RabbitMQ-1 Helloword
参考:http://rabbitmq.mr-ping.com/
介绍
RabbitMQ是一个消息代理。它的工作就是接收和转发消息。你可以把它想像成一个邮局:你把信件放入邮箱,邮递员就会把信件投递到你的收件人处。在这个比喻中,RabbitMQ就扮演着邮箱、邮局以及邮递员的角色。
RabbitMQ和邮局的主要区别在于,它处理纸张,而是接收、存储和发送消息(message)这种二进制数据。
下面是RabbitMQ和消息所涉及到的一些术语。
- 生产(Producing)的意思就是发送。发送消息的程序就是一个生产者(producer)。我们一般用"P"来表示:
- 队列(queue)就是存在于RabbitMQ中邮箱的名称。虽然消息的传输经过了RabbitMQ和你的应用程序,但是它只能被存储于队列当中。实质上队列就是个巨大的消息缓冲区,它的大小只受主机内存和硬盘限制。多个生产者(producers)可以把消息发送给同一个队列,同样,多个消费者(consumers)也能够从同一个队列(queue)中获取数据。队列可以绘制成这样(图上是队列的名称):

- 在这里,消费(Consuming)和接收(receiving)是同一个意思。一个消费者(consumer)就是一个等待获取消息的程序。我们把它绘制为"C":

需要指出的是生产者、消费者、代理需不要待在同一个设备上;事实上大多数应用也确实不在会将他们放在一台机器上。
Hello World!
(使用pika 0.10.0 Python客户端)
接下来我们用Python写两个小程序。一个发送单条消息的生产者(producer)和一个接收消息并将其输出的消费者(consumer)。传递的消息是"Hello World"。
下图中,"P"代表生产者,"C"代表消费者,中间的盒子代表为消费者保留的消息缓冲区,也就是我们的队列。
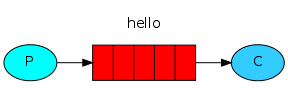
生产者(producer)把消息发送到一个名为"hello"的队列中。消费者(consumer)从这个队列中获取消息。
RabbitMQ库
RabbitMQ使用的是AMQP 0.9.1协议。这是一个用于消息传递的开放、通用的协议。针对不同编程语言有大量的RabbitMQ客户端可用。在这个系列教程中,RabbitMQ团队推荐使用Pika这个Python客户端。大家可以通过pip这个包管理工具进行安装:
我们第一个程序send.py会发送一个消息到队列中。首先要做的事情就是建立一个到RabbitMQ服务器的连接。
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
现在我们已经跟本地机器的代理建立了连接。如果你想连接到其他机器的代理上,需要把代表本地的localhost改为指定的名字或IP地址。
接下来,在发送消息之前,我们需要确认服务于消费者的队列已经存在。如果将消息发送给一个不存在的队列,RabbitMQ会将消息丢弃掉。下面我们创建一个名为"hello"的队列用来将消息投递进去。
channel.queue_declare(queue='hello')
这时候我们就可以发送消息了,我们第一条消息只包含了Hello World!字符串,我们打算把它发送到hello队列。
在RabbitMQ中,消息是不能直接发送到队列中的,这个过程需要通过交换机(exchange)来进行。但是为了不让细节拖累我们的进度,这里我们只需要知道如何使用由空字符串表示的默认交换机即可。如果你想要详细了解交换机,可以查看我们教程的第三部分来获取更多细节。默认交换机比较特别,它允许我们指定消息究竟需要投递到哪个具体的队列中,队列名字需要在routing_key参数中指定。
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print(" [x] Sent 'Hello World!'")
在退出程序之前,我们需要确认网络缓冲已经被刷写、消息已经投递到RabbitMQ。通过安全关闭连接可以做到这一点。
connection.close()
发送不成功!
如果这是你第一次使用RabbitMQ,并且没有看到"Sent"消息出现在屏幕上,你可能会抓耳挠腮不知所以。这也许是因为没有足够的磁盘空间给代理使用所造成的(代理默认需要200MB的空闲空间),所以它才会拒绝接收消息。查看一下代理的日志文件进行确认,如果需要的话也可以减少限制。配置文件文档会告诉你如何更改磁盘空间限制(disk_free_limit)。
接收
我们的第二个程序receive.py,将会从队列中获取消息并将其打印到屏幕上。
这次我们还是需要要先连接到RabbitMQ服务器。连接服务器的代码和之前是一样的。
下一步也和之前一样,我们需要确认队列是存在的。我们可以多次使用queue_declare命令来创建同一个队列,但是只有一个队列会被真正的创建。
channel.queue_declare(queue='hello')
你也许要问: 为什么要重复声明队列呢 —— 我们已经在前面的代码中声明过它了。如果我们确定了队列是已经存在的,那么我们可以不这么做,比如此前预先运行了send.py程序。可是我们并不确定哪个程序会首先运行。这种情况下,在程序中重复将队列重复声明一下是种值得推荐的做法。
列出所有队列
你也许希望查看RabbitMQ中有哪些队列、有多少消息在队列中。此时你可以使用rabbitmqctl工具(使用有权限的用户):
sudo rabbitmqctl list_queues
(在Windows中不需要sudo命令)
rabbitmqctl list_queues
从队列中获取消息相对来说稍显复杂。需要为队列定义一个回调(callback)函数。当我们获取到消息的时候,Pika库就会调用此回调函数。这个回调函数会将接收到的消息内容输出到屏幕上。
def
callback(ch, method, properties, body):print(" [x] Received %r" % body)
下一步,我们需要告诉RabbitMQ这个回调函数将会从名为"hello"的队列中接收消息:
channel.basic_consume(callback,
queue='hello',
no_ack=True)
要成功运行这些命令,我们必须保证队列是存在的,我们的确可以确保它的存在——因为我们之前已经使用queue_declare将其声明过了。
no_ack参数稍后会进行介绍。
最后,我们运行一个用来等待消息数据并且在需要的时候运行回调函数的无限循环。
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
将代码整合到一起
send.py的完整代码:
#!/usr/bin/env python
import pika
connection =
pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print(" [x] Sent 'Hello World!'")
connection.close()
(send.py源码)
receive.py的完整代码:
#!/usr/bin/env python
import pika
connection =
pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
def
callback(ch, method, properties, body):print(" [x] Received %r" % body)
channel.basic_consume(callback,
queue='hello',
no_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
(receive.py源码)
现在我们可以在终端中尝试一下我们的程序了。
首先我们启动一个消费者,它会持续的运行来等待投递到达。python receive.py
# => [*] Waiting for messages. To exit press CTRL+C
# => [x] Received 'Hello World!'
然后启动生产者,生产者程序每次执行后都会停止运行。
python send.py
# => [x] Sent 'Hello World!'
成功了!我们已经通过RabbitMQ发送第一条消息。你也许已经注意到了,receive.py程序并没有退出。它一直在准备获取消息,你可以通过Ctrl-C来中止它。
试下在新的终端中再次运行send.py。
我们已经学会如何发送消息到一个已知队列中并接收消息。是时候移步到第二部分了,我们将会建立一个简单的工作队列(work queue)。
RabbitMQ-1 Helloword的更多相关文章
- (转) RabbitMQ学习之helloword(java)
http://blog.csdn.net/zhu_tianwei/article/details/40835555 amqp-client:http://www.rabbitmq.com/java-c ...
- rabbitmq学习(二) —— helloword!
rabbitmq学习当然是跟着官网走最好了,官网的教程写的很好,跟着官网教程走一遍就会有个初步了解了 下面的教程转自http://cmsblogs.com/?p=2768,该博客对官网的翻译还不错 介 ...
- RabbitMQ学习之集群部署
我们先搭建一个普通集群模式,在这个模式基础上再配置镜像模式实现高可用,Rabbit集群前增加一个反向代理,生产者.消费者通过反向代理访问RabbitMQ集群. 架构图如下: 设计架构可以如下:在一个集 ...
- RabbitMq 技术文档
RabbitMq 技术文档 目录 1 AMQP简介 2 AMQP的实现 3 RabbitMQ简介 3.1 概念说明 3.2 消息队列的使用过程 3.3 RabbitMQ的特性 4 RabbitMQ使用 ...
- Python一路走来 RabbitMQ
一:介绍:(induction) Rabbitmq 是一个消息中间件.他的思想就是:接收和发送消息.你可以把它想成一个邮政局.当你把你的邮件发送到邮箱的,首先你需要确认的是:邮政员先生能把你的邮件发送 ...
- 柯南君:看大数据时代下的IT架构(4)消息队列之RabbitMQ--案例(Helloword起航)
柯南君:看大数据时代下的IT架构(4)消息队列之RabbitMQ--案例(Helloword起航) 二.起航 本章节,柯南君将从几个层面,用官网例子讲解一下RabbitMQ的实操经典程序案例,让大家重 ...
- RabbitMQ消息队列(一)-RabbitMQ的优劣势及产生背景
本篇并没有直接讲到技术,例如没有先写个Helloword.我想在选择了解或者学习一门技术之前先要明白为什么要现在这个技术而不是其他的,以免到最后发现自己学错了.同时如果已经确定就是他,最好先要了解下技 ...
- RabbitMQ消息队列(二)-RabbitMQ消息队列架构与基本概念
没错我还是没有讲怎么安装和写一个HelloWord,不过快了,这一章我们先了解下RabbitMQ的基本概念. RabbitMQ架构 说是架构其实更像是应用场景下的架构(自己画的有点丑,勿嫌弃) 从图中 ...
- rabbitmq 入门基础(一)
第一章:Rabbitmq简单介绍 简单介绍: Rabbitmq是一个消息中间件.主要用于消息的转发和接收.假设把rabbitmq比作邮局:仅仅要你将信件投递到邮箱,你就能够确信邮递员将能够把你的信件递 ...
- (转)RabbitMQ学习之集群部署
http://blog.csdn.net/zhu_tianwei/article/details/40931971 我们先搭建一个普通集群模式,在这个模式基础上再配置镜像模式实现高可用,Rabbit集 ...
随机推荐
- kettle 发邮件带附件
新建一个job,主要用到的组件有两个,如下图: 首先点击下图的文件,选择你要做为邮件附件的文件.选完后会在前辈的文件.目录中显示.然后点击增加,会下面文件列表中显示已经添加的文件(涂黄色的部分) 按下 ...
- gitignore中常见需要被无视的文件
gitignore中常见的需要被忽略的文件:例如各个系统.一些软件会自动生成的文件,主要适用于web项目. 复制后,保存进.gitignore文件中即可. # Project node_modules ...
- JQ插件写法 扩展JQ方法
目录: 1.基本JQ扩展插件js的格式 2.对JQ选中元素的方法的扩展,调用类似于$("selector").myMethod(),这里的myMethod是自己扩展的方法,与.cl ...
- 单项目实现vendor分离编译,增加编译效率(vue-cli)
1.在build文件夹下添加文件:webpack.dll.config.js const path = require('path') const webpack = require('webpack ...
- NBUT 1224 Happiness Hotel 2010辽宁省赛
Time limit 1000 ms Memory limit 131072 kB The life of Little A is good, and, he managed to get enoug ...
- 转:AMD规范与CMD规范的区别是什么?
AMD规范与CMD规范的区别是什么? 在比较之前,我们得先来了解下什么是AMD规范?什么是CMD规范?当然先申明一下,我个人也是总结下而已,也是网上看到的资料,自己总结下或者可以说整理下而已,供 ...
- SecureCRT来上传和下载文件
引用:https://www.cnblogs.com/zhengyihan1216/p/6260667.html Linux--用SecureCRT来上传和下载文件 SecureCRT下的文件传输协议 ...
- HOG+SVM+INRIAPerson数据集代码
#include <iostream> #include <opencv2/core/core.hpp> #include <opencv2/highgui/highgu ...
- OK335xS-Android mkmmc-android-ubifs.sh hacking
#/******************************************************************************* # * OK335xS-Androi ...
- LDA模型应用实践-希拉里邮件主题分类
#coding=utf8 import numpy as np import pandas as pd import re from gensim import corpora, models, si ...