Spark-Unit1-spark概述与安装部署
一、Spark概述
spark官网:spark.apache.org
Spark是用的大规模数据处理的统一计算引擎,它是为大数据处理而设计的快速通用的计算引擎。spark诞生于加油大学伯克利分校AMP实验室。
mapreduce(MR)与spark的对比:
1.MR在计算中产生的结果存储在磁盘上,spark存储在内存中;
2.磁盘运行spark的速度是MR的10倍,内存运行spark是MR的100多倍;
3.spark并不是为了替代Hadoop,而是为了补充Hadoop;
4.spark没有存储,但他可以继承HDFS。
Spark启用的是内存分布式数据集,而Scala语言可以轻松的处理分布式数据集,Scala语言可以说是为Spark而生的,而Spark 的出现推动了Scala语言的发展。
二、Spark特点
1.速度快
磁盘运行spark的速度是MR的10倍,内存运行spark是MR的100多倍;
Spark使用最先进的DAG调度程序,查询优化器和物理执行引擎,实现批处理和流处理的高性能。
注释:DAG:有向无环图,上一个RDD的计算结果作为下一个RDD计算的初始值,可以迭代成千上万次。
查询优化器:指的是spark sql
批处理:spark sql
流处理:spark streaming
2.便于使用
支持Java/Scala/python/R/SQL编写应用程序
3.通用性高
不仅支持批处理、流处理,
还支持机器学习(MLlib:machine learning library)和图形计算(GraphX)
4.兼容性高
Spark运行在Hadoop,Apache Mesos。Kubernetes,独立或云端。它可以访问各种数据源。
Spark实现了Standalone模式作为内置的资源管理和调度框架。
三、Spark的安装部署
1.准备工作:
新建三台虚拟机(建议2G内存,1G也可以)/使用远程连接工具连接 / 关闭防火墙 / 修改主机名
/ 修改映射文件 / 设置免密登陆 / 安装jdk(1.8以上版本)
2.在官网下载spark 安装包(我是2.2.0版本)
然后上传到Linux系统,解压,删包,重命名
3.修改spark部分配置文件
进入spark->conf
1)重命名spark-env.sh.template 为 spark-env.sh,进入该文件
添加配置信息:
export JAVA_HOME=/root/sk/jdk1.8.0_132 //jdk安装路径
export SPARK_MASTER_HOST=spark-01 //spark主节点机器名
export SPARK_MASTER_PORT=7077 //spark主机点端口号
2)重命名slaves.template(好像是这个)为slaves,进入该文件
删除最后一行“localhost”
添加:spark-02
spark-03 //其他两台从节点worker,便于一键启动
4.发送修改好的spark解压文件夹到其他两台机器
scp -r sprk sprk-02:$PWD
5.启动spark,访问web页面
在spark 的sbin目录下输入命令:
./start-all.sh
然后通过ip:端口号访问UI界面,如:
192.168.50.186:8080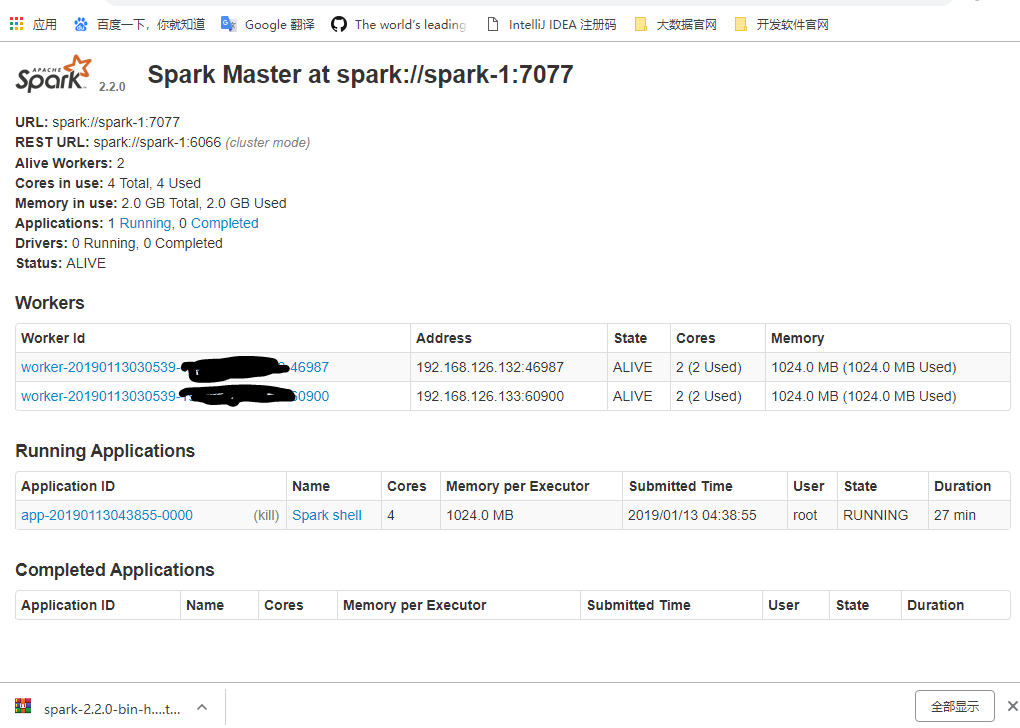
四、Spark的UI界面详解
URL:统一资源定位符,spark-master的访问地址
REST URL:可以通过rest的方式访问集群
Alive Workers:存活的worker数量
cores in use:可以使用的核心数量
Memory in use:可以使用的内存大小
Applications:正在运行和已经完成的应用程序
Driver:通过driver提交的任务情况
Status:节点的状态
Spark-Unit1-spark概述与安装部署的更多相关文章
- Spark、Shark集群安装部署及遇到的问题解决
1.部署环境 OS:Red Hat Enterprise Linux Server release 6.4 (Santiago) Hadoop:Hadoop 2.4.1 Hive:0.11.0 JDK ...
- HBase的概述和安装部署
一.HBase概述 1.HBase是Hadoop数据库,是一个分布式.可扩展的大数据存储. HBase是用于对大数据进行随机.实时读写访问的非关系型数据库,它的目标托管非常大的表——数十亿行N百万列. ...
- Kafka概述及安装部署
一.Kafka概述 1.Kafka是一个分布式流媒体平台,它有三个关键功能: (1)发布和订阅记录流,类似于消息队列或企业消息传递系统: (2)以容错的持久方式存储记录流: (3)记录发送时处理流. ...
- Zookeeper的概述、安装部署及选举机制
一.Zookeeper概述 1.Zookeeper是Hadoop生态的管理者,它致力于开发和维护开源服务器,实现高度可靠的分布式协调. 2.Zookeeper的两大功能: (1)存储数据 (2)监听 ...
- Flume的概述和安装部署
一.Flume概述 Flume是一种分布式.可靠且可用的服务,用于有效的收集.聚合和移动大量日志文件数据.Flume具有基于流数据流的简单灵活的框架,具有可靠的可靠性机制和许多故障转移和恢复机制,具有 ...
- Spark安装部署(local和standalone模式)
Spark运行的4中模式: Local Standalone Yarn Mesos 一.安装spark前期准备 1.安装java $ sudo tar -zxvf jdk-7u67-linux-x64 ...
- 【Hadoop离线基础总结】oozie的安装部署与使用
目录 简单介绍 概述 架构 安装部署 1.修改core-site.xml 2.上传oozie的安装包并解压 3.解压hadooplibs到与oozie平行的目录 4.创建libext目录,并拷贝依赖包 ...
- Kubernetes后台数据库etcd:安装部署etcd集群,数据备份与恢复
目录 一.系统环境 二.前言 三.etcd数据库 3.1 概述 四.安装部署etcd单节点 4.1 环境介绍 4.2 配置节点的基本环境 4.3 安装部署etcd单节点 4.4 使用客户端访问etcd ...
- 【Spark学习】Spark 1.1.0 with CDH5.2 安装部署
[时间]2014年11月18日 [平台]Centos 6.5 [工具]scp [软件]jdk-7u67-linux-x64.rpm spark-worker-1.1.0+cdh5.2.0+56-1.c ...
随机推荐
- java基础题刷题中的知识点复习
将变量转换为字符串方法:(String)待转对象..toString().String.valueOf(待转对象) 对字符串进行操作的方法,使用StringBuffer和StringBuilder定义 ...
- WebSocket异步通讯,实时返回数据相关问题论坛
https://stackoverflow.com/questions/23773407/a-websockets-receiveasync-method-does-not-await-the-ent ...
- Linux永久修改IP地址
通常我们为了快速修改IP地址,会这么做 ifconfig eth0 192.168.0.2 netmask 255.255.255.0 这样修改IP地址后,你再运行ifconfig命令后,的确IP地址 ...
- LeetCode(101):对称二叉树
Easy! 题目描述: 给定一个二叉树,检查它是否是镜像对称的. 例如,二叉树 [1,2,2,3,4,4,3] 是对称的. 1 / \ 2 2 / \ / \ 3 4 4 3 但是下面这个 [1,2, ...
- 【python】查找函数定义
help(函数名) 举例:想知道gevnet.Timeout这个函数是怎么用的.help(gevent.Timeout). 之前不知道这样查,每次遇到新函数想知道有哪些参数我都要到网上疯狂查阅文档.现 ...
- tp3.2 事务
public function exchangeTransfer($user_id, $type, $money, $config, $other_id = 0) { $r['code'] = ERR ...
- linux 源码安装PHP
解压: 解压完: configure: configure成功: make: make完成: 安装完成!!! 测试: 需要./bin/php来运行php 想要任何目录输入PHP就能使用php 方法一: ...
- matlab提取wind底层数据库操作
首先需要安装navicat for SQL server 软件, 为了实现Matlab 通过JDBC方式连接Sqlserver数据库, 需要安装Sqlserver JDBC驱动. 地址: https: ...
- C++ Primer 笔记——动态数组
1.动态数组定义时也需要指明数组的大小,但是可以不是常量. int i; int arr[i]; // 错误,数组的大小必须为常量 int *p = new int[i]; // 正确,大小不必是常量 ...
- Django-model聚合查询与分组查询
Django-model聚合查询与分组查询 聚合函数包含:SUM AVG MIN MAX COUNT 聚合函数可以单独使用,不一定要和分组配合使用:不过聚合函数一般和group by 搭配使用 agg ...