kaldi运行thchs30例子
首先,thchs30有两种数据库,kaldi运行的数据库最好是 thchs30-openslr。
修改run.sh里面的语音库路径 thchs30=...
修改nj线程数 等于CPU的核心数
修改cmd.sh queue.pl 改为run.pl本地机器跑
运行出现错误:
lexicon.txt验证出错
里面binary file matches
这是grep的问题,grep -v -a '<s>' | grep -v -a '</s>' | sort -u > data/dict/lexicon.txt || exit 1;
---------------------------------------------------------------------------------------------------------------------------
在线识别部分:
去egs下,打开voxforge,里面有个online_demo,直接考到thchs30下。在online_demo里面建2个文件夹online-data work,在online-data下建两个文件夹audio和models,audio下放你要回放的wav,models建个文件夹tri1,把s5下的exp下的tri1下的final.mdl和35.mdl(final.mdl是快捷方式)考过去。把s5下的exp下的tri1下的graph_word里面的words.txt,和HCLG.fst,考到models的tri1下。
类似处理,包括tri2b,tri3b,tri4b,不过后者需要添加转移矩阵,final.mat以及所指的mat文件。
如下所示,例如 tri2b文件夹下,
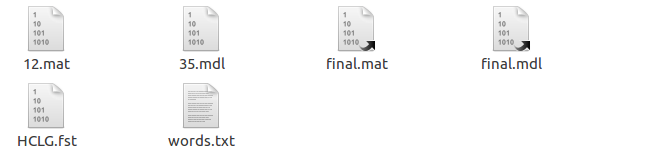
打开online_demo的run.sh
a)将下面这段注释掉:(这段是voxforge例子中下载现网的测试语料和识别模型的。我们测试语料自己准备,模型就是tri1了)
if [ ! -s ${data_file}.tar.bz2 ]; then
echo "Downloading test models and data ..."
wget -T 10 -t 3 $data_url;
if [ ! -s ${data_file}.tar.bz2 ]; then
echo "Download of $data_file has failed!"
exit 1
fi
fi
b) 然后再找到如下这句,将其路径改成tri1
ac_model_type=tri2b
if [ -s $ac_model/final.mat ]; then
trans_matrix=$ac_model/final.mat
echo "set matrix"
fi
online-gmm-decode-faster --rt-min=0.5 --rt-max=0.7 --max-active=4000 \
--beam=12.0 --acoustic-scale=0.0769 --left-context=3 --right-context=3 $ac_model/final.mdl $ac_model/HCLG.fst \
$ac_model/words.txt '1:2:3:4:5' $trans_matrix;;
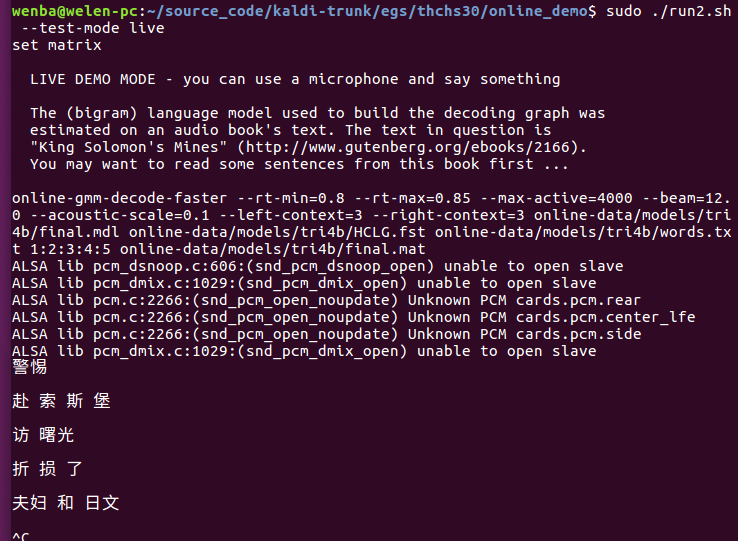
识别效果很差
kaldi运行thchs30例子的更多相关文章
- kaldi 运行voxforge例子
---------------------------------------------------------------------------------------------------- ...
- kaldi使用thchs30数据进行训练并执行识别操作
操作系统 : Ubutu18.04_x64 gcc版本 :7.4.0 数据准备及训练 数据地址: http://www.openslr.org/18/ 在 egs/thchs30/s5 建立 thch ...
- [Linux][Hadoop] 运行WordCount例子
紧接上篇,完成Hadoop的安装并跑起来之后,是该运行相关例子的时候了,而最简单最直接的例子就是HelloWorld式的WordCount例子. 参照博客进行运行:http://xiejiangl ...
- caffe简易上手指南(一)—— 运行cifar例子
简介 caffe是一个友好.易于上手的开源深度学习平台,主要用于图像的相关处理,可以支持CNN等多种深度学习网络. 基于caffe,开发者可以方便快速地开发简单的学习网络,用于分类.定位等任务,也可以 ...
- sparkR的一个运行的例子
在sparkR在配置完成的基础上,本例采用Spark on yarn模式,介绍sparkR运行的一个例子. 在spark的安装目录下,/examples/src/main/r,有一个dataframe ...
- (四)伪分布式下jdk1.6+Hadoop1.2.1+HBase0.94+Eclipse下运行wordCount例子
本篇先介绍HBase在伪分布式环境下的安装方式,然后将MapReduce编程和HBase结合起来使用,完成WordCount这个例子. HBase在伪分布环境下安装 一. 前提条件 已经成功地安装 ...
- RedHat 安装Hadoop并运行wordcount例子
1.安装 Red Hat 环境 2.安装JDK 3.下载hadoop2.8.0 http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/had ...
- 八、VTK安装并运行一个例子
一.版本 win10 VS2019 VTK8.2.0 其实vtk的安装过程和itk的安装过程很是类似,如果你对itk的安装很是熟悉(也就是我的博客一里面的内容,那么自己就可以安装.) 如果不放心,可以 ...
- 配置RHadoop与运行WordCount例子
1.安装R语言环境 su -c 'rpm -Uvh http://download.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch. ...
随机推荐
- c#线程池中的异常
static void Main(string[] args) { //写日志 //使用线程池 ; i < ; i++) { ThreadPool.QueueUserWorkItem(new W ...
- How to find SPRO path by t-code name
e.g:OB58 F1->Technical Information Find Table Name->V_T011 3.SM30 V_T011 Customizing Continue ...
- sliding window:"Marginalization","Schur complement","First estimate jacobin"
[1]知行合一2 SLAM中的marginalization 和 Schur complement SLAM的Bundle Adjustment上,随着时间的推移,路标特征点(landmark)和相机 ...
- 【转】重写Equals为什么要同时重写GetHashCode
.NET程序员都知道,如果我们重写一个类的Equals方法而没有重写GetHashCode,则VS会提示警告 :“***”重写 Object.Equals(object o)但不重写 Object.G ...
- linux 网络管理的三种方式
修改网络IP的三种方式 1.修改配置文件 1.1dhcp自动获取 配置文件地址/etc/sysconfig/network-scripts TYPE=Ethernet #类型=以太网 PROXY_M ...
- PS教程:大神教你用PS制作《大鱼海棠》海报
本来做的是一千左右像素的,但最后粗心让我存成500几px的了,可能会有点不清楚,唉,忙活这莫久竟然不敌最后一步的粗心呀 教程有千千万,但跟着作就好像是以前幼儿园老师拿着你的手写字,你可 ...
- oracle竖表转横表字段合并
select * from( SELECT t.ID, ISTATUS, ITIMEOUT, IRESENDTIMEOUT, IRESENDFIXED, IAUTOUPGRADE, STRTERMPR ...
- python3 第三十章 - 内置函数之Dictionary相关
Python字典包含了以下内置函数: 序号 函数及描述 实例 1 len(dict)计算字典元素个数,即键的总数. >>> dict = {'Name': 'cnblogs', 'A ...
- mysql伪列
<!-- NOTE:internal_name_trim使用的是伪列,而不是数据库返回的数据 --><select id="listByStoreIdAndPartsN ...
- 猜数字游戏;库的使用:turtle
myNum = print('猜字游戏\n') while True: guess = int(input('请输入一个数:')) if guess > myNum: print('不对哦猜大了 ...