3.1、Factorization Machine模型
Factorization Machine模型
在Logistics Regression算法的模型中使用的是特征的线性组合,最终得到的分隔超平面属于线性模型,其只能处理线性可分的二分类问题,现实生活中的分类问题是多中多样的,存在大量的非线性可分的分类问题。
为了使得Logistics Regression算法能够处理更多的复杂问题,对Logistics Regression算法精心优化主要有两种,(1)对特征进行处理,如核函数的方法,将非线性可分问题转换为近似线性可分的问题(2)对Logistics Regression算法进行扩展,因子分解机(Factorization Machine,FM)是对基本Logistics Regression算法的扩展,是由Steffen Rendle提出的一种基于矩阵分解的机器学习算法。
1、Logistics Regression算法的不足:
由于Logistics Regression算法简单,易于实现的特点,在工业界中得到广泛的使用,但是基本的Logistics Regression算法只能处理线性可分的二分类问题,对于下图的非线性可分的二分类问题,基本的Logistics Regression算法却不能够很好的进行分类。
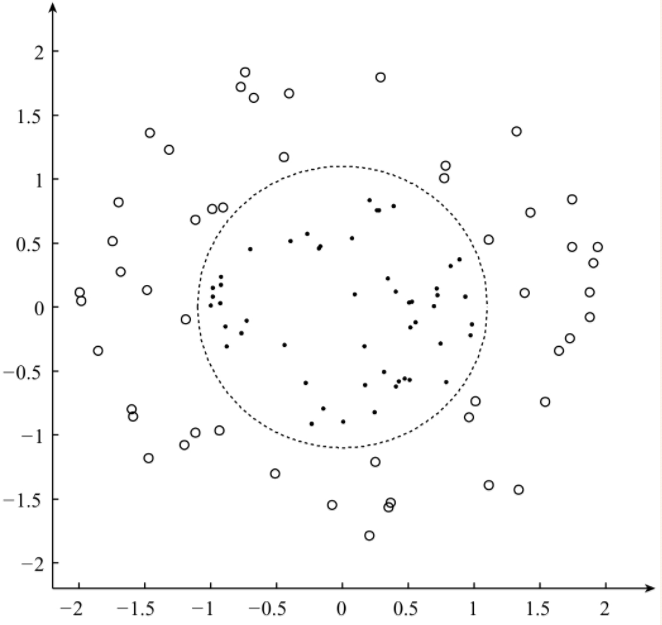
基本的Logistics Regression算法不能很好的将上述的数据分开,为了能够利用Logistics Regression算法处理非线性可分的数据,通常有两种方法,(1)利用人工对特征进行处理,使用核函数对特征进行处理,对于上图所示对的数据,利用函数f(x)=x2进行特征处理处理后的数据如下图,(2)对于基本的Logistic Regression算法进行扩展,以适应更难分类问题。
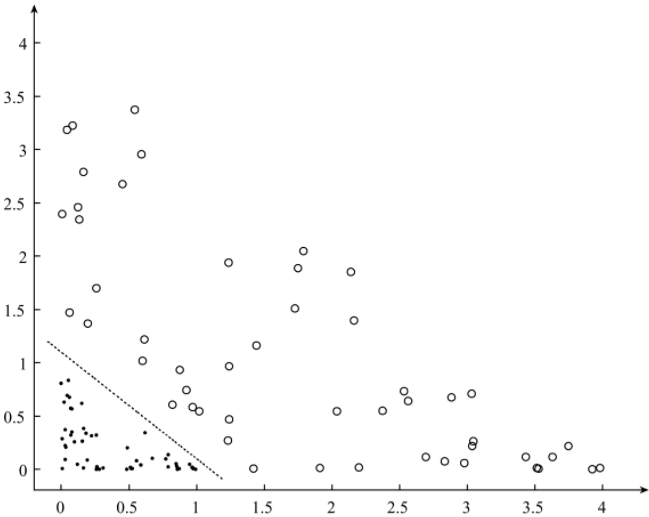
因子分解机(Factorization Machine,FM)算法是对Logistics Regression算法的扩展,在因子分解机FM模型中,不仅包含了Logistics Regression模型中的线性项,还包含了非线性的交叉项,利用矩阵分解的方法对,模型中的交叉项的系数学习,得到每一项的系数,而无需人工参与。
理解:在线性模型中,我们假设的是所有的特征之间是没有相互影响的。所有我们可以用线性模型f(x)=x*w+b但是在实际问题中,可能会出现两个特征或者多个特征的相互影响,所以这里就引入因子分解机模型,这里有一个度的问题,这里的度就是指有多少个特征之间影响,如果是两个特征之间相互影响这里的度就是2,如果是三次特征之间相互影响,这里的度就是3.但是我们一般处理的都是度为2 的问题。
1、因子分解模型
FM是一般线性模型的推广,一般的线性模型可以表示为(式0):
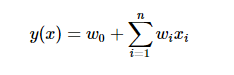
但是上述模型没有考虑特征间的关联,为表示关联特征对y的影响,引入多项式模型,以xiyi表示两特征的组合,有如下二阶多项式模型(式1):
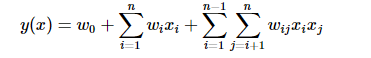
对于因子分解机模型FM模型,引入度的概念。对于度为2的因子分解机FM的模型为:
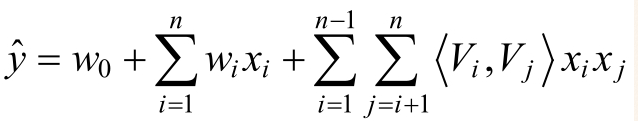
其中,参数w0∈R,W∈Rn,V∈Rn×k。<Vi,Vj>表示的是两个大小为k的向量Vi和Vj的点积。
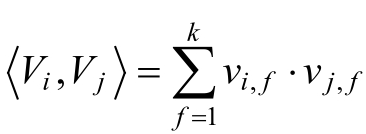
其中,Vi表示的是系数矩阵V的第i维为向量,且Vi = (vi,1,vi,2,.......vi,k),K∈N+称为超参数,且k的大小称为因子分解机FM算法的度。在因子分解机机FM模型中,前面两部分是传统的线性模型,最后一部分将两个互异特征分量之间的相互关系考虑进来。
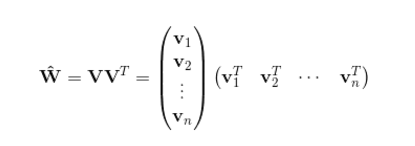
2、因子分解机可以处理的问题
- 回归问题
- 二分类问题
- 排序问题
对于处理回归问题,其最终的形式为:
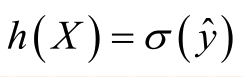
其中,∂阀值函数,通常取为Sigmoid函数:
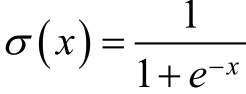
3、二分类因子分解机FM算法的损失函数:
使用logit loss作为优化标准,即:
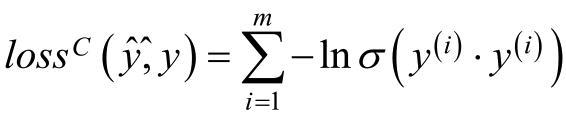
FM算法中交叉项的处理
1.交叉项系数:
在基本线性回归模型的基础上引入交叉项,如下:
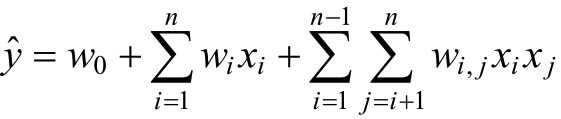
这种直接在交叉项xixj的前面加上交叉项系数wi,j的方式,在稀疏数据的情况下存在一个很大的缺陷,即在对于观察样本中为未出现交互特征分量时,不能对相应的参数进行估计。对每一个特征分量xi引入辅助向量Vi = (vi,1,vi,2,.......vi,k),利用ViVjT对交叉项的系数wi,j进行估计即:
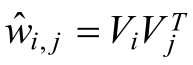
令:
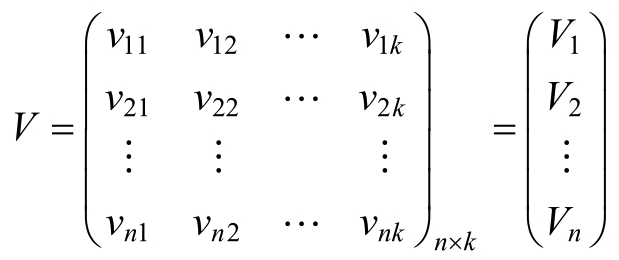
则:
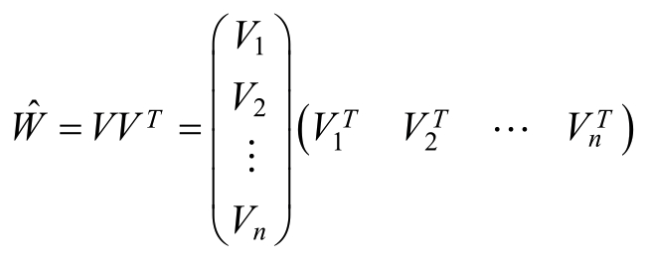
这就对应于了一种矩阵的分解,对k值得限定、FM的表达能力均有一定的影响。
模型的求解:
对于交叉项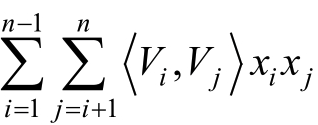 的求解,可以采用公式:
的求解,可以采用公式:
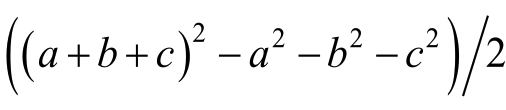
其具体过程如下:
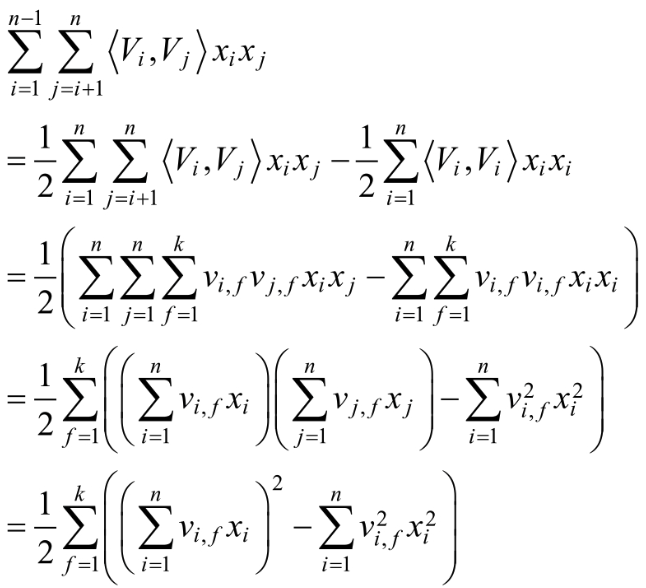
3、FM算法求解:
对于FM算法的求解,主要利用了梯度下降法。
3.1、随机梯度下降(SGD)
随机梯度下降在每次迭代的过程中,仅根据一个样本对模型中的参数进行调整。
随机梯度下降法的优化过程为:
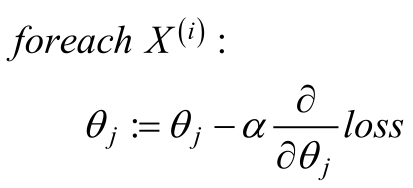
假设数据集中有m个训练样本,即{X(1),X(2),........X(i)},每个样本X(i)有n个特征即
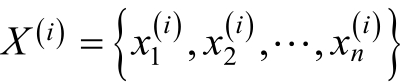
对于度为2 的因子分解机FM模型,其主要的参数有一次项和常数项的参数w0,w1,....wn以及交叉项的系数矩阵V。在利随机梯度对模型的参数进行学习的过程中,主要是对损失函数求导,即:
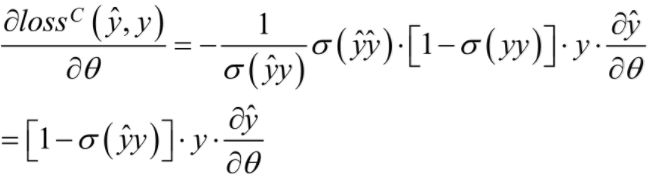
而: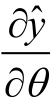 为:
为:
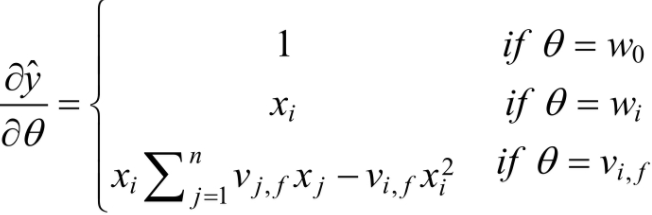
3.2、FM算法流程:
利用随机梯度下降算法对因子分解机FM模型中的参数进行学习的基本步骤如下:
1.初始化权重w0,w1,....wn和V
2.对每一个样本:
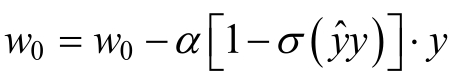
对特征i∈{1,.....n}:
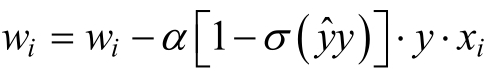
3.重复步骤2,直到满足终止条件
4、用Python实现
利用随机梯度下降训练FM模型
def stocGradAscent(dataMatrix, classLabels, k, max_iter, alpha):
'''利用随机梯度下降法训练FM模型
input: dataMatrix(mat)特征
classLabels(mat)标签
k(int)v的维数
max_iter(int)最大迭代次数
alpha(float)学习率
output: w0(float),w(mat),v(mat):权重
'''
m, n = np.shape(dataMatrix)
# 1、初始化参数
w = np.zeros((n, 1)) # 其中n是特征的个数
w0 = 0 # 偏置项
v = initialize_v(n, k) # 初始化V # 2、训练
for it in range(max_iter):
for x in range(m): # 随机优化,对每一个样本而言的
inter_1 = dataMatrix[x] * v
inter_2 = np.multiply(dataMatrix[x], dataMatrix[x]) * \
np.multiply(v, v) # multiply对应元素相乘
# 完成交叉项
interaction = np.sum(np.multiply(inter_1, inter_1) - inter_2) / 2.
p = w0 + dataMatrix[x] * w + interaction # 计算预测的输出
loss = sigmoid(classLabels[x] * p[0, 0]) - 1 w0 = w0 - alpha * loss * classLabels[x]
for i in range(n):
if dataMatrix[x, i] != 0:
w[i, 0] = w[i, 0] - alpha * loss * classLabels[x] * dataMatrix[x, i] for j in range(k):
v[i, j] = v[i, j] - alpha * loss * classLabels[x] * \
(dataMatrix[x, i] * inter_1[0, j] -\
v[i, j] * dataMatrix[x, i] * dataMatrix[x, i]) # 计算损失函数的值
if it % 1000 == 0:
print ("\t------- iter: ", it, " , cost: ", \
getCost(getPrediction(np.mat(dataMatrix), w0, w, v), classLabels)) # 3、返回最终的FM模型的参数
return w0, w, v
初始化交叉的权重:
def initialize_v(n, k):
'''初始化交叉项
input: n(int)特征的个数
k(int)FM模型的超参数
output: v(mat):交叉项的系数权重
'''
v = np.mat(np.zeros((n, k))) for i in range(n):
for j in range(k):
# 利用正态分布生成每一个权重
v[i, j] = normalvariate(0, 0.2)
return v
为了能够使用正态分布对权重进行初始化,我们需要导入normalvariate函数
from random import normalvariate
Sigmoid函数
def sigmoid(inx):
return 1.0/(1+np.exp(-inx))
计算当前的损失函数的值:
def getCost(predict, classLabels):
'''计算预测准确性
input: predict(list)预测值
classLabels(list)标签
output: error(float)计算损失函数的值
'''
m = len(predict)
error = 0.0
for i in range(m):
error -= np.log(sigmoid(predict[i] * classLabels[i] ))
return error
3.1、Factorization Machine模型的更多相关文章
- Factorization Machine
Factorization Machine Model 如果仅考虑两个样本间的交互, 则factorization machine的公式为: $\hat{y}(\mathbf{x}):=w_0 + \ ...
- Factorization Machine算法
参考: http://stackbox.cn/2018-12-factorization-machine/ https://baijiahao.baidu.com/s?id=1641085157432 ...
- Factorization Machine因子分解机
隐因子分解机Factorization Machine[http://www. w2bc. com/article/113916] https://my.oschina.net/keyven/blog ...
- FM(Factorization Machines)模型详解
优点 FM模型可以在非常稀疏的数据中进行合理的参数估计,而SVM做不到这点 在FM模型的复杂度是线性的,优化效果很好,而且不需要像SVM一样依赖于支持向量. FM是一个通用模型,它可以用于任何特征为实 ...
- 3.2、Factorization Machine实践
1.在上一篇博客中我们构建度为二的因子分解机模型,这篇博客对这个模型进行实践 下图为准备的数据集: 完整代码为: # -*- coding: UTF-8 -*- # date:2018/6/6 # U ...
- AI Factorization Machine(FM)算法
FM算法 参考链接: https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf
- AFM论文精读
深度学习在推荐系统的应用(二)中AFM的简单回顾 AFM模型(Attentional Factorization Machine) 模型原始论文 Attentional Factorization M ...
- FM与FFM深入解析
因子机的定义 机器学习中的建模问题可以归纳为从数据中学习一个函数,它将实值的特征向量映射到一个特定的集合中.例如,对于回归问题,集合 T 就是实数集 R,对于二分类问题,这个集合可以是{+1,-1}. ...
- 主流CTR预估模型的演化及对比
https://zhuanlan.zhihu.com/p/35465875 学习和预测用户的反馈对于个性化推荐.信息检索和在线广告等领域都有着极其重要的作用.在这些领域,用户的反馈行为包括点击.收藏. ...
随机推荐
- uboot启动完成,kernel启动时lcd屏…
先说说开发环境吧: 1 内核:linux2.6.xx 2 uboot:买开发板带的 注释:在最后我又添加了问题得到完美解决的办法. 问题:uboot启动完成,kernel启动时lcd屏幕出现杂色(比如 ...
- C++ 输出精度和输出小数点位数
有时候需要调节小数点的精度或者位数 #include<iostream> #include<iomanip> using namespace std; //设置数据精度 set ...
- Solidity oraclize 常用数据源
1. 股票数据: https://blog.quandl.com/api-for-stock-data iextrading.com www.nowapi.com 中文 2. 外汇数据: https: ...
- Smarty3——从配置文件获取的变量
再使用配置变量前要 引入配置变量即:{$config_load file=‘file_path’}$marty3中可以从配置文件中 用 # 号包起来引用配置文件中的变量({#config_var_na ...
- vis用于做3D图表的js插件
vis.js用于做3D图表:(浏览网站需要FQ)实例:http://visjs.org/graph3d_examples.html代码下载:https://github.com/almende/vis
- ios7 设置status bar风格
How to change status bar style during launch on iOS 7 up vote4down votefavorite When I launch my a ...
- (转)那天有个小孩教我WCF[一][1/3]
原文地址:http://www.cnblogs.com/AaronYang/p/2950931.html 既然是小孩系列,当然要有一点基础才能快速掌握,归纳,总结的一个系列,哈哈 前言: 第一篇嘛,不 ...
- 编写高质量代码改善C#程序的157个建议——建议46:显式释放资源需继承接口IDisposable
建议46:显式释放资源需继承接口IDisposable C#中的每一个类型都代表一种资源,资源分为两类: 托管资源:由CLR管理分配和释放的资源,即从CLR里new出来的对象. 非托管资源:不受CLR ...
- 代理(Proxy)模式
代理模式(Proxy):为其他对象提供一种代理以控制对这个对象的反问. * 抽象主题角色(Subject):声明了真实主题和代理主题的共同接口,这样一来在任何使用真实主题的地方都可以使用代理主题. * ...
- 20145218张晓涵 PC平台逆向破解_advanced
---恢复内容开始--- 20145218张晓涵 PC平台逆向破解_advanced shellcode注入 基础知识 shellcode就是在利用溢出攻击溢出时要值入的代码,也就是溢出后去执行的代码 ...