valgrind的callgrind工具进行多线程性能分析
1.http://valgrind.org/downloads/old.html
2.yum install valgrind
Valgrind的主要作者Julian Seward刚获得了今年的Google-O'Reilly开源大奖之一──Best Tool Maker。让我们一起来看一下他的作品。Valgrind是运行在Linux上一套基于仿真技术的程序调试和分析工具,它包含一个内核──一个软件合成的CPU,和一系列的小工具,每个工具都可以完成一项任务──调试,分析,或测试等。Valgrind可以检测内存泄漏和内存违例,还可以分析cache的使用等,灵活轻巧而又强大,能直穿程序错误的心脏,真可谓是程序员的瑞士军刀。
一. Valgrind概观
Valgrind的最新版是3.2.0,它一般包含下列工具:
1.Memcheck
最常用的工具,用来检测程序中出现的内存问题,所有对内存的读写都会被检测到,一切对malloc()/free()/new/delete的调用都会被捕获。所以,它能检测以下问题:
1.对未初始化内存的使用;
2.读/写释放后的内存块;
3.读/写超出malloc分配的内存块;
4.读/写不适当的栈中内存块;
5.内存泄漏,指向一块内存的指针永远丢失;
6.不正确的malloc/free或new/delete匹配;
7,memcpy()相关函数中的dst和src指针重叠。
这些问题往往是C/C++程序员最头疼的问题,Memcheck在这里帮上了大忙。
2.Callgrind
和gprof类似的分析工具,但它对程序的运行观察更是入微,能给我们提供更多的信息。和gprof不同,它不需要在编译源代码时附加特殊选项,但加上调试选项是推荐的。Callgrind收集程序运行时的一些数据,建立函数调用关系图,还可以有选择地进行cache模拟。在运行结束时,它会把分析数据写入一个文件。callgrind_annotate可以把这个文件的内容转化成可读的形式。
3.Cachegrind
Cache分析器,它模拟CPU中的一级缓存I1,Dl和二级缓存,能够精确地指出程序中cache的丢失和命中。如果需要,它还能够为我们提供cache丢失次数,内存引用次数,以及每行代码,每个函数,每个模块,整个程序产生的指令数。这对优化程序有很大的帮助。
4.Helgrind
它主要用来检查多线程程序中出现的竞争问题。Helgrind寻找内存中被多个线程访问,而又没有一贯加锁的区域,这些区域往往是线程之间失去同步的地方,而且会导致难以发掘的错误。Helgrind实现了名为“Eraser”的竞争检测算法,并做了进一步改进,减少了报告错误的次数。不过,Helgrind仍然处于实验阶段。
5. Massif
堆栈分析器,它能测量程序在堆栈中使用了多少内存,告诉我们堆块,堆管理块和栈的大小。Massif能帮助我们减少内存的使用,在带有虚拟内存的现代系统中,它还能够加速我们程序的运行,减少程序停留在交换区中的几率。
此外,lackey和nulgrind也会提供。Lackey是小型工具,很少用到;Nulgrind只是为开发者展示如何创建一个工具。我们就不做介绍了。
二. 使用Valgrind
Valgrind的使用非常简单,valgrind命令的格式如下:
valgrind [valgrind-options] your-prog [your-prog options]
一些常用的选项如下:
选项
作用
-h --help
显示帮助信息。
--version
显示valgrind内核的版本,每个工具都有各自的版本。
-q --quiet
安静地运行,只打印错误信息。
-v --verbose
打印更详细的信息。
--tool= [default: memcheck]
最常用的选项。运行valgrind中名为toolname的工具。如果省略工具名,默认运行memcheck。
--db-attach= [default: no]
绑定到调试器上,便于调试错误。
我们通过例子看一下它的具体使用。我们构造一个存在内存泄漏的C程序,如下:
#include
#include
void f(void)
{
int* x = malloc(10 * sizeof(int));
x[10] = 0; // problem 1: heap block overrun
} // problem 2: memory leak -- x not freed
int main(void)
{
int i;
f();
printf("i=%d/n",i); //problem 3: use uninitialised value.
return 0;
}
保存为memleak.c并编译,然后用valgrind检测。
$ gcc -Wall -o memleak memleak.c
$ valgrind --tool=memcheck ./memleak
我们得到如下错误信息:
==3649== Invalid write of size 4
==3649== at 0x80483CF: f (in /home/wangcong/memleak)
==3649== by 0x80483EC: main (in /home/wangcong/memleak)
==3649== Address 0x4024050 is 0 bytes after a block of size 40 alloc'd
==3649== at 0x40051F9: malloc (vg_replace_malloc.c:149)
==3649== by 0x80483C5: f (in /home/wangcong/memleak)
==3649== by 0x80483EC: main (in /home/wangcong/memleak)
前面的3649是程序运行时的进程号。第一行是告诉我们错误类型,这里是非法写入。下面的是告诉我们错误发生的位置,在main()调用的f()函数中。
==3649== Use of uninitialised value of size 4
==3649== at 0xC3A264: _itoa_word (in /lib/libc-2.4.so)
==3649== by 0xC3E25C: vfprintf (in /lib/libc-2.4.so)
==3649== by 0xC442B6: printf (in /lib/libc-2.4.so)
==3649== by 0x80483FF: main (in /home/wangcong/memleak)
这个错误是使用未初始化的值,在main()调用的printf()函数中。这里的函数调用关系是通过堆栈跟踪的,所以有时会非常多,尤其是当你使用C++的STL时。其它一些错误都是由于把未初始化的值传递给libc函数而被检测到。在程序运行结束后,valgrind还给出了一个小的总结:
==3649== ERROR SUMMARY: 20 errors from 6 contexts (suppressed: 12 from 1)
==3649== malloc/free: in use at exit: 40 bytes in 1 blocks.
==3649== malloc/free: 1 allocs, 0 frees, 40 bytes allocated.
==3649== For counts of detected errors, rerun with: -v
==3649== searching for pointers to 1 not-freed blocks.
==3649== checked 47,256 bytes.
==3649==
==3649== LEAK SUMMARY:
==3649== definitely lost: 40 bytes in 1 blocks.
==3649== possibly lost: 0 bytes in 0 blocks.
==3649== still reachable: 0 bytes in 0 blocks.
==3649== suppressed: 0 bytes in 0 blocks.
==3649== Use --leak-check=full to see details of leaked memory.
我们可以很清楚地看出,分配和释放了多少内存,有多少内存泄漏。这对我们查找内存泄漏十分方便。然后我们重新编译程序并绑定调试器:
$ gcc -Wall -ggdb -o memleak memleak.c
$ valgrind --db-attach=yes --tool=memcheck ./memleak
一出现错误,valgrind会自动启动调试器(一般是gdb):
==3893== ---- Attach to debugger ? --- [Return/N/n/Y/y/C/c] ---- y
starting debugger
==3893== starting debugger with cmd: /usr/bin/gdb -nw /proc/3895/fd/1014 3895
退出gdb后我们又能回到valgrind继续执行程序。
还是用上面的程序,我们使用callgrind来分析一下它的效率:
$ valgrind --tool=callgrind ./memleak
Callgrind会输出很多,而且最后在当前目录下生成一个文件: callgrind.out.pid。用callgrind_annotate来查看它:
$ callgrind_annotate callgrind.out.3949
详细的信息就列出来了。而且,当callgrind运行你的程序时,你还可以使用callgrind_control来观察程序的执行,而且不会干扰它的运行。
再来看一下cachegrind的表现:
$ valgrind --tool=cachegrind ./memleak
得到如下信息:
==4073== I refs: 147,500
==4073== I1 misses: 1,189
==4073== L2i misses: 679
==4073== I1 miss rate: 0.80%
==4073== L2i miss rate: 0.46%
==4073==
==4073== D refs: 61,920 (46,126 rd + 15,794 wr)
==4073== D1 misses: 1,759 ( 1,545 rd + 214 wr)
==4073== L2d misses: 1,241 ( 1,062 rd + 179 wr)
==4073== D1 miss rate: 2.8% ( 3.3% + 1.3% )
==4073== L2d miss rate: 2.0% ( 2.3% + 1.1% )
==4073==
==4073== L2 refs: 2,948 ( 2,734 rd + 214 wr)
==4073== L2 misses: 1,920 ( 1,741 rd + 179 wr)
==4073== L2 miss rate: 0.9% ( 0.8% + 1.1% )
上面的是指令缓存,I1和L2i缓存,的访问信息,包括总的访问次数,丢失次数,丢失率。
中间的是数据缓存,D1和L2d缓存,的访问的相关信息,下面的L2缓存单独的信息。Cachegrind也生成一个文件,名为cachegrind.out.pid,可以通过cg_annotate来读取。输出是一个更详细的列表。Massif的使用和cachegrind类似,不过它也会生成一个名为massif.pid.ps的PostScript文件,里面只有一幅描述堆栈使用状况的彩图。
以上只是简单的演示了valgrind的使用,更多的信息可以在它附带的文档中得到,也可以访问valgrind的主页:http://www.valgrind.org。学会正确合理地使用valgrind对于调试程序会有很大的帮助
使用valgrind的callgrind工具进行多线程性能分析
valgrind是开源的性能分析利器。 根据它的文档,可以用它来检查内存泄漏等问题,还可以用来生成函数的调用图,就这两个功能就足够有吸引力了。
本文主要是介绍如何使用valgrind的callgrind工具进行性能分析。
分析过程
使用callgrind工具生成性能分析数据
命令格式如下:
valgrind --tool=callgrind ./exproxy
其中 ./exproxy就是我们要分析的程序。执行完毕后,就会在当前目录下生成一个文件。文件名为“callgrind.out.进程号”。如,callgrind.out.31113。注意,对于daemon进程的调试,不要通过kill -9方式停止。
如果你调试的程序是多线程,你也可以在命令行中加一个参数 -separate-threads=yes。这样就会为每个线程单独生成一个性能分析文件。如下:
valgrind --tool=callgrind --separate-threads=yes ./exproxy
生成的文件除了callgrind.out.31113外,还会多出一些子线程的文件。文件名如下:
callgrind.out.31113-01 callgrind.out.31113-02 callgrind.out.31113-03
把callgrind生成的性能数据转换成dot格式数据
可以使用gprof2dot.py脚本,把callgrind生成的性能分析数据转换成dot格式的数据。方便使用dot把分析数据图形化。
脚本可以 点此下载 。脚本使用方式如下:
python gprof2dot.py -f callgrind -n10 -s callgrind.out.31113 > valgrind.dot
使用dot把数据生成图片
命令格式如下:
dot -Tpng valgrind.dot -o valgrind.png
生成的图片示例

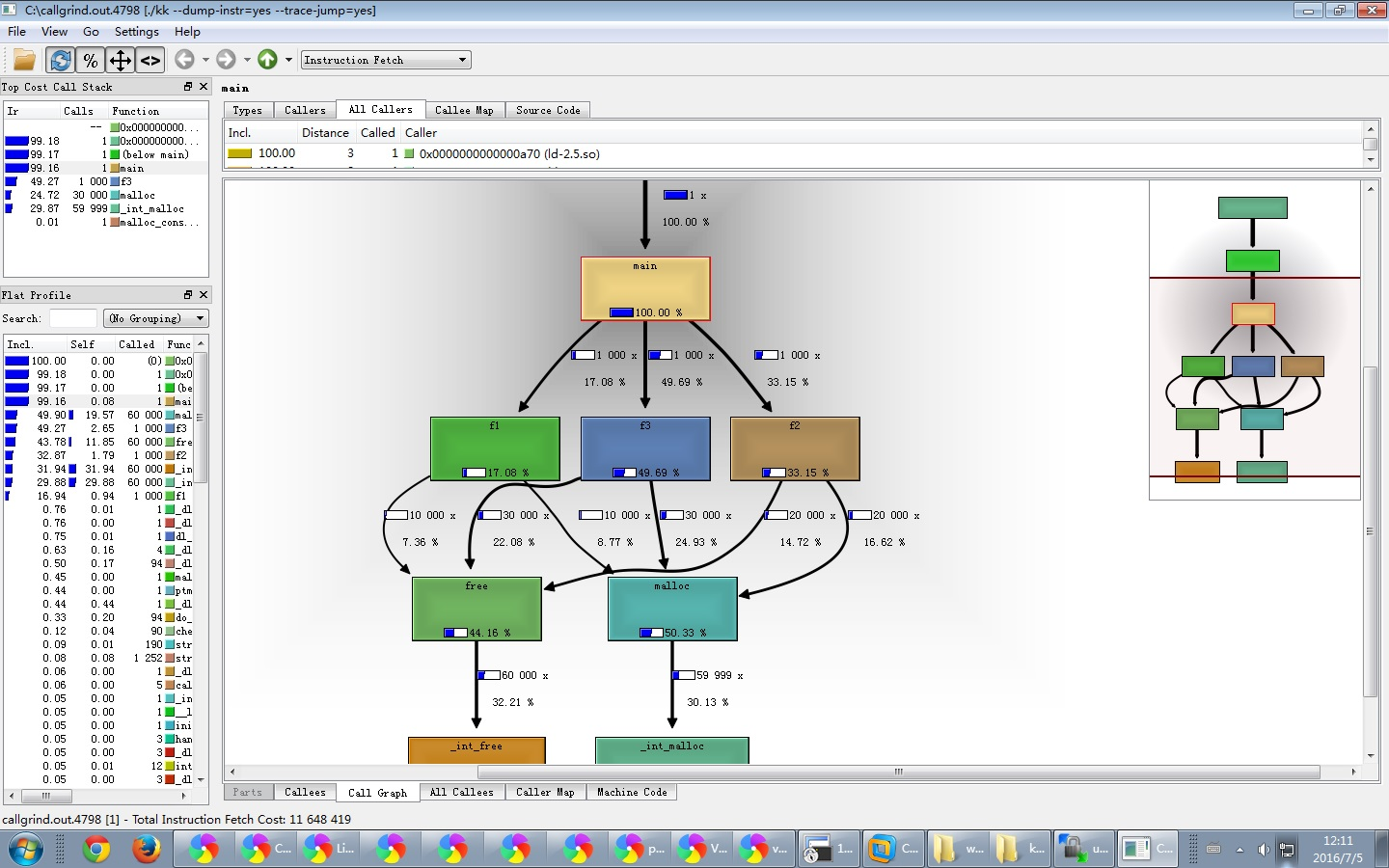
通过图形,我们可以很直观的知道那段程序执行慢,并且了解相关调用关系
[root@localhost uu]# cat kk.c #include <stdio.h>
#include <stdlib.h> void f1() {
int i;
int *p;
for (i = 0; i < 10; i++) {
p = malloc(sizeof(int));
*p = 10;
free(p);
}
} void f2() {
int i;
int *p;
for (i = 0; i < 20; i++) {
p = malloc(sizeof(int));
*p = 10;
free(p);
}
} void f3() {
int i;
int *p;
for (i = 0; i < 30; i++) {
p = malloc(sizeof(int));
*p = 10;
free(p);
}
} int main() {
int i; for (i = 0; i < 1000; i++) {
f1();
f2();
f3();
} return 0;
} gcc -g kk.c -okk
[root@localhost uu]# valgrind --tool=callgrind ./kk --dump-instr=yes --trace-jump=yes
==4798== Callgrind, a call-graph generating cache profiler
==4798== Copyright (C) 2002-2009, and GNU GPL'd, by Josef Weidendorfer et al.
==4798== Using Valgrind-3.5.0 and LibVEX; rerun with -h for copyright info
==4798== Command: ./kk --dump-instr=yes --trace-jump=yes
==4798==
==4798== For interactive control, run 'callgrind_control -h'.
==4798==
==4798== Events : Ir
==4798== Collected : 11648419
==4798==
==4798== I refs: 11,648,419
[root@localhost uu]# ll
总用量 44
-rw------- 1 root root 26499 Jul 4 21:01 callgrind.out.4798
-rwxr-xr-x 1 root root 9289 Jul 4 20:48 kk
-rw-r--r-- 1 root root 516 Jul 4 20:48 kk.c
把callgrind.out.4798传到 window 7 ,
如果要时行源代码显示,KK.C也传到windows 7
用kcachegrind 打开callgrind.out.4798 ,即显示下面图
LINUX: http://kcachegrind.sourceforge.net/html/Home.html
windows: https://sourceforge.net/projects/precompiledbin/files/?source=navbar
valgrind的callgrind工具进行多线程性能分析的更多相关文章
- valgrind 打印程序调用树+进行多线程性能分析
使用valgrind的callgrind工具进行多线程性能分析 yum install valgrind / wget http://valgrind.org/downloads/valgrind-3 ...
- 用Chrome开发者工具做JavaScript性能分析
来源: http://blog.jobbole.com/31178/ 你的网站正常运转.现在我们来让它运转的更快.网站的性能由页面载入速度和代码执行效率决定.一些服务可以让你的网站载入更快,比如压缩J ...
- jacoco覆盖率工具测试及性能分析
ant版本:https://ant.apache.org/bindownload.cgi jdk版本 注: ant 1.10 ---> jdk1.8 ant 1.9 ---& ...
- 利用PyCharm的Profile工具进行Python性能分析
Profile:PyCharm提供了性能分析工具Run->Profile,如下图所示.利用Profile工具可以对代码进行性能分析,找出瓶颈所在. 测试:下面以一段测试代码来说明如何使用pych ...
- valgrind和Kcachegrind性能分析工具详解
一.valgrind介绍 valgrind是运行在Linux上的一套基于仿真技术的程序调试和分析工具,用于构建动态分析工具的装备性框架.它包括一个工具集,每个工具执行某种类型的调试.分析或类似的任务, ...
- CLR Profiler 性能分析工具
CLR Profiler 性能分析工具 CLR Profiler 性能分析工具 CLR Profiler 有两个版本,分别用于CLR1.1 和 CLR2.0,至于CLR4试了一些也可以,但不知道是否完 ...
- Linux下性能分析工具汇总
来自:http://os.51cto.com/art/201104/253114.htm 本文讲述的是:CPU性能分析工具.Memory性能分析工具.I/O性能分析工具.Network性能分析工具. ...
- APP 性能分析工作台——你的最佳桌面端性能分析助手
目前 MARS-App 性能分析工作台版本为开发者提供Fastbot桌面版的服务. 旨在帮助开发者们更快.更便捷地开启智能测试之旅,成倍提升稳定性测试的效率. 作者:字节跳动终端技术--王凯 背景 F ...
- Linux下利用Valgrind工具进行内存泄露检测和性能分析
from http://www.linuxidc.com/Linux/2012-06/63754.htm Valgrind通常用来成分析程序性能及程序中的内存泄露错误 一 Valgrind工具集简绍 ...
随机推荐
- js面向对象编程(一):封装(转载)
一. 生成对象的原始模式 假定我们把猫看成一个对象,它有"名字"和"颜色"两个属性. var Cat = { name : '', color : '' } 现 ...
- Ansi,UTF8,Unicode,ASCII编码的区别 ---我看完了 明白了很多
来自:http://blog.csdn.net/xiongxiao/article/details/3741731 ------------------------------------------ ...
- 将win平台上的mysql数据复制到linux上报错Can't write; duplicate key in table
将win平台上的mysql数据复制到linux上报错Can't write; duplicate key in table xxx 新年新气象,果然在新年的第一天就遇到了一个大坑,项目在win上跑的没 ...
- Spring:与Redis的集成
一个月没写过博客了,一直想记录一下之前学习的Redis的有关知识,但是因为四月太过于慵懒和忙碌,所以一直没有什么机会,今天就来讲讲,如何使用Spring当中的Spring-data-redis去与Re ...
- 原生js编写设为首页兼容ie、火狐和谷歌
// JavaScript Document // 加入收藏 <a onclick="AddFavorite(window.location,document.title)" ...
- 后门工具dbd
后门工具dbd dbd功能类似于Netcat,但提供强大的加密功能,支持AES-CBC-128和HMAC-SHA1加密.该工具可以运行在类Unix和Windows系统中.渗透测试人员首先使用该工具 ...
- git log 查看某文件的修改历史
先进入此文件所在的目录下 1. git log --help 所有的git命令都可以通过git manual查看 在synopsis中可以看到公式 git log [<options>] ...
- CodeChef - UASEQ Chef and sequence
Read problems statements in Mandarin Chinese and Russian. You are given an array that consists of n ...
- Codeforces 920 G List Of Integers
题目描述 Let's denote as L(x,p)L(x,p) an infinite sequence of integers yy such that gcd(p,y)=1gcd(p,y)=1 ...
- 【贪心】【multiset】 Codeforces Round #401 (Div. 2) B. Game of Credit Cards
对第一个人的排序,然后从小到大处理,对第一个人的每枚卡片,从第二个人的卡片中选择一个大于等于它的最小的,否则选择一个当前剩下的最小的,这样可以保证负场最少. 如果选择的改成大于它的最小的,就可以保证胜 ...