sklearn的GridSearchCV例子
class sklearn.model_selection.GridSearchCV(estimator, param_grid, scoring=None, fit_params=None, n_jobs=1, iid=True, refit=True, cv=None, verbose=0, pre_dispatch='2*n_jobs', error_score='raise', return_train_score=True)
1.estimator:
传入估计器与不需要调参的参数,每一个估计器都需要一个scoring参数。
2.param_grid:
需要最优化的参数的取值,值为字典或者列表。
3.scoring:
模型评价标准,默认None,这时需要使用score函数,根据所选模型不同,评价准则不同。字符串或者自定义形如:scorer(estimator, X, y);如果是None,则使用estimator的误差估计函数。
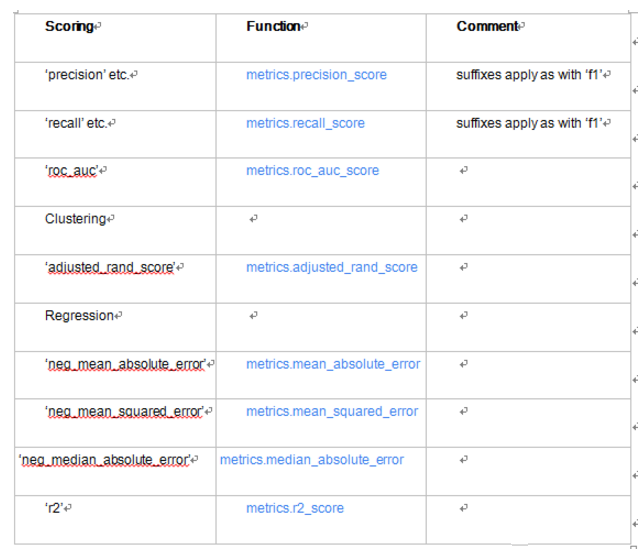
4.n_jobs
n_jobs: 并行数,int:个数,-1:跟CPU核数一致。
5.refit=True
默认为True,程序将会以交叉验证训练集得到的最佳参数,重新对所有可用的训练集与开发集进行,作为最终用于性能评估的最佳模型参数。即在搜索参数结束后,用最佳参数结果再次fit一遍全部数据集。
6.pre_dispatch=‘2*n_jobs’
指定总共分发的并行任务数。当n_jobs大于1时,数据将在每个运行点进行复制,这可能导致OOM,而设置pre_dispatch参数,则可以预先划分总共的job数量,使数据最多被复制pre_dispatch次。
from sklearn.datasets import load_iris
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report X,y = load_iris(return_X_y=True)
df_X = pd.DataFrame(X,columns=list("ABCD")) #gridSearchCV
parameters = [{'n_estimators':[10,100,1000],
'criterion':['entropy','gini'],
'max_depth':[10,50,100,200],
'min_samples_split':[2,5,10],
'min_weight_fraction_leaf':[0.0,0.1,0.2,0.3,0.4,0.5]}] parameters = [{'n_estimators':[10,20]}] #scoring="precision"或者"recall"或者"roc_auc","accuracy"或者None clf = GridSearchCV(RandomForestClassifier(), parameters,cv=2,scoring="accuracy")
clf.fit(df_X,y) clf.cv_results_
# =============================================================================
# {'mean_fit_time': array([0.0089916 , 0.01695275]),
# 'mean_score_time': array([0.00099409, 0.00148273]),
# 'mean_test_score': array([0.94666667, 0.96 ]),
# 'mean_train_score': array([0.98666667, 1. ]),
# 'param_n_estimators': masked_array(data=[10, 20],
# mask=[False, False],
# fill_value='?',
# dtype=object),
# 'params': [{'n_estimators': 10}, {'n_estimators': 20}],
# 'rank_test_score': array([2, 1]),
# 'split0_test_score': array([0.96, 0.96]),
# 'split0_train_score': array([1., 1.]),
# 'split1_test_score': array([0.93333333, 0.96 ]),
# 'split1_train_score': array([0.97333333, 1. ]),
# 'std_fit_time': array([1.01363659e-03, 9.53674316e-07]),
# 'std_score_time': array([4.17232513e-06, 5.05685806e-04]),
# 'std_test_score': array([0.01333333, 0. ]),
# 'std_train_score': array([0.01333333, 0. ])}
# =============================================================================
clf.best_estimator_
# =============================================================================
# RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
# max_depth=None, max_features='auto', max_leaf_nodes=None,
# min_impurity_decrease=0.0, min_impurity_split=None,
# min_samples_leaf=1, min_samples_split=2,
# min_weight_fraction_leaf=0.0, n_estimators=20, n_jobs=1,
# oob_score=False, random_state=None, verbose=0,
# warm_start=False)
# ============================================================================= clf.best_score_
# =============================================================================
# Out[42]: 0.96
#
# ============================================================================= clf.best_params_ # =============================================================================
# Out[43]: {'n_estimators': 20}
#
# =============================================================================
clf.grid_scores_ # =============================================================================
# [mean: 0.94667, std: 0.01333, params: {'n_estimators': 10},
# mean: 0.96000, std: 0.00000, params: {'n_estimators': 20}]
# =============================================================================
参考:http://blog.51cto.com/emily18/2088128
sklearn的GridSearchCV例子的更多相关文章
- sklearn参数优化方法
学习器模型中一般有两个参数:一类参数可以从数据中学习估计得到,还有一类参数无法从数据中估计,只能靠人的经验进行指定,后一类参数就叫超参数 比如,支持向量机里的C,Kernel,gama,朴素贝叶斯里的 ...
- 《转》sklearn参数优化方法
sklearn参数优化方法 http://www.cnblogs.com/nolonely/p/7007961.html 学习器模型中一般有两个参数:一类参数可以从数据中学习估计得到,还有一类参 ...
- GridSearchCV 与 RandomizedSearchCV 调参
GridSearchCV GridSearchCV的名字其实可以拆分为两部分,GridSearch和CV,即网格搜索和交叉验证. 这两个概念都比较好理解,网格搜索,搜索的是参数,即在指定的参数范 ...
- sklearn参数优化
学习器模型中一般有两个参数:一类参数可以从数据中学习估计得到,还有一类参数无法从数据中估计,只能靠人的经验进行指定,后一类参数就叫超参数 比如,支持向量机里的C,Kernel,gama,朴素贝叶斯里的 ...
- 机器学习之sklearn——SVM
sklearn包对于SVM可输出支持向量,以及其系数和数目: print '支持向量的数目: ', clf.n_support_ print '支持向量的系数: ', clf.dual_coef_ p ...
- 使用sklearn优雅地进行数据挖掘【转】
目录 1 使用sklearn进行数据挖掘 1.1 数据挖掘的步骤 1.2 数据初貌 1.3 关键技术2 并行处理 2.1 整体并行处理 2.2 部分并行处理3 流水线处理4 自动化调参5 持久化6 回 ...
- 使用sklearn优雅地进行数据挖掘
目录 1 使用sklearn进行数据挖掘 1.1 数据挖掘的步骤 1.2 数据初貌 1.3 关键技术2 并行处理 2.1 整体并行处理 2.2 部分并行处理3 流水线处理4 自动化调参5 持久化6 回 ...
- 【转】使用sklearn优雅地进行数据挖掘
这里是原文 目录 使用sklearn进行数据挖掘 1.1 数据挖掘的步骤 1.2 数据初貌 1.3 关键技术并行处理 并行处理 2.1 整体并行处理 2.2 部分并行处理流水线处理自动化调参持久化回顾 ...
- 转载:使用sklearn进行数据挖掘
目录 1 使用sklearn进行数据挖掘 1.1 数据挖掘的步骤 1.2 数据初貌 1.3 关键技术2 并行处理 2.1 整体并行处理 2.2 部分并行处理3 流水线处理4 自动化调参5 持久化6 回 ...
随机推荐
- Ubuntu:系统启动服务
系统启动服务 针对Ubuntu 5级别服务的说明 安装sysv-rc-conf sudo apt-get install sysv-rc-conf acpi-support 高级电源管理支持 acpi ...
- iOS-----使用AFNetworking实现网络通信
使用AFNetworking实现网络通信 AFNetworking可以用于发送HTTP请求,接收HTTP响应,但不会缓存服务器响应,不能执行HTML页面中嵌入的JavaScript代码, 也不会对页面 ...
- bisect
# 二分查找算法 import bisect farm = sorted(['haystack', 'needle', 'cow', 'pig']) # ['cow', 'haystack', 'ne ...
- pymysql模块操作数据库
pymysql模块是python操作数据库的一个模块 connect()创建数据库链接,参数是连接数据库需要的连接参数 使用方式: 模块名称.connect() 参数: host=数据库ip po ...
- C# 处理DateTime算法,取某月第1天及最后一天
代码如下所示: /// <summary> /// 取得某月的第一天 /// </summary> /// <param name="datetime" ...
- LG2023 [AHOI2009]维护序列
题意 老师交给小可可一个维护数列的任务,现在小可可希望你来帮他完成. 有长为N的数列,不妨设为a1,a2,-,aN .有如下三种操作形式: (1)把数列中的一段数全部乘一个值; (2)把数列中的一段数 ...
- git server side hook 试用
git 的hook 是一个很方便的功能,我们可以使用hook 做好多处理,比如client side hook 进行 提交格式校验,server side 进行ci/cd 处理 测试使用docker- ...
- socat 广播以及多播
官方文档有一个关于组播,多播的例子挺不错,记录下 多播客户端以及服务器 注意地址修改为自己的网络 server socat UDP4-RECVFROM:6666,ip-add-membership=2 ...
- SQL Server中如何实现遍历表的记录
SQL Server遍历表一般都要用到游标,SQL Server中可以很容易的用游标实现循环,实现SQL Server遍历表中记录. 但游标在实际的开发中都不推荐使用. 我们知道还可以借助临时表或表变 ...
- 命令行net time同步时间(内网)
首先还是推荐大家使用Internet时间来同步自己计算机的时间,这样做主要是方便,就是设置一个ntp服务器,我推荐下面的三个ntp服务器地址. time.asia.apple.com //亲测有效 a ...