[Scikit-learn] 1.1 Generalized Linear Models - Lasso Regression
Ref: http://blog.csdn.net/daunxx/article/details/51596877
Ref: https://www.youtube.com/watch?v=ipb2MhSRGdw
Ref: nullege.com/codes
大纲 OUTLINE
初步认识
一、Lasso回归的几种算法
Lasso Regression(L1)
|-- Coordinate descent【最快算法】
|-- Least Angle Regression【最好算法】
|-- Compressive sensing【究极应用】
二、Lasso回归模型
是一个用于估计稀疏参数的线性模型,特别适用于参数数目缩减。基于这个原因,Lasso回归模型在压缩感知(compressed sensing)中应用的十分广泛。从数学上来说,Lasso是在线性模型上加上了一个L1正则项。
对L1正则项后效果的理解:Sparsity and Some Basics of L1 Regularization
Lasso 与 “稀疏解”

图上画了原始的 least square 解,LASSO 的解以及 ridge regression 的解,用上面同样的方法(不过由于 ridge regularizer 是 smooth 的,所以过程却简单得多)可以得知 ridge regression 的解是如下形式
- ridge regression 只是做了一个全局缩放
- LASSO 则是做了一个 soft thresholding
- 将绝对值小于 的那些系数直接变成零了,这也就更加令人信服地解释了 LASSO 为何能够产生稀疏解了。
算法详解
一、坐标下降法 - Coordinate descent
Lasso回归的最快解法
坐标下降法在稀疏矩阵上的计算速度非常快,同时也是Lasso回归最快的解法。 (最快不一定最好)
代码详见: http://blog.csdn.net/daunxx/article/details/51596877
#!/usr/bin/python
# -*- coding: utf-8 -*- """
author : duanxxnj@163.com
time : 2016-06-06_15-41 Lasso 回归应用于稀疏信号 """
print(__doc__) import numpy as np
import matplotlib.pyplot as plt
import time from sklearn.linear_model import Lasso
from sklearn.metrics import r2_score # 用于产生稀疏数据
np.random.seed(int(time.time()))
# 生成系数数据,样本为50个,参数为200维
n_samples, n_features = 50, 200
# 基于高斯函数生成数据
X = np.random.randn(n_samples, n_features)
# 每个变量对应的系数
coef = 3 * np.random.randn(n_features)
# 变量的下标
inds = np.arange(n_features)
# 变量下标随机排列
np.random.shuffle(inds)
# 仅仅保留10个变量的系数,其他系数全部设置为0
# 生成稀疏参数
coef[inds[10:]] = 0
# 得到目标值,y
y = np.dot(X, coef)
# 为y添加噪声
y += 0.01 * np.random.normal((n_samples,)) # 将数据分为训练集和测试集
n_samples = X.shape[0]
X_train, y_train = X[:n_samples / 2], y[:n_samples / 2]
X_test, y_test = X[n_samples / 2:], y[n_samples / 2:] # Lasso 回归的参数
alpha = 0.1
lasso = Lasso(max_iter=10000, alpha=alpha) # 基于训练数据,得到的模型的测试结果
# 这里使用的是坐标轴下降算法(coordinate descent)
y_pred_lasso = lasso.fit(X_train, y_train).predict(X_test) # 这里是R2可决系数(coefficient of determination)
# 回归平方和(RSS)在总变差(TSS)中所占的比重称为可决系数
# 可决系数可以作为综合度量回归模型对样本观测值拟合优度的度量指标。
# 可决系数越大,说明在总变差中由模型作出了解释的部分占的比重越大,模型拟合优度越好。
# 反之可决系数小,说明模型对样本观测值的拟合程度越差。
# R2可决系数最好的效果是1。
r2_score_lasso = r2_score(y_test, y_pred_lasso) print("测试集上的R2可决系数 : %f" % r2_score_lasso) plt.plot(lasso.coef_, label='Lasso coefficients')
plt.plot(coef, '--', label='original coefficients')
plt.legend(loc='best') plt.show()
可见,200个系数的最终结果如下:

迹线图查看:(迹线颜色的设置:http://matplotlib.org/api/colors_api.html)

Standardize data

运行结果比对如下:


二、最小角回归 - Least Angle Regression(LARS)
最小角回归是针对高维数据的回归算法,由Bradley Efron, Trevor Hastie, Iain Johnstone 和 Robert Tibshirani开发。
LARS模型可以使用estimator Lars ,或者底层实现 lars_path 。
LassoLars is a lasso model implemented using the LARS algorithm, and unlike the implementation based on coordinate_descent,
this yields the exact solution, which is piecewise linear as a function of the norm of its coefficients.
LARS的优势
- 当 p >> n 时计算是非常高效的。(比如当维数远大于点数)
- 它和前向选择计算速度差不多一样块,并且和普通最小二乘复杂度一样。
- 它生成一个完整的分段线性的解的路径,这对于交叉验证或者类似的尝试来调整模型是有效的。
- 如果两个变量的相应总是相同,那么它们的系数应该有近似相同的增长速率。因此这算法和直觉判断一样,并且增长总是稳定的。
- It is easily modified to produce solutions for other estimators, like the Lasso.
LARS的缺点
- 因为LARS是基于剩余误差多次迭代拟合,所以对噪声的影响比较敏感。这个问题在 Efron et al. (2004) Annals of Statistics article这篇文章中讨论部分详细谈论了。
基本原理
在阐述最小角回归( Least Angle Regression)算法,首先介绍两种更为简单直观的前向(Forward)算法做一些说明,最小回归算法是以这两种前向算法为基础的:
- 前向选择算法
- 前向梯度算法
代码实践
良心博文:http://blog.csdn.net/xbinworld/article/details/44284293
事实上,不论是Lasso还是Stagewise方法都是Least angle regression(LARS)的变种。
LARS的选择不需要经历那么多小的迭代,可以每次都在需要的方向上一步走到最远,因此计算速度很快,下面来具体描述一下LARS。
#!/usr/bin/env python
"""
=====================
Lasso path using LARS
===================== Computes Lasso Path along the regularization parameter using the LARS
algorithm on the diabetes dataset. Each color represents a different
feature of the coefficient vector, and this is displayed as a function
of the regularization parameter. """
print(__doc__) # Author: Fabian Pedregosa <fabian.pedregosa@inria.fr>
# Alexandre Gramfort <alexandre.gramfort@inria.fr>
# License: BSD 3 clause import numpy as np
import matplotlib.pyplot as plt from sklearn import linear_model
from sklearn import datasets
# Get data
diabetes = datasets.load_diabetes()
X = diabetes.data
y = diabetes.target
# training
print("Computing regularization path using the LARS ...")
alphas, _, coefs = linear_model.lars_path(X, y, method='lasso', verbose=True) xx = np.sum(np.abs(coefs.T), axis=1)
xx /= xx[-1] plt.plot(xx, coefs.T)
ymin, ymax = plt.ylim()
plt.vlines(xx, ymin, ymax, linestyle='dashed')
plt.xlabel('|coef| / max|coef|')
plt.ylabel('Coefficients')
plt.title('LASSO Path')
plt.axis('tight')
plt.show()
运行结果:

三、ElasticNet
适用的情况
ElasticNet 是一种使用L1和L2先验作为正则化矩阵的线性回归模型。
这种组合用于只有很少的权重非零的稀疏模型,比如:class:Lasso,但是又能保持:class:Ridge 的正则化属性。
原理分析
我们可以使用 l1_ratio 参数来调节L1和L2的凸组合(一类特殊的线性组合)。
当多个特征和另一个特征相关的时候弹性网络非常有用。Lasso 倾向于随机选择其中一个,而弹性网络更倾向于选择两个.
在实践中,Lasso 和 Ridge 之间权衡的一个优势是它允许在循环过程(Under rotate)中继承 Ridge 的稳定性.
弹性网络的目标函数是最小化:


代码展示
###############################################################################
# ElasticNet
from sklearn.linear_model import ElasticNet enet = ElasticNet(alpha=alpha, l1_ratio=0.7) y_pred_enet = enet.fit(X_train, y_train).predict(X_test)
r2_score_enet = r2_score(y_test, y_pred_enet)
print(enet)
print("r^2 on test data : %f" % r2_score_enet) plt.plot(enet.coef_, label='Elastic net coefficients')
plt.plot(lasso.coef_, label='Lasso coefficients')
plt.plot(coef, '--', label='original coefficients')
plt.legend(loc='best')
plt.title("Lasso R^2: %f, Elastic Net R^2: %f" % (r2_score_lasso, r2_score_enet))
plt.show()
print("Computing regularization path using the elastic net...")
alphas_enet, coefs_enet, _ = enet_path(
X, y, eps=eps, l1_ratio=0.8, return_models=False, fit_intercept=False)
print("Computing regularization path using the positve elastic net...")
alphas_positive_enet, coefs_positive_enet, _ = enet_path(
X, y, eps=eps, l1_ratio=0.8, positive=True, return_models=False,
fit_intercept=False)
pl.figure(3)
ax = pl.gca()
ax.set_color_cycle(2 * ['b', 'r', 'g', 'c', 'k'])
l1 = pl.plot(-np.log10(alphas_enet), coefs_enet.T)
l2 = pl.plot(-np.log10(alphas_positive_enet), coefs_positive_enet.T, linestyle='--')
pl.xlabel('-Log(alpha)')
pl.ylabel('coefficients')
pl.title('Elastic-Net and positive Elastic-Net')
pl.legend((l1[-1], l2[-1]), ('Elastic-Net', 'positive Elastic-Net'), loc='lower left')
pl.axis('tight')
pl.show()
运行结果:

三种模型的比较


四、Compressive sensing
Ref: 初识压缩感知Compressive Sensing
Ref: 压缩感知进阶——有关稀疏矩阵

如果要想采集很少一部分数据并且指望从这些少量数据中「解压缩」出大量信息,就需要保证:
第一:这些少量的采集到的数据包含了原信号的全局信息,
有趣的是,在某些特定的场合,上述第一件事情是自动得到满足的。最典型的例子就是医学图像成像,例如断层扫描(CT)技术和核磁共振(MRI)技术。对这两种技术稍有了解的人都知道,这两种成像技术中,仪器所采集到的都不是直接的图像像素,而是图像经历过全局傅立叶变换后的数据。也就是说,每一个单独的数据都在某种程度上包含了全图像的信息。在这种情况下,去掉一部分采集到的数据并不会导致一部分图像信息永久的丢失(它们仍旧被包含在其它数据里)。这正是我们想要的情况。
第二:存在一种算法能够从这些少量的数据中还原出原先的信息来。
第二件事就要归功于陶哲轩和坎戴的工作了。他们的工作指出,如果假定信号(无论是图像还是声音还是其他别的种类的信号)满足某种特定的「稀疏性」,那么从这些少量的测量数据中,确实有可能还原出原始的较大的信号来,其中所需要的计算部分是一个复杂的迭代优化过程,即所谓的「L1-最小化」算法。
压缩感知:
其理论依据是:如果只需要10万个分量就可以重建绝大部分的图像,那何必还要做所有的200万次测量,只做10万次不就够了吗?(在实际应用中,我们会留一个安全余量,比如说测量30万像素,以应付可能遭遇的所有问题,从干扰到量化噪声,以及恢复算法的故障。)这样基本上能使节能上一个数量级,这对消费摄影没什么意义,对感知器网络而言却有实实在在的好处。
不过,正像我前面说的,相机自己不会预先知道两百万小波系数中需要记录哪十万个。要是相机选取了另外10万(或者30万),反而把图片中所有有用的信息都扔掉了怎么办?
解决的办法简单但是不太直观。就是用非小波的算法来做30万个测量——尽管我前面确实讲过小波算法是观察和压缩图像的最佳手段。实际上最好的测量其实应该是(伪)随机测量:
比如说随机生成30万个滤镜(mask)图像并测量真实图像与每个mask的相关程度。这样,图像与mask之间的这些测量结果(也就是“相关性”)很有可能是非常小非常随机的。
但是——这是关键所在——构成图像的2百万种可能的小波函数会在这些随机的mask的测量下生成自己特有的“特征”,它们每一个都会与某一些mask成正相关,与另一些mask成负相关,但是与更多的mask不相关。
可是(在极大的概率下)2百万个特征都各不相同;这就导致,其中任意十万个的线性组合仍然是各不相同的(以线性代数的观点来看,这是因为一个30万维线性子空间中任意两个10万维的子空间几乎互不相交)。
因此,理论上是有可能从这30万个随机mask数据中恢复图像的(至少可以恢复图像中的10万个主要细节)。简而言之,我们是在讨论一个哈希函数的线性代数版本。
PS: 这里的原理就是说,如果3维线性子空间中的任意两个2维子空间是线性相关的话,比如:
①3x+2y=8
②6x+4y=16
③4x+5y=10
中,①②就是线性相关的,①③不是线性相关的。将200万个小波函数降维到30万个掩模基的过程就是类似去掉①②中冗余基的过程。
然而这种方式仍然存在两个技术问题。
- 首先是噪声问题:10万个小波系数的叠加并不能完全代表整幅图像,另190万个系数也有少许贡献。这些小小贡献有可能会干扰那10万个小波的特征,这就是所谓的“失真”问题。
- 第二个问题是如何运用得到的30万测量数据来重建图像。
我们先来关注后一个问题(怎样恢复图像)。如果我们知道了2百万小波中哪10万个是有用的,那就可以使用标准的线性代数方法(高斯消除法,最小二乘法等等)来重建信号。(这正是线性编码最大的优点之一——它们比非线性编码更容易求逆。大多数哈希变换实际上是不可能求逆的——这在密码学上是一大优势,在信号恢复中却不是。)可是,就像前面说的那样,我们事前并不知道哪些小波是有用的。怎么找出来呢?
一个单纯的最小二乘近似法会得出牵扯到全部2百万系数的可怕结果,生成的图像也含有大量颗粒噪点。要不然也可以代之以一种强力搜索,为每一组可能的10万关键系数都做一次线性代数处理,不过这样做的耗时非常恐怖(总共要考虑大约10的17万次方个组合!),而且这种强力搜索通常是NP-complete的(其中有些特例是所谓的“子集合加总”问题)。不过还好,还是有两种可行的手段来恢复数据:
• 匹配追踪:
找到一个其标记看上去与收集到的数据相关的小波;
在数据中去除这个标记的所有印迹;
不断重复直到我们能用小波标记“解释”收集到的所有数据。
Matching pursuit: locate a wavelet whose signature seems to correlate with the data collected; remove all traces of that signature from the data; and repeat until we have totally “explained” the data collected in terms of wavelet signatures.
就是先找出一个貌似是基的小波,然后去掉该小波在图像中的分量,迭代直到找出所有10w个小波.
• 基追踪(又名L1模最小化):
在所有与(image)数据匹配的小波组合中,找到一个“最稀疏的”基,也就是其中所有系数的绝对值总和越小越好。(这种最小化的结果趋向于迫使绝大多数系数都消失了。)这种最小化算法可以利用单纯形法之类的凸规划算法,在合理的时间内计算出来。
Basis pursuit (or 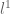
需要注意到的是,这类图像恢复算法还是需要相当的运算能力的(不过也还不是太变态),不过在传感器网络这样的应用中这不成问题,因为图像恢复是在接收端(这端有办法连接到强大的计算机)而不是传感器端(这端就没办法了)进行的。
现在已经有严密的结果显示,对原始图像设定不同的压缩率或稀疏性,这两种算法完美或近似完美地重建图像的成功率都很高。
- 匹配追踪法通常比较快,
- 基追踪算法在考虑到噪声时则显得比较准确。
Compressive sensing: tomography reconstruction with L1 prior (Lasso)
This example shows the reconstruction of an image from a set of parallel projections, acquired along different angles. Such a dataset is acquired in computed tomography (CT).
Without any prior information on the sample, the number of projections required to reconstruct the image is of the order of the linear size l of the image (in pixels). For simplicity we consider here a sparse image, where only pixels on the boundary of objects have a non-zero value. Such data could correspond for example to a cellular material. Note however that most images are sparse in a different basis, such as the Haar wavelets. Only l/7 projections are acquired, therefore it is necessary to use prior information available on the sample (its sparsity): this is an example of compressive sensing.
The tomography projection operation is a linear transformation. In addition to the data-fidelity term corresponding to a linear regression, we penalize the L1 norm of the image to account for its sparsity. The resulting optimization problem is called the Lasso. We use the class sklearn.linear_model.Lasso, that uses the coordinate descent algorithm. Importantly, this implementation is more computationally efficient on a sparse matrix, than the projection operator used here.
The reconstruction with L1 penalization gives a result with zero error (all pixels are successfully labeled with 0 or 1), even if noise was added to the projections. In comparison, an L2 penalization (sklearn.linear_model.Ridge) produces a large number of labeling errors for the pixels. Important artifacts are observed on the reconstructed image, contrary to the L1 penalization. Note in particular the circular artifact separating the pixels in the corners, that have contributed to fewer projections than the central disk.
代码复杂,待日后研究。不过在此之前,有必要先复习下小波。
"""
======================================================================
Compressive sensing: tomography reconstruction with L1 prior (Lasso)
====================================================================== This example shows the reconstruction of an image from a set of parallel
projections, acquired along different angles. Such a dataset is acquired in
**computed tomography** (CT). Without any prior information on the sample, the number of projections
required to reconstruct the image is of the order of the linear size
``l`` of the image (in pixels). For simplicity we consider here a sparse
image, where only pixels on the boundary of objects have a non-zero
value. Such data could correspond for example to a cellular material.
Note however that most images are sparse in a different basis, such as
the Haar wavelets. Only ``l/7`` projections are acquired, therefore it is
necessary to use prior information available on the sample (its
sparsity): this is an example of **compressive sensing**. The tomography projection operation is a linear transformation. In
addition to the data-fidelity term corresponding to a linear regression,
we penalize the L1 norm of the image to account for its sparsity. The
resulting optimization problem is called the :ref:`lasso`. We use the
class :class:`sklearn.linear_model.Lasso`, that uses the coordinate descent
algorithm. Importantly, this implementation is more computationally efficient
on a sparse matrix, than the projection operator used here. The reconstruction with L1 penalization gives a result with zero error
(all pixels are successfully labeled with 0 or 1), even if noise was
added to the projections. In comparison, an L2 penalization
(:class:`sklearn.linear_model.Ridge`) produces a large number of labeling
errors for the pixels. Important artifacts are observed on the
reconstructed image, contrary to the L1 penalization. Note in particular
the circular artifact separating the pixels in the corners, that have
contributed to fewer projections than the central disk.
""" print(__doc__) # Author: Emmanuelle Gouillart <emmanuelle.gouillart@nsup.org>
# License: BSD 3 clause import numpy as np
from scipy import sparse
from scipy import ndimage
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridge
import matplotlib.pyplot as plt def _weights(x, dx=1, orig=0):
x = np.ravel(x)
floor_x = np.floor((x - orig) / dx)
alpha = (x - orig - floor_x * dx) / dx
return np.hstack((floor_x, floor_x + 1)), np.hstack((1 - alpha, alpha)) def _generate_center_coordinates(l_x):
X, Y = np.mgrid[:l_x, :l_x].astype(np.float64)
center = l_x / 2.
X += 0.5 - center
Y += 0.5 - center
return X, Y def build_projection_operator(l_x, n_dir):
""" Compute the tomography design matrix. Parameters
---------- l_x : int
linear size of image array n_dir : int
number of angles at which projections are acquired. Returns
-------
p : sparse matrix of shape (n_dir l_x, l_x**2)
"""
X, Y = _generate_center_coordinates(l_x)
angles = np.linspace(0, np.pi, n_dir, endpoint=False)
data_inds, weights, camera_inds = [], [], []
data_unravel_indices = np.arange(l_x ** 2)
data_unravel_indices = np.hstack((data_unravel_indices,
data_unravel_indices))
for i, angle in enumerate(angles):
Xrot = np.cos(angle) * X - np.sin(angle) * Y
inds, w = _weights(Xrot, dx=1, orig=X.min())
mask = np.logical_and(inds >= 0, inds < l_x)
weights += list(w[mask])
camera_inds += list(inds[mask] + i * l_x)
data_inds += list(data_unravel_indices[mask])
proj_operator = sparse.coo_matrix((weights, (camera_inds, data_inds)))
return proj_operator def generate_synthetic_data():
""" Synthetic binary data """
rs = np.random.RandomState(0)
n_pts = 36.
x, y = np.ogrid[0:l, 0:l]
mask_outer = (x - l / 2) ** 2 + (y - l / 2) ** 2 < (l / 2) ** 2
mask = np.zeros((l, l))
points = l * rs.rand(2, n_pts)
mask[(points[0]).astype(np.int), (points[1]).astype(np.int)] = 1
mask = ndimage.gaussian_filter(mask, sigma=l / n_pts)
res = np.logical_and(mask > mask.mean(), mask_outer)
return res - ndimage.binary_erosion(res) # Generate synthetic images, and projections
l = 128
proj_operator = build_projection_operator(l, l / 7.)
data = generate_synthetic_data()
proj = proj_operator * data.ravel()[:, np.newaxis]
proj += 0.15 * np.random.randn(*proj.shape) # Reconstruction with L2 (Ridge) penalization
rgr_ridge = Ridge(alpha=0.2)
rgr_ridge.fit(proj_operator, proj.ravel())
rec_l2 = rgr_ridge.coef_.reshape(l, l) # Reconstruction with L1 (Lasso) penalization
# the best value of alpha was determined using cross validation
# with LassoCV
rgr_lasso = Lasso(alpha=0.001)
rgr_lasso.fit(proj_operator, proj.ravel())
rec_l1 = rgr_lasso.coef_.reshape(l, l) plt.figure(figsize=(8, 3.3))
plt.subplot(131)
plt.imshow(data, cmap=plt.cm.gray, interpolation='nearest')
plt.axis('off')
plt.title('original image')
plt.subplot(132)
plt.imshow(rec_l2, cmap=plt.cm.gray, interpolation='nearest')
plt.title('L2 penalization')
plt.axis('off')
plt.subplot(133)
plt.imshow(rec_l1, cmap=plt.cm.gray, interpolation='nearest')
plt.title('L1 penalization')
plt.axis('off') plt.subplots_adjust(hspace=0.01, wspace=0.01, top=1, bottom=0, left=0,
right=1) plt.show()
学习中,Real-Time Compressive Tracking:http://www4.comp.polyu.edu.hk/~cslzhang/CT/CT.htm
End.
[Scikit-learn] 1.1 Generalized Linear Models - Lasso Regression的更多相关文章
- [Scikit-learn] 1.1 Generalized Linear Models - Logistic regression & Softmax
二分类:Logistic regression 多分类:Softmax分类函数 对于损失函数,我们求其最小值, 对于似然函数,我们求其最大值. Logistic是loss function,即: 在逻 ...
- [Scikit-learn] 1.1 Generalized Linear Models - from Linear Regression to L1&L2
Introduction 一.Scikit-learning 广义线性模型 From: http://sklearn.lzjqsdd.com/modules/linear_model.html#ord ...
- [Scikit-learn] 1.5 Generalized Linear Models - SGD for Classification
NB: 因为softmax,NN看上去是分类,其实是拟合(回归),拟合最大似然. 多分类参见:[Scikit-learn] 1.1 Generalized Linear Models - Logist ...
- [Scikit-learn] 1.5 Generalized Linear Models - SGD for Regression
梯度下降 一.亲手实现“梯度下降” 以下内容其实就是<手动实现简单的梯度下降>. 神经网络的实践笔记,主要包括: Logistic分类函数 反向传播相关内容 Link: http://pe ...
- 广义线性模型(Generalized Linear Models)
前面的文章已经介绍了一个回归和一个分类的例子.在逻辑回归模型中我们假设: 在分类问题中我们假设: 他们都是广义线性模型中的一个例子,在理解广义线性模型之前需要先理解指数分布族. 指数分布族(The E ...
- Andrew Ng机器学习公开课笔记 -- Generalized Linear Models
网易公开课,第4课 notes,http://cs229.stanford.edu/notes/cs229-notes1.pdf 前面介绍一个线性回归问题,符合高斯分布 一个分类问题,logstic回 ...
- Popular generalized linear models|GLMM| Zero-truncated Models|Zero-Inflated Models|matched case–control studies|多重logistics回归|ordered logistics regression
============================================================== Popular generalized linear models 将不同 ...
- Regression:Generalized Linear Models
作者:桂. 时间:2017-05-22 15:28:43 链接:http://www.cnblogs.com/xingshansi/p/6890048.html 前言 本文主要是线性回归模型,包括: ...
- Generalized Linear Models
作者:桂. 时间:2017-05-22 15:28:43 链接:http://www.cnblogs.com/xingshansi/p/6890048.html 前言 主要记录python工具包:s ...
随机推荐
- Face Alignment by Coarse-to-Fine Shape Searching--解析
人脸关键点定位.Face Alignment by Coarse-to-Fine Shape Searching 算法源码详解(上) http://blog.csdn.net/shenxiaolu19 ...
- 配置Chrome Workspace功能
配置Chrome Workspace功能 Chrome Workspace功能是将在Chrome开发者工具(F12)中对文档的修改直接应用于对应文件中.由于Chrome并不知道当然文档对应用的文件为哪 ...
- android开发(45) 自定义软键盘(输入法)
概述 在项目开发中遇到一个需求,”只要数字键盘的输入,仅仅有大写字母的输入,某些输入法总是会提示更新,弹出广告等“,使得我们需要自定义输入. 关联到的知识 KeyboardView 一个视图 ...
- 两个项目之间通过 RestTemplate 进行调用
A服务发出请求: @RequestMapping("/jqgridjsondata.json") @ResponseBody public String jqgridJsonDat ...
- linux下shellcode提取常用到的命令
汇编语言的汇编指令: nasm -f elf xxx.asm 生成xxx.o文件 ld -o xxx xxx.o 生成可执行文件,不用加参数-s ,否则在提取shellcode的十六进制码的 ...
- 【转】nGrinder 简易使用教程
https://www.cnblogs.com/jwentest/p/7136727.html 背景 性能压测工具之前使用的是jmeter,这次说的是nGrinder,先直接搬运两者之间的比较 比较点 ...
- [kafka] 004_kafka_安装运行
1.下载和安装 目前kafka的稳定版本为0.10.0.0 下载地址:http://kafka.apache.org/downloads.html 下载后解压缩安装包到系统即可完成安装 > ta ...
- Python 匿名参数
#-*- coding:utf-8 -*- #匿名函数 #匿名函数语法格式 ''' 变量 = lambda 参数列表:表达式 ''' func = lambda x,y:x+y a = func(2, ...
- 自然语言交流系统 phxnet团队 创新实训 项目博客 (七)
在本项目中使用到的“语音转文本”的技术总结: 语音转文本部分是调用的科大讯飞的在线语音,它的激发方式是按键,通过按钮触发开启安卓设备的录音,此部分需要在源码中写入关于安卓权限的要求,来调用安卓的录音权 ...
- 关于Unity中物理检测的准备
1.要确定每个物体的碰撞类型,是有碰撞效果的碰撞还是没有碰撞效果的碰撞(is trigger),带不带刚体. 2.给每个物体分层,再设置哪些层会发生碰撞,哪些完全不产生碰撞. 3.给每个物体设置标记, ...