自然语言处理之jieba分词
在处理英文文本时,由于英文文本天生自带分词效果,可以直接通过词之间的空格来分词(但是有些人名、地名等需要考虑作为一个整体,比如New York)。而对于中文还有其他类似形式的语言,我们需要根据来特殊处理分词。而在中文分词中最好用的方法可以说是jieba分词。接下来我们来介绍下jieba分词的特点、原理与及简单的应用
1、特点
1)支持三种分词模式
精确模式:试图将句子最精确的切开,适合文本分析
全模式:把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义
搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词
2)支持繁体分词
3)支持自定义词典(支持载入新的词典或者更新自带的词典)
2、原理
jieba分词的算法原理主要有以下三项:
1)基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG)
2)采用了动态规划查找最大概率路径,找出基于词频的最大切分组合
3)对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法
接下来我们来逐步的讲解这三种方法。
第一条:基于Tier树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图。
首先我们来介绍下Tier树,Tier树中文名叫字典树、前缀树等等。它的用途主要是将字符串整合成树形。首先我们来看一下由 “清华大学” 、“清华” 、“清新” 、“中华” 、“华人” 五个中文词构成的Tier树。树的结构如下
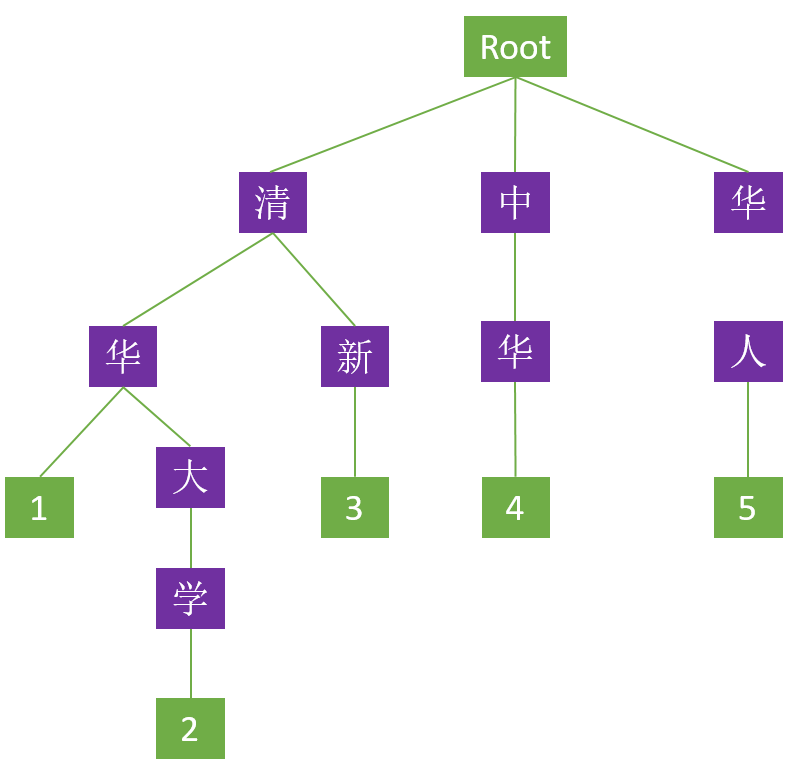
这个树里面每一个方块代表一个节点,其中 ”Root” 表示根节点,不代表任何字符;紫色代表分支节点;绿色代表叶子节点。除根节点外每一个节点都只包含一个字符。从根节点到叶子节点,路径上经过的字符连接起来,构成一个词。而叶子节点内的数字代表该词在字典树中所处的链路(字典中有多少个词就有多少条链路),具有共同前缀的链路称为串。除此之外,还需特别强调 Trie 树的以下几个特点:
1)具有相同前缀的词必须位于同一个串内;例如 “清华”、“清新” 两个词都有“清”这个前缀,那么在 Trie 树上只需构建一个 “清” 节点,“华” 和 “新” 节点共用一个父节点即可,如此两个词便只需三个节点便可存储,这在一定程度上减少了字典的存储
空间。)
2)Trie 树中的词只可共用前缀,不可共用词的其他部分;例如 “中华”、“华人” 这两个词虽然前一个词的后缀是后一个词的前缀,但在树形上必须是独立的两条链路,而不可以通过首尾交接构建这两个词,这也说明 Trie 树仅能依靠公共前缀压缩字典的存
储空间,并不能共享词中的所有相同的字符;当然,这一点也有 “例外” ,对于复合词,可能会出现两词首尾交接的假象,比如 “清华大学” 这个词在上例 Trie 树中看起来似乎是由 “清华” 、“大学” 两词首尾交接而成,但是叶子节点的标识已经明
确说明 Trie 树里面只有 ”清华“ 和 ”清华大学“ 两个词,它们之间共用了前缀,而非由 “清华” 和 ”大学“ 两词首尾交接所得,因此上例 Trie 树中若需要 “大学” 这个词则必须从根节点开始重新构建该词。)
3)Trie 树中任何一个完整的词,都必须是从根节点开始至叶子节点结束,这意味着对一个词进行检索也必须从根节点开始,至叶子节点才算结束。
在 Trie 树中搜索一个字符串,会从根节点出发,沿着某条链路向下逐字比对字符串的每个字符,直到抵达底部的叶子节点才能确认字符串为该词,这种检索方式具有以下两个优点:
1)公共前缀的词都位于同一个串内,查词范围因此被大幅缩小(比如首字不同的字符串,都会被排除)。)
2)Trie 树实质是一个有限状态自动机((Definite Automata, DFA),这就意味着从 Trie 树的一个节点(状态)转移到另一个节点(状态)的行为完全由状态转移函数控制,而状态转移函数本质上是一种映射,这意味着:逐字搜索 Trie 树时,从一个字符到下
一个字符比对是不需要遍历该节点的所有子节点的。
构建完Tier树之后就可以根据Tier树生成句子的有向无环图(DAG)
如果待切分的字符串有m个字符,考虑每个字符左边和右边的位置,则有m+1个点对应,点的编号从0到m。把候选词看成边,可以根据词典生成一个切分词图。切分词图是一个有向正权重的图。"有意见分歧" 这句话的切分词图如下所示。
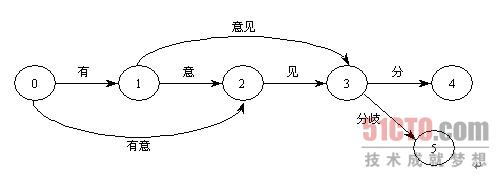
在 "有意见分歧" 的切分词图中:"有" 这条边的起点是0,终点是1;"有意" 这条边的起点是0,终点是2,以此类推。切分方案就是从源点0到终点5之间的路径,共存在两条切分路径。
路径1:0-1-3-5 对应切分方案S1:有/ 意见/ 分歧/
路径2:0-2-3-5 对应切分方案S2:有意/ 见/ 分歧/
第二条:采用了动态规划查找最大概率路径,找出基于词频的最大切分组合
在jieba分词中的Tier树会标记每个词的频率(等于出现的次数除以总数,当总体样本很大时,可以近似的看做词的概率),在知道每个词出现的频率之后,就可以基于动态规划的方法来寻找概率最大的分词路径。一般的动态规划寻找最优路径都是从左往右,然而在这里是从右往左去寻找最优路径。这主要是因为汉语句子中的重心往往在后面,后面才是句子的主干,因此从右往左计算的正确率往往要高于从左往右的正确率。
第三条:对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法
未登录词就是在词典(Tier树)中未记录的词。对于这类词就是采用HMM模型来生成的(因此如果删除了词典,也是可以进行分词的)。那么HMM模型是如何构建的呢?首先定义了四种状态BEMS,B是开始,begin位置;E是end,是结束位置;M是middle,是中间位置;S是singgle,单独成词的位置,没有前,也没有后。也就是说,他采用了状态为(B、E、M、S)这四种状态来标记中文词语,比如北京可以标注为 BE,即 北/B 京/E,表示北是开始位置,京是结束位置;中华民族可以标注为BMME,就是开始、中间、中间、结束。
jieba分词的作者对大量语料进行的训练,得到了finalseg目录下的三个文件(prob_trans.py 、prob_emit.py 、prob_start.py )
要统计的主要有三个概率表:
prob_trans.py
1)位置转换概率,即B(开头),M(中间),E(结尾),S(独立成词)四种状态的转移概率;
{‘B’: {‘E’: 0.8518218565181658, ‘M’: 0.14817814348183422},
‘E’: {‘B’: 0.5544853051164425, ‘S’: 0.44551469488355755},
‘M’: {‘E’: 0.7164487459986911, ‘M’: 0.2835512540013088},
‘ S’: {‘B’: 0.48617017333894563, ‘S’: 0.5138298266610544}}
P(E|B) = 0.851;P(M|B) = 0.149,说明当我们处于一个词的开头时,下一个字是结尾的概率要远高于下一个字是中间字的概率,符合我们的直觉,因为二个字的词比多个字的词更常见。
prob_emit.py
2)位置到单字的发射概率,比如P(“和”|M)表示一个词的中间出现”和”这个字的概率;
prob_start.py
3)词语以某种状态开头的概率,其实只有两种,要么是B,要么是S。这个就是起始向量,就是HMM系统的最初模型状态实际上,BEMS之间的转换有点类似于2元模型,就是2个词之间的转移二元模型考虑一个单词后出现另外一个单词的概率,
是N元模型中的一种。例如:一般来说,”中国”之后出现”北京”的概率大于”中国”之后出现”北海”的概率,也就是:中国北京 比 中国北海出现的概率大些, 更有可能是一个中文词语。但是这里并不能确定作者是不是使用了二元模型。不过jieba分词的
性能这么好,应该不是使用了二元模型。
因此jieba分词的过程:
1)生成Tier树
2)给定句子,使用正则获取连续的中文字符和英文字符,切分成短语列表,构建有向无环图(先生成,然后去词典中匹配寻找最大概率路径)和使用动态规划,得到概率最大的路径。对DAG中那些没有在字典中查到的词,组合成一个新的片段短语,
使用HMM模型进行分词。
3)使用python中的yield语法生成一个词语生成器返回.
3、应用
1)分词
jieba.cut 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型
jieba.cut_for_search 方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细。待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。
注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8
jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode),或者用
jieba.lcut 以及 jieba.lcut_for_search 直接返回 list
jieba.Tokenizer(dictionary=DEFAULT_DICT) 新建自定义分词器,可用于同时使用不同词典。jieba.dt 为默认分词器,所有全局分词相关函数都是该分词器的映射。
2)添加自定义词典
载入词典:
开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。虽然 jieba 有新词识别能力,但是自行添加新词可以保证更高的正确率
用法: jieba.load_userdict(file_name) # file_name 为文件类对象或自定义词典的路径
词典格式和 dict.txt 一样,一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。file_name 若为路径或二进制方式打开的文件,则文件必须为 UTF-8 编码。
词频省略时使用自动计算的能保证分出该词的词频。
调整词典:
使用 add_word(word, freq=None, tag=None) 和 del_word(word) 可在程序中动态修改词典。
使用 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
注意:自动计算的词频在使用 HMM 新词发现功能时可能无效。
3)关键词提取
基于TF-IDF算法的关键词抽取:
import jieba.analyse
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
sentence 为待提取的文本
topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
withWeight 为是否一并返回关键词权重值,默认值为 False
allowPOS 仅包括指定词性的词,默认值为空,即不筛选
jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件
基于TextRank算法的关键词抽取:
jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v')) 直接使用,接口相同,注意默认过滤词性。
jieba.analyse.TextRank() 新建自定义 TextRank 实例
4)词性标注
ieba.posseg.POSTokenizer(tokenizer=None) 新建自定义分词器,tokenizer 参数可指定内部使用的jieba.Tokenizer 分词器。jieba.posseg.dt 为默认词性标注分词器。
5)并行分词
原理:将目标文本按行分隔后,把各行文本分配到多个 Python 进程并行分词,然后归并结果,从而获得分词速度的可观提升
基于 python 自带的 multiprocessing 模块,目前暂不支持 Windows
用法:
jieba.enable_parallel(4) # 开启并行分词模式,参数为并行进程数
jieba.disable_parallel() # 关闭并行分词模式
6)Tokenize:返回词语在原文中的起止位置
jieba.tokenize(text)
7)延迟加载机制
jieba 采用延迟加载,import jieba 和 jieba.Tokenizer() 不会立即触发词典的加载,一旦有必要才开始加载词典构建前缀字典。如果你想手工初始 jieba,也可以手动初始化。
jieba.initialize()
自然语言处理之jieba分词的更多相关文章
- Python自然语言处理学习——jieba分词
jieba——“结巴”中文分词是sunjunyi开发的一款Python中文分词组件,可以在Github上查看jieba项目. 要使用jieba中文分词,首先需要安装jieba中文分词,作者给出了如下的 ...
- 自然语言处理之中文分词器-jieba分词器详解及python实战
(转https://blog.csdn.net/gzmfxy/article/details/78994396) 中文分词是中文文本处理的一个基础步骤,也是中文人机自然语言交互的基础模块,在进行中文自 ...
- 自然语言处理课程(二):Jieba分词的原理及实例操作
上节课,我们学习了自然语言处理课程(一):自然语言处理在网文改编市场的应用,了解了相关的基础理论.接下来,我们将要了解一些具体的.可操作的技术方法. 作为小说爱好者的你,是否有设想过通过一些计算机工具 ...
- pypinyin, jieba分词与Gensim
一 . pypinyin from pypinyin import lazy_pinyin, TONE, TONE2, TONE3 word = '孙悟空' print(lazy_pinyin(wor ...
- jieba分词(1)
近几天在做自然语言处理,看了一篇论文:面向知识库的中文自然语言问句的语义理解,里面提到了中文的分词,大家都知道对于英文的分词,NLTK有很好的支持,但是NLTK对于中文的分词并不是很好(其实也没有怎么 ...
- jieba分词-强大的Python 中文分词库
1. jieba的江湖地位 NLP(自然语言)领域现在可谓是群雄纷争,各种开源组件层出不穷,其中一支不可忽视的力量便是jieba分词,号称要做最好的 Python 中文分词组件. 很多人学习pytho ...
- jieba分词处理
分词是一种数学上的应用,他可以直接根据词语之间的数学关系进行文字或者单词的抽象,比如,讲一句话"我来自地球上中国"进行单词分割,我们可能会得到如下的内容:"我" ...
- widows下jieba分词的安装
在切词的时候使用到jieba分词器,安装如下: 切入到结巴包,执行 python setup.py install 安装后,可以直接在代码中引用: import jieba
- 【原】关于使用jieba分词+PyInstaller进行打包时出现的一些问题的解决方法
错误现象: 最近在做一个小项目,在Python中使用了jieba分词,感觉非常简洁方便.在Python端进行调试的时候没有任何问题,使用PyInstaller打包成exe文件后,就会报错: 错误原因分 ...
随机推荐
- .NET 发送电子邮件
static void Main(string[] args) { ///先引入 using System.Net.Mail; ///发送邮件 using (MailMessage mailMessa ...
- react-conponent-todo
<!DOCTYPE html> <html> <head> <script src="../../build/react.js">& ...
- 腾讯的产品思维 VS 阿里的终局思维
从成立到借壳上市,有赞用了5年多时间.这期间,它有好几次机会死掉,有很多的理由活不到今天,白鸦曾经说,每一次度过难关最关键都是靠团队的力量.谢天谢地,它活了下来. 那么,这个在To B领域敢打敢拼的团 ...
- 关于TensorFlow你需要了解的9件事
关于TensorFlow你需要了解的9件事 https://mp.weixin.qq.com/s/cEQAdLnueMEj0OQZtYvcuw 摘要:本文对近期在旧金山举办的谷歌 Cloud Next ...
- .net core 下编码问题
System.Globalization.CultureInfo.CurrentCulture = new System.Globalization.CultureInfo("zh-CN&q ...
- iOS----------开发中常用的宏有那些
OC对象判断是否为空? 字符串是否为空 #define kStringIsEmpty(str) ([str isKindOfClass:[NSNull class]] || str == nil || ...
- 自定义控件详解(六):Paint 画笔MaskFilter过滤
首先看一个API:setMaskFilter(MaskFilter maskfilter): 设置MaskFilter,可以用不同的MaskFilter实现滤镜的效果,如滤化,立体等. 以下有两个Ma ...
- filter帅选
var ages = [32, 33, 16, 40]; ages= ages.filter(function checkAdult(obj) {//obj表示数组中的每个元素 return obj ...
- 新的 Centos 服务器初始化配置
当你初次创建新的 Centos 服务器的时候, Centos 默认的配置安全性和可用性上会存在一点缺陷(运维人员往往会有初始化的脚本).为了增强服务器的安全性和可用性,有些配置你应该尽快地完成. 这篇 ...
- 编程经验点滴----在 Oracle 数据库中保存空字符串
写程序这么多年,近几天才发现,向 Oracle 数据库表中,保存空字符串 '' ,结果成了 null. 由于数据库数值 null 的比较.判断,与空字符串 '' 存在差异.一不留神,代码中留下了 bu ...