Machine Learning 算法可视化实现2 - Apriori算法实现
目录
一、关联分析
关联分析是一种在大规模数据集中寻找有趣关系的任务。 这些关系可以有两种形式:
- 频繁项集(frequent item sets): 经常出现在一块的物品的集合。
- 关联规则(associational rules): 暗示两种物品之间可能存在很强的关系。
相关术语
关联分析(关联规则学习): 从大规模数据集中寻找物品间的隐含关系被称作
关联分析(associati analysis)或者关联规则学习(association rule learning)。 下面是用一个杂货店例子来说明这两个概念,如下图所示:
频繁项集: {葡萄酒, 尿布, 豆奶} 就是一个频繁项集的例子。
关联规则: 尿布 -> 葡萄酒 就是一个关联规则。这意味着如果顾客买了尿布,那么他很可能会买葡萄酒。
那么 频繁 的定义是什么呢?怎么样才算频繁呢? 度量它们的方法有很多种,这里我们来简单的介绍下支持度和可信度。
- 支持度: 数据集中包含该项集的记录所占的比例。例如上图中,{豆奶} 的支持度为 4/5。{豆奶, 尿布} 的支持度为 3/5。
- 可信度: 针对一条诸如 {尿布} -> {葡萄酒} 这样具体的关联规则来定义的。这条规则的
可信度被定义为支持度({尿布, 葡萄酒})/支持度({尿布}),从图中可以看出 支持度({尿布, 葡萄酒}) = 3/5,支持度({尿布}) = 4/5,所以 {尿布} -> {葡萄酒} 的可信度 = 3/5 / 4/5 = 3/4 = 0.75。
支持度 和 可信度 是用来量化 关联分析 是否成功的一个方法。 假设想找到支持度大于 0.8 的所有项集,应该如何去做呢? 一个办法是生成一个物品所有可能组合的清单,然后对每一种组合统计它出现的频繁程度,但是当物品成千上万时,上述做法就非常非常慢了。 我们需要详细分析下这种情况并讨论下 Apriori 原理,该原理会减少关联规则学习时所需的计算量。
二、Apriori 原理
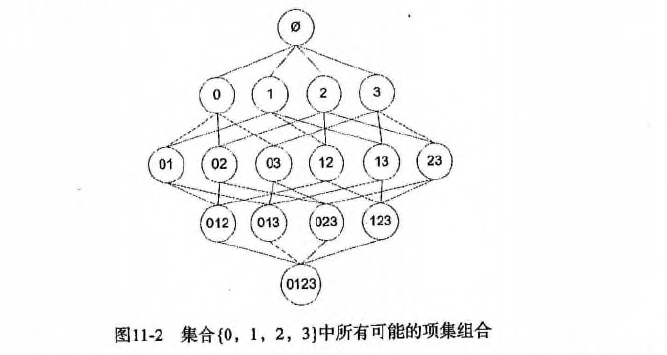
假设我们一共有 4 个商品: 商品0, 商品1, 商品2, 商品3。 所有可能的情况如下:
如果我们计算所有组合的支持度,也需要计算 15 次。即 2^N - 1 = 2^4 - 1 = 15。
随着物品的增加,计算的次数呈指数的形式增长 ...
为了降低计算次数和时间,研究人员发现了一种所谓的 Apriori 原理,即某个项集是频繁的,那么它的所有子集也是频繁的。 例如,如果 {0, 1} 是频繁的,那么 {0}, {1} 也是频繁的。 该原理直观上没有什么帮助,但是如果反过来看就有用了,也就是说如果一个项集是 非频繁项集,那么它的所有超集也是非频繁项集,如下图所示:
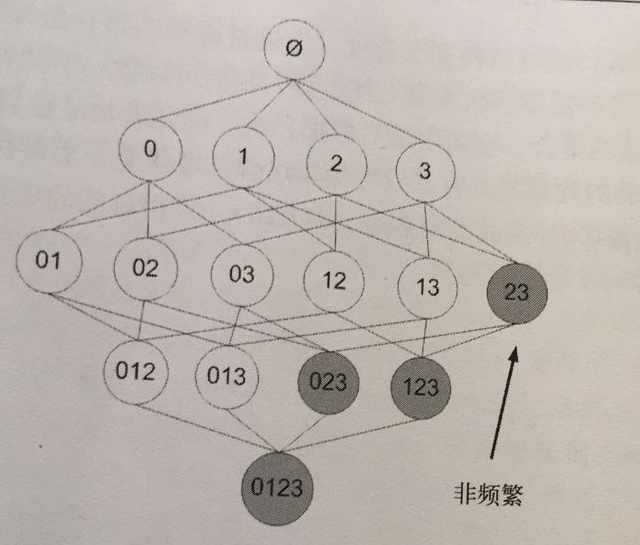
在图中我们可以看到,已知灰色部分 {2,3} 是 非频繁项集,那么利用上面的知识,我们就可以知道 {0,2,3} {1,2,3} {0,1,2,3} 都是 非频繁的。 也就是说,计算出 {2,3} 的支持度,知道它是 非频繁 的之后,就不需要再计算 {0,2,3} {1,2,3} {0,1,2,3} 的支持度,因为我们知道这些集合不会满足我们的要求。 使用该原理就可以避免项集数目的指数增长,从而在合理的时间内计算出频繁项集。
Apriori 算法优缺点
* 优点:易编码实现
* 缺点:在大数据集上可能较慢
* 适用数据类型:数值型 或者 标称型数据。
Apriori 算法流程步骤:
* 收集数据:使用任意方法。
* 准备数据:任何数据类型都可以,因为我们只保存集合。
* 分析数据:使用任意方法。
* 训练数据:使用Apiori算法来找到频繁项集。
* 测试算法:不需要测试过程。
* 使用算法:用语发现频繁项集以及物品之间的关联规则。
三、Apriori 算法实现 - 频繁项集
关联分析的目标包括两项: 发现 频繁项集 和发现 关联规则。 首先需要找到 频繁项集,然后才能发现 关联规则。Apriori 算法是发现频繁项集的一种方法。
算法实现步骤:
- Apriori 算法的两个输入参数分别是最小支持度和数据集。
- 该算法首先会生成所有单个物品的项集列表。
- 接着扫描交易记录来查看哪些项集满足最小支持度要求,那些不满足最小支持度要求的集合会被去掉。
- 然后对生下来的集合进行组合以生成包含两个元素的项集。
- 接下来再重新扫描交易记录,去掉不满足最小支持度的项集。
- 该过程重复进行直到所有项集被去掉。
'''
变量含义:
dataSet: 数据集 [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
D: 对dataSet的每一行进行了set转换 [{1, 3, 4}, {2, 3, 5}, {1, 2, 3, 5}, {2, 5}],当成dataSet即可
Ck: 代表候选项集; C1:只有一个元素的项集
Lk: 代表频繁项集
conf: 可信度
freqSet: 频繁项集中的元素
H: 频繁项集中的元素的集合
brl: 关联规则列表的空数组
prunedH:记录 可信度大于阈值的集合
bigRuleList 可信度规则列表(关于 (A->B+可信度) 3个字段的组合) 函数调用顺序:
load_dataSet -> apriori( createC1 -> scanD -> aprioriGen )
generateRules -> ( rulesFromConseq -> calcConf )
'''
3.1 加载数据集
# 加载数据集
def load_dataSet():
return [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]] #返回一个列表(交易记录)
3.2 创建只有一个元素的项集列表 C1。即对 dataSet 进行去重,排序,放入 list 中,然后转换所有的元素为 frozenset
# 创建只有一个元素的项集列表;即对 dataSet 进行去重,排序,放入 list 中,然后转换所有的元素为 frozenset
def createC1(dataSet):
'''
:param :dataSet
:return:frozenset 返回一个 frozenset 格式的 list
'''
C1 = []
for transaction in dataSet:
for item in transaction:
if not [item] in C1: #遍历所有元素,添加进入“单个物品的项集列表”
C1.append([item]) #注意!!!item一定要加中括号,代表列表; 不然C1的元素是int,int是不可迭代的;执行list(map(frozenset, C1)),报错如下:TypeError: 'int' object is not iterable
C1.sort() # 对数组进行 `从小到大` 的排序
return list(map(frozenset, C1)) # 对每一个元素 frozenset
3.3 通过候选项集Ck,返回频繁项集和支持度字典
伪代码:(通过扫描数据集以寻找交易记录子集)
- 对数据集中的每条交易记录 tran
- 对每个候选项集 can
- 检查一下 can 是否是 tran 的子集: 如果是则增加 can 的计数值
- 对每个候选项集
- 如果其支持度不低于最小值,则保留该项集
- 返回所有频繁项集列表 以下是一些辅助函数。
# 计算候选数据集 CK 在数据集 D 中的支持度,并返回支持度大于最小支持度(minSupport)的数据(即频繁项集)
def scanD(D, Ck, minSupport):
'''
:param D: 数据集
:param Ck: 候选项集列表
:param minSupport: 最小支持度
:return:
retList 支持度大于 minSupport 的集合
supportData 候选项集支持度数据
'''
can_count = {} # 临时存放选数据集 Ck 的频率. 例如: a->10, b->5, c->8
for tid in D: # 遍历数据集中每一条交易记录
for can in Ck: # 遍历每一项候选项集
if can.issubset(tid):
if not can in can_count:
can_count[can] = 1
else:
can_count[can] += 1
numItems = float(len(dataSet)) # 数据集的条数
retList = [] #支持度大于 minSupport 的集合
supportData = {} # 候选项集支持度数据
for key in can_count:
# 支持度 = 候选项(key)出现的次数 / 所有数据集的数量
support = can_count[key] / numItems
if support >= minSupport:
# 在 retList 的首位插入元素,只存储支持度满足频繁项集的值
retList.insert(0, key)
# 存储所有的候选项(key)和对应的支持度(support)
supportData[key] = support
return retList, supportData
3.4 通过频繁项集Lk,返回下一个候选项集
# 输入频繁项集列表 Lk 与返回的元素个数 k,然后输出所有可能的候选项集 Ck
def aprioriGen(Lk, k):
'''
:param lk: 频繁项集列表
:param k: 返回的项集元素个数(若元素的前 k-2 相同,就进行合并)
:return:
retList 元素两两合并的数据集
'''
retList = []
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i+1, lenLk):
L1 = list(Lk[i])[: k - 2]
L2 = list(Lk[j])[: k - 2]
L1.sort()
L2.sort()
# 第一次 L1,L2 为空,元素直接进行合并,返回元素两两合并的数据集
if L1 == L2:
retList.append(Lk[i] | Lk[j])
return retList
3.5 Apiori算法, 返回总的频繁项集列表 和 总的支持度字典
# 找出数据集 dataSet 中支持度 >= 最小支持度的候选项集以及它们的支持度。即我们的频繁项集。和支持度字典
def apriori(dataSet, minSupport=0.5):
'''
首先构建集合 C1,然后扫描数据集来判断这些只有一个元素的项集是否满足最小支持度的要求。那么满足最小支持度要求的项集构成集合 L1。然后 L1 中的元素相互组合成 C2,C2 再进一步过滤变成 L2,然后以此类推,知道 CN 的长度为 0 时结束,即可找出所有频繁项集的支持度。)
:param dataSet: 原始数据集
:param minSupport: 支持度的阈值
:return:
L 频繁项集的全集
supportData 所有元素和支持度的全集
'''
C1 = createC1(dataSet) # 只有一个元素的候选项集列表;即对 dataSet 进行去重,排序,放入 list 中,然后转换所有的元素为 frozenset
D = list(map(set, dataSet)) # 对每一行进行 set 转换,然后存放到集合中,并转换成列表
L1,supportData = scanD(D, C1, minSupport)# 计算候选数据集 C1 在数据集 D 中的支持度,并返回支持度大于 minSupport 的数据 L = [L1] # L 加了一层 list, L 一共 2 层 list
k = 2
# 判断 L 的第 k-2 项的数据长度是否 > 0。第一次执行时 L 为 [[frozenset([1]), frozenset([3]), frozenset([2]), frozenset([5])]]。L[k-2]=L[0]=[frozenset([1]), frozenset([3]), frozenset([2]), frozenset([5])],最后面 k += 1
while (len(L[k - 2]) > 0):
Ck = aprioriGen(L[k-2], k) #例如: 以 {0},{1},{2} 为输入且 k = 2 则输出 {0,1}, {0,2}, {1,2}. 以 {0,1},{0,2},{1,2} 为输入且 k = 3 则输出 {0,1,2} Lk, supportK = scanD(D, Ck, minSupport)# 计算候选数据集 CK 在数据集 D 中的支持度,并返回支持度大于 minSupport 的数据,即为Lk
supportData.update(supportK)# 保存所有候选项集的支持度,如果字典没有,就追加元素,如果有,就更新元素
if(len(Lk) == 0):
break
# Lk 表示满足频繁子项的集合,L 元素在增加,例如:
# l=[[set(1), set(2), set(3)]]
# l=[[set(1), set(2), set(3)], [set(1, 2), set(2, 3)]]
L.append(Lk) #L的第一个元素是包含“只含有一个元素”频繁项集列表;L的第二个元素是包含有“两个元素的”频繁项集列表.....
k += 1 return L, supportData
到这一步,我们就找出我们所需要的 频繁项集 和他们的 支持度 了,接下来再找出关联规则即可
四、Apriori 算法实现 - 从频繁项集中挖掘关联规则
前面我们介绍了用于发现 频繁项集 的 Apriori 算法,现在要解决的问题是如何找出 关联规则。
要找到 关联规则,我们首先从一个 频繁项集 开始。 我们知道集合中的元素是不重复的,但我们想知道基于这些元素能否获得其它内容。 某个元素或某个元素集合可能会推导出另一个元素。 从先前 杂货店 的例子可以得到,如果有一个频繁项集 {豆奶,莴苣},那么就可能有一条关联规则 “豆奶 -> 莴苣”。 这意味着如果有人买了豆奶,那么在统计上他会购买莴苣的概率比较大。 但是,这一条件反过来并不总是成立。 也就是说 “豆奶 -> 莴苣” 统计上显著,那么 “莴苣 -> 豆奶” 也不一定成立。
前面我们给出了 频繁项集 的量化定义,即它满足最小支持度要求。
对于 关联规则,我们也有类似的量化方法,这种量化指标称之为 可信度。
一条规则 A -> B 的可信度定义为 support(A | B) / support(A)。(注意: 在 python 中 | 表示集合的并操作,而数学书集合并的符号是 U)。A | B 是指所有出现在集合 A 或者集合 B 中的元素。
由于我们先前已经计算出所有 频繁项集 的支持度了,现在我们要做的只不过是提取这些数据做一次除法运算即可。
一个频繁项集可以产生多少条关联规则呢?
如下图所示,给出的是项集 {0,1,2,3} 产生的所有关联规则: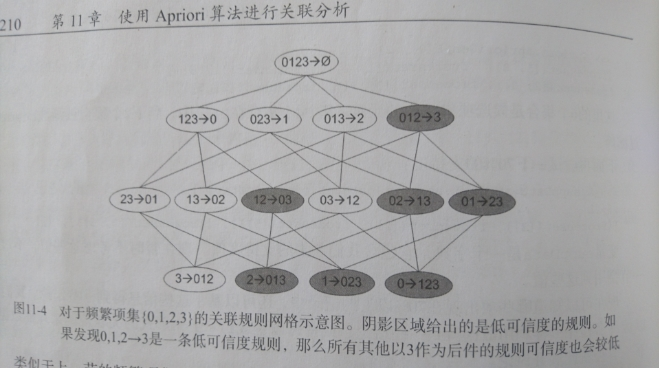
与我们前面的 频繁项集 生成一样,我们可以为每个频繁项集产生许多关联规则。
如果能减少规则的数目来确保问题的可解析,那么计算起来就会好很多。
通过观察,我们可以知道,如果某条规则并不满足 最小可信度 要求,那么该规则的所有子集也不会满足 最小可信度 的要求。
如上图所示,假设 012 -> 3 并不满足最小可信度要求,那么就知道任何左部为 {0,1,2} 子集的规则也不会满足 最小可信度 的要求。 即 12 -> 03 , 02 -> 13 , 01 -> 23 , 2 -> 013, 1 -> 023, 0 -> 123 都不满足 最小可信度 要求。
可以利用关联规则的上述性质属性来减少需要测试的规则数目,跟先前 Apriori 算法的套路一样。
4.1 计算可信度
# 计算可信度(confidence)
def calcConf(freqSet, H, supportData, brl, minConf=0.7):
''' 对两个元素的频繁项集,计算可信度,例如: {1,2}/{1} 或者 {1,2}/{2} 看是否满足条件)
:param freqSet: 频繁项集中的元素,例如: frozenset([1, 3])
:param H: 频繁项集中的元素的集合,例如: [frozenset([1]), frozenset([3])]
:param supportData: 所有元素的支持度的字典
:param brl: 关联规则列表的空数组
:param minConf: 最小可信度
:return:
prunedH:记录 可信度大于阈值的集合
''' # 记录可信度大于最小可信度(minConf)的集合
prunedH = []
for conseq in H: # 假设 freqSet = frozenset([1, 3]), H = [frozenset([1]), frozenset([3])],那么现在需要求出 frozenset([1]) -> frozenset([3]) 的可信度和 frozenset([3]) -> frozenset([1]) 的可信度
conf = supportData[freqSet] / supportData[freqSet - conseq] # 支持度定义: a -> b = support(a | b) / support(a). 假设 freqSet = frozenset([1, 3]), conseq = [frozenset([1])],那么 frozenset([1]) 至 frozenset([3]) 的可信度为 = support(a | b) / support(a) = supportData[freqSet]/supportData[freqSet-conseq] = supportData[frozenset([1, 3])] / supportData[frozenset([1])]
if conf >= minConf:
print(freqSet - conseq, '-->', conseq, 'conf:', conf)
brl.append((freqSet - conseq, conseq, conf))
prunedH.append(conseq)
return prunedH
4.2 递归计算频繁项集的规则
def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7):
'''
:param freqSet: 频繁项集中的元素,例如: frozenset([2, 3, 5])
:param H: 频繁项集中的元素的集合,例如: [frozenset([2]), frozenset([3]), frozenset([5])]
:param supportData: 所有元素的支持度的字典
:param brl: 关联规则列表的数组
:param minConf: 最小可信度
'''
# H[0] 是 freqSet 的元素组合的第一个元素,并且 H 中所有元素的长度都一样,长度由 aprioriGen(H, m+1) 这里的 m + 1 来控制
# 该函数递归时,H[0] 的长度从 1 开始增长 1 2 3 ...
# 假设 freqSet = frozenset([2, 3, 5]), H = [frozenset([2]), frozenset([3]), frozenset([5])]
# 那么 m = len(H[0]) 的递归的值依次为 1 2
# 在 m = 2 时, 跳出该递归。假设再递归一次,那么 H[0] = frozenset([2, 3, 5]),freqSet = frozenset([2, 3, 5]) ,没必要再计算 freqSet 与 H[0] 的关联规则了。
m = len(H[0])
if (len(freqSet) > (m + 1)):
# 生成 m+1 个长度的所有可能的 H 中的组合,假设 H = [frozenset([2]), frozenset([3]), frozenset([5])]
# 第一次递归调用时生成 [frozenset([2, 3]), frozenset([2, 5]), frozenset([3, 5])]
# 第二次 。。。没有第二次,递归条件判断时已经退出了
Hmp1 = aprioriGen(H, m + 1)
# 返回可信度大于最小可信度的集合
Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf) # 计算可信度后,还有数据大于最小可信度的话,那么继续递归调用,否则跳出递归
if (len(Hmp1) > 1):
rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf)
4.3 生成关联规则
def generateRules(L, supportData, minConf=0.7):
'''
:param L: 频繁项集列表
:param supportData: 频繁项集支持度的字典
:param minConf: 最小可信度
:return:
bigRuleList 可信度规则列表(关于 (A->B+可信度) 3个字段的组合)
'''
bigRuleList = []
# 假设 L = [[frozenset([1]), frozenset([3]), frozenset([2]), frozenset([5])], [frozenset([1, 3]), frozenset([2, 5]), frozenset([2, 3]), frozenset([3, 5])], [frozenset([2, 3, 5])]]
for i in range(1, len(L)):
# 获取频繁项集中每个组合的所有元素
for freqSet in L[i]:
# 假设:freqSet= frozenset([1, 3]), H=[frozenset([1]), frozenset([3])]
# 组合总的元素并遍历子元素,并转化为 frozenset 集合,再存放到 list 列表中
H = [frozenset([item]) for item in freqSet]
# 2 个的组合,走 else, 2 个以上的组合,走 if
if (i > 1):
rulesFromConseq(freqSet, H, supportData, bigRuleList, minConf)
else:
calcConf(freqSet, H, supportData, bigRuleList, minConf)
return bigRuleList
到这里为止,通过调用 generateRules 函数即可得出我们所需的 关联规则。
完整源码:
# -*- coding: utf-8 -*-
# @Time : 2018/3/23 1:00
# @Author : TanRong
# @Software: PyCharm
# @File : apriori.py from numpy import * '''
变量含义:
dataSet: 数据集 [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
D: 对dataSet的每一行进行了set转换 [{1, 3, 4}, {2, 3, 5}, {1, 2, 3, 5}, {2, 5}],当成dataSet即可
Ck: 代表候选项集; C1:只有一个元素的项集
Lk: 代表频繁项集
conf: 可信度
''' # 加载数据集
def load_dataSet():
return [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]] #返回一个列表(交易记录) # 创建只有一个元素的项集列表;即对 dataSet 进行去重,排序,放入 list 中,然后转换所有的元素为 frozenset
def createC1(dataSet):
'''
:param :dataSet
:return:frozenset 返回一个 frozenset 格式的 list
'''
C1 = []
for transaction in dataSet:
for item in transaction:
if not [item] in C1: #遍历所有元素,添加进入“单个物品的项集列表”
C1.append([item]) #注意!!!item一定要加中括号,代表列表; 不然C1的元素是int,int是不可迭代的;执行list(map(frozenset, C1)),报错如下:TypeError: 'int' object is not iterable
C1.sort() # 对数组进行 `从小到大` 的排序
return list(map(frozenset, C1)) # 对每一个元素 frozenset # 计算候选数据集 CK 在数据集 D 中的支持度,并返回支持度大于最小支持度(minSupport)的数据(即频繁项集)
def scanD(D, Ck, minSupport):
'''
:param D: 数据集
:param Ck: 候选项集列表
:param minSupport: 最小支持度
:return:
retList 支持度大于 minSupport 的集合
supportData 候选项集支持度数据
'''
can_count = {} # 临时存放选数据集 Ck 的频率. 例如: a->10, b->5, c->8
for tid in D: # 遍历数据集中每一条交易记录
for can in Ck: # 遍历每一项候选项集
if can.issubset(tid):
if not can in can_count:
can_count[can] = 1
else:
can_count[can] += 1
numItems = float(len(dataSet)) # 数据集的条数
retList = [] #支持度大于 minSupport 的集合
supportData = {} # 候选项集支持度数据
for key in can_count:
# 支持度 = 候选项(key)出现的次数 / 所有数据集的数量
support = can_count[key] / numItems
if support >= minSupport:
# 在 retList 的首位插入元素,只存储支持度满足频繁项集的值
retList.insert(0, key)
# 存储所有的候选项(key)和对应的支持度(support)
supportData[key] = support
return retList, supportData # 输入频繁项集列表 Lk 与返回的元素个数 k,然后输出所有可能的候选项集 Ck
def aprioriGen(Lk, k):
'''
:param lk: 频繁项集列表
:param k: 返回的项集元素个数(若元素的前 k-2 相同,就进行合并)
:return:
retList 元素两两合并的数据集
'''
retList = []
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i+1, lenLk):
L1 = list(Lk[i])[: k - 2]
L2 = list(Lk[j])[: k - 2]
L1.sort()
L2.sort()
# 第一次 L1,L2 为空,元素直接进行合并,返回元素两两合并的数据集
if L1 == L2:
retList.append(Lk[i] | Lk[j])
return retList # 找出数据集 dataSet 中支持度 >= 最小支持度的候选项集以及它们的支持度。即我们的频繁项集。和支持度字典
def apriori(dataSet, minSupport=0.5):
'''
首先构建集合 C1,然后扫描数据集来判断这些只有一个元素的项集是否满足最小支持度的要求。那么满足最小支持度要求的项集构成集合 L1。然后 L1 中的元素相互组合成 C2,C2 再进一步过滤变成 L2,然后以此类推,知道 CN 的长度为 0 时结束,即可找出所有频繁项集的支持度。)
:param dataSet: 原始数据集
:param minSupport: 支持度的阈值
:return:
L 频繁项集的全集
supportData 所有元素和支持度的全集
'''
C1 = createC1(dataSet) # 只有一个元素的候选项集列表;即对 dataSet 进行去重,排序,放入 list 中,然后转换所有的元素为 frozenset
D = list(map(set, dataSet)) # 对每一行进行 set 转换,然后存放到集合中,并转换成列表
L1,supportData = scanD(D, C1, minSupport)# 计算候选数据集 C1 在数据集 D 中的支持度,并返回支持度大于 minSupport 的数据 L = [L1] # L 加了一层 list, L 一共 2 层 list
k = 2
# 判断 L 的第 k-2 项的数据长度是否 > 0。第一次执行时 L 为 [[frozenset([1]), frozenset([3]), frozenset([2]), frozenset([5])]]。L[k-2]=L[0]=[frozenset([1]), frozenset([3]), frozenset([2]), frozenset([5])],最后面 k += 1
while (len(L[k - 2]) > 0):
Ck = aprioriGen(L[k-2], k) #例如: 以 {0},{1},{2} 为输入且 k = 2 则输出 {0,1}, {0,2}, {1,2}. 以 {0,1},{0,2},{1,2} 为输入且 k = 3 则输出 {0,1,2} Lk, supportK = scanD(D, Ck, minSupport)# 计算候选数据集 CK 在数据集 D 中的支持度,并返回支持度大于 minSupport 的数据,即为Lk
supportData.update(supportK)# 保存所有候选项集的支持度,如果字典没有,就追加元素,如果有,就更新元素
if(len(Lk) == 0):
break
# Lk 表示满足频繁子项的集合,L 元素在增加,例如:
# l=[[set(1), set(2), set(3)]]
# l=[[set(1), set(2), set(3)], [set(1, 2), set(2, 3)]]
L.append(Lk) #L的第一个元素是包含“只含有一个元素”频繁项集列表;L的第二个元素是包含有“两个元素的”频繁项集列表.....
k += 1
print(L, supportData)
return L, supportData # 计算可信度(confidence)
def calcConf(freqSet, H, supportData, brl, minConf=0.7):
''' 对两个元素的频繁项集,计算可信度,例如: {1,2}/{1} 或者 {1,2}/{2} 看是否满足条件)
:param freqSet: 频繁项集中的元素,例如: frozenset([1, 3])
:param H: 频繁项集中的元素的集合,例如: [frozenset([1]), frozenset([3])]
:param supportData: 所有元素的支持度的字典
:param brl: 关联规则列表的空数组
:param minConf: 最小可信度
:return:
prunedH:记录 可信度大于阈值的集合
''' # 记录可信度大于最小可信度(minConf)的集合
prunedH = []
for conseq in H: # 假设 freqSet = frozenset([1, 3]), H = [frozenset([1]), frozenset([3])],那么现在需要求出 frozenset([1]) -> frozenset([3]) 的可信度和 frozenset([3]) -> frozenset([1]) 的可信度
conf = supportData[freqSet] / supportData[freqSet - conseq] # 支持度定义: a -> b = support(a | b) / support(a). 假设 freqSet = frozenset([1, 3]), conseq = [frozenset([1])],那么 frozenset([1]) 至 frozenset([3]) 的可信度为 = support(a | b) / support(a) = supportData[freqSet]/supportData[freqSet-conseq] = supportData[frozenset([1, 3])] / supportData[frozenset([1])]
if conf >= minConf:
print(freqSet - conseq, '-->', conseq, 'conf:', conf)
brl.append((freqSet - conseq, conseq, conf))
prunedH.append(conseq)
return prunedH # 递归计算频繁项集的规则
def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7):
'''
:param freqSet: 频繁项集中的元素,例如: frozenset([2, 3, 5])
:param H: 频繁项集中的元素的集合,例如: [frozenset([2]), frozenset([3]), frozenset([5])]
:param supportData: 所有元素的支持度的字典
:param brl: 关联规则列表的数组
:param minConf: 最小可信度
'''
# H[0] 是 freqSet 的元素组合的第一个元素,并且 H 中所有元素的长度都一样,长度由 aprioriGen(H, m+1) 这里的 m + 1 来控制
# 该函数递归时,H[0] 的长度从 1 开始增长 1 2 3 ...
# 假设 freqSet = frozenset([2, 3, 5]), H = [frozenset([2]), frozenset([3]), frozenset([5])]
# 那么 m = len(H[0]) 的递归的值依次为 1 2
# 在 m = 2 时, 跳出该递归。假设再递归一次,那么 H[0] = frozenset([2, 3, 5]),freqSet = frozenset([2, 3, 5]) ,没必要再计算 freqSet 与 H[0] 的关联规则了。
m = len(H[0])
if (len(freqSet) > (m + 1)):
# 生成 m+1 个长度的所有可能的 H 中的组合,假设 H = [frozenset([2]), frozenset([3]), frozenset([5])]
# 第一次递归调用时生成 [frozenset([2, 3]), frozenset([2, 5]), frozenset([3, 5])]
# 第二次 。。。没有第二次,递归条件判断时已经退出了
Hmp1 = aprioriGen(H, m + 1)
# 返回可信度大于最小可信度的集合
Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf) # 计算可信度后,还有数据大于最小可信度的话,那么继续递归调用,否则跳出递归
if (len(Hmp1) > 1):
rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf) # 生成关联规则
def generateRules(L, supportData, minConf=0.7):
'''
:param L: 频繁项集列表
:param supportData: 频繁项集支持度的字典
:param minConf: 最小可信度
:return:
bigRuleList 可信度规则列表(关于 (A->B+可信度) 3个字段的组合)
'''
bigRuleList = []
# 假设 L = [[frozenset([1]), frozenset([3]), frozenset([2]), frozenset([5])], [frozenset([1, 3]), frozenset([2, 5]), frozenset([2, 3]), frozenset([3, 5])], [frozenset([2, 3, 5])]]
for i in range(1, len(L)):
# 获取频繁项集中每个组合的所有元素
for freqSet in L[i]:
# 假设:freqSet= frozenset([1, 3]), H=[frozenset([1]), frozenset([3])]
# 组合总的元素并遍历子元素,并转化为 frozenset 集合,再存放到 list 列表中
H = [frozenset([item]) for item in freqSet]
# 2 个的组合,走 else, 2 个以上的组合,走 if
if (i > 1):
rulesFromConseq(freqSet, H, supportData, bigRuleList, minConf)
else:
calcConf(freqSet, H, supportData, bigRuleList, minConf)
return bigRuleList if __name__ == '__main__':
dataSet = load_dataSet()
L, supportData = apriori(dataSet)
bigRuleList = generateRules(L, supportData)
print(bigRuleList)
apriori.py
- 分级法: 频繁项集->关联规则
- 1.首先从一个频繁项集开始,接着创建一个规则列表,其中规则右部分只包含一个元素,然后对这个规则进行测试。
- 2.接下来合并所有剩余规则来创建一个新的规则列表,其中规则右部包含两个元素。
- 如下图:
- 最后: 每次增加频繁项集的大小,Apriori 算法都会重新扫描整个数据集,是否有优化空间呢?
转载自: ApacheCN
Machine Learning 算法可视化实现2 - Apriori算法实现的更多相关文章
- 数据挖掘算法(四)Apriori算法
参考文献: 关联分析之Apriori算法
- 【Machine Learning·机器学习】决策树之ID3算法(Iterative Dichotomiser 3)
目录 1.什么是决策树 2.如何构造一棵决策树? 2.1.基本方法 2.2.评价标准是什么/如何量化评价一个特征的好坏? 2.3.信息熵.信息增益的计算 2.4.决策树构建方法 3.算法总结 @ 1. ...
- Apriori算法实现
Apriori算法原理:http://blog.csdn.net/kingzone_2008/article/details/8183768 import java.util.HashMap; imp ...
- 关联规则—频繁项集Apriori算法
频繁模式和对应的关联或相关规则在一定程度上刻画了属性条件与类标号之间的有趣联系,因此将关联规则挖掘用于分类也会产生比较好的效果.关联规则就是在给定训练项集上频繁出现的项集与项集之间的一种紧密的联系.其 ...
- 海量数据挖掘MMDS week2: 频繁项集挖掘 Apriori算法的改进:基于hash的方法
http://blog.csdn.net/pipisorry/article/details/48901217 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- Apriori算法详解
一.Apriori 算法概述Apriori 算法是一种最有影响力的挖掘布尔关联规则的频繁项集的 算法,它是由Rakesh Agrawal 和RamakrishnanSkrikant 提出的.它使用一种 ...
- [Machine Learning] 国外程序员整理的机器学习资源大全
本文汇编了一些机器学习领域的框架.库以及软件(按编程语言排序). 1. C++ 1.1 计算机视觉 CCV —基于C语言/提供缓存/核心的机器视觉库,新颖的机器视觉库 OpenCV—它提供C++, C ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 9) Anomaly Detection&Recommender Systems
这部分内容来源于Andrew NG老师讲解的 machine learning课程,包括异常检测算法以及推荐系统设计.异常检测是一个非监督学习算法,用于发现系统中的异常数据.推荐系统在生活中也是随处可 ...
- 机器学习实战(Machine Learning in Action)学习笔记————07.使用Apriori算法进行关联分析
机器学习实战(Machine Learning in Action)学习笔记————07.使用Apriori算法进行关联分析 关键字:Apriori.关联规则挖掘.频繁项集作者:米仓山下时间:2018 ...
随机推荐
- 22)django-中间件
一:中间件介绍 django 中的中间件(middleware),在django中,中间件其实就是一个类,在请求到来和结束后, django会根据自己的规则在合适的时机执行中间件中相应的方法. 在dj ...
- 鼠标hover图片时遮罩层匀速上升显示内容top、定位
1.html <div class="div1"> <div class="div11"> <p >Dolor nu ...
- js——事件冒泡与捕获小例子
布局代码 #outer{ width: 300px; height: 300px; background: red; } #inner{ width: 200px; height: 200px; ba ...
- 中介模型以及优化查询以及CBV模式
一.中介模型:多对多添加的时候用到中介模型 自己创建的第三张表就属于是中介模型 class Article(models.Model): ''' 文章表 ''' title = models.Char ...
- LeetCode(123):买卖股票的最佳时机 III
Hard! 题目描述: 给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格. 设计一个算法来计算你所能获取的最大利润.你最多可以完成 两笔 交易. 注意: 你不能同时参与多笔交易(你必 ...
- WEB漏洞 XSS(一)
1.xss的形成原理 xss 中文名是“跨站脚本攻击”,英文名“Cross Site Scripting”.xss也是一种注入攻击,当web应用对用户输入过滤不严格,攻击者写入恶意的脚本代码(HTML ...
- java web----MINA框架使用
前期准备 1.下载 http://mina.apache.org/ 2.将依赖包添加到工程目录下(在工程目录下创建libs(directory目录)) 3.将 slf4j-api-1.7.26.jar ...
- C++ Primer 笔记——OOP
1.基类通常都应该定义一个虚析构函数,即使该函数不执行任何实际操作也是如此. 2.任何构造函数之外的非静态函数都可以是虚函数,关键字virtual只能出现在类内部的声明语句之前而不能用于类外部的函数定 ...
- 论文阅读笔记二十六:Fast R-CNN (ICCV2015)
论文源址:https://arxiv.org/abs/1504.08083 参考博客:https://blog.csdn.net/shenxiaolu1984/article/details/5103 ...
- 论文阅读笔记二-ImageNet Classification with Deep Convolutional Neural Networks
分类的数据大小:1.2million 张,包括1000个类别. 网络结构:60million个参数,650,000个神经元.网络由5层卷积层,其中由最大值池化层和三个1000输出的(与图片的类别数相同 ...