Node.js 薄荷网爬取
Node.js:是一个基于前端的服务器,主要的特点:单线程,异步I/O(对这个没有了解,开发起来真的会踩很多坑),事件驱动
前言:本人主要是一个以使用.Net平台下的语言,进行开发的一个菜鸡,之前面试这家公司的时候,面试官问我一个问题给你一个页面里面有十页的分页数据,你能使用什么技术将这些数据全部抓取出来。对于当时刚毕业的我听到这个问题,心里一下想到python(对它没有任何的了解,我以为python只是用来做数据挖掘的,对这门语言完全没了解过贸然吹牛感觉会被打脸),然后我尴尬的说了句在网页控制台里使用jquery或者js,抓当前页的数据(只是在控制台里展示出来,还不能入库),面试官听到这个回答,我只看到了他嘴角上扬了一下,但是最后居然还是奇迹般的通过了面试,进入了这家公司直到现在,非常感恩这次机会,算是让我正式步入了IT这个行业,成为一名专业的编程人员吧。
之后我尝试过使用c#的WebBrowser对象,Python的HTMLSession包来抓这个薄荷网的数据,最后在对比的时候还是觉得Node.js(异步搞清楚之后)好使,在Node.js里那些已经被大神们封装好的包,直接拿来使用就行,几乎只需要一点点的HTML层级结构知识,一点jQuery选择器知识差不多就能将整个网页的数据进行爬取了。
薄荷网地址:http://www.boohee.com/food/,这个网站的 热量查询板块 非常适合拿来练手( 还是程序员自己人坑自己人呀!哈哈哈哈哈,还是给人家打一波广告吧,虽然没什么流量,哈哈哈哈) 薄荷 减肥健身 掌控人生 专业的在线体重管理平台 强大的食品营养数据库
抓取接口使用python的requests包进行抓取数据较好,在接口数据返回之后,会自动将数据转换为元组类型,在c#中需要手段将数据转换为JObject 然后再对应进行取值
抓取web网页数据用nodejs较好,使用cheerio包可以直接将获取到的web页面进行 jQuery 语法操作获取个性化数据
源码
GitHub:https://github.com/loyking/NodeJs.git
下载包语法:
npm install packagename
需要导入的包: var http = require("http"), //http协议请求
url = require("url"), //url地址
sql = require("mssql"), //数据库操作
express = require("express"), //框架
superagent = require("superagent"), //网络请求(注意:没有连接网络,则请求不了网页)
eventproxy = require("eventproxy"), //异步回调
cheerio = require("cheerio"), //node.js中的jquery库
uuid = require("uuid/v4"), //v1:产生时间戳的uuid 使用的数据库为SQL server2017版,表中定义的主键类型为uniqueidentifier,在nodejs中对应的则是uuid
async = require("async") //异步
目标:将热量查询板块 =》 薄荷食物库 =》 每个分类中的食物名称、热量、评价.....等等相关数据进行爬取(画的有点丑)

首先进去之后就能看到如下板块了,一共是11个板块分类(图没有截全请不要介意.........)
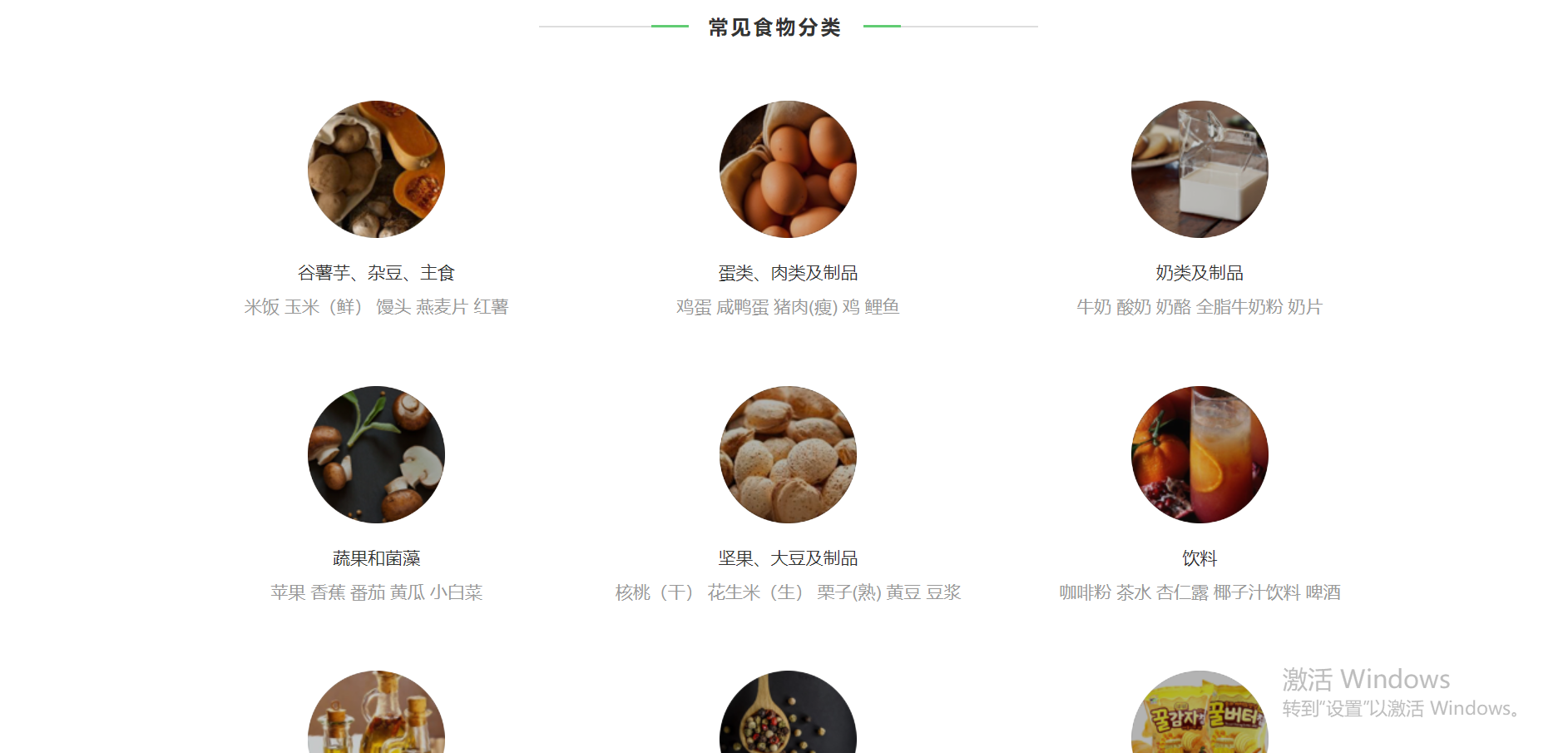
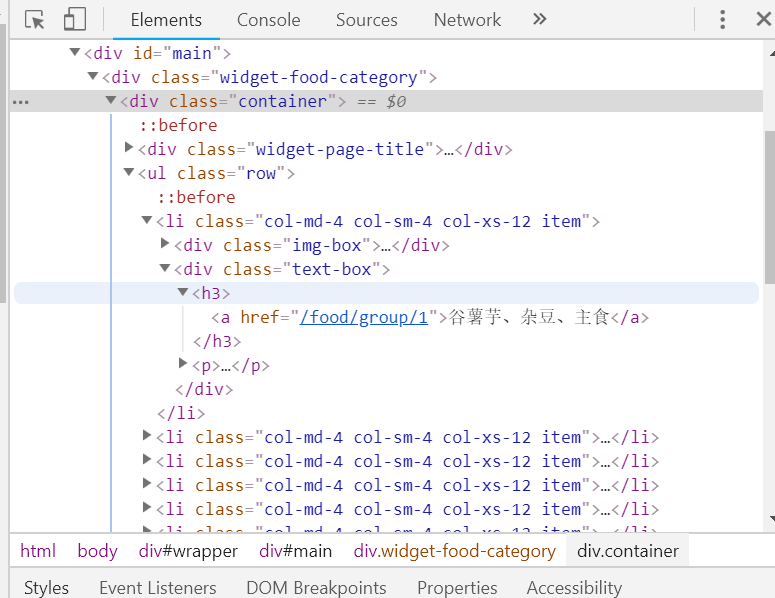
我们现在需要做的第一步就是对这个页面的层级结构进行分析一波,得到我们想要的数据(每个分类板块的url地址),按下F12键打开 开发者工具 查看一下这些分类的层级结构 就是如下图了,我们需要的一级数据(对数据进行一个排序,从父级(分类板块)开始)就是那个a表的href属性了
然后它的层级结构是(我们用jquery选择器来做实例,cheerio包是支持这种jq语法的)
$("#main .container ul[class='row'] li div[class='text-box'] h3 a").attr('href') 其实根本不需要写的这么复杂,这里只是让大家对这个层级有一个清晰的了解
由于我们取到的是对应的分类路径没有带域名的,所以我们等下在程序中是需要定义一个常量来保存域名信息,然后对获取到的href进行字符拼接
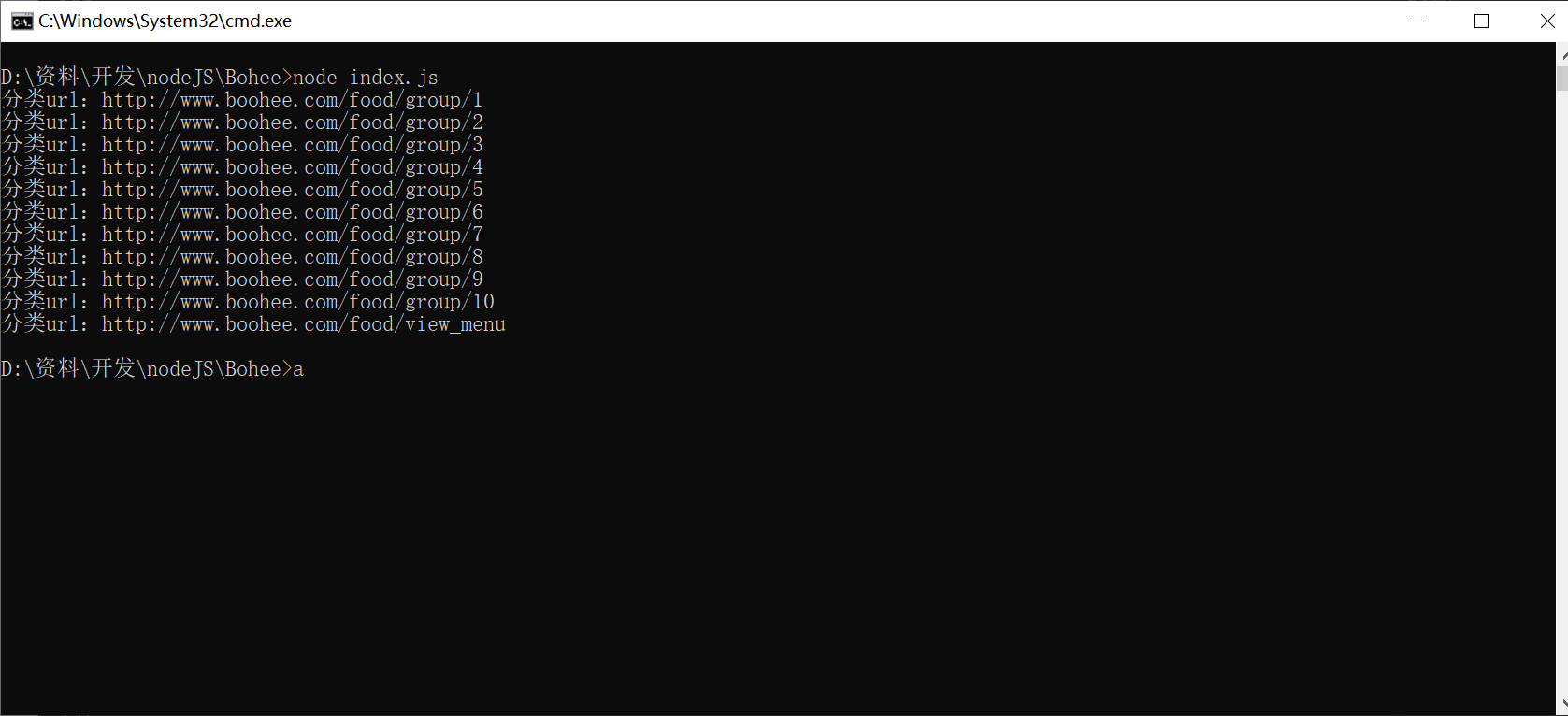
我使用的是Windows下的环境,启动程序之后,控制台进行输出所有的分类url(每个食品分类板块的url)
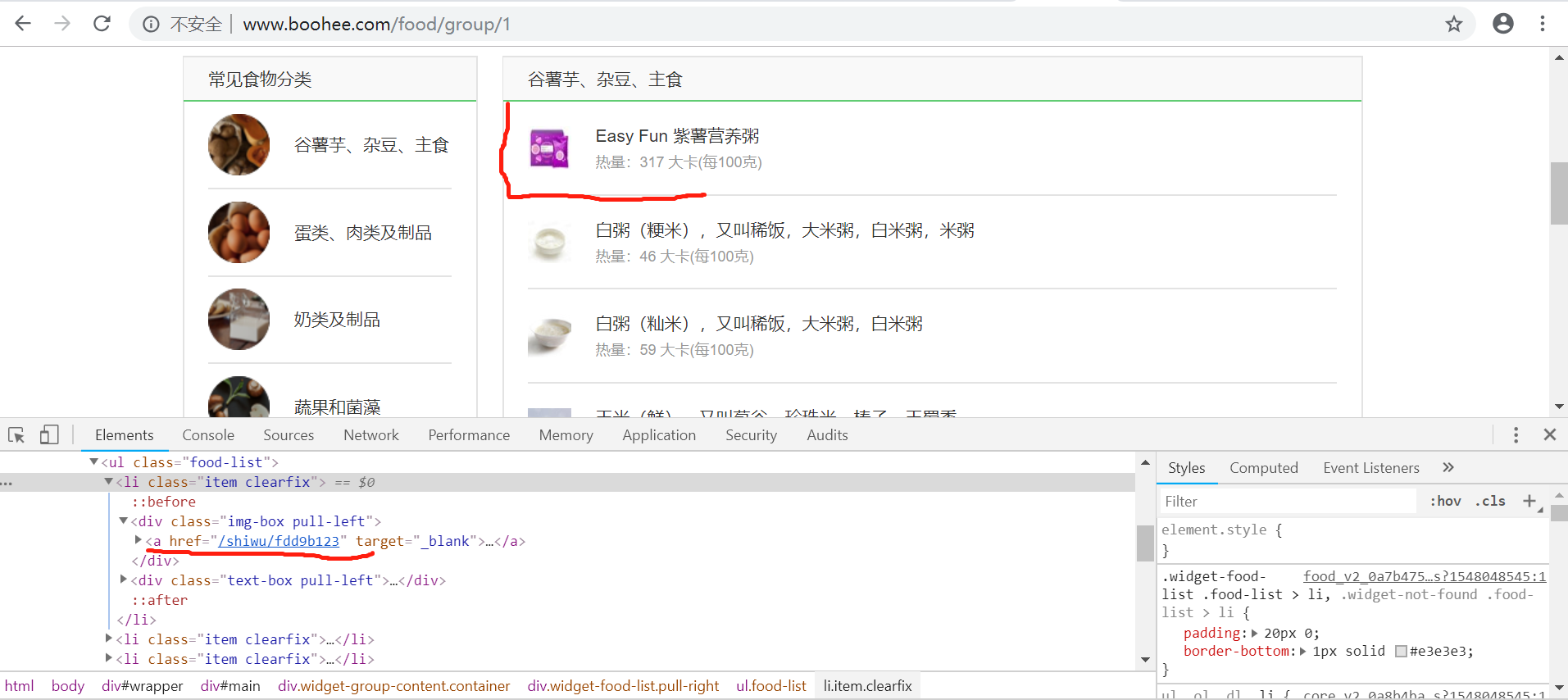
对分类url进行循环遍历,得到所有该板块下所有的食物信息

根据当前板块的url得到所有的食品url信息,根据html层级结构布局来看想要得到所有的食品信息是肯定需要使用循环遍历的
首先得到该食品链接的a标签:$("div[class='img-box pull-left'] a[target='_blank']") ,进行遍历循环然后再单个元素进行attr("href")取得属性值
然后将所有的a标签的href属性进行输出得到如下图信息(在异步的执行中可能不是按照原有页面排版的顺序进行输出)

得到所有的食物url后就能直接请求页面抓取我们想要的数据了
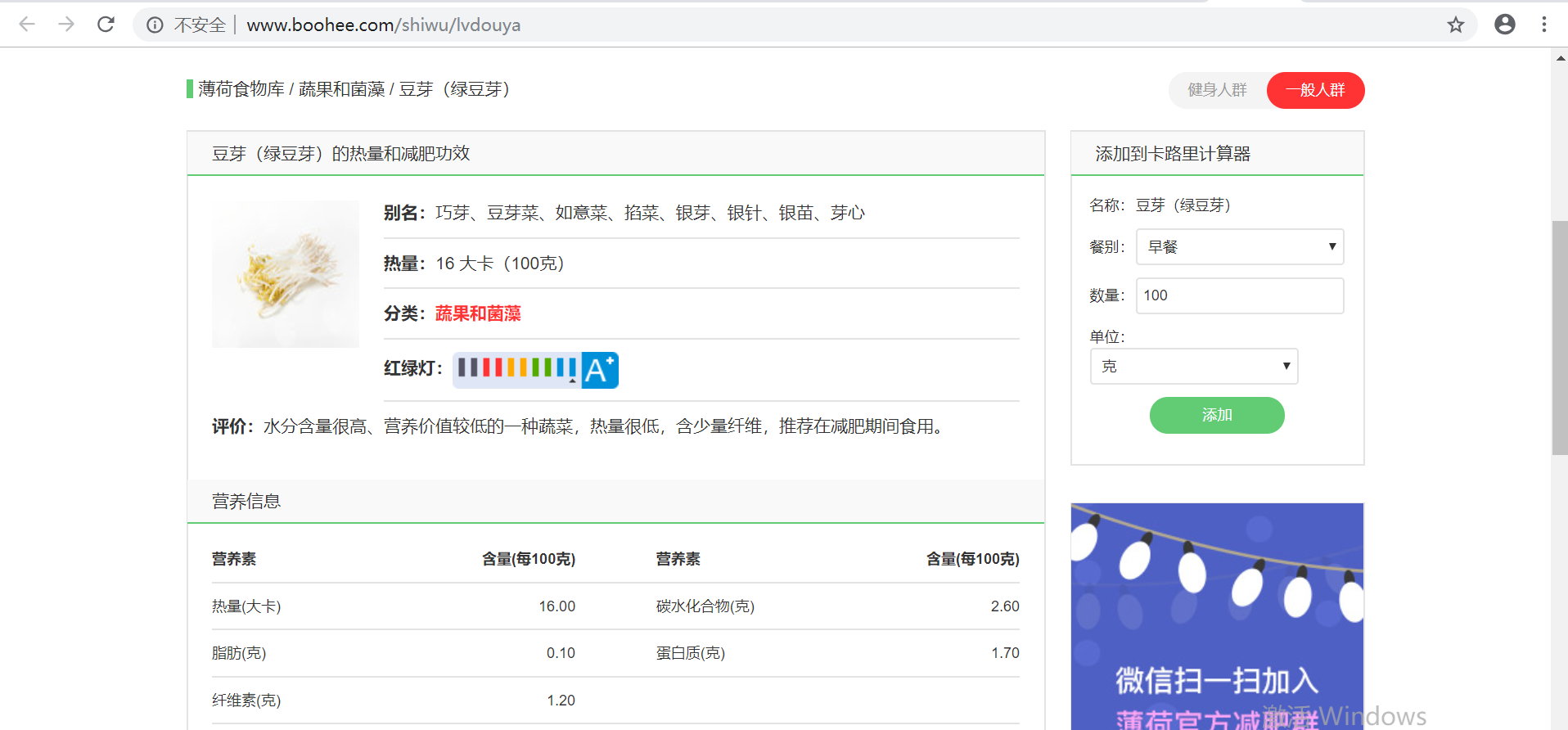
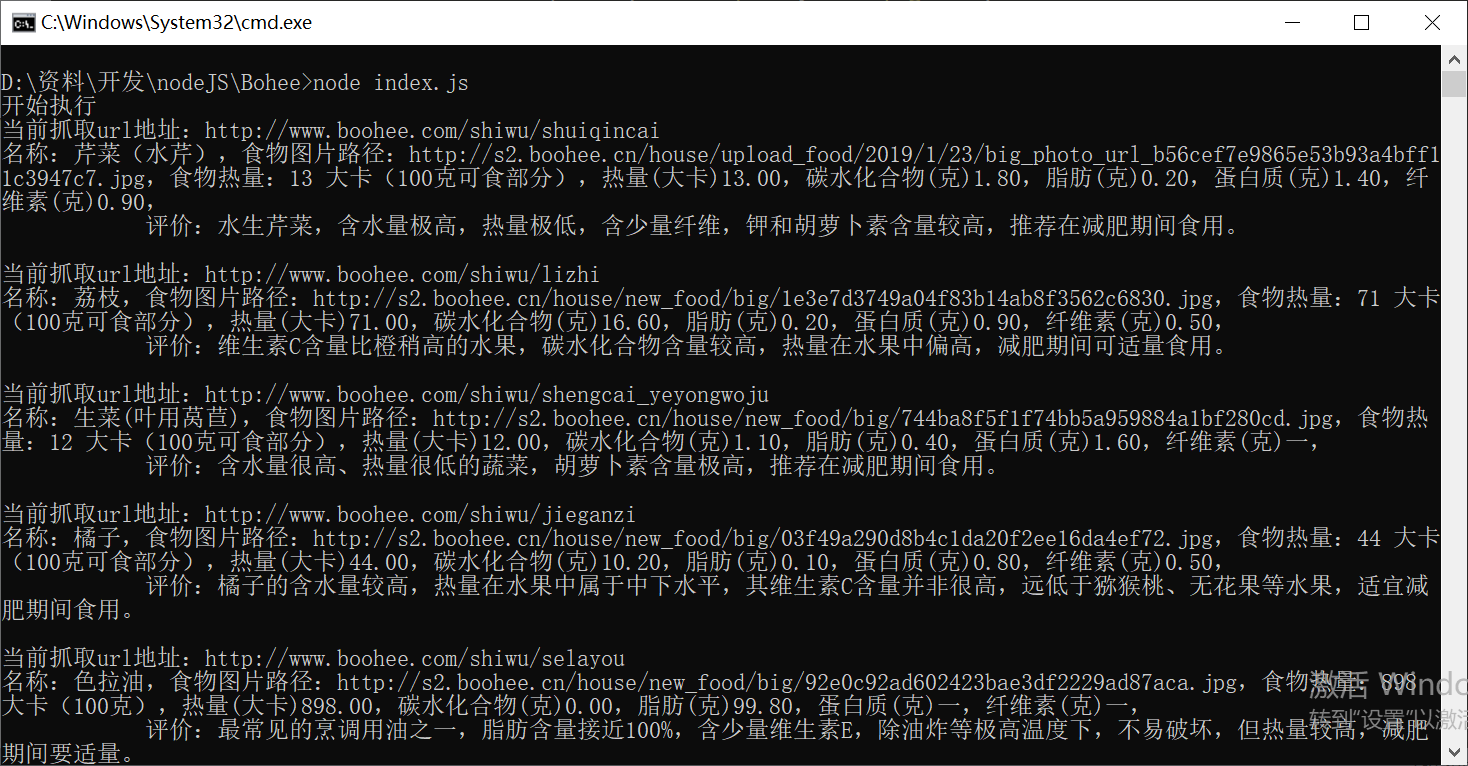
具体内部实现可从GitHub上复制源码下载至本地阅读,抓取数据也许不是程序员开发必备的技能,但是稍微了解了解也是好的,当作成一个辅助技能挺好的
2019转折点的一年啊,加油
开工大吉,哈哈哈接了公司好多红包哦
Node.js 薄荷网爬取的更多相关文章
- Node JS爬虫:爬取瀑布流网页高清图
原文链接:Node JS爬虫:爬取瀑布流网页高清图 静态为主的网页往往用get方法就能获取页面所有内容.动态网页即异步请求数据的网页则需要用浏览器加载完成后再进行抓取.本文介绍了如何连续爬取瀑布流网页 ...
- Node.js 动态网页爬取 PhantomJS 使用入门(转)
Node.js 动态网页爬取 PhantomJS 使用入门 原创NeverSettle101 发布于2017-03-24 09:34:45 阅读数 8309 收藏 展开 版权声明:本文为 winte ...
- Node.js爬虫实战 - 爬你喜欢的
前言 今天没有什么前言,就是想分享些关于爬虫的技术,任性.来吧,各位客官,里边请... 开篇第一问:爬虫是什么嘞? 首先咱们说哈,爬虫不是"虫子",姑凉们不要害怕. 爬虫 - 一种 ...
- 对 js加密数据进行爬取和解密
对 js加密数据进行爬取和解密 分析: 爬取的数据是动态加载 并且我们进行了抓包工具的全局搜索,没有查找到结果 意味着:爬取的数据从服务端请求到的是加密的密文数据 页面每10s刷新一次,刷新后发现数据 ...
- 爬虫-通过本地IP地址从中国天气网爬取当前城市天气情况
1.问题描述 最近在做一个pyqt登录校园网的小项目,想在窗口的状态栏加上当天的天气情况,用爬虫可以很好的解决我的问题. 2.解决思路 考虑到所处位置的不同,需要先获取本地城市地址,然后作为中 ...
- Node.js之网游服务器实践
此文已由作者尧飘海授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 随着Node.js的不断发展与壮大,应用范围也越来越广泛,从传统的企业应用,到互联网使用,再到云计算的发展, ...
- [Python] 前程无忧招聘网爬取软件工程职位 网络爬虫 https://www.51job.com
首先进入该网站的https://www.51job.com/robots.txt页面 给出提示: 找不到该页 File not found 您要查看的页已删除,或已改名,或暂时不可用. 请尝试以下操作 ...
- Node.js爬虫数据抓取乱码问题总结
一.非UTF-8页面处理 1.背景 windows-1251编码 比如俄语网站:https://vk.com/cciinniikk 可耻地发现是这种编码 所有这里主要说的是 Windows-1251( ...
- Node.js爬虫数据抓取 -- 问题总结
一 返回的信息提示 Something went wrong request模块请求出现未知错误 其中,所用代码如下(无User-Agent部分) 问题多次派查无果,包括: 1:postman请 ...
随机推荐
- template or render function not defined vue 突然报错了,怎么解决
报错图例如下:template or render function not defined vue 突然报错了,怎么解决什么错误呢,就是加载不出来,网上看了一通,是vue版本不对,是vue-comp ...
- 360或者金山毒霸可能会导致HP网络打印机驱动安装失败“数据无效”的解决办法
360或者金山毒霸可能会导致HP网络打印机驱动安装失败“数据无效”的解决办法 同事办公室的打印机是网线接口的那种网络打印机,不是直接连到电脑的那种,他电脑安装了360和金山毒霸,WIN10下安 ...
- 和2018年年初做管理系统的不同(vuex)
从2017年底开始做公司批改后台系统(服务内部人员对熊猫小课用户的作业进行批改.对批改员工资结算等)到教务系统(服务于内部人员对熊猫小课等移动端产品的内容进行配置等).ai-boss系统(服务于内部人 ...
- Linux下阅读源代码工具安装
综合他们多篇博客,做一个自己的总结(从0开始,记录过程) 系统:ubuntu 16.04 vim:7.4.1689 内容来源: https://www.cnblogs.com/wangzhe1635 ...
- KongCLI参考
Introduction Kong提供的CLI(Command Line Interface)允许您启动.停止和管理Kong实例.CLI管理您的本地节点(如当前机器上的本地节点). If you ha ...
- OPPO R6007在哪里打开usb调试模式的完美流程
当我们使用Pc接通安卓手机的时候,如果手机没有开启USB开发者调试模式,Pc则无法成功读到我们的手机,遇到此种情况我们需要想方设法将手机的USB开发者调试模式打开,以下内容我们讲解OPPO R6007 ...
- linux dd命令 创造一个文件
创造一个1G的文件 dd if=/dev/zero of=/nod/tmp/test bs=1M count=1024 创造一个1T的文件 [root@oracledg tmp]# dd if=/de ...
- Centos7下GlusterFS分布式存储集群环境部署记录
0)环境准备 GlusterFS至少需要两台服务器搭建,服务器配置最好相同,每个服务器两块磁盘,一块是用于安装系统,一块是用于GlusterFS. 192.168.10.239 GlusterFS-m ...
- 数据帧、MTU、MSS、IP分片
1.以太网帧 在以太网链路上的数据包称作以太帧,在802.3标准里,规定了一个以太帧的数据部分(Payload)的最大长度是1500个字节(MTU),再加上14字节链路头和4字节的FCS,所以以太网帧 ...
- idea基本使用1
首先推荐两个快捷键 alt+Ent 相当于eclipse中的crtl+1 alt+ins :能创建包,类等,还能生成getter,setter,和构造函数 首先创建一个w ...