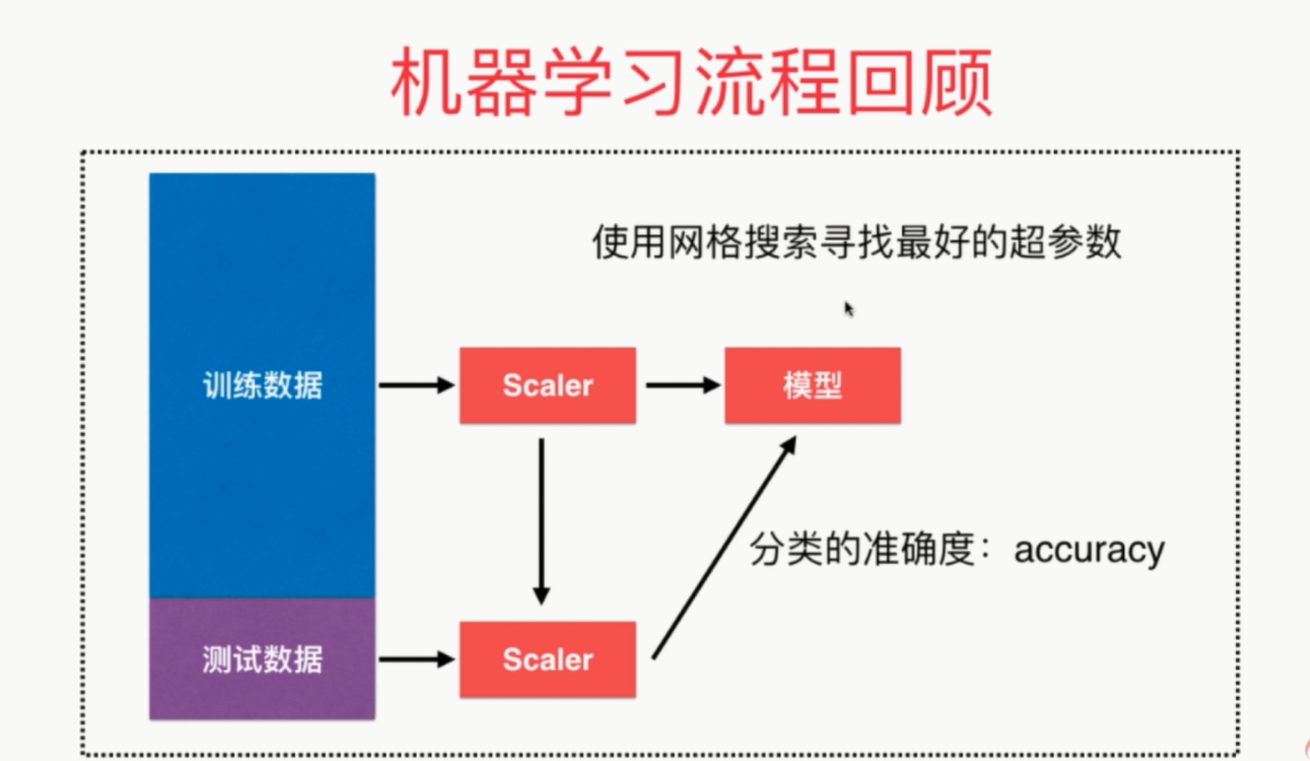
更完整的刻画机器学习应用的流程


distances = []
for x_train in X_train:
d=sqrt(np.sum((x_train-x)**2))
distances.append(d)
distances=[sqrt(np.sum((x_train-x)**2)) for x_train in X_train]
可以说kNN是一个不需要训练过程的算法
K近邻算法是非常特殊的,可以被认为是没有模型的算法
为了和其他算法统一,可以认为训练数据集就是模型本身
kNN:
from sklearn.neighbors import KNeighborsClassifier
kNN_classifier=KNeighborsClassifier(n_neighbors=6)
kNN_classifier.fit(X_train,y_train)
kNN_classifier.predict(x)
有关K近邻算法
解决分类问题
天然可以解决多分类问题
思想简单,效果强大
使用k近邻算法解决回归问题
KNeighborsRegressor
kNN:
from sklearn.neighbors import KNeighborsClassifier
kNN_classifier=KNeighborsClassifier(n_neighbors=6)
kNN_classifier.fit(X_train,y_train)
kNN_classifier.predict(x)




须考虑距离的权重!通常是将距离的倒数作为权重





相当于因为距离又获得了一个超参数

寻找最好的k,调参
best_score = 0.0
besk_k = -1
for k in range(1,11):
knn_clf = KNeighborsClassifier(n_neighbors=k)
knn_clf.fit(X_train,y_train)
score = knn_clf.score(X_test,y_test)
if score>best_score:
best_k=k
best_score=score print('best_k=',best_k)
print('best_score=',best_score) 考虑距离?
best_method = ''
best_score = 0.0
besk_k = -1
for method in ['uniform','distance']:
for k in range(1,11):
knn_clf = KNeighborsClassifier(n_neighbors=k,weights=method)
knn_clf.fit(X_train,y_train)
score = knn_clf.score(X_test,y_test)
if score>best_score:
best_k=k
best_score=score
best_method = method
print('best_k=',best_k)
print('best_score=',best_score)
print('best_method',best_method) 搜索明可夫斯基距离相应的p
%%time
best_p = -1
best_score = 0.0
besk_k = -1
for k in range(1,11):
for p in range(1,6):
knn_clf = KNeighborsClassifier(n_neighbors=k,weights='distance',p = p)
knn_clf.fit(X_train,y_train)
score = knn_clf.score(X_test,y_test)
if score>best_score:
best_k=k
best_score=score
best_p=p
print('best_k=',best_k)
print('best_score=',best_score)
print('best_p=',best_p)



缺点2:高度数据相关
缺点3:预测的结果不具有可解释性
缺点4:维数灾难
随着维度的增加,‘看似相近’的的两个点之间的距离越来越大

解决方法:降维(PCA)
# coding=utf-8
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
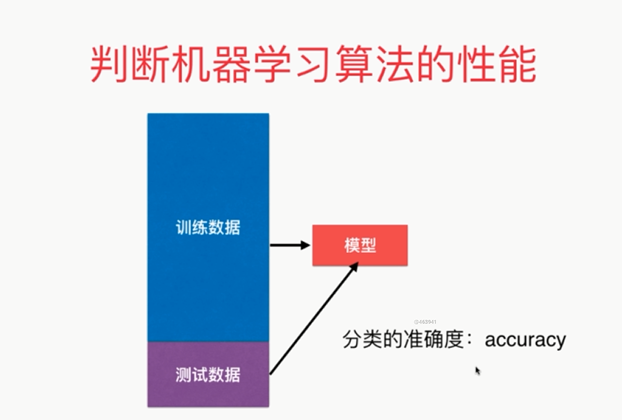
from sklearn.metrics import accuracy_score # 分类的准确度
from sklearn.model_selection import GridSearchCV iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=666)
standardScaler = StandardScaler() # 创建实例
standardScaler.fit(X_train)
# standardScaler.mean_
# standardScaler.scale_
X_train = standardScaler.transform(X_train) # 使用transform方法进行归一化
X_test_standard = standardScaler.transform(X_test) # 寻找最好的参数K
# param_grid = [
# {
# 'weights': ['uniform'],
# 'n_neighbors': [i for i in range(1, 11)]
# },
# {
# 'weights': ['distance'],
# 'n_neighbors': [i for i in range(1, 11)],
# 'p': [i for i in range(1, 6)]
# }
# ]
# knn_clf = KNeighborsClassifier()
# grid_search = GridSearchCV(knn_clf, param_grid)
# grid_search.fit(X_train, y_train)
# print(grid_search.best_estimator_, grid_search.best_params_, grid_search.best_score_)
# knn_clf.predict(X_test)
# knn_clf.score(X_test, y_test) knn_clf = KNeighborsClassifier(n_neighbors=3)
knn_clf.fit(X_train, y_train) # X_train已经进行了归一化
print(knn_clf.score(X_test_standard, y_test))
# 或者
y_predict = knn_clf.predict(X_test_standard)
print(accuracy_score(y_test, y_predict))
knn_clf.score(X_test_standard, y_test)
个人整个流程代码
第4章 最基础的分类算法-k近邻算法的更多相关文章
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- 分类算法----k近邻算法
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的 ...
- 机器学习(四) 机器学习(四) 分类算法--K近邻算法 KNN (下)
六.网格搜索与 K 邻近算法中更多的超参数 七.数据归一化 Feature Scaling 解决方案:将所有的数据映射到同一尺度 八.scikit-learn 中的 Scaler preprocess ...
- python 机器学习(二)分类算法-k近邻算法
一.什么是K近邻算法? 定义: 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. 来源: KNN算法最早是由Cover和Hart提 ...
- 最基础的分类算法-k近邻算法 kNN简介及Jupyter基础实现及Python实现
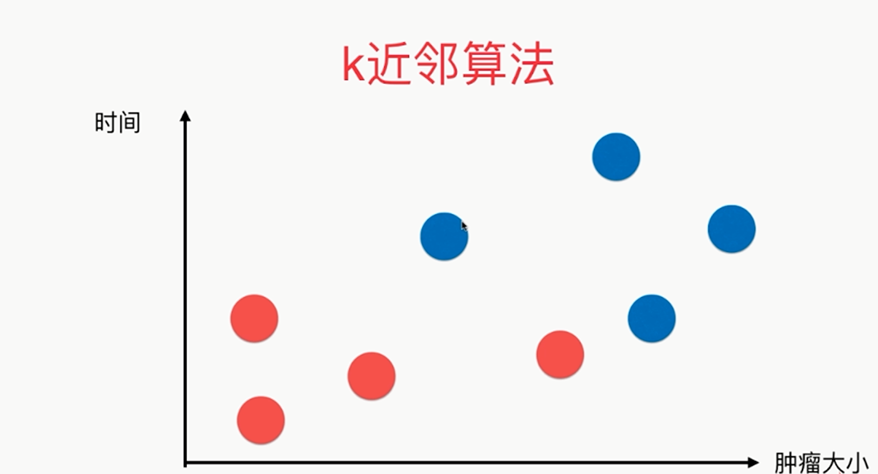
k-Nearest Neighbors简介 对于该图来说,x轴对应的是肿瘤的大小,y轴对应的是时间,蓝色样本表示恶性肿瘤,红色样本表示良性肿瘤,我们先假设k=3,这个k先不考虑怎么得到,先假设这个k是 ...
- 【学习笔记】分类算法-k近邻算法
k-近邻算法采用测量不同特征值之间的距离来进行分类. 优点:精度高.对异常值不敏感.无数据输入假定 缺点:计算复杂度高.空间复杂度高 使用数据范围:数值型和标称型 用例子来理解k-近邻算法 电影可以按 ...
- k近邻算法
k 近邻算法是一种基本分类与回归方法.我现在只是想讨论分类问题中的k近邻法.k近邻算法的输入为实例的特征向量,对应于特征空间的点,输出的为实例的类别.k邻近法假设给定一个训练数据集,其中实例类别已定. ...
- 机器学习03:K近邻算法
本文来自同步博客. P.S. 不知道怎么显示数学公式以及排版文章.所以如果觉得文章下面格式乱的话请自行跳转到上述链接.后续我将不再对数学公式进行截图,毕竟行内公式截图的话排版会很乱.看原博客地址会有更 ...
- 02-16 k近邻算法
目录 k近邻算法 一.k近邻算法学习目标 二.k近邻算法引入 三.k近邻算法详解 3.1 k近邻算法三要素 3.1.1 k值的选择 3.1.2 最近邻算法 3.1.3 距离度量的方式 3.1.4 分类 ...
随机推荐
- 国际站中国区,孟买上Redis 4.0 集群版
信息摘要: 国际站中国区,孟买上线Redis 4.0 集群版适用客户: 所有用户版本/规格功能: redis 4.0 集群版产品文档: https://www.alibabacloud.com/hel ...
- POJ - 3278 Catch That Cow 简单搜索
Farmer John has been informed of the location of a fugitive cow and wants to catch her immediately. ...
- muduo网络库源码学习————线程本地单例类封装
muduo库中线程本地单例类封装代码是ThreadLocalSingleton.h 如下所示: //线程本地单例类封装 // Use of this source code is governed b ...
- 《C程序设计语言》 练习1-22
问题描述 练习1-22 编写一个程序,把较长的输入行“折”成短一些的两行或者多行,折行的位置在输入行的第N列之前的最后一个非空格之后.要保持程序能够智能地处理输入行很长以及在制定的列前没有空格或者制表 ...
- B站弹幕系统架构——GOIM解读
架构图 说明: 1.logic启动http服务器, 接受http请求,用于将数据推送到kafka以及获取在线用户信息,websocket身份校验 2.comet组件起动webdocket/tcp服务, ...
- 70行实现Promise核心源码
70行实现Promise核心源码 前言: 一直以来都是只会调用Promise的API,而且调API还是调用axios封装好的Promise,太丢人了!!!没有真正的去了解过它的原理是如何实现的,自 ...
- schedule定时任务出现问题 (大坑已填)!!
因为python每次运行完,并不清除内存,nowtime一直不变,这导致了一个致命问题,使我的脚本一直运行失败,具体如下: 我设置的是每隔30分钟登陆一次,代码如下 if __name__ == &q ...
- 带你看看Java的锁(一)-ReentrantLock
前言 AQS一共花了5篇文章,对里面实现的核心源码都做了注解 也和大家详细描述了下,后面的几篇文字我将和大家聊聊一下AQS的实际使用,主要会聊几张锁,第一篇我会和大家聊下ReentrantLock 重 ...
- MOS管和三极管开关特性
不知道对不对? 待续!!!
- Mysql常用sql语句(18)- union 全连接
测试必备的Mysql常用sql语句系列 https://www.cnblogs.com/poloyy/category/1683347.html 前言 其实Mysql并没有全连接,Oracle才有全连 ...