Java8 Hash改进/内存改进
又开新坑o(*≧▽≦)ツ讲讲几个Java版本的特性,先开始Java8,

HashMap的改进
HashMap采用哈希算法,先使用hashCode()判断哈希值是否相同,如果相同,再使用equals(),如果再相同,则会替换掉原先的值,如不同则形成链表,后来的放前,原先的被挤到后面去,这种情况叫碰撞,我们应该要尽量避免这种情况,所以我们要通过改进hashCode()和equals(),当然我们无法完全避免这种情况。
为了不让链表太长,HashMap提供了加载因子,0.75,当元素到达哈希表的75%时,进行扩容,如果设定到100%扩容,也许算出的哈希值就只有那几个,比如长度为16的哈希表,一直只存3,5,7,8,其他的哈希值所在的位置无人问津,这样就会产生很长的链影响性能。那么哈希值可以取很小吗?也不可以,这样会频繁扩容,浪费空间。
一旦扩容,会将链表里的元素,每个重新计算新的位置,这样碰撞概率就会变低。
即使有这种扩容机制,但是碰撞依旧避免不了,所以意味着效率变低,打个比方,在1.8之前Java采用数组+链表方式,如果产生了冲突情况,比如我找哈希值为3的值,就要从数组索引值为3的链表头开始找,最糟糕的情况是找到这个链表的尾部,因此1.8将这种结构改进,变成数组+链表+红黑树 。
当链表上碰撞的个数大于8,总容量大于64,就会将链表转换成红黑树,这样的好处,除了添加,其他操作都要比链表快。

ConcurrentHashMap
1.7之前,并发级别默认为16,concurrentLevel=16;现在来介绍一下ConcurrentHashMap:
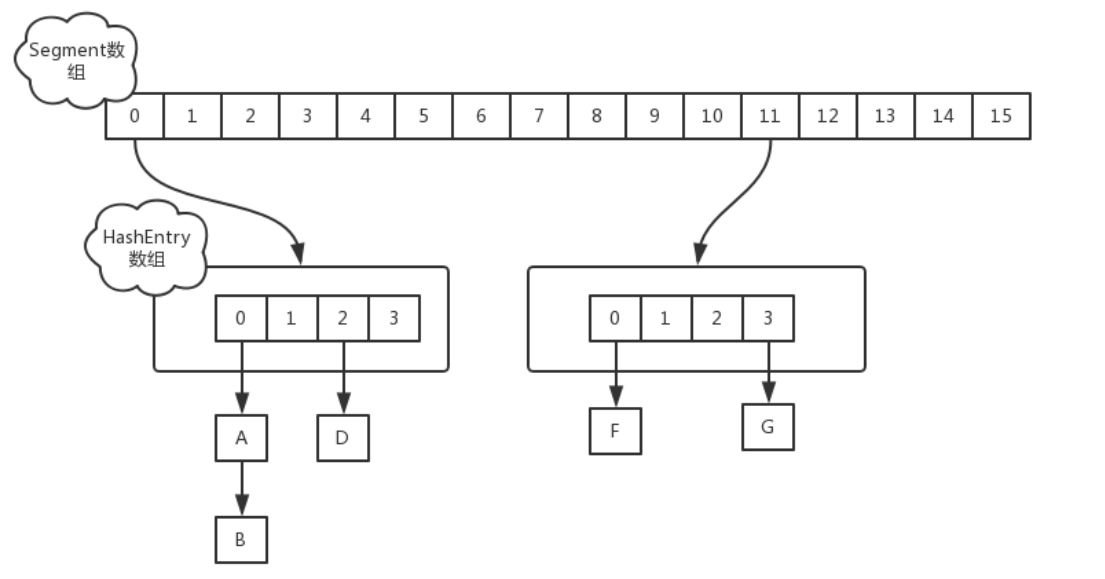
ConcurrentHashMap的数据结构是由一个Segment数组和多个HashEntry组成,主要实现原理是实现了锁分离的思路解决了多线程的安全问题,如下图所示:
Segment数组的意义就是将一个大的table分割成多个小的table来进行加锁,也就是上面的提到的锁分离技术,而每一个Segment元素存储的是HashEntry数组+链表,这个和HashMap的数据存储结构一样。
ConcurrentHashMap 与HashMap和Hashtable 最大的不同在于:put和 get 两次Hash到达指定的HashEntry,第一次hash到达Segment,第二次到达Segment里面的Entry,然后在遍历entry链表。
JDK1.8的实现已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作,整个看起来就像是优化过且线程安全的HashMap,虽然在JDK1.8中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本。
内存改进
内存分为三大块,栈、堆、方法区,之前方法区其实属于堆的永久区的一部分,可是我们平常都把它分开画,因为JDK1.8取消这块方法区,取而代之的是MetaSpace(元空间),最大特色是它直接使用物理内存,而不是使用分配内存,这说明垃圾回收机制运行机制概率变低,效率提升。也就是说OutOfMemoryError,几乎不会发生。
既然如此,一些调优条件就无效了,比如PremGenSize、MaxPremGenSize,取而代之的是MetaspaceSize MaxMetaspaceSize

参考博文:
https://www.cnblogs.com/duanxz/p/3520829.html
https://www.jianshu.com/p/a7767e6ff2a2
Java8 Hash改进/内存改进的更多相关文章
- 为什么hash作为内存使用的经典数据结构?
听到这样说法:hash是内存中使用的经典数据结构.内存是典型的随机访问设备. 为什么hash这种数据结构很适合内存使用呢?如何理解内存是随机访问设备呢? 因为我想知其所以然,如何理解背后的原因,我花费 ...
- Java8 读写锁的改进:StampedLock(笔记)
StampedLock是Java8引入的一种新的所机制,简单的理解,可以认为它是读写锁的一个改进版本,读写锁虽然分离了读和写的功能,使得读与读之间可以完全并发,但是读和写之间依然是冲突的,读 ...
- java8新特性:内存和lambda表达式
1.内存变化 取消了永久区和方法区,取而代之的是MetaSpace元空间,即直接使用物理内存,即电脑内存8G则直接使用8g内存,而不是分配内存.因为内存改变,所以调整性能对应的调整参数也随之改变. 2 ...
- 美团分布式ID生成框架Leaf源码分析及优化改进
本文主要是对美团的分布式ID框架Leaf的原理进行介绍,针对Leaf原项目中的一些issue,对Leaf项目进行功能增强,问题修复及优化改进,改进后的项目地址在这里: Leaf项目改进计划 https ...
- 【译】ASP.NET Core 6 中的性能改进
原文 | Brennan Conroy 翻译 | 郑子铭 受到 Stephen Toub 关于 .NET 性能的博文的启发,我们正在写一篇类似的文章来强调 6.0 中对 ASP.NET Core 所做 ...
- Fedora 24最新工作站版本之四大重要改进
导读 2014年,Fedora.next倡议正式开始建立Fedora Linux未来十年的发展规划.从本质上讲,这项规划旨在进一步使Fedora不再只是一套汇聚多种开源产品的通用库(例如Debian) ...
- 改进的newlisp编译脚本,只需要配置
前面有一篇Say bye to CMake and Makefile我开始用自己编写的newlisp脚本替代CMake,今天对前面的进行改进. 改进部分是: 1. newlisp armory模块的引 ...
- 团队作业3-需求改进&原型设计
选题:实验室报修系统 实验室设备经常会发生这样或那样的故障,靠值班人员登记设备故障现象,维护人员查看故障记录,进行维修,然后登记维修过程与内容,以备日后复查,用这种方式进行设备运营管理,它仅仅起到一个 ...
- k-means算法的优缺点以及改进
大家接触的第一个聚类方法,十有八九都是K-means聚类啦.该算法十分容易理解,也很容易实现.其实几乎所有的机器学习和数据挖掘算法都有其优点和缺点.那么K-means的缺点是什么呢? 总结为下: (1 ...
随机推荐
- 缓存数据库Memcache
为什么用缓存数据库 MySQL:将数据存储在磁盘上,数据写入读取相对较慢 Memcached:将数据存在内存中的数据库,数据读写都快,但是数据容易丢失 数据存储,数据仓库选择MySQL这种磁盘的数据库 ...
- I/O 机制的介绍(Linux 中直接 I/O 机制的介绍)
IO连接的建立方式 1.缓存IO.流式IO: 2.映射IO.块式IO: 3.直接IO. IO的方式: 同步.异步.定时刷新: MMAP与内核空间 mmap使用共享用户空间与内核空间实现: 直接 I/O ...
- Leetcode:204
编写一个程序判断给定的数是否为丑数.丑数就是只包含质因数 2, 3, 5 的正整数.统计所有小于非负整数 n 的质数的数量.示例:输入: 10输出: 4解释: 小于 10 的质数一共有 4 个, 它们 ...
- [CQOI2016]手机号码
嘟嘟嘟 这题一看就是数位dp. 我写数位dp,一般是按数位dp的格式写一个爆搜,然后加一点记忆化. 不过其实我一直不是很清楚记忆化是怎么加,感觉就是把dfs里的参数都扔到dp数组里,好像很暴力啊. 这 ...
- sqlachemy 查询当日数据,
Tokens.query.filter(Tokens.user_id == user_id, db.cast(Tokens.create_time, db.DATE) == db.cast(curre ...
- 数据泵expdp 在rac环境下 paralle 的处理方法
其实这个是个很常见的问题,写下来做纪念吧.说明:而在11GR2后EXPDP 和 IMDP的WORKER进程在设置parallel参数时会在多个INSTANCE启动,所以DIRECTORY必须在共享磁盘 ...
- idea 2018.1 for mac JRebel破解
第一步: 在 Idea 中下载 Jrebel 路径:preferences-plugins-Browse repositories-直接搜索下载 Jrebel 第二步:配置反向代理工具 1.安装 ...
- bernoulli数
LL B[N][],C[N][N],f[N][]; int n,m; LL gcd(LL a,LL b){return b?gcd(b,a%b):a;} LL lcm(LL a,LL b){retur ...
- CF434D Nanami's Power Plant 最小割
传送门 因为连距离限制的边的细节调了贼久QAQ 这个题和HNOI2013 切糕性质相同,都是有距离限制的最小割问题 对于每一个函数,用一条链记录变量\(x\)在不同取值下这个函数的贡献.对于一个\(x ...
- 深入浅出:HTTP/2
上篇文章深入浅出:5G和HTTP里给自己挖了一根深坑,说是要写一篇关于HTTP/2的文章,今天来还账了. 本文分为以下几个部分: HTTP/2的背景 HTTP/2的特点 HTTP/2的协议分析 HTT ...