RPC调用与GC垃圾回收
RPC调用
- 多个服务协同完成一次业务时,由于业务约束(如红包不符合使用条件、账户余额不足等)、系统故障(如网络或系统超时或中断、数据库约束不满足等),都可能造成服务处理过程在任何一步无法继续,使数据处于不一致的状态。传统的基于数据库本地事务的解决方案只能保障单个服务的一次处理具备原子性、隔离性、一致性与持久性,但无法保障多个分布服务间处理的一致性
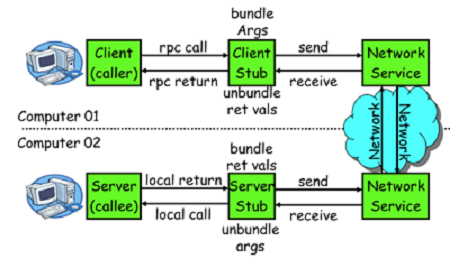
- 分析源代码,基本原理如下:
- client 一个线程调用远程接口,生成一个唯一的 ID (比如一段随机字符串,UUID 等) , Dubbo 是使用 AtomicLong 从 0 开始累计数字的
- 将打包的方法调用信息(如调用的接口名称,方法名称,参数值列表等),和处理结果的回调对象 call back ,全都封装在一起,组成一个对象 0bject
- 向专门存放调用信息的全局 ConcurrentHashMap 里面 put ( ID , object )
- 将 ID 和打包的方法调用信息封装成一对象 connRequest ,使用 Iosession.write ( connRequest )异步发送出去
- 当前线程再使用call back 的get()方法试图获取远程返回的结果,在 get()内部,则使用 Synchronized 获取回调对象 caIlback 的锁,再先检测是否已经获取到结果,如果没有,然后调用 callbaCk 的 wait()方法,释放 callback 上的锁,让当前线程处于等待状态
- 服务端接收到请求并处理后,将结果(此结果中包含了前面的 ID ,即回传)发送给客户端,客户端 socket连接上专门监听消息的线程收到消息,分析结果,取到 ID ,再从前面的ConcurrentHashMap里面 get(ID) ,从而找到 callback ,将方法调用结果设置到 callback 对象里
- 监听线程接着使用 synchronized 获取回调对象 callback 的锁(因为前面调用过 wait ( ) ,那个线程已释放 callback 的锁了),再 notlfyAll ( ) ,唤醒前面处于等待状态的线程继续执行( call back 的 get ( )方法继续执行就能拿到调用结果了),至此,整个过程结束
- 当前线程怎么让它暂停,等结果回来后,再向后执行?
- 先生成一个对象obj ,在一个全局 map 里 put ( 1D obj )存放起来,再用synchronized获取obj锁,再调用obj.wait()让当前线程处于等待状态,然后另一消息监听线程等到服务端结果来了后,再 map.get (ID )找到 obj ,再用 synchronized获取obj 锁,再调用obj.notifyAll唤配前面处于等待状态的线程
- Socket 通信是一个全双工的方式,如果有多个线程同时进行远程方法调用,这时建立在client server之间的socket连接上会有很多双方发送的消息有传递,前后顺序也可能是乱七八嘈的,server处理完结果后,将结果消息发送给 client, client收到很多消息,怎么知道消息结果是原先哪个线程调用的? 使用一个ID ,让其唯一,然后传递给服务端,再服务端又回传回来,这样就知道结果是原先哪个线程的了
GC垃圾回收
年轻代收集器
- Serial收集器:“停止-复制”算法,单线程,进行垃圾收集时必须暂停其他线程的所有工作
- ParNew收集器:Serial收集器的多线程版本,“停止-复制”算法,多线程
- Parallel Scavenge收集器:”停止-复制“算法,并行的多线程收集器,可控制的吞吐量
老年代收集器
- Serial Old:Serial收集器的老年代版本,同样是一个单线程收集器,使用“标记-整理”算法
- Parallel Old收集器:Parallel Scavenge收集器的老年代版本,使用多线程和“标记-整理”算法
- CMS收集器:CMS(Conrrurent Mark Sweep)收集器是以获取最短回收停顿时间为目标的收集器,使用"标记-清除"算法
CMS收集器
- 初始标记:标记GCRoots能直接关联到的对象,时间很短
- 并发标记:进行GCRoots Tracing(可达性分析)过程,时间很长
- 重新标记:修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,时间较长
- 并发清除:清除未标记(无关联引用)的对象,伴随着用户线程的执行,清除后会产生浮动垃圾
- 优缺点:对CPU资源非常敏感,可能会导致应用程序变慢,吞吐率下降,无法处理浮动垃圾,采用的“标记-清除”算法,会产生大量的内存碎片
垃圾回收算法实现
- 停止-复制算法:将内存分为两块,当其中一块内存用完了,将还存活着的对象复制到另一块中,再将使用过的内存一次性清理掉
- 标记-清除算法:首先标记出所有需要回收的对象,标记完成后统一回收所有被标记的对象
- 标记-整理算法:让所有存活对象都向一端移动,然后直接清理掉边界以外的内存
RPC调用与GC垃圾回收的更多相关文章
- 数往知来C#之接口 值类型与引用类型 静态非静态 异常处理 GC垃圾回收 值类型引用类型内存分配<四>
C# 基础接口篇 一.多态复习 使用个new来实现,使用virtual与override -->new隐藏父类方法 根据当前类型,电泳对应的方法(成员) -->override ...
- GC垃圾回收
我们在开发需求的时候,可能很少关注到垃圾回收,因为我们绝大多数的时候都是使用的托管资源,托管资源的内存回收.net已经帮我们做了,但是.net的内存回收不是实时的,所以我们还是要关注下.net的垃圾回 ...
- JVM和GC垃圾回收机制和内存分配
JVM运行期间 线程共享 线程私有 线程共享: 方法区 堆方法区:存放可以共享数据,静态常量,类的共有方法属性字段等,可以共享的存在方法区. 堆:存放class对象 . 线程私有:本地方法栈 虚拟机栈 ...
- Java虚拟机笔记(二):GC垃圾回收和对象的引用
为什么要了解GC 我们都知道Java开发者在开发过程中是不需要关心对象的回收的,因为Java虚拟机的原因,它会自动回收那些失效的垃圾对象.那我们为什么还要去了解GC和内存分配呢? 答案很简单:当我们需 ...
- java面试题之----JVM架构和GC垃圾回收机制详解
JVM架构和GC垃圾回收机制详解 jvm,jre,jdk三者之间的关系 JRE (Java Run Environment):JRE包含了java底层的类库,该类库是由c/c++编写实现的 JDK ( ...
- 乐字节Java|GC垃圾回收机制、package和import
本文接上一篇:乐字节Java|this关键字.static关键字.block块.本文是接着讲述JavaGC垃圾回收机制.package 和 import语句. 一.GC垃圾回收机制 GC全名:Garb ...
- 计时器 GC垃圾回收 demo
计时器: public void start() { //定义计时器 Timer timer=new Timer(); //定义运行间隔(数字越小,速度越快) int interval=30; //创 ...
- Java学习之二(线程(了解) JVM GC 垃圾回收)
线程与进程(了解)→JVM→字节码→GC 一.程序 = 算法 + 数据结构(大佬) 二.程序 = 框架 + 业务逻辑(现实) 1.线程与进程.同步与异步 1.1进程是什么? 进程就是操作系统控制的基本 ...
- JVM虚拟机 与 GC 垃圾回收
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 一.JVM体系结构概述 1.JVM 与系统.硬件 JVM是运行在操作系统之上的,它与硬件没有直接的交 ...
随机推荐
- Windows Server2012 搭建域错误“本地Administraor账户不需要密码”
标签:MSSQL/SQLServer/域控制器提升的先决条件验证失败/密码不符合要求 概述 在安装WindowsServer2012域控出现administrator账户密码不符合要求的错误,但是实际 ...
- Python爬虫学习之正则表达式爬取个人博客
实例需求:运用python语言爬取http://www.eastmountyxz.com/个人博客的基本信息,包括网页标题,网页所有图片的url,网页文章的url.标题以及摘要. 实例环境:pytho ...
- Gephi安装过程中出现错误:can’t find java 1.8 or higher
Gephi具体的安装过程我就不多说了,一直点击下一步就OK了,我想说的是出现如下图这种或者类似的错误怎么解决. 在百度的过程中发现很多的博文等等出现这个错误的解决方法都是安装对应版本的JDK啊,配置对 ...
- JAVA线程池的实际运用
线程池的创建 我们可以通过ThreadPoolExecutor来创建一个线程池 /** * @param corePoolSize 线程池基本大小,核心线程池大小,活动线程小于corePoolSize ...
- Java实现链表的常见操作算法
链表分为单链表,双向链表和循环链表,是一种链式存储结构,由一个个结点链式构成,结点包含数据域和指针域,其中单链表是只有一个指向后驱结点的指针,双向链表除头结点和尾结点外,每个结点都有一个前驱指针和一个 ...
- Javascript高级编程学习笔记(75)—— 表单(3)表单字段
表单字段 表单作为web应用中不可或缺的一部分,当然也是可以使用原生的 DOM 元素来访问的 除了标准的访问方式之外,每个表单都拥有一个 elements 属性,该属性保存着该表单所有 表单元素 的集 ...
- Android APK安装过程学习笔记
1.什么是APK APK,即Android Package,Android安装包.不同平台的安装文件格式都不同,类似于Windows的安装包是二进制的exe格式,Mac的安装包是dmg格式.APK可以 ...
- 再谈spring的循环依赖是怎么造成的?
老生常谈,循环依赖!顾名思义嘛,就是你依赖我,我依赖你,然后就造成了循环依赖了!由于A中注入B,B中注入A导致的吗? 看起来没毛病,然而,却没有说清楚问题!甚至会让你觉得你是不清楚spring的循环依 ...
- The SDK 'Microsoft.NET.Sdk' specified could not be found.
有一台电脑用 VS Code 开发 .NET Core 项目时,每次打开文件夹都有一个错误(标题),定位在 C# 插件,鼠标放在代码上没有智能提醒,输入代码时没有补全提示,重装 VS Code 和所有 ...
- 【Spark调优】小表join大表数据倾斜解决方案
[使用场景] 对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中的一个RDD或表的数据量比较小(例如几百MB或者1~2GB),比较适用此方案. [解决方案] ...